







 本文介绍了Chinese-Mixtral-8x7B模型,通过Mistral进行中文扩词表增量预训练,提高编解码效率,开源了模型权重、预训练代码和使用FlashAttention2加速推理的方法。模型展示了强大的中文生成和理解能力以及性能指标。
本文介绍了Chinese-Mixtral-8x7B模型,通过Mistral进行中文扩词表增量预训练,提高编解码效率,开源了模型权重、预训练代码和使用FlashAttention2加速推理的方法。模型展示了强大的中文生成和理解能力以及性能指标。
Chinese-Mixtral-8x7B基于Mistral发布的模型Mixtral-8x7B进行了中文扩词表增量预训练。扩充后的词表显著提高了模型对中文的编解码效率,并通过大规模开源语料对扩词表模型进行增量预训练,使模型具备了强大的中文生成和理解能力。
开源地址见https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B。
该项目开源了模型权重和扩词表增量预训练代码。
该使用QLoRA进行训练,LoRA权重与合并权重后的模型分别开源。
使用Flash Attention 2加速推理代码如下:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "HIT-SCIR/Chinese-Mixtral-8x7B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, attn_implementation="flash_attention_2", torch_dtype=torch.bfloat16, device_map="auto")
text = "我的名字是"
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
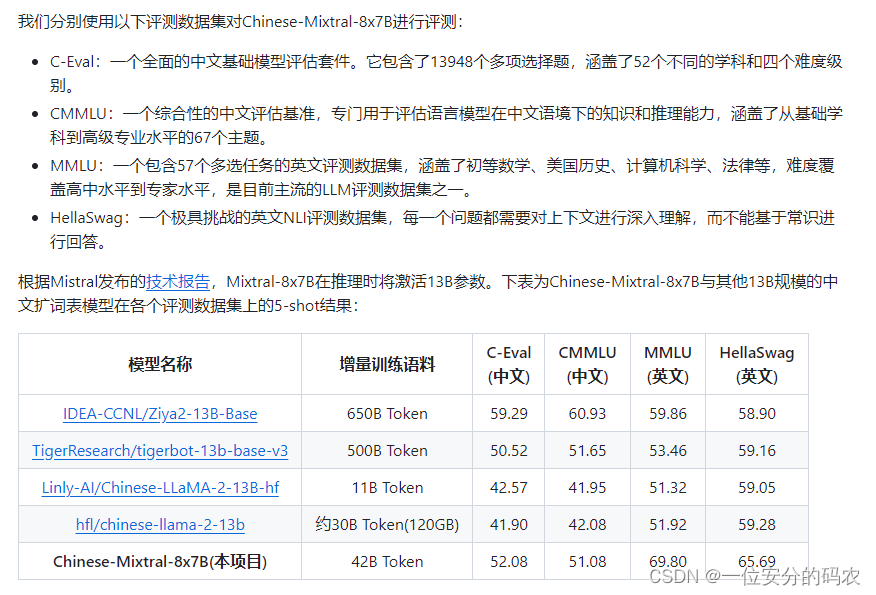
模型性能如下:
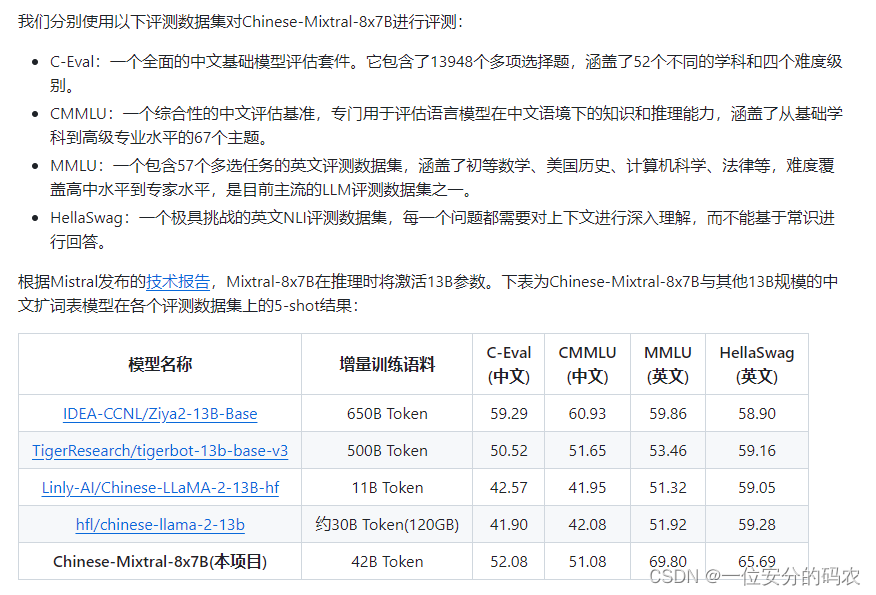
模型生成效果:

中文编码效率:
参考https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B


















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









