







文章目录
前言
博主是一名电子专业的学生,在校期间非常喜欢写文章,曾经写过 4 篇读书文章获了奖。后来大二时决心转向本专业,放弃了原来的文学写作。在校期间,博主一直觉得对C语言学习不精,于是在大四上半学期,博主写了这篇C语言总结笔记的初稿,再后来工作期间又加入了一些补充。因此,本笔记可以说倾注了博主很多的时间和精力,希望能够帮助到想了解C语言的小伙伴。
2024年2月新增(第11、12种字符)
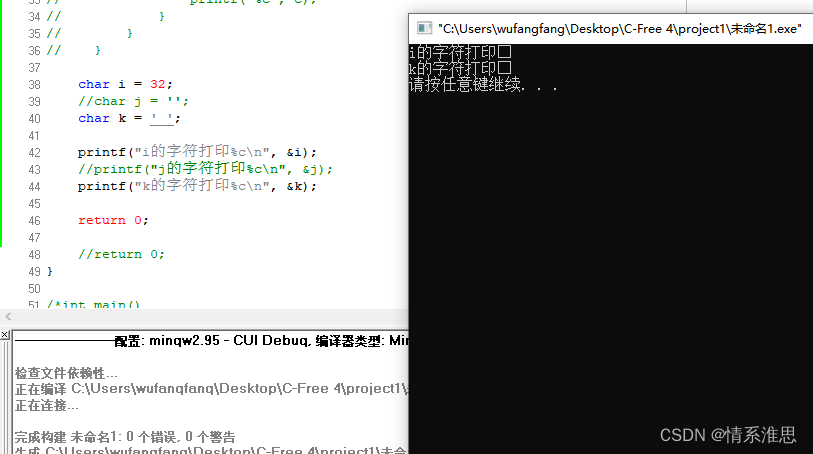
'' 会报错[Error] C:\Users\wufangfang\Desktop\C-Free 4\project1\未命名1.cpp:39: empty character constant
' ' 是一个空格字符=ASCII值是32=空格的作用
" " 是空格字符串(末尾自动加'\0'字符)
同样 "" 也会报错,不过没验证
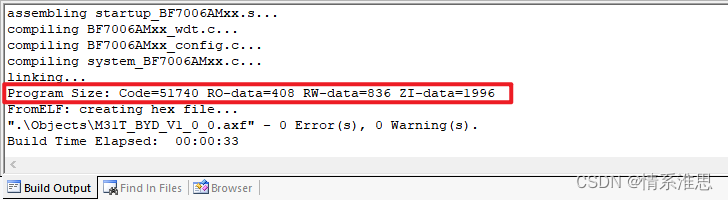
2024年6月新增补充(RO、RW和ZI-DATA说明)
ARM中的RO、RW和ZI DATA说明
上面文章是转载,写得很好,我简单总结下:
hex文件=s19文件=其它格式文件=可执行文件包含=ASCII文件(包含十六进制)=单片机编译代码生成的烧录文件=体积稍大,包含信息多
bin文件=可执行文件=单片机生成的=二进制文件=无数个0和1=可用特定软件转化为十六进制查看,但本质上还是二进制=体积小,信息精简
Keil编译文本字符代码时,会将代码转化为指令,这些指令就在可执行文件里,可执行文件存到ROM里面(也可以理解为FLASH放代码的),当可执行文件开始运行时,CPU最终是按照FLASH里面的指令在RAM里面运行,很多东西都在RAM里面的环境才能运行,比如堆栈是动态的就是RAM里面
RO在ROM里面不动,是指可执行文件里面的指令和常量(define和const等)
RW必须在RAM里,是可执行文件里涉及到的已经初始化的变量等等
ZI-DATA必须也在RAM里面,是可执行文件里涉及到的未初始化的变量等等
1、辨析10种字符,字符串
C语言没有字符串类型,也没有字符串变量,字符串是存放在字符型数组=字符数组中的
(0,‘0’,“0”,NULL,\n,\0,“\n”,“\0”,‘\0’,‘\n’)
整形0,字符0,字符串0(末尾自动加’\0’字符),空指针,不知道(应该没有意义),不知道(应该没有意义),不知道(应该是字符串),不知道(应该是字符串),空字符,转义字符=换行操作
按下回车键=换行+回车=‘\n’+‘\r’
‘\0’=ASCII值为0的字符=空操作=什么也不做=用它默认加在字符串尾部不会产生异常影响!=空格字符
2、数组,字符串,字符数组
有整型变量,有整型数组
有字符型变量,有字符型数组
有结构体类型变量,有结构体类型数组
数组元素如有剩余,自动赋值空字符=‘\0’,不进行尾部添加操作
字符串中,进行尾部操作自动加’\0’字符,字符串存储在字符型数组=字符数组中,没有字符串型数组
如果(字符串个数+1)=字符数组长度,则数组中最后一个元素就是’\0’元素(字符串自动添加的,作为结束标志位)
如果字符串个数+1=数组长度+1,则无影响,数组中无需添加’\0’元素,就是说字符串自动添加的’\0’字符并没有写入数组中
char c[5] = {‘C’,‘h’,‘i’,‘n’,‘a’};//这样写可以,为了统一化规范化,一般不这样做(一般会让数字大于5)
如果(字符串个数+1)<数组长度,则数组中后面所有默认都添加’\0’
虽然没有字符串类型,和字符串型数组,但是可以喊它为字符串常量=“China”
puts(字符数组)=输出字符串(将字符串尾部的’\0’字符转化为’\n’=输出换行),printf可以实现输出字符串功能,所以一般不用她
gets(字符数组)=输入字符串
strcat(字符数组1,字符数组2)=连接=将1尾部的’\0’位置清楚放2的第一个字符=开始1必须足够大能容下2否则出错
strcpy(字符数组1,字符数组2)=复制=1必须足够大能容下2=2也可以是字符串常量
strcmp(字符数组1,字符数组2)=比较=直到出现不同的字符或者遇到’\0’字符才结束判断
strlen(字符数组)=字符串长度=这是实际长度不包括尾部的’\0’字符(数组会加上这个字符)
strlwr(字符数组)=转换为小写
strupr(字符数组)=转换为大写
没有必要,不建议使用全局变量,程序设计中,要求模块“内聚性强”,与其它模块的“耦合性弱”,当然也有其它原因,比如与局部变量名冲突
3、四种存储类别(auto,register,stasic,extern)
每一个变量和函数都有两个属性,数据类型和数据的存储类别,数据类型自不必说,存储类别分为1auto=动态存储,2statis=静态存储,3register=寄存器,4extern外部,电脑供用户使用的有程序区和静态存储区和动态存储区,全局变量放在静态存储区,程序执行完才释放
1中,默认的都是这个存储方式,一般省略不写,函数中的形参,函数中定义的局部变量(注意,先后调用同一个函数,前后调用的局部变量的地址有可能不同,因为系统动态分配内存空间,函数调用完立即释放)
2中,函数调用后,其变量占用的存储单元不释放(程序整个运行期间都不释放),自不必说(注意如果static类型变量不赋初值,则整形默认为0,字符默认为’\0’,而auto变量=动态存储变量,默认为垃圾值)(还要注意,其它地方不能引用这个变量)
3中,现在电脑速度很快,已经基本上不用这种类型变量了,但是了解有这种类型即可
4中,main函数中这个extern 变量之后,main函数里就可以引用位于main函数下面定义的这个变量(另一用法就是将变量的作用域扩展到其它文件,在其他文件中寻找这个变量)(注意static 变量,这个变量的作用域限制在本文件中,即使用extern调用这个变量也不行),所以说首先在本文件中查找,如果查找不到再去其它文件中查找
extern函数与extern变量,作用是一样的,前者是在其它文件中寻找到这个函数并调用,前提是函数没有被static化,后者是可以调用其它文件中这个变量,前提是这个变量没有被static化
注意:123中主要针对的都是局部变量(auto,register,stasic),4中=全局变量extern,我们可以简单的这样认为:假如1文件中有全局变量int A,2文件中全局变量extern int A,那么extern的作用=将1中A外部变量的作用域扩展到2文件,使得2文件可以调用这个A变量(课本说法),或者说2文件中会从其它文件比如1文件中寻找这个A变量(我自己理解=上面4中文字=课本解释)
4、指针与指针变量详解
第八章 善于利用指针
C语言中的地址=内存编号(纯地址)+数据的类型=“带类型的地址”,不过我们一般举例子都是将地址表示为=2000=2000H
指针不等于指针变量,指针=地址(指向变量单元),指针变量=特殊变量=它的值为地址
int i;
int *P=&i;
上面中i是整型变量,它的地址=内存编号+4个字节长度(VC++6.0是如此)
*=指向,所以*p=指针变量p指向的变量i=i,p的类型=int *类型=基类型=指向int的指针
p=指向整型数据的指针变量(标准说法)
p=指针变量(简称),它的值=地址=内存编号+4个字节,不能说p=地址(p=&i是赋值语句,不能说他们相等,我刚刚就弄错了,切记),只能说指针变量存储了整型变量i的内存地址=内存编号+4个字节=它的内容是变量i的地址
&i=变量i的内存编号+数据类型(4个字节),所以指针变量p加1=指向的i地址值+4个字节
因为指针变量p的内容=变量i的地址(再次提醒包括两个),而*p的值=i的值,于是通过这两种方式都可以实现指向操作,比如大小排序,①前者可以互换指针变量即是说交换了彼此指针变量的内容也就是各自指向的地址,比如p1指向a的地址,p2指向b的地址,此时交换之后,p1指向b的地址,p2指向a的地址,所以各自加上星号的值就当与两个数交换了,不需要借助中间变量t,注意此时a和b各自的内容也即是各自的数值不变,只是p1和p2指向变了而已。②后者可以直接交换各自数值,就是说p1的p2的内容不变,但是通过指针间接交换a和b的值(*p1与*p2交换),于是虽然p1和p2指向方向不变,但是指向的a和b的值已经改变了,于是说,也相当于两个数值交换了。
函数的调用可以得到一个返回值,而使用指针变量作为参数,可以得到多个变化了的值,比如两个指向的指针变量p1和p2都发生了变化,这在普通函数中是难以做到的,要善于利用指针
int a[10] = {1,3,5,7,9};
int *p = &a[0];
int *p=a;//上面两行语句等价
*(p+1)的意思是指p指向数组中下一个元素,但是对于p指向的地址(再次强调包括两个)来说,它加4个字节(int型数组),系统怎么知道加几个字节呢?答:根据你定义指针p的基类型int *来判断
a[2]中[]其实是变址运算符(我还是真的第一次知道,哈哈长见识了)
fun(int arr[],int n);
fun(int *arr,int n);//以上两行语句的等价,用数组名作函数参数会改变原有值
fun(int arr,int n);//这句话语法上没有错误,但是你定义了一个新的整型形参arr想干嘛?
char *string = "wu fang fang";
char string[] = "wu fang fang";
上面两句话功能差不多,有细微差别,前者中string指向字符串中第一个字符的地址,string是指向字符型的指针变量(没有字符串类型),后者中使用的字符数组=字符型数组来存储字符串,string是字符数组名,它也=数组中第一个字符的地址,所以某一方面来说,上面两句话等价
char string[13];
string[] = "wu fang fang";//这种写法错误,虽然看上去很正常,但是这样会出错
string[13] = "wu fang fang";//这样错得更加离谱,第一下表=索引已经越界了,第二字符串直接赋给一个数组中成员=字符型变量,这可能吗?显然不可能
char string[13];
string = "wu fang fang";//这是可以滴
char *string;
string = "wu fang fang";//这是正确滴
char *a;
scanf("%s",a);//这样不会出现eror,但是这种会警告,很危险,有可能a指向了程序内存中某一个很重要的数据,此时你输入字符串就改变了这个数据,进而破坏系统,损坏数据时你还不知道
//可以通过 *(string+1),像引用指针数组一样去引用字符串中的某一个字符,也就是说,引用数组元素可以用“下标法”或者“地址法”,这些方法同样适用于字符指针string引用字符串
char *format;
format = "a=%d,b=%c\n";
printf(format,a,b);//这三句话是不是很六?
struct Student
{
int num;
char name[20];
char sex;
int age;
float score;
}student1,student2;
以上结构体当中,struct是关键字,Student中S大写是习惯,不是程序规定
(Student=结构体名=结构体标记)+(struct=关键字)=结构体类型
可以定义结构体类型的变量=结构体变量名=student1或者student2
.在所有运算符中优先级最高
结构体变量名.成员名,也可以结构体变量名.(成员名=另一结构体变量名).另一成员
5、结构体变量与结构体指针
用结构体变量和结构体变量的指针作函数参数
struct Student *pt;//pt可以指向struct Student类型的变量或者数组元素
pt=&student1;
student1.成员名=(*pt).成员名=pt->成员名
#include <stdio.h>
#define N 3
struct Student
{
int num;
char name[20];
float score[3];
float aver;
}
int main()
{
void input(struct Student stu[]);
struct Student max(struct Student stu[]);
void print(struct Student stu);
struct Student stu[N],*p=stu;//定义struct Student类型结构体数组stu,指向这个结构体数组的指针变量p,其指向数组中第一个成员的地址=&stu[0]=stu,所以跟数组指针一样,*stu=stu[0]
input(p);//实参是结构体数组指针p
print(max(p));// max(p)的解释与下面一样,
return 0;
}
//注意这里是形参stu,p的指向进来,使得p的数值=主函数中stu结构体数组中成员的第一个地址=&主函数stu[0]=stu,使得这个p的值给了这个临时的动态存储结构体数组stu中成员第一个地址,使得这个stu的起始地址=主函数中stu的起始地址,实参是结构体数组指针p,形参是结构体数组名stu不等于上面主函数定义的stu,并且形参不可写成struct Student stu,你想想这是啥了?这是结构体变量了,跟指针八竿子打不着,不知道能不能写成struct Student stu[数字]?(就暂且认为没有这种说法吧20210205)(自我感觉和struct Student stu一个意思,只是它带有长度了而已)
void input(struct Student stu[])
{
}
struct Student max(struct Student stu[])//这个函数返回值=结构体类型数据
{
}
void print(struct Student stud)//这个stud没有写错,形参是结构体类型变量名stud
{
}
❤🧡💛 1. 结构体一级指针与结构体二级指针(高阶补充)
注:这是我随便找的一个demo代码,具体干什么不用管,了解其中的语法知识即可
/* 定义一个struct MultiTimerHandle类型的结构体 */
struct MultiTimerHandle
{
MultiTimer* next;
uint64_t deadline;
//MultiTimerCallback_t callback;
void* userData;
};
typedef struct MultiTimerHandle MultiTimer;//给struct MultiTimerHandle结构体类型起了个别名MultiTimer
/* 定义一个MultiTimer类型的结构体(一级)指针timerList */
static MultiTimer* timerList = NULL;
MultiTimer** nextTimer = &timerList;
//MultiTimer类型的结构体二级指针nextTimer、MultiTimer类型的结构体一级指针timerList
//一级指针timerList指向MultiTimer类型的结构体、二级指针nextTimer指向一级指针timerList
//nextTimer==一级指针地址==&timerList≠一级指针的内容,因为一级指针内容是地址,而是一级指针自身在存储空间的地址
//*timerList==MultiTimer类型的结构体
//**nextTimer==MultiTimer类型的结构体==*timerList
//*nextTimer==MultiTimer类型的结构体(首)地址==一级指针timerList的内容
//MultiTimer类型的结构体二级指针nextTimer、MultiTimer类型的结构体一级指针timerList
//一级指针timerList指向MultiTimer类型的结构体、二级指针nextTimer指向一级指针timerList
//nextTimer=一级指针地址=&timerList≠一级指针的内容,因为一级指针内容是地址,而是一级指针自身在存储空间的地址
//*timerList=MultiTimer类型的结构体
//**nextTimer=MultiTimer类型的结构体=*timerList
//*nextTimer=MultiTimer类型的结构体(首)地址=一级指针timerList的内容
timerList是结构体一级指针,timerList->deadline可以获取结构体成员的值,(*timerList).deadline效果和timerList->deadline一样
nextTimer 是结构体二级指针,(*nextTimer )->deadline可以获取结构体成员的值,(**nextTimer ).deadline效果和(*nextTimer )->deadline一样
6、指向函数的指针与指向函数返回值的指针
指向函数的指针
函数名=函数的起始地址=函数的入口地址(调用函数时,从函数名得到函数的起始地址,并执行代码)
int (*p)(int,int);//定义了一个指向函数的指针变量p,它指向的是整型且有两个整型参数(形参)的函数(指向函数的地址)
//int *p(int,int);等于int *(p(int,int));//()的优先级高于指针运算符*,这里定义的是指向函数返回值(有可能是int型或char型或float型)的整型指针变量p(指向变量的地址)
p=max;//将整型且有两个整型参数的函数的入门地址=起始地址赋给p,使得p指向函数起始地址,注意只需要将函数名max赋给p即可,不能将p=max(a,b);,对指向函数的指针变量不能进行算术运算,如++或者--操作
int max(int,int)
{
}
书中【例8.23】中一个程序例子,就是使用指针变量来选择使用哪个函数,首先scanf输入a和b的值,再scanf输入n值来选择a还是b,通过if和else if语句来通过a还是b来判断指针变量p指向哪个函数的起始地址,进而实现不同函数的调用,但是其实也可以利用switch语句来做,也可以使用简单的if判断,书中说这样使程序更简洁和专业(反正我没看出来哈哈)
❤🧡💛 1. 指向函数的指针的 typedef 用法(高阶补充)
注:代码是别人的,注释是我写的
typedef int (*pFunc_t)(char *frame, int len);//定义了一个指向函数的指针类型pFunc_t
//它指向的是整型且有一个字符指针参数,一个整型参数(形参)的函数(指向函数的地址)
int read_voltage(char *data, int len)
{
int voltage = 0;
//其他功能代码
return voltage;
}
int main(void)
{
pFunc_t pHandler = read_voltage;//定义了一个pFunc_t指向函数的指针类型的指针变量pHandler
//read_voltage是函数名=函数的入口地址=地址,它看上去比下面的数组指针的指针二级指针要容易理解
return 0;
}
typedef void (*lp) ( ); /* 定义一个无参数、无返回类型的 */
/* 函数指针类型 */
lp lpReset = (lp)0xF000FFF0; /* 定义一个函数指针,指向*/
/* CPU启动后所执行第一条指令的位置 */
lpReset(); /* 调用函数 */
解释typedef void (*lp) ( ); 这句话,如果没有typedef的话,就是void (*lp) ( );,定义的是函数指针变量lp,lp指向的是(void返回值,输入参数为空)类型的函数,函数名字作为地址赋给lp,但是加了typedef之后,lp变成了指向空返回值空输入参数函数的函数指针类型,注意它是类型,于是lpReset才是函数指针变量,于是lpReset()就是一个地址为(lp)0xF000FFF0的函数,这个函数无形参无返回值,比如
void lpReset()
{
}
以下为转载
函数指针
首先要理解以下三个问题:
(1)C语言中函数名直接对应于函数生成的指令代码在内存中的地址,因此函数名可以直接赋给指向函数的指针;
(2)调用函数实际上等同于"调转指令+参数传递处理+回归位置入栈",本质上最核心的操作是将函数生成的目标代码的首地址赋给CPU的PC寄存器;
(3)因为函数调用的本质是跳转到某一个地址单元的去执行,所以可以"调用"一个根本就不存在的函数实体,晕?请往下看:
请拿出你可以获得的任何一本大学《原理》教材,书中讲到,186 CPU启动后跳转至绝对地址0xFFFF0(对应C语言指针是0xF000FFF0,0xF000为段地址,0xFFF0为段内偏移)执行,请看下面的代码:
typedef void (*lp) ( ); /* 定义一个无参数、无返回类型的 */ /* 函数指针类型 */
lp lpReset = (lp)0xF000FFF0; /* 定义一个函数指针,指向*/ /* CPU启动后所执行第一条指令的位置 */
lpReset(); /* 调用函数 */
在以上的程序中,我们根本没有看到任何一个函数实体,但是我们却执行了这样的函数调用:lpReset(),它实际上起到了"软重启"的作用,跳转到CPU启动后第一条要执行的指令的位置。记住:函数无它,唯指令集合耳;你可以调用一个没有函数体的函数,本质上只是换一个地址开始执行指令!
7、指针作为函数参数
用指向函数的指针作函数参数(因为指针变量存储的是函数的入口地址,那么将这个指针变量作为参数传入另一个函数,那么这另一个函数不就可以间接调用这个函数了吗)
void fun(int (* x1)(int),int(* x2(int,int))
{
int a,b,i=3,j=5;
a=(* x1)(i);
b=(* x2)(I,j);
}
//下面我来解释上面这个函数,就是很简单的再fun函数里通过两个不同类型的入口形参指针变量x1和x2来进行调用两个返回值都为int类型的函数,并且将返回值一次返回给a和b,那么有人会问,直接在fun函数里面引用这两个函数不就行了吗?那就想法太简单了,你想想指针的用法太灵活了,这个fun函数很灵活,可以通过入口参数来选择调用不用的函数,你直接调用函数不就固定调用了吗,也有人说可以在fun函数中选择入口参数,通过if来判断选择调用哪个函数,第一就是你要写多少个if语句?如果几百个函数供if选择呢?第二指针的速度也很快(运用这种思路可以编写出较为复杂的程序,比如求定积分函数)
【例8.24】与上面的【例8.23】前者是调用不用的实参传入fun的形参进而选择调用不同的函数,后者是通过if语句来选择将指针变量p赋给不同的函数入口地址,都可以实现指针调用不同的函数,书中只是前者可以编写求定积分函数,后者没有说明
返回指针值的函数,具体可看例子【例8.25】,不难,看懂了上面的讲解,这个程序很容易就看懂了
8、指针数组与数组指针
指针数组和多重指针
指针数组与数组指针:
int a[10] = {1,3,5,7,9};
int *p = &a[0];
int *p=a;//上面两行语句等价
int (*p1)[4];//这是定义了一个指向包含4个元素的一维数组的指针变量p1
上面就是数组指针=定义了一个指针变量=变量,它的内容是地址=指针=指向的一维数组的首地址
int *p[4];//注意与int (*p1)[4];的区别
上面就是指针数组=定义了一个指针数组=数组,它的内容是指针=地址,它的每个成员都是一个指针变量=数组的每个成员都是指向某个一维数组的首地址
❤🧡💛 1. 数组指针的 typedef 用法(高阶补充)
注:代码是别人的,注释是我写的
#include <stdio.h>
typedef int (*PTR_TO_ARRAY)[3];//数组指针=指针=定义了一个指向3个成员的一维数组指针类型=数据类型,类似于int型,char型
//相当于定义了一个...的数据类型,然后再用这个定义一个这种...数据类型的指针变量=指向地址的地址=二级指针
int main()
{
Int I;
Int temp[3]={1,2,3};
PTR_TO_ARRAY ptr_to_array;//定义了一个PTR_TO_ARRAY数组指针类型的指针ptr_to_array
ptr_to_array = &temp;//ptr_to_array可以理解为指针的指针,因为&temp是数组首地址的地址
for(i+0;i<3;i++)
{
printf("%d\n",(*ptr_to_array)[i]);//(*ptr_to_array)=temp
}
return 0;
}
书本上【例8.27】就很容易看懂了,借此可以知道指针数组的用途及优点,此外还有指针的指针=多重指针,具体可看书【例8.28】
实际上main函数是有参数的,但是在命令行操作下,需要用到main的入口参数
int main(int argc,char *argv[])
{
//Code
}
//第一个参数必须是int型=形参的个数,第二个参数必须是字符指针数组=用来接收从操作系统命令行中的一个字符串的首字符=dos命令行==unix命令行=linux命令行=命令名(包括盘符、路径)参数1,参数2,···参数n,这一部分不难很少,具体去看书
9、动态内存与指针变量
动态内存分配与指向它的指针变量
栈=一般的内存存储空间=静态存储和动态存储,比如全局变量,局部变量,变量,数组等=想象成客栈,永久住或者临时住
堆=存放临时用的数据,此数据不需要函数声明,也不跟随程序结束时自动释放,随用随存,随不用随释放,动态分配,由于没有在程序中声明这些变量或者数组,所以只能通过指针来引用这些数据,不能通过变量名或者数组名来引用这些数据=想象成杂物往地上一堆,随时可以堆在地上
1malloc,2calloc,3free,4realloc四个库函数可以实现对内存的动态分配
1中是开辟动态存储区,未成功执行返回空指针(NULL)
2中是开辟动态存储区,未成功执行返回空指针(NULL)
3中是重新分配动态存储区,未成功执行返回空指针(NULL)
4中是释放动态存储区,函数无返回值
另外注意这123函数都是(4函数无返回值)=返回指针的函数=指向函数返回值的指针,它们类型都是void类型=空类型=不确定指向的类型,最初的C语言不是void类型,为什么要这么做?具体可看书,这一块不是很难,以前看不懂,现在忽然全部明白了(这种指针只提供一个“纯地址”,而不指向任何类型数据,因此想用这个指针来获取数据是枉然的)
int *pt;
pt=(int *)mcalloc(100);//标准,所以我们要在前面加上(int *)强制类型转换,明白了吗?
int a=3;
int *p1=&a;//正确,定义指向整形变量a的指针变量p1
int *p3=(void *)p1;//正确,定义空类型(不指向)的指针变量p3
p3=&a;//错误,p3是无指向类型的指针变量,不能指向a
int *p2=(int *)p3;//正确,将p3的值=纯地址,变成整型,但是它仍然不指向
p2=&a;//正确,此时使上面的p2指针变量指向a
ASCII文件=文本文件(一个字符对应一个字节)!=二进制文件(不是一个字符占用一个字节=内存中的数据存储方式),磁盘中的字符数据用ASCII形式存储,数值型数据两种存储方式都可以,但是二进制文件速度更快=内存中的数据存储方式
枚举元素=枚举常量(不能对它赋值)=整数(枚举类型=系统默认是整型)(可以对它printf输出)
枚举变量(只能将枚举常量=整数,赋给枚举变量,不可以将其他值赋给枚举变量),使用枚举变量的好处是比较直观
···至此,我的C语言,算是小告一个段落了···20210205下午14:45于凡尔
【补充】谭浩强第三版
补充(第三版书籍):
void main()
{
//Code
}
中,main是函数的名字,表示主函数,void表示此函数是“空类型”,即执行该函数后不会返回一个函数值
算法(对操作的描述)+数据结构(对数据的描述)=程序
变量代表内存中具有特定属性的一个存储单元,它用来存放数据=数值,变量名!=变量值,变量名实际上代表了一个存储单元的地址,计算机通过该变量名寻找到这个地址,取出这个地址单元里面的数据
实际上,数值是以补码表示的,一个正整数的补码和该数的原码(就是该数的二进制形式)相同,如果是负整数,就比较复杂,这里不多赘述
[signed] short [int];
unsigned short [int];
[signed] long [int];
unsigned long [int];
C语言规定,long型不短于int型,short型不长于int型
一个16位有符号整型变量,表示数值范围-32768~32767,所以32767加1会发生溢出,产生新的数值为-32768
计算机中,浮点型数据中,字节位数拆分为,数符位,小数部分位,指数位,其中小数部分位(bit)越多则越精确,指数位(bit)越多则数值越大
float 32位
double 64位
long double 128位(这种用得很少)
不同类型的整形数据可以进行算术运算,比如int可以和unsigned int相加
···············································································
#include <stdio.h>
int main(int argc, char *argv[])
{
float p = 5.1f;
int f = (int)(p*100);
printf("%d", f);
getch();
return 0;
}
【补充】一些小知识总结
❤🧡💛1. C语言代码运行过程、内存存储方式、栈的讲解
1)预处理: 宏定义展开、头文件展开、条件编译,这里并不会检查语法
2)编译:检查语法,将预处理后文件编译生成汇编文件
3)汇编:将汇文件生成目标文件(二进制文件)
4)链接:将目标文件链接为可执行程序

代码运行前:上面是linux系统下gcc编译器编译后的二进制文件
全局初始化数据区/静态数据区( data 段):该区包含了在程序中明确被初始化的全局变量、已经初始化的静态变量( 包括全局静态变量和局部静态变量)和常量数据(如字符串常量)
未初始化数据区(又叫 bss 区):存入的是全局未初始化变量和未初始化静态变量。未初始化数据区的数据在程序开始执行之前被内核初始化为 0 或者空(NULL)。
代码运行前:这个是大名鼎鼎的keil编译器编译的单片机程序,也是可以看出分区,大同小异
综合来看的话,代码编译或者代码运行,内存都笼统分为数据区和代码区,代码区只读是指令,数据区可读可写存储数据,在程序运行之后数据区多了一些概念如“堆”“栈”
如何简单地类比记住堆和栈的区别呢?拿我们熟悉的事物来记忆,局部变量存在栈里面,局部变量是啥?函数执行完自动销毁,因此栈就是实时加载和释放,那为什么栈是先入后出呢?你想一想当调用一个临时函数执行完之后肯定要回到调用函数前的地址开始继续从调用之前的程序地址处运行,所以一定是先入后出
堆跟malloc函数有关,所以,一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
//以下截图自《黑马程序员》






//以上截图自《黑马程序员》
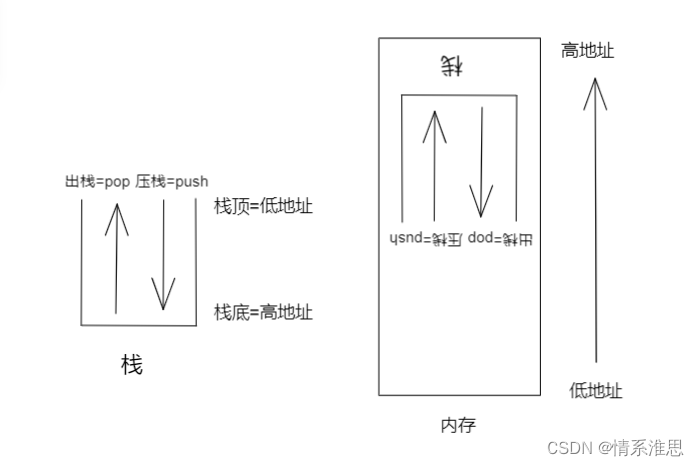
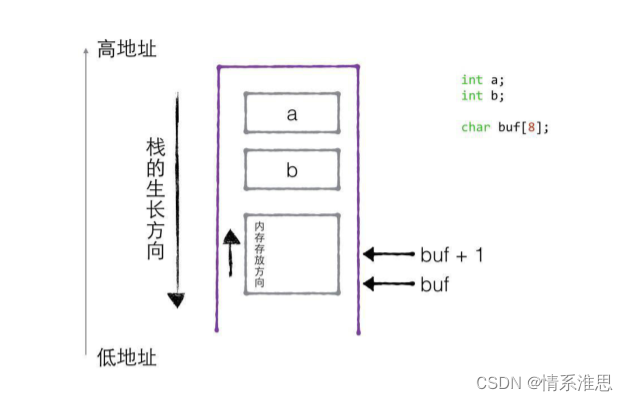
这是我自己画的图,首先内存不是栈,内存>栈,栈存储局部变量,内存存储的东西多了去了,内存地址就是由低到高,学过单片机的都知道程序是从0x0000000地址开始执行,然后跳到执行main函数的向量表,而栈的pop是高地址到低地址,push是低地址到高地址,栈的增长方向是从高地址到低地址(因为第一个数据存在栈底),栈的这种特特性想放在内存里面匹配,那么它一定是颠倒过来的
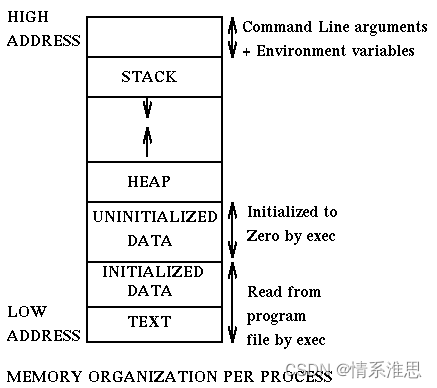
上面这张图很牛逼,详情请看博客链接 进程中栈向下增长的原因?
【转载】浮点数的存储方式
我想要输出510,可是机器却输出509,如果改为5.5则一切正常,为什么?首先,flaot类型数据为32位=4字节,从左向右依次是,符号位(1),小数点后数字位=有效数字位=尾数位(8),指数位=阶码位(23),基数=2(十进制位10),所以1+8+23=32位。
5 = 101 (2进制)
0.1 = 0.0 0011 0011 0011 0011 0011 0011 …(无限循环)
因此,5.1 = 101.0 0011 0011 0011 0011 0011 0011 0011 0011 …
二进制计数,5.1= 1.010 0011 0011 0011 0011 0011 0011 0011 0011 0011… × 2^2
二进制科学计数法中基数=2,十进制科学计数法中基数=10,这很小学,因为科学计数法中,第一位都是1,于是为了增加精确度,节省32位位数资源,我们不存储这个1,计算机就默认科学计数法中第一个数为1,于是此时可以节省一个bit为来存储数据。
我们日常表示都是十进制数据,比如5.1,但是计算机只认识0和1,你还不能以二进制形式=101.0 0011 0011 0011 0011 0011 0011 0011 0011 … ,存在计算机中,你必须用二进制科学计数法=1.010 0011 0011 0011 0011 0011 0011 0011 0011 0011… × 2^2存储在计算机中,比如上面中,如果忽略第一位1,那么就是010 0011 0011 0011 0011 0011 0011 0011 0011 0011… * 2^2取23位得到 0100 0110 0110 0110 0110 011,此时这个23位就是小数部分=尾数部分,那么符号位就是0=正,那么还剩下8位=指数位=阶码位=2,基数=2,那么此时应该注意不是0000 0010,而是根据规定,指数统一+127再转换为无符号8位2进制数,也就是2+127=129=1000 0001,所以上面完成的32位就是0(符号)+10000001(指数,阶码)+0100011001100110011(尾数,小数)。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
//library
{
float a=5.1;
int *i=&a;
printf("%x", *i);
System ("pause");/* 将PAUSE送到system command line去执行 */
return 0;
}
40a33333
0100 0000 1010 0011 0011 0011 0011 0011
得出的结果确实如上述所分析
那既然一切都通顺了,我们再来分析为啥510会变成509了,首先计算机遇到0100 0000 1010 0011 0011 0011 0011 0011这一串数字,它先看到第一位0知道它是正数,再看1000 0001,算出指数为2,它知道了指数是2^2,那么它再看到010 0011 0011 0011 0011 001这一串数字是23位,它知道了是小数=尾数部分,然后它自动在前面加上1(二进制科学计数法中的1),然后它知道了真实情况是1.010 0011 0011 0011 0011 001×2^2=101.0 0011 0011 0011 0011 001,于是想办法从二进制转成十进制啊,然后101很显然=5(十进制)0.00011 0011 0011 0011 001=多少呢?反正公式我也忘记了,我借助计算机算了一下0.00011001100110011001100110011(二进制) = 0.0999999996274709(十进制),于是计算机知道了这个数字=5.0999999996274709,于是*100=509,所以明白了为啥是509了吧,就是这么简单
//下面一部分,我是直接复制粘贴的,上面也是这个人写的,不过我以自己思路复述一遍
无奈吧,这个时候想要精确的浮点数的话, 只有自己写高精度算法了。
-----------------------------------------------------------------------------------
乘数、被乘数都要先转化为二进制,二进制的乘法远比十进制简单,比如乘数是1011,只需将将被乘数分别左移3位、1位,移动后补入0,并将这三个数(被乘数左移3位的、被乘数左移1位的及未移位的被乘数)在累加器中相加,所得总和就是积,根据需要积可再转化为十进制。
除法与乘法类似,只不过将左移改为右移,加改成减。实际上减也是通过取补码后再加,因此计算机芯片上的累加器是最繁忙的部分
-------------------------------------------------------------------------------------
IEEE 754 用科学记数法以底数为 2 的小数来表示浮点数。IEEE 浮点数用 1 位表示数字的符号,用 8 位来表示指数,用 23 位来表示尾数,即小数部分。作为有符号整数的指数可以有正负之分。小数部分用二进制(底数 2)小数来表示,这意味着最高位对应着值 ?(2 -1),第二位对应着 ?(2 -2),依此类推。对于双精度浮点数,用 11 位表示指数,52 位表示尾数。
【转载】C语言的面向对象编程
/* 按下OK键 */
void onOkKey()
{
/* 判断在什么焦点菜单上按下Ok键,调用相应处理函数 */
Switch(currentFocus)
{
case MENU1:
menu1OnOk();
break;
case MENU2:
menu2OnOk();
break;
…
}
}
/* 按下Cancel键 */
void onCancelKey()
{
/* 判断在什么焦点菜单上按下Cancel键,调用相应处理函数 */
Switch(currentFocus)
{
case MENU1:
menu1OnCancel();
break;
case MENU2:
menu2OnCancel();
break;
…
}
}
可以理解为MENU1按键在两种情况下会进入OK函数或者Cancel函数,这样的缺点是啥?
1、onOkKey()函数,看着不美观,也不易读,代码很长
2、如果需要增加功能,还要每个函数都要增加或者删除case,这很麻烦
/* 将菜单的属性和操作"封装"在一起 */
typedef struct tagSysMenu
{
char *text; /* 菜单的文本 */
BYTE xPos; /* 菜单在LCD上的x坐标 */
BYTE yPos; /* 菜单在LCD上的y坐标 */
void (*onOkFun)(); /* 在该菜单上按下ok键的处理函数指针 */
void (*onCancelFun)(); /* 在该菜单上按下cancel键的处理函数指针 */
}SysMenu, *LPSysMenu;
static SysMenu menu[MENU_NUM] =
{
{
"menu1", 0, 48, menu1OnOk, menu1OnCancel
}
,
{
" menu2", 7, 48, menu2OnOk, menu2OnCancel
}
,
{
" menu3", 7, 48, menu3OnOk, menu3OnCancel
}
,
{
" menu4", 7, 48, menu4OnOk, menu4OnCancel
}
//…
};
/* 按下OK键 */
void onOkKey()
{
menu[currentFocusMenu].onOkFun();
}
/* 按下Cancel键 */
void onCancelKey()
{
menu[currentFocusMenu].onCancelFun();
}
换成了这样,这样的好处是什么?
1、onOkKey()函数变少了,见名之意,它调用了onOkFun()函数
2、其实我也没看出哪里好了?可能我写的代码还是太少了
















 5102
5102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









