







FE-VAD: High-Low Frequency Enhanced Weakly Supervised Video Anomaly Detection 论文阅读
文章信息:

发表于:ICME2024(CCF-B)
原文链接:https://ieeexplore.ieee.org/abstract/document/10688326/
无源码
Abstract
弱监督视频异常检测(WSVAD)旨在识别视频中的异常事件,使用视频级标签而不是帧级标签。以往的研究通常侧重于在时空领域建模异常。然而,异常的表现形式多种多样,仅在时空领域建模是远远不够的。为了解决这一问题并全面捕捉不同形式的异常,我们提出了一种新方法——高低频增强弱监督视频异常检测(FE-VAD),该方法引入了频域信息,用以捕捉和分析不同频率层次的异常特征,从而有助于学习局部和全局时空依赖关系。我们的FE-VAD由时间增强网络(TSN)和高低频增强网络(HLFN)组成。TSN用于增强传统时空域中的异常特征,HLFN则通过空间和时间上解耦和调整高频与低频信息。在FE-VAD中,频域分析为描述传统时空域中难以检测的异常事件提供了互补的视角。大量实验表明,我们的FE-VAD方法在上海科技、UCFCrime和XD-Violence三个数据集上均取得了最先进的结果。
I. INTRODUCTION
视频异常检测(VAD)是一项旨在识别视频序列中异常事件的任务,其中异常表现为在意外的时间或地点出现的异常视觉或运动模式[1]。VAD主要基于无监督的一类分类方法,假设模型在训练过程中能够学习到正常特征的全面表示。然而,现实世界中正常和异常行为的模式多种多样,这使得准确感知异常变得困难。因此,研究人员提出了弱监督视频异常检测(WSVAD)以缓解这一问题,利用多实例学习(MIL)来提高检测精度。Sultani等人[2]引入了UCF-Crime数据集,并提出了用于WSVAD的多实例学习(MIL)方法。He等人[3]提出了一种基于图的MIL框架,并采用了锚字典学习。Sun等人[4]提出了一种基于变换器的模型,并通过考虑长短期特征的共教学策略进行训练。Cao等人[5]设计了一种跨批聚类损失函数,以优化视频内特征对比。Lv等人[6]通过优化训练过程中的不变预测来学习无偏的异常特征。Pu等人[7]将文本提示与传统的时空引导模型相结合。
视频异常检测(VAD)是一项旨在识别视频序列中异常事件的任务,其中异常表现为在意外的时间或地点出现的异常视觉或运动模式[1]。VAD主要基于无监督的一类分类方法,假设模型在训练过程中能够学习到正常特征的全面表示。然而,现实世界中正常和异常行为的模式多种多样,这使得准确感知异常变得困难。因此,研究人员提出了弱监督视频异常检测(WSVAD)以缓解这一问题,利用多实例学习(MIL)来提高检测精度。Sultani等人[2]引入了UCF-Crime数据集,并提出了用于WSVAD的多实例学习(MIL)方法。He等人[3]提出了一种基于图的MIL框架,并采用了锚字典学习。Sun等人[4]提出了一种基于变换器的模型,并通过考虑长短期特征的共教学策略进行训练。Cao等人[5]设计了一种跨批聚类损失函数,以优化视频内特征对比。Lv等人[6]通过优化训练过程中的不变预测来学习无偏的异常特征。Pu等人[7]将文本提示与传统的时空引导模型相结合。
为了解决这些问题,我们提出了一种新的高低频增强弱监督视频异常检测框架(FE-VAD),该框架结合了传统的时空域增强网络(TSN)和频域增强网络(HLFN)。首先,频域增强为学习异常特征提供了一种互补视角,帮助模型检测在传统时空域中可能难以感知的异常事件。此外,通过傅里叶变换(FFT)将视频特征转换到频域中,可以在整个视频的各频率之间建立高效的全局交互,从而增强视频特征的全局依赖性。具体来说,我们的方法采用了频率解耦模块,将特征分离为高频特征和低频特征两个分支。随后,设计了频率调整模块,以进一步编码从空间和时间域转换的高频和低频特征的异常特征表示。相关研究表明,低频特征更适合高层语义,而高频特征对捕捉细节变化更敏感[10]。因此,在我们的频率调整模块中,高频特征用于检测细微的局部异常,而低频特征用于识别全局时空异常特征并过滤掉无关噪声。这两类特征在异常检测中表现出互补的能力。最后,为了优化由高频和低频特征回归的异常得分,我们在推理阶段提出了一种特定于视频的缩放和平滑策略。利用异常训练数据,我们设置了一个阈值,并基于该阈值为推理视频分配伪标签,从而帮助模型有选择地缩放推理视频的异常得分。实验表明,我们的FE-VAD方法在ShanghaiTech、UCF-Crime和XD-Violence数据集上实现了当前最先进的结果。
综上所述,我们的贡献如下:
-
据我们所知,我们首次将频率增强引入弱监督视频异常检测(WSVAD)领域,为该领域提供了一个互补的视角,提高了模型描述和检测异常事件的能力,超越了传统的时空方法。
-
我们提出了一种高低频增强网络(HLFN),该网络包括两个主要组件:频率解耦模块(FDM)和频率调整块(FAB)。FDM旨在将高频和低频特征分离,提供不同的特征,而FAB则用于调节频率信息,并为每个频率分配可学习的权重。HLFN包括两个步骤:首先沿时间域进行频域增强,然后沿空间域进行频域增强,这有效提升了特征表示异常的能力。
-
我们采用特定于视频的缩放和平滑策略,以优化推理阶段的异常检测。该策略利用训练数据在推理过程中分配伪标签,从而优化帧级异常得分。
II. PROPOSED APPROACH
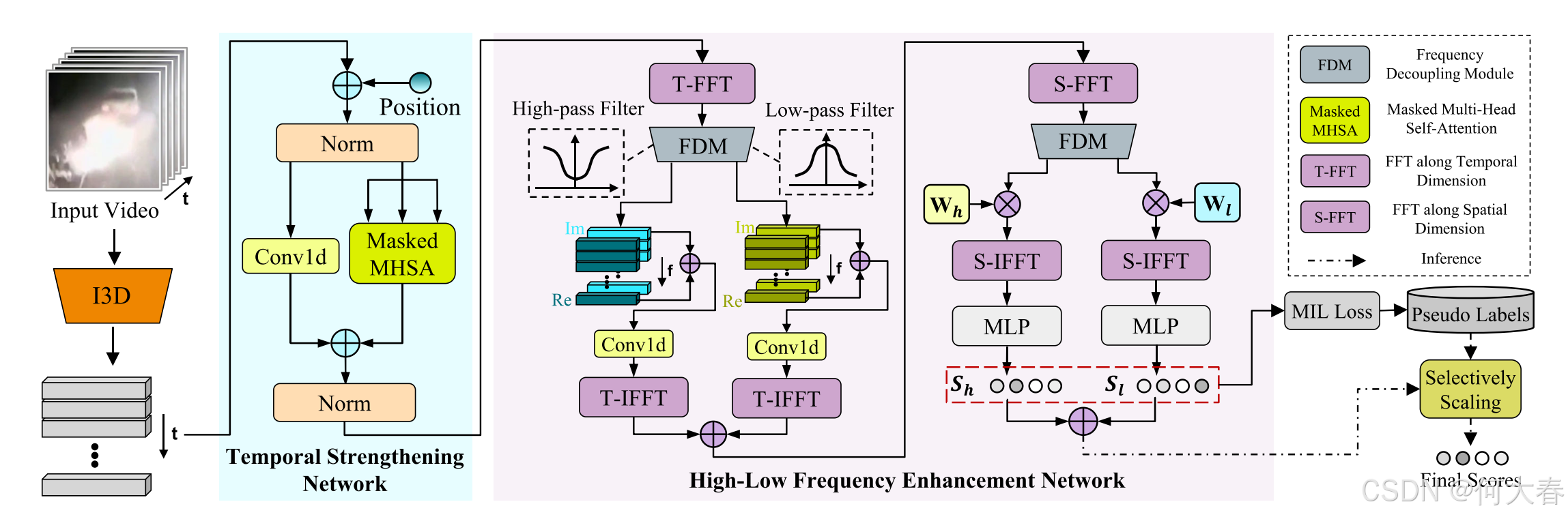
图1. 提出的FE-VAD框架由三个组件组成:骨干模型、时序增强网络和高低频增强网络。
如图1所示,我们首先利用一个主干网络提取训练视频的与任务无关的片段级特征。沿用以往的WSVAD方法[7][11],我们使用I3D[12]来提取特征,采用16帧大小的滑动窗口。随后,基于自注意力的时间增强网络被用于建模传统时空域中的异常,而高低频增强网络则被提出用于从频域中检测异常。频率解耦模块和频率调整块被联合使用,以感知来自时间和空间域的各种异常模式。最后,在推理阶段,我们提出了特定于视频的缩放和平滑策略,以进一步优化帧级异常得分。
A. Temporal Strengthening Network
时间增强网络(TSN)旨在增强时空域内的时序异常特征,既考虑全局也考虑局部。虽然以往的方法引入了基于自注意力的网络来感知全局时序关系[4][7],但WSVAD的独特特性启发我们提出了进一步的优化。首先,鉴于视频相比文本和图像具有更大的冗余性,特征的局部相关性也显得尤为重要。因此,我们引入了一个1维卷积层,卷积核大小为3,用于局部时序增强。对于视频的片段特征 X = ( x 1 , x 2 , . . . , x n ) X=(x_1,x_2,...,x_n) X=(x1,x2,...,xn),局部分支可以表示为:
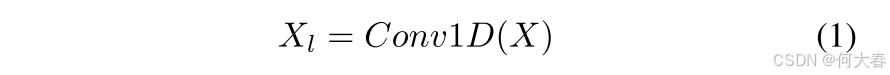
其次,由于异常事件通常会影响随后的事件——例如,一起交通事故导致人群逐渐聚集——按定义,之后发生的事件不被视为异常。为了减轻过去事件对未来事件的影响,并使模型更加专注于预测未来的异常特征,我们采用了掩蔽自注意力机制。在注意力矩阵中,我们掩蔽过去特征对未来特征的影响,实际上是保留注意力矩阵的上三角部分,可以表示为:
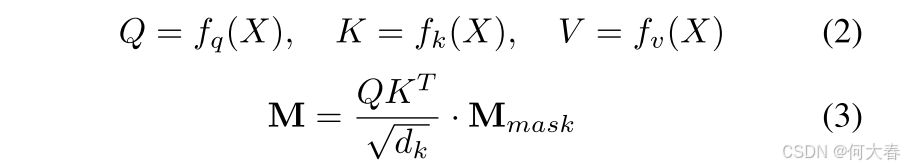
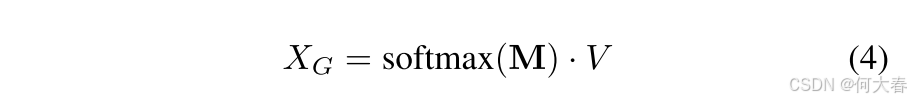
在这里, M m a s k \mathbf{M}_{mask} Mmask 是一个操作,它将注意力得分矩阵的下三角部分设置为一个非常小的值(例如,负无穷大)。这样可以确保在应用softmax函数时,这些值接近零。 d k d_k dk表示片段特征的维度。在增强片段特征中的长期时序信息后,我们通过一个可学习的参数 α \alpha α,自适应地将其与局部增强的特征进行加和,如方程5所示。
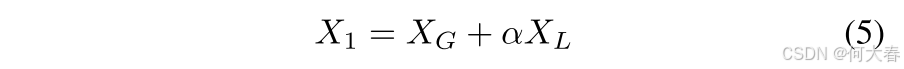
B. High-Low Frequency Enhancement Network
高低频增强网络(HLFN)引入了频率分析,增强了模型感知各种异常模式的能力。HLFN利用快速傅里叶变换(FFT)将视频特征转换为频率特征,为异常检测提供了一个互补的视角。在传统时域增强异常特征后,我们的方法依次将时空域的特征转换到频域,并分别增强频率信息。我们的HLFN由两个步骤组成:时频步骤和空频步骤。在每个步骤中,我们利用频率解耦模块和频率调整块来在不同尺度上建模异常。
在第一步中,我们沿时间域使用一维傅里叶变换(FFT)将特征 X 1 X_1 X1转换为频域特征 X f 1 X_{f1} Xf1。然后,通过频率解耦模块,将 X f 1 X_{f1} Xf1分离为高频特征 X h f 1 X_{hf1} Xhf1和低频特征 X l f 1 X_{lf1} Xlf1。具体而言,这些特征是通过将 X f 1 X_{f1} Xf1分别通过高通滤波器和低通滤波器获得的。我们采用高斯滤波器进行频率解耦。与理想滤波器和巴特沃斯滤波器相比,高斯滤波器在本质上增强或衰减高/低频信息,这意味着它们保留了所有频率信息。此外,高斯滤波器提供更平滑的边缘和更自然的过渡。这些优点有助于建模各种异常模式,特别是那些与截止点附近频率相关的异常。
随后,频率调整块被用来修改频域权重。考虑到时间维度中视频长度的变化,受[10]启发,我们采用频域卷积层来处理这个问题。对于每个频率,我们分别分离实部和虚部,然后沿相应的维度将它们连接起来。这个过程将不可卷积的复数张量转换为可卷积的张量。随后,我们对这个实数张量执行1维卷积,卷积核大小为1。以高频特征为例:
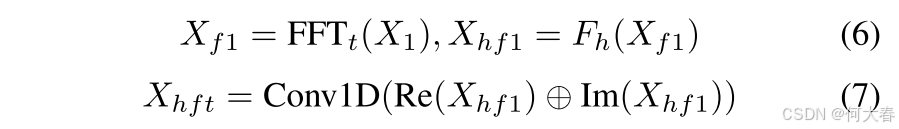
其中, F h F_h Fh 表示高斯高通滤波器,Re 和 Im 分别表示实部和虚部, ⊕ \oplus ⊕ 表示两个张量的拼接,FFT t _t t 表示沿时间维度的一维傅里叶变换。类似地, X l f t X_{lft} Xlft 也是通过相同方式获得的。随后,我们使用逆傅里叶变换(IFFT)将它们转换回时间域,并将它们加在一起,如下所示:
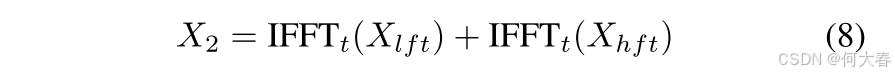
在第二步中,我们对空间域进行频率增强。与第一步类似,使用频率解耦模块将高频和低频特征分离,这通过高斯高通/低通滤波器实现。随后,我们使用频率调整块进一步修改空间域中的频率特征。与第一步不同,我们选择了一种不同的方法来增强频率异常特征。受[13]启发,由于空间域特征的长度是固定的,我们使用一维频率权重矩阵
W
W
W 来直接调整每个频率的幅度。使用频率权重矩阵不仅代表了一种更直接、更简洁的方法,还使我们的模型具备了自适应调节每个频率的能力,从而实现更细粒度的频率调整。以高频特征为例:
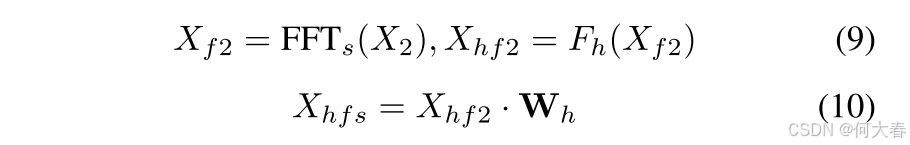
其中,FFT s _s s表示沿空间(特征)维度的一维傅里叶变换。
与第一步不同,我们不直接合并高频和低频特征;相反,我们保留高频和低频两个分支。首先,我们分别使用逆傅里叶变换(IFFT)将它们转换回空间域,将它们与原始特征拼接,然后通过三个线性层分别回归高频和低频特征的异常得分( S h S_h Sh 和 S l S_l Sl)。在训练阶段,我们为高频和低频的异常得分设计损失函数。在推理阶段,我们提出了特定于视频的缩放和平滑策略,将它们结合起来共同获得帧级异常得分。我们希望高频和低频的两个分支分别负责在不同尺度上检测异常特征,并能够互相补充。
C. High-Low Frequency MIL Loss
我们提出了一个高低频多实例学习(MIL)损失函数。与传统的MIL损失类似,我们在每个视频中使用更高的异常得分来与视频级标签一起计算交叉熵损失。
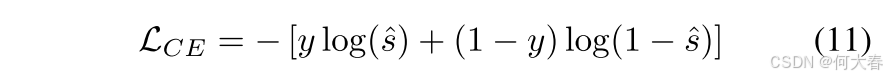
为了增强视频异常模式的学习,对于异常视频,我们自适应地选择具有最高异常得分的 topk = l e n v n \frac{len_v}{n} nlenv 个片段作为代表。考虑到高频特征更关注细节,而低频特征更关注整体模式,我们设置 n h > n l n_h > n_l nh>nl,意味着对于高频特征损失选择的片段较少。这种差异化的片段选择策略优化了模型在高频信息中分辨细粒度细节的能力,同时捕捉低频信息中的更广泛上下文。最终的 HLF-MIL 损失可以表示为:
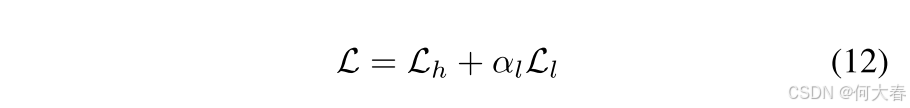
D. Video-specific Scaling and Smoothing Strategy
特定于视频的缩放和平滑策略(VSSS)旨在优化推理阶段的异常得分。首先,我们在训练过程中记录每个异常视频的最高异常得分,创建异常得分集合
D
s
D_s
Ds。随后,从
D
s
D_s
Ds 中选择最低得分
s
min
s_{\text{min}}
smin,并实施一个阈值
θ
\theta
θ,用来计算阈值得分
s
thres
s_{\text{thres}}
sthres:
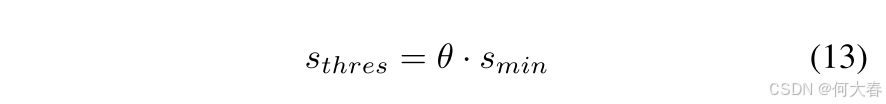
通过
s
thres
s_{\text{thres}}
sthres,我们在推理时为每个视频分配伪标签。当最大片段级(帧级)异常得分超过
θ
\theta
θ 时,该视频被伪标签为异常。对于来自一个视频的帧级异常得分
s
v
s_v
sv,当
max
(
s
v
)
≥
s
thres
\text{max}(s_v) \geq s_{\text{thres}}
max(sv)≥sthres 且
max
(
s
v
)
−
min
(
s
v
)
>
0
\text{max}(s_v) - \text{min}(s_v) > 0
max(sv)−min(sv)>0 时,我们对其进行缩放,如下所示:
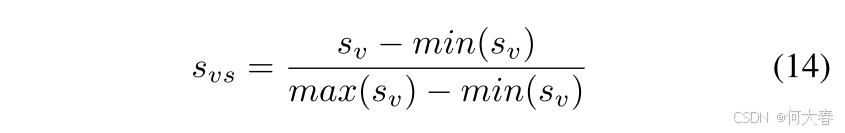
最后,为了获得更平滑的异常得分,我们利用一维高斯滤波器优化异常得分,然后通过在相邻帧之间进行线性插值来细化片段级得分,重点关注每个16帧片段的中心帧,从而实现得分的更平滑过渡。
III. EXPERIMENT
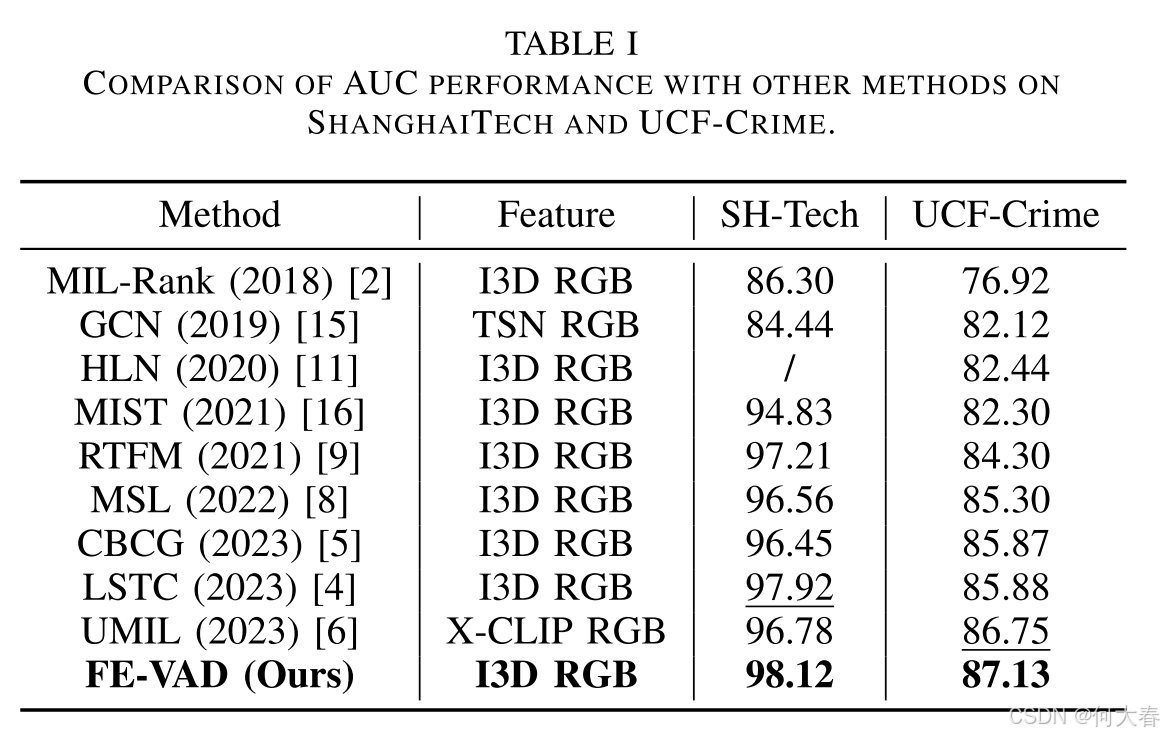
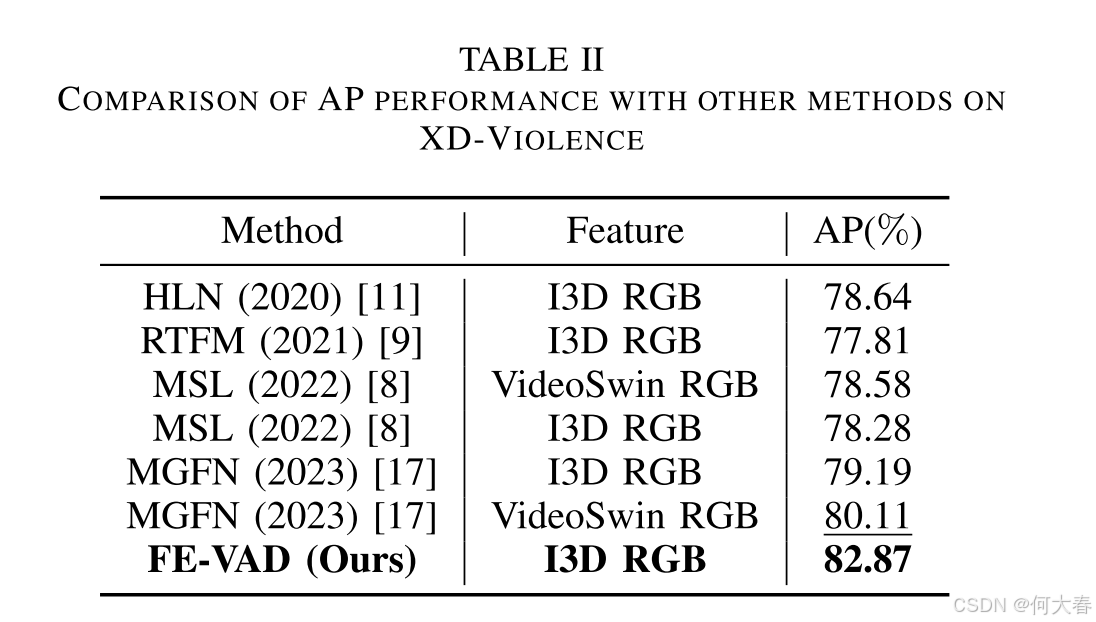
IV. CONCLUSION
在本文中,我们提出了一种基于频率增强的全新WSVAD模型。该模型结合了传统时空域信息增强与频域增强模块,两者相辅相成,有效地提升了异常事件的检测能力。此外,我们对频率特征进行解耦,联合高频和低频特征来检测异常事件。最后,我们利用特定于视频的缩放和平滑策略来优化帧级异常得分。三个数据集上的实验结果表明,FE-VAD具有领先的性能。
阅读总结
这个频域模块,怎么实现的从论文里看不出来,对于没有相应知识的我来说,获取作者可以多介绍一下,比如说虚部实部是什么。

















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









