







 本文提出了EmotiCon,一个基于学习的算法,用于视频和图像中情境感知的人类情绪识别。受心理学中的弗雷格语境原则启发,EmotiCon结合了对情感识别的三种解释:多种模式(如面部和步态)、背景视觉信息和社会动力学互动。实验表明,EmotiCon在EMOTIC数据集上实现了35.48的平均精度,比之前的方法提高了7-8分。此外,还介绍了一个新的数据集GroupWalk,包含45个视频,用于多人情感识别。
本文提出了EmotiCon,一个基于学习的算法,用于视频和图像中情境感知的人类情绪识别。受心理学中的弗雷格语境原则启发,EmotiCon结合了对情感识别的三种解释:多种模式(如面部和步态)、背景视觉信息和社会动力学互动。实验表明,EmotiCon在EMOTIC数据集上实现了35.48的平均精度,比之前的方法提高了7-8分。此外,还介绍了一个新的数据集GroupWalk,包含45个视频,用于多人情感识别。
情绪识别论文:EmotiCon: Context-Aware Multimodal Emotion Recognition using Frege’s Principle
论文地址:https://arxiv.org/pdf/2003.06692.pdf
目录
2.1. 多模态情绪识别Uni/Multimodal Emotion Recognition
2.2. 心理学研究中的情景感知情绪识别Context-Aware Emotion Recognition in Psychology Research
2.3.情境感知的情感识别Context-Aware Emotion Recognition
2.4. 情境感知的情感识别数据集Context-Aware Emotion Recognition Datasets
3.1. 记号和概述Notation and Overview
3.2. 情景一Context 1: Multiple Modalities
3.3. 情景二Context 2: Situational/Background Context
3.4. 情景三Context 3: Inter-Agent Interactions/SocioDynamic Context
4. 网络结构和实施细节Network Architecture and Implementation Details
6. 实验和结果Experiments and Results
6.2. Evaluation Metrics and Methods
7. 结论、局限性和未来工作Conclusion, Limitations, and Future Work

摘要Abstract
我们提出了EmotiCon,一个基于学习的算法,用于语境感知的视频和图像中感知人类情绪的算法。受心理学中弗雷格语境原则的启发,我们的方法结合了对情感识别语境的三种解释。我们的第一种解释是基于使用多种模式(如面孔和步态)进行情感识别。对于第二种解释,我们从输入图像中收集语义背景并使用一个基于自我注意的CNN来编码这些信息。最后,我们使用深度图来模拟与社会动态互动和代理人之间的接近有关的第三种解释。我们通过在EMOTIC(一个基准数据集)上的实验来证明我们网络的效率。在26个类别中,平均精度(AP)为35.48分,这比之前的方法提高了7-8分。我们还介绍了一个新的数据集--GroupWalk,它是是一个在多个真实世界环境中拍摄的人们行走的视频集合。我们报告了GroupWalk的4个类别的AP值为65.83,这也是对先前方法的一个改进。
1. 介绍Introduction
在日常生活中,感知我们周围人的情绪是至关重要的。人类在与他人互动时,经常根据他们感知到的情绪来改变自己的行为。特别是,自动情绪识别已经被用于不同的应用,包括人机交互[13]、监控[12]、机器人技术、游戏、娱乐,以及更多。情绪被建模为离散的类别或情感维度的连续空间中的点[16]。在连续空间中,情绪被视为价值、唤醒和支配的三维空间中的点。在这项工作中,我们的重点是识别感知到的人类情绪,而不是一个人在离散情绪空间中的实际情绪状态。
情感识别的最初工作大多是单模态[46, 1, 47, 44]方法。我们使用多种模态(语境1)的人脸和步态、背景视觉信息(语境2)和社会动力学的代理人之间的互动(语境3)来推断出感知的情感。EmotiCon的性能优于先前的情境感知情绪识别方法。以上是EMOTIC数据集的一个输入样本。
数据集的输入样本。这可能对应于面部表情、声音、文字、身体姿势、步态或生理信号。此后,又有多模态情感识别[49, 21, 50],其中各种模态的组合被使用,并以不同的方式组合在一起以推断情感。尽管从一个人身上提取的这些模式或线索可以为我们提供关于感知到的情感,但语境在理解所感知的情感方面也起着非常关键的作用。弗雷格的语境原则[45]敦促我们不要孤立地询问一个词的含义,而要在句子的语境中寻找其含义。我们在心理学中使用了语境原则背后的这一概念在心理学中用于情感识别。"语境 "已经被心理学研究者以多种方式进行解释。 包括:
(a) 情境1(多种模式): 融合不同模式的线索是情境的最初定义之一。这个领域也被称为多模态情感识别。结合各种模式可以提供互补的信息,从而导致更好的推断,并且在野外的数据集上表现得更好。
(b)情景2(背景感知):从图像中的视觉线索对场景进行语义理解,有助于深入了解代理人的周围环境和活动,这两者都会影响代理人的感知的情绪状态。
(c)情景3(社会动态的代理间互动)。心理学研究者认为,其他代理人的存在或不存在都会影响到代理人的感知情绪状态。当其他代理共享一个身份或被代理人所认识时,他们经常协调他们的行为。当其他代理人是陌生人时,情况就不同了。这种互动和与其他代理的接近性在感知情绪识别方面的探索较少。
我们的目标之一是使情感识别系统在现实生活场景中发挥作用。这意味着要使用不需要复杂设备就能捕捉到的模式而且是现成的。心理学研究者[3]已经通过混合脸部和身体特征进行实验,发现参与者会猜测与身体特征相匹配的情绪。这也是因为 "嘲弄 "一个人的面部表情很容易。随后,研究人员[25,38]发现面部和身体特征的结合是推断人类情绪的可靠措施。因此,将这种脸部和身体的特征结合起来用于基于情境的情绪识别是非常有用的。
主要贡献。我们提出了EmotiCon,这是一个语境软件的情感识别模型。EmotiCon的输入是图像/视频帧,输出是一个多标签的情感分类。我们的工作的创新部分包括:
1. 我们提出了一个上下文感知的多模态情感识别算法,称为EmotiCon识别算法,与Ferge的语境原则一致,在这项工作中,我们试图结合对上下文的三种解释来执行情感识别的视频和图像。
2. 我们还提出了一种新的方法,使用基于深度的CNN对代理人之间的社会动力学互动进行建模。我们计算了图像的深度图并将其反馈给网络,以了解代理人之间的接近程度。
3. 尽管可以扩展到任何数量的模式,我们还是发布了一个新的数据集GroupWalk。据我们所知,目前很少有在不受控制的情况下捕获的数据集。这些数据集是在不受控制的环境中捕获的,其中包括面部和步态都有情绪标签注释的数据集。为了促进这一领域的研究,我们将GroupWalk公开提供了情感注释。GroupWalk是一个由45个视频组成的集合,这些视频是在多个真实世界的环境中拍摄的人们在密集的人群中行走的视频。这些视频有大约3544个代理人,并对他们的情绪标签进行了注释。
我们通过测试我们的工作与之前的方法EMOTIC[28]上测试了我们的性能,EMOTIC是一个基准数据集。我们报告在EMOTIC上的AP得分提高到35.48,比之前的方法[27, 30, 58]提高了7-8。我们
我们还报告了我们的方法和之前的方法在新的数据集GroupWalk上的AP得分。我们在两个数据集上都进行了消融实验,以证明对EmotiCon的三个组成部分的需要。根据EMOTIC提供的注释在EMOTIC中,我们对26个离散情感标签进行了多标签分类。在GroupWalk上,我们也进行了
对4种离散的情绪进行多标签分类(愤怒、快乐、中立、悲伤)。
2. 相关工作Related Work
在这一节中,我们简要介绍了以前关于单模态和多模态情感识别的工作,语境感知的情感识别,以及现有的语境识别数据集。
2.1. 多模态情绪识别Uni/Multimodal Emotion Recognition
以前的情感识别工作是通过手工制作的特征[48, 60]或深度学习网络[32, 17, 31]来进行情感识别的工作。使用单一模式,如面部表情[46, 1]、声音。和语言表达[47]、身体手势[42]、步态[44]和生理信号,如呼吸和心脏提示[26]。这种模式已经发生了转变,研究人员试图融合多种模式来进行
情感识别,也被称为多模态情感识别。融合方法如早期融合[49]、后期融合[21]和混合融合[50]已经被探索用于融合[21]和混合融合[50]等方法已被探索用于多模态的情感识别。多模态情感识别已经被心理学的研究所推动,并且也有助于提高野外情感识别数据集的准确性,如IEMOCAP[9]和
cmu-mosei [57]。
2.2. 心理学研究中的情景感知情绪识别Context-Aware Emotion Recognition in Psychology Research
虽然是在语言哲学领域提出的,但弗雷格[45]提出,词语不应该被孤立地看待,而应该在其命题的背景下看待。孤立地看,而应该在其命题的背景下看。心理学研究者[6, 29, 37]也同意,就像大多数心理过程一样,情绪过程不可能是一个单独的过程。大多数心理过程一样,情绪过程不能解释,没有背景。他们认为,语境往往会产生情绪,也会形成对情绪的感知方式。涉及情境的情感文献[2, 5, 39]提出了情境特征的几大类:人、情境和背景。Martinez等人al. [36]对情境的必要性进行了实验。并发现,即使在无声的视频中,参与者的脸和身体被遮住,观众也能成功地推断出情感的成功。Greenway等人[20]将这些语境特征分为三个层次,从微观层面(个人)到宏观层面(文化)。在第二层次(情景)中,他们包括像其他代理人的存在和亲近的因素。研究表明,仅仅是他人的存在研究表明,与人们独处的情况相比,另一个人的存在会引起更多的情绪表达[54, 24]。这些表达当人们相互认识并且不是陌生人[24]时,这些表达会被放大。
2.3.情境感知的情感识别Context-Aware Emotion Recognition
最近在情境感知的情感识别方面的工作是基于深度学习网络架构。Kosti等人等人。[27]和Lee等人[30]介绍了在情境感知情感识别方面的两个最新进展。他们提出了类似的架构。他们都有两个流的架构,然后是一个融合网络。一个流集中在一种模式([30]为面部,[27]为身体),另一种模式
着重于捕捉上下文。Lee等人[30]认为除人脸以外的所有东西都是上下文,因此将人脸从图像中掩盖起来,并将其送入融合网络。因此,从图像中掩盖了脸部,以提供给上下文流。另一方面,[30]使用区域提议网络(RPN)来从图像中提取情境元素。这些元素成为情感图的节点,被送入图形卷积网络(GCN)来编码情境。另一个被关注的问题是群体情感识别[19, 53]。这里的目标是标记
在假设他们都有一些社会身份的情况下,为画面中的所有人的情绪贴上标签。假设他们都有一些社会身份。
2.4. 情境感知的情感识别数据集Context-Aware Emotion Recognition Datasets
过去的大多数情感识别数据集要么只关注单一的模式,如人脸。要么只关注单一的模式,例如脸部或身体特征,或者是在受控环境下收集的。例如,GENKI数据库[52]和UCDSEE数据集[51]是主要关注在实验室环境中收集的采集的面部表情。情感在野外识别(EmotiW)的挑战[14]中,有三个数据库。AFEW数据集[15](从电视节目和电影中收集的节目和电影),SFEW(AFEW的一个子集,只有脸部的注释)和SFEW(AFEW的一个子集,只有脸部的注释),以及HAPPEI数据库,该数据库专注于群体层面的情感估计问题。最近的一些工作已经意识到了使用情境进行情感识别的潜力,并强调了最近的一些工作已经意识到使用情境进行情感识别的潜力,并强调了突出了这种数据集的缺乏。情境感知情绪识别(CAER)数据集[58]是一个来自电视节目的视频片段集合,其中有7个离散的情绪。EMOTIC数据集[27]是一个来自数据集的图像集合,MSCOCO[34]ADE20K[61]以及从网络搜索中下载的图像。该数据集是一个包含23,571张图片,其中约有34,320人被注释为26个离散情绪类别。我们在表1中总结和比较了所有这些数据集。
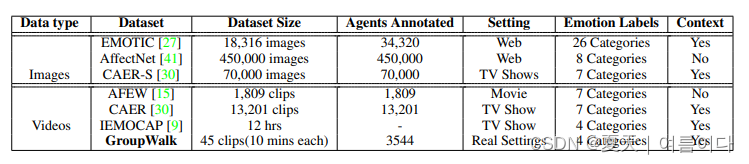
表1:情境感知情感识别数据集分析。我们将GroupWalk与现有的情感识别数据集进行比较
如EMOTIC [27], AffectNet [41], CAER和CAER-S [30], 以及AFEW [15]。
3.我们的方法Our Approach: EmotiCon
在这一节中,我们将对第3节中的方法进行概述。第3.1节中对该方法进行了概述,并在第3.2、3.3和3.4节中的三种语境解释。
3.1. 记号和概述Notation and Overview
我们在图2中展示了我们的情景感知多模态情感识别模型EmotiCon的概况。我们的输入包括一个RGB图像,I。我们对I进行处理,为每个网络生成对应于三个语境的输入数据。三种情境的网络。语境1的网络包括n个流,对应n个不同的模式,分别表示为m1, m2, .... , mn。每个不同的层输出一个特征向量,fi. 这n个特征向量f1, f2, .... , fn被结合起来通过乘法融合[40],得到一个特征编码。
h1 = g(f1, f2, ..., fn),其中g(-)对应于乘法融合函数。同样,h2和h3是通过对应于第二和第三背景的网络计算出来的。h1、h2和h3被连接起来以进行多标签情感分类。
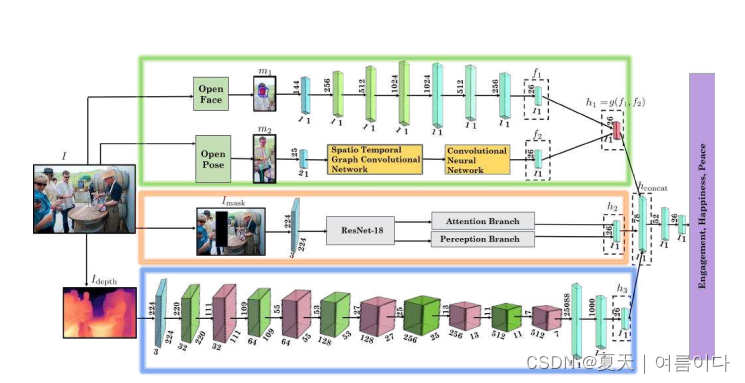
图2:EmotiCon:我们使用了对上下文的三种解释。我们首先提取两种模式的特征,得到f1和f2,然后从原始输入图像I中输入Imask和Idepth。然后通过各自的神经网络来获得h1、h2和h3。为了得到h1,我们使用一个乘法融合层(红色)来融合来自两种模式、面部和步态的输入。连接起来,得到hconcat。
3.2. 情景一Context 1: Multiple Modalities
在现实生活中,人们出现在一个多感官的环境中,包括声音、身体和面孔。包括声音、身体和脸;这些方面也被视为作为一个整体被感知。结合一种以上的模式来推断情绪是有益的,因为来自不同的不同模式的线索可以相互补充。他们似乎也能在野外数据集上的表现比其他单模态方法更好[40]。我们的方法可以扩展到任何数量的可用模态。为了验证这一说法,除了EMOTIC和GroupWalk有两种模态外我们还展示了在IEMOCAP数据集上的结果。数据集上的结果,其中人脸、文本和语音是三种模态。从输入图像I,我们得到m1, m2, .... ,mn,使用4.1节中解释的处理步骤。这些输入然后通过各自的神经网络架构,得到f1, f2, ... , fn。为了使我们的算法为了使我们的算法对传感器噪声具有鲁棒性,并对噪声信号具有抗性,我们将这些特征进行乘法组合以获得h1。正如在以前的研究中[35, 40],乘法融合学会了强调可靠的模式,并减少对其他模态。为了训练这一点,我们使用修改后的损失函数之前提出的[40],定义为:
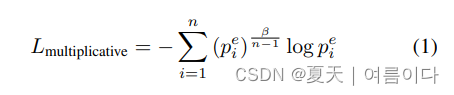
其中n是所考虑的模式的总数。和![]() 是对情感类e的预测,由网络对i的预测给出网络对第
是对情感类e的预测,由网络对i的预测给出网络对第![]()
第一种模式。
3.3. 情景二Context 2: Situational/Background Context
我们的目标是从图像和视频中识别语义背景,以进行感知情绪识别。语义背景包括对场景中存在的物体(不包括主要代理人)、它们的空间范围的理解关键字,以及正在进行的活动。例如,在图1中,输入的图像由一群人组成,他们在一个阳光明媚的日子里围在一起喝酒。明亮的阳光明媚的日子"、"饮料杯"、"帽子 "和 "绿色的草地"构成了语义成分,并可能影响对一个人的感知情绪的判断
一个人的感知情绪的判断。受计算机视觉中多种方法的启发文献[59, 18]中围绕语义场景理解的多种方法,我们使用注意力机制来训练一个模型来关注,使其在掩盖主要代理人的同时关注图像的不同方面。以提取场景的语义成分。该掩码,Imask∈R224×224,对于一个输入图像I来说,它被给出为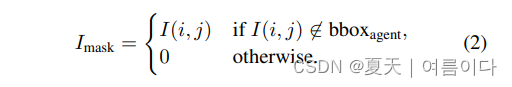
其中,bboxagent表示代理人在场景中的边界盒。场景中的代理。
3.4. 情景三Context 3: Inter-Agent Interactions/SocioDynamic Context
当一个代理人被其他代理人包围时,他们所感知的情绪会发生变化。当其他代理人有共同的身份或被代理人认识时,他们经常协调他们的行为。当其他代理人是陌生人时,这种情况就不同了。这种
互动和接近可以帮助我们更好地推断出代理人的情绪。之前的实验研究使用行走速度、距离和接近度的特征来模拟代理人之间的社会动态互动,以解释他们的个性特征。其中一些算法,如社会力模型[23]。是基于这样的假设:行人会受到吸引力或排斥力来驱动他们的动态。像RVO[56]这样的非线性模型旨在建立个体之间的避免碰撞模型,同时走到他们各自的目标。但是,这些方法都没有捕捉到群体中的凝聚力。我们提出了一种方法来模拟这些社会动态的通过使用深度图计算接近特征来模拟这些社会动态的互动。深度图,Idepth∈R224×224,对应于输入图像,I,通过一个二维矩阵表示,其中
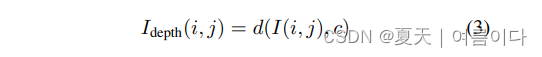
d(I(i, j), c)表示第i行像素的距离。i行和j列与摄像机中心的距离,c。输入的深度图通过一个CNN,得到h3。除了基于深度图的表示外,我们还使用图卷积网络我们还使用图卷积网络(GCNs)来模拟基于距离的社会动态互动。代理人之间基于距离的社会动态互动。GCNs已经被用来模拟交通网络[22]和活动识别[55]中的类似互动。GCN网络的输入包括所有代理人的空间坐标,用X∈Rn×2
其中n代表图像中的图像中的代理数量,以及未加权的毗连矩阵,A∈Rn×n,它的定义如下。
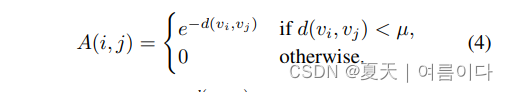
函数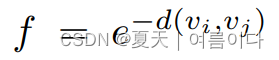 [7]表示任何两个代理人之间的相互作用.
[7]表示任何两个代理人之间的相互作用.
4. 网络结构和实施细节Network Architecture and Implementation Details
4.1. 数据处理Data Processing
语境1:我们使用OpenFace[4]来提取一个144维的人脸模态向量,m1∈R的144次方维获得,通过多个面部位置。我们计算出二维步态模态向量,m2∈R的25×2次方,使用OpenPose[10]从输入图像中提取25个坐标,我们记录x和y的像素值。
语境2:我们使用RobustTP[11],它是一种行人跟踪方法,用于计算场景中所有代理人的边界框。
这些包围盒被用来根据公式2计算图像mask。
语境3:我们使用Megadepth[33]来提取输入图像I的深度图。从输入图像中提取深度图,用公式3计算。
4.2. 网络架构Network Architecture
语境1:给定一个人脸向量m1,我们使用三个一维的卷积(图2中用浅绿色描述)。批量归一化和ReLU非线性。之后是一个最大池操作和三个全连接的层(图2中的青色),采用批量归一化和
ReLU。对于m2,我们使用了由[8]提出的ST-GCN架构,它是目前用于情绪分类的SOTA网络,用于姿态。他们的方法最初是为处理16个身体关节的二维姿势信息而设计的。我们修改了他们的设置,以处理25个关节的二维姿态输入。我们在图2中显示了不同的层和超参数。这两个网络为我们提供了f1和f2。然后,这两个网络被乘法融合(描述为图2中的红色)来生成h1。
语境2:为了学习输入图像I的语义背景,我们使用了注意力分支网络(ABN) [18]在被遮蔽的图像Imask上。ABN包含一个注意力分支,它侧重于注意力地图,以识别和定位图像中的重要区域。它
输出这些潜在的重要位置,其形式为h2.
语境3:我们进行了两个实验,分别使用深度图和GCN。对于基于深度的网络,我们计算深度图,Idepth并通过一个CNN。该CNN由5个交替的二维卷积层组成(图2中的深绿色描述)。和最大
池化层(图2中的品红色)。随后是后面是两个全连接层,尺寸为1000和26(图2中的青色)。
对于基于图形的网络,我们使用两个图形卷积层,然后是两个线性层,维度为100和26。
融合语境解释:为了融合来自三种语境解释的特征向量,我们使用了一种早期融合技术。在进行任何单独的情感推断之前,在进行任何单独的情感推断之前,我们将特征向量连接起来。
h concat=[h1,h2,h3]
我们使用两个尺寸为52和26的全连接层,然后是一个softmax层。这个输出被用于计算损失和误差,然后反向传播误差回传到网络中。
损失函数:我们的分类问题是一个多标签的分类问题,我们给输入的图像或视频分配一个或多个
一个情感标签到一个输入图像或视频。为了训练这个网络,我们使用多标签软边际损失函数
并用L classification来表示它。该损失函数优化了基于最大熵的多标签一比一损失输入x和输出y之间的最大熵。所以,我们把这两个损失函数结合起来。Lmultiplicative(来自公式1)和Lclassification来训练EmotiCon。
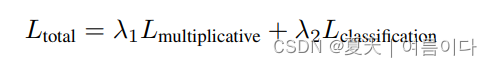
5. 数据集Datasets
在第5.1节中,我们详细介绍了用于情境感知情感识别的基准数据集,EMOTIC。我们还介绍了新的数据集GroupWalk的细节,并与其他现有的数据集进行了比较。并在第5.2节中与其他现有数据集进行了比较。就像表1中总结的那样,有很多情感识别的数据集,但它们没有任何可用的上下文。尽管我们的方法在这些数据集上也能工作,但我们并不期望在这些数据集上比SOTA有任何明显的改进。只是为了加强我们确实在IEMOCAP[9]上运行了我们的方法,它有有限的上下文信息。
语境信息有限,并将我们的结果总结在附录B。
5.1. EMOTIC Dataset
EMOTIC数据集包含了23,571张图片,其中有34,320个注释的人在无限制的环境中。这些注释包括图像中人的明显情绪状态。每个人都被注释为26个离散的类别,每个图像都有多个标签。
5.2. GroupWalk Dataset
5.2.1 Annotation
GroupWalk由45段视频组成,这些视频是在8个真实世界的环境中用固定的摄像机拍摄的,包括
医院门口、机构建筑、公共汽车站、火车站,以及市场、旅游景点、购物场所等等。注释者对所有的代理人进行了注释,包括所有视频中清晰可见的面部和步态。10位注释者共注释了3544个代理人。这些注释包括以下情绪标签--愤怒、快乐、中立和悲伤。在这个数据集上的努力仍在进行。到目前为止,所收集和注释的数据集可以在项目网页上找到。为了准备数据集的训练和测试部分,我们随机选择了36个视频进行训练和9个视频用于测试。虽然感知到的情绪是必不可少的,但其他的情感诸如主导地位和友好程度对于执行联合和/或团体任务也很重要。因此,我们为每个代理人的主导地位和友好程度附加了标签。更多细节关于注解过程、标注者和标签处理的更多细节在附录A中介绍。
6. 实验和结果Experiments and Results
在本节中,我们将讨论为EmotiCon进行的实验。在第6.1节中介绍了超参数和训练细节。在第6.2节中,我们将EmotiCon的性能与之前的方法进行比较。在第6.3节中,我们对定性和定量的结果进行了详细的分析。在第6.5节中。我们进行了实验来验证EmotiCon的每个EmotiCon的每个组成部分的重要性。
6.1.训练细节Training Details
在EMOTIC数据集上训练EmotiCon时,我们使用了标准的训练、评价和测试的分割比例。对于GroupWalk,我们将数据集分成85%的训练(85%)和测试(15%)集。在GroupWalk中,每个样本点都是一个代理ID;因此,输入是视频中代理的所有帧为视频中的代理。为了在视频上扩展EmotiCon。我们对所有的帧进行前向传递,并在所有的帧中取预测向量的平均值,然后计算AP分数,并将其用于测试。然后计算AP分数,并将其用于损失计算和反向传播的损失。我们对EMOTIC使用32个批次,对GroupWalk使用1个批次。我们训练EmotiCon训练75个epochs。我们使用亚当优化器,学习率为0.0001。我们所有的结果都是在在NVIDIA GeForce GTX 1080 Ti GPU上生成。所有的代码都是PyTorch[43]实现。
6.2. Evaluation Metrics and Methods
我们使用标准指标平均精度(AP)来评估我们所有的方法。对于EMOTIC和GroupWalk数据集,我们将我们的方法与以下方法进行比较SOTA方法。
1. Kosti等人[27]提出了一个双流网络,然后是一个融合网络。第一个流编码上下文,然后将整个图像作为输入给CNN。第二个流是一个CNN,用于提取身体特征。融合网络结合了两个CNN的特征
两个CNN的特征,并估计离散的情绪类别。
2. Zhang等人[58]建立了一个情感图,其节点为从图像中提取的背景元素。作为从图像中提取的情境元素。为了检测情境元素,他们使用了一个区域提案网络(RPN)。该图被送入一个图卷积网络(GCN)。网络中的另一个平行分支使用CNN对身体特征进行编码。使用一个CNN。这两个分支的输出被连接起来,推断出一个情绪标签。
3. Lee等人[30]提出了一个网络架构,CAERNet由两个子网络组成,一个双流编码网络和一个自适应融合网络。双流编码网络包括一个面部流和一个上下文流,其中面部表情和上下文(背景)被编码。一个自适应融合融合网络用于融合这两个数据流。
我们使用Kosti等人[27]的公开实施。并在GroupWalk上训练整个模型。这两个Zhang等人[58]和Lee等人[30]都没有公开的实现。我们尽最大努力复制了Lee等人[30]的方法。以我们最好的理解。对于Zhang等人的方法[58],虽然我们报告了他们在EMOTIC数据集上的表现,但由于实施细节有限,我们很难建立他们的模型来测试他们在GroupWalk上的表现。
6.3. Analysis and Discussion
与SOTA的比较:我们在表2中总结了所有方法在EMOTIC和GroupWalk数据集上对AP的评估。
我们在表2中总结了所有方法在EMOTIC和GroupWalk数据集上的APs。对于EmotiCon,我们报告了基于GCN和基于深度图的Container实现的AP.对于EmotiCon,我们报告了基于GCN和基于深度图的Context 3实现的AP得分。在EMOTIC和GroupWalk数据集上,EmotiCon都比SOTA好。
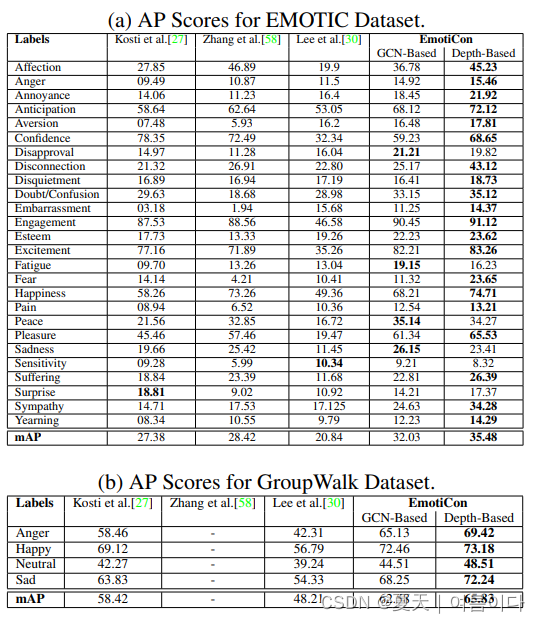
表2:情感分类性能。我们报告了在EMOTIC和GroupWalk数据集上的AP得分。EmotiCon在大多数类别和总体上都优于所有三种方法。
普及到更多的模式:EmotiCon成功的一个主要因素是它能够将不同的情绪从环境中结合起来.模式通过乘法融合进行有效结合。我们的方法是学习将更高的权重分配给更具表现力的方式分配更高的权重,同时压制较弱的方式。比如说。在脸部可能不可见的情况下,EmotiCon从上下文中推导出情感(见图3,中间一行(右))。这与Lee等人[30]相反,后者依赖于面部数据的可用性。因此,他们在EMOTIC和GroupWalk数据集上的表现都很差。因为这两个数据集都包含许多人脸不明显的例子。为了进一步证明EmotiCon在任何模式下的通用能力,我们额外地在附录B中报告了我们在IEMOCAP数据集[9]上的表现。

图3: 定性结果。我们展示了三个例子的分类结果,分别来自EMOTIC数据集(左)和GroupWalk数据集(右)。在最上面一排的例子(左)和中间一排的例子(右)中,深度图清楚地标出了网球运动员即将挥拍的样子,以表达对他的期待。而从医院出来的女人则表达悲伤。在底排(左)和底排(中)的例子中,棺材和孩子的风筝的语义环境被清楚地识别出来,分别表达了悲伤,快乐和愉悦。
GCN与深度图:基于GCN的方法并没有表现不如基于深度的方法,但紧随其后。这可能是由于平均而言,EMOTIC数据集平均包含5个代理。文献中基于GCN的方法是在数据集上训练的,每个图像或视频中的代理数量多得多。此外,由于采用了基于深度的方法,EmotiCon对一般场景的三维方面进行了倾斜,并不局限于对代理之间的关系。
失败案例:我们展示了两个来自EMOTIC数据集中的两个例子,EmotiCon未能正确分类。我们还展示了地面实况和预测的情感标签。在第一张图片中,EmotiCon无法收集到任何上下文信息。另一方面,在第二张图像中,有很多上下文信息,如图像中的许多视觉元素和多个代理。这导致
导致对感知到的情感的不正确推断。

图4:EmotiCon的错误分类:我们展示了两个例子,EmotiCon对标签进行了错误的分类。在第一个例子中,EmotiCon对预测感到困惑,因为缺乏任何上下文。在第二个例子中,有很多的上下文可用,这也变得令人困惑。
6.4. Qualitative Results
我们展示了三个例子的定性结果,每个例子分别来自两个数据集,见图3。第一列是标记主代理的输入图像,第二列是相应的提取的人脸和图像。第二列显示了相应的提取的面部和步态,第三列显示模型学习的注意力图,最后,在第四栏,我们显示了从输入图像中提取的深度图。注意力图中的热图显示了网络所学习的内容。网络学到了什么。在底排(左)和底行(中间)的例子中,语义环境和孩子的风筝被清楚地识别出来,分别表达了悲伤和快乐。与输入图像相对应的深度图与输入图像相对应的深度图捕捉到了接近和代理人之间互动的想法。在最上面一排的例子(左)和中间一排的例子(右)中,深度图清楚地标出了即将挥拍的网球运动员即将挥拍来表达期待,而来自医院的女人则表达了悲伤,分别表达了悲伤的情绪。
6.5. Ablation Experiments
为了说明语境2和语境3的重要性。我们在EMOTIC和GroupWalk数据集上运行EmotiCon。删除对应于这两个语境的网络,然后逐一删除其中的任何一个。消融实验的结果总结在表3中。
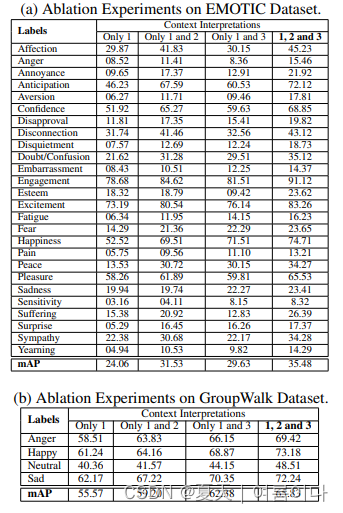
表3:消融实验。在整个过程中保持情境解释1,我们逐一移除其他两个情境解释。并比较两个数据集的情绪分类的AP分数。
我们选择在所有这些运行中保留语境1,因为只有语境1在捕捉来自本身的信息。我们从图3的定性结果中观察到上下文2在EMOTIC数据集的图像中似乎更有表现力。数据集的图像中,语境2似乎更有表现力,而语境3在GroupWalk中更有代表性。这一点得到了表3中报告的结果的支持。第2栏和第3栏的结果也支持了这一点。为了理解为什么会发生这种情况,我们仔细分析了这两个数据集。EMOTIC数据集是为带语境的情感识别任务收集的。它是一个由多个数据集收集的图片组成的数据集,并从互联网上搜刮而来。因此,这些图片中的大多数有着丰富的背景。此外,我们还发现
超过一半的EMOTIC图片最多含有3个人。这些都是我们认为解释2比解释3更有助于EMOTIC的原因。在GroupWalk数据集中,情况恰恰相反。每一帧的人数要高得多。这种密度在解释3中得到了最好的体现,有助于网络做出更好的推断。
7. 结论、局限性和未来工作Conclusion, Limitations, and Future Work
我们提出了EmotiCon,一个情境感知的情绪识别系统,它借用并结合了心理学中的情境解释。我们使用了多种模式(脸部和步态)、情景背景以及社会动力学背景信息。我们努力使用容易获得的模态,这些模态可以用商品硬件(如相机)轻松捕获或提取。为了促进更多关于用自然的方式进行情感识别的研究,我们还发布了一个新的数据集,叫做GroupWalk。我们的模型有局限性,经常在某些类别标签之间混淆。此外,我们目前在离散情感标签上进行多类分类是在离散的情感标签上进行的。在未来,我们我们也希望向连续的情绪模型(价值、唤醒和支配)。作为未来工作的一部分
,我们还将探索更多这样的语境解释来提高准确率。
8. Acknowledgements
这项研究得到了ARO赠款的部分支持W911NF1910069和W911NF1910315以及英特尔公司。
个人总结:
1.论文情景一包含openface识别人脸,openpose识别姿态,情景二包括加了注意力的背景语义信息,情景三是深度的情景识别。
2.
References
[1] Kingsley Oryina Akputu, Kah Phooi Seng, and Yun Li Lee. Facial emotion recognition for intelligent tutoring environment. In IMLCS, pages 9–13, 2013.
[2] Amelia Aldao. The future of emotion regulation research: Capturing context. Perspectives on Psychological Science, 8(2):155–172, 2013.
[3] H Aviezer, Y Trope, et al. Body cues, not facial expressions, discriminate between intense positive and negative emotions. 2012.
[4] Tadas Baltrusaitis, Peter Robinson, and Louis-Philippe ˇ Morency. Openface: an open source facial behavior analysis toolkit. In 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1–10. IEEE, 2016.
[5] Lisa Feldman Barrett, Batja Mesquita, and Maria Gendron. Context in emotion perception. Current Directions in Psychological Science, 20(5):286–290, 2011.
[6] Lisa Feldman Barrett, Batja Mesquita, and Eliot R Smith. The context principle. The mind in context, 1, 2010.
[7] Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps for dimensionality reduction and data representation. Neural computation, 15(6):1373–1396, 2003.
[8] Uttaran Bhattacharya, Trisha Mittal, Rohan Chandra, Tanmay Randhavane, Aniket Bera, and Dinesh Manocha. Step: Spatial temporal graph convolutional networks for emotion perception from gaits. arXiv preprint arXiv:1910.12906, 2019.
[9] Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. Iemocap: Interactive emotional dyadic motion capture database. Language resources and evaluation, 42(4):335, 2008.
[10] Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Openpose: realtime multi-person 2d pose estimation using part affinity fields. arXiv preprint arXiv:1812.08008, 2018. [11] Rohan Chandra, Uttaran Bhattacharya, Christian Roncal, Aniket Bera, and Dinesh Manocha. Robusttp: End-to-end trajectory prediction for heterogeneous road-agents in dense traffic with noisy sensor inputs. In ACM Computer Science in Cars Symposium, page 2. ACM, 2019.
[12] Chlo Clavel, Ioana Vasilescu, Laurence Devillers, Gal Richard, and Thibaut Ehrette. Fear-type emotion recognition for future audio-based surveillance systems. Speech Communication, 50:487–503, 06 2008.
[13] Roddy Cowie, Ellen Douglas-Cowie, Nicolas Tsapatsoulis, George Votsis, Stefanos Kollias, Winfried Fellenz, and J.G. Taylor. Emotion recognition in human-computer interaction. SP Magazine, IEEE, 18:32 – 80, 02 2001.
[14] Abhinav Dhall, Roland Goecke, Jyoti Joshi, Jesse Hoey, and Tom Gedeon. Emotiw 2016: Video and group-level emotion recognition challenges. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, pages 427–432. ACM, 2016.
[15] Abhinav Dhall, Roland Goecke, Simon Lucey, Tom Gedeon, et al. Collecting large, richly annotated facial-expression databases from movies. IEEE multimedia, 19(3):34–41, 2012. [16] Paul Ekman and Wallace V Friesen. Head and body cues in the judgment of emotion: A reformulation. Perceptual and motor skills, 24(3 PT 1):711–724, 1967.
[17] C Fabian Benitez-Quiroz, Ramprakash Srinivasan, and Aleix M Martinez. Emotionet: An accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5562– 5570, 2016.
[18] Hiroshi Fukui, Tsubasa Hirakawa, Takayoshi Yamashita, and Hironobu Fujiyoshi. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10705–10714, 2019.
[19] Samanyou Garg. Group emotion recognition using machine learning, 2019.
[20] Katharine H Greenaway, Elise K Kalokerinos, and Lisa A Williams. Context is everything (in emotion research). Social and Personality Psychology Compass, 12(6):e12393, 2018.
[21] Hatice Gunes and Massimo Piccardi. Bi-modal emotion recognition from expressive face and body gestures. Journal of Network and Computer Applications, 30(4):1334–1345, 2007.
[22] Shengnan Guo, Youfang Lin, Ning Feng, Chao Song, and Huaiyu Wan. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 922–929, 2019.
[23] Dirk Helbing and Peter Molnar. Social force model for pedestrian dynamics. Physical review E, 51(5):4282, 1995.
[24] Esther Jakobs, Antony SR Manstead, and Agneta H Fischer. Social context effects on facial activity in a negative emotional setting. Emotion, 1(1):51, 2001.
[25] A Kleinsmith, N Bianchi-Berthouze, et al. Affective body expression perception and recognition: A survey. IEEE TAC, 2013.
[26] R Benjamin Knapp, Jonghwa Kim, and Elisabeth Andre.´ Physiological signals and their use in augmenting emotion recognition for human–machine interaction. In Emotionoriented systems, pages 133–159. Springer, 2011.
[27] Ronak Kosti, Jose Alvarez, Adria Recasens, and Agata Lapedriza. Context based emotion recognition using emotic dataset. IEEE transactions on pattern analysis and machine intelligence, 2019.
[28] Ronak Kosti, Jose M Alvarez, Adria Recasens, and Agata Lapedriza. Emotion recognition in context. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. [29] Alison Ledgerwood. Evaluations in their social context: Distance regulates consistency and context dependence. Social and Personality Psychology Compass, 8(8):436–447, 2014.
[30] Jiyoung Lee, Seungryong Kim, Sunok Kim, Jungin Park, and Kwanghoon Sohn. Context-aware emotion recognition networks. arXiv preprint arXiv:1908.05913, 2019.
[31] Shan Li, Weihong Deng, and JunPing Du. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2852–2861, 2017.
[32] Yong Li, Jiabei Zeng, Shiguang Shan, and Xilin Chen. Occlusion aware facial expression recognition using cnn with attention mechanism. IEEE Transactions on Image Processing, 28(5):2439–2450, 2018.
[33] Zhengqi Li and Noah Snavely. Megadepth: Learning singleview depth prediction from internet photos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2041–2050, 2018. [34] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence ´ Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
[35] Kuan Liu, Yanen Li, Ning Xu, and Prem Natarajan. Learn to combine modalities in multimodal deep learning. arXiv preprint arXiv:1805.11730, 2018. [36] Aleix M Martinez. Context may reveal how you feel. Proceedings of the National Academy of Sciences, 116(15):7169–7171, 2019. [37] James K McNulty and Frank D Fincham. Beyond positive psychology? toward a contextual view of psychological processes and well-being. American Psychologist, 67(2):101, 2012. [38] H Meeren, C van Heijnsbergen, et al. Rapid perceptual integration of facial expression and emotional body language. PNAS, 2005.
[39] Batja Mesquita and Michael Boiger. Emotions in context: A sociodynamic model of emotions. Emotion Review, 6(4):298–302, 2014.
[40] Trisha Mittal, Uttaran Bhattacharya, Rohan Chandra, Aniket Bera, and Dinesh Manocha. M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues, 2019.
[41] Ali Mollahosseini, Behzad Hasani, and Mohammad H. Mahoor. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Transactions on Affective Computing, 10(1):1831, Jan 2019.
[42] Costanza Navarretta. Individuality in communicative bodily behaviours. In Cognitive Behavioural Systems, pages 417– 423. Springer, 2012.
[43] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in PyTorch. In NIPS Autodiff Workshop, 2017.
[44] Tanmay Randhavane, Aniket Bera, Kyra Kapsaskis, Uttaran Bhattacharya, Kurt Gray, and Dinesh Manocha. Identifying emotions from walking using affective and deep features. arXiv preprint arXiv:1906.11884, 2019.
[45] Michael David Resnik. The context principle in frege’s philosophy. Philosophy and Phenomenological Research, 27(3):356–365, 1967.
[46] Jason M Saragih, Simon Lucey, and Jeffrey F Cohn. Face alignment through subspace constrained mean-shifts. In ICCV, pages 1034–1041. IEEE, 2009.
[47] Klaus R Scherer, Tom Johnstone, and Gundrun Klasmeyer. Vocal expression of emotion. Handbook of affective sciences, pages 433–456, 2003.
[48] Caifeng Shan, Shaogang Gong, and Peter W McOwan. Facial expression recognition based on local binary patterns: A comprehensive study. Image and vision Computing, 27(6):803–816, 2009. [49] Karan Sikka, Karmen Dykstra, Suchitra Sathyanarayana, Gwen Littlewort, and Marian Bartlett. Multiple kernel learning for emotion recognition in the wild. In ICMI, pages 517– 524. ACM, 2013.
[50] Karan Sikka, Karmen Dykstra, Suchitra Sathyanarayana, Gwen Littlewort, and Marian Bartlett. Multiple kernel learning for emotion recognition in the wild. In Proceedings of the 15th ACM on International conference on multimodal interaction, pages 517–524. ACM, 2013. [51] Jessica L Tracy, Richard W Robins, and Roberta A Schriber. Development of a facs-verified set of basic and selfconscious emotion expressions. Emotion, 9(4):554, 2009.
[52] http://mplab.ucsd.edu. The MPLab GENKI Database.
[53] Kai Wang, Xiaoxing Zeng, Jianfei Yang, Debin Meng, Kaipeng Zhang, Xiaojiang Peng, and Yu Qiao. Cascade attention networks for group emotion recognition with face, body and image cues. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, ICMI ’18, pages 640–645, New York, NY, USA, 2018. ACM.
[54] Kyoko Yamamoto and Naoto Suzuki. The effects of social interaction and personal relationships on facial expressions. Journal of Nonverbal Behavior, 30(4):167–179, 2006.
[55] Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[56] Hengchin Yeh, Sean Curtis, Sachin Patil, Jur van den Berg, Dinesh Manocha, and Ming Lin. Composite agents. In Proceedings of the 2008 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, pages 39–47. Eurographics Association, 2008.
[57] AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In ACL (Volume 1: Long Papers), pages 2236–2246, 2018.
[58] Minghui Zhang, Yumeng Liang, and Huadong Ma. Contextaware affective graph reasoning for emotion recognition. In 2019 IEEE International Conference on Multimedia and Expo (ICME), pages 151–156. IEEE, 2019.
[59] Jian Zheng, Sudha Krishnamurthy, Ruxin Chen, Min-Hung Chen, Zhenhao Ge, and Xiaohua Li. Image captioning with integrated bottom-up and multi-level residual top-down attention for game scene understanding. arXiv preprint arXiv:1906.06632, 2019.
[60] Lin Zhong, Qingshan Liu, Peng Yang, Bo Liu, Junzhou Huang, and Dimitris N Metaxas. Learning active facial patches for expression analysis. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 2562– 2569. IEEE, 2012.
[61] Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision, 127(3):302–321, 2019.


















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











