









----------------------------------🗣️ 语音合成 VITS相关系列直达 🗣️ -------------------------------------
🫧VITS :TTS | 保姆级端到端的语音合成VITS论文详解及项目实现(超详细图文代码)
🫧MB-iSTFT-VITS:TTS | 轻量级语音合成论文详解及项目实现
🫧MB-iSTFT-VITS2:TTS | 轻量级VITS2的项目实现以及API设置-CSDN博客
🫧PolyLangVITS:MTTS | 多语言多人的VITS语音合成项目实现-CSDN博客
本文主要是 讲解了PolyLangVITS项目实现,未找到论文,可能并未发表~
代码:ldORI-Muchim/PolyLangVITS: Multi-speaker Speech Synthesis Using VITS(KO, JA, EN, ZH) (github.com)
目录
【PS2】FileNotFoundError: [Errno 2] No such file or directory: '../datasets/vits_train.txt.cleaned'
【PS5】 FileNotFoundError: [Errno 2] No such file or directory: '../datasets/so_train.txt.cleaned'
【PS6】× Getting requirements to build wheel did not run successfully.
1.项目说明
项目把ASR语音识别和语音合成集合在一起,无需手动数据预处理,只需要语音数据就可以合成自然的人声。
- ASR:加载fast-wisper模型
- TTS:直接使用VITS模型
2.项目实现
2.1.环境设置
Win、Linux系统最小16GB的RAM
GPU至少12GB的VRAM
python3.8
Anaconda/pyorch/cuda/zlib dll
conda create -n plvits python=3.8
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
pip install -U pyopenjtalk --no-build-isolation
apt install cmake
pip install Cython
git clone https://github.com/ORI-Muchim/PolyLangVITS.git
cd PolyLangVITS
pip install -r requirements.txt
# 如果出错查看【PS7】
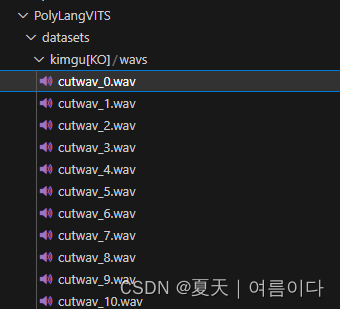
将中文数据集以以下名称命名
数据集名称[ZH]韩语[KO],日语[JA],英语[EN]
例如data[ZH],文件夹下的语音存为wavs路径下
也就是/workspace/tts/PolyLangVITS/datasets/data[ZH]/wavs:如图
2.2.数据处理
2.2.1.自己的数据集的话一定要先确认采样率
如果自己的数据不确定采样率,查看音频采样率命令
file 1.wav
或者自己录音的情况,需要对音频进行重新采样
import os
import librosa
import tqdm
import soundfile as sf
import time
if __name__ == '__main__':
# 要查找的音频类型
audioExt = 'WAV'
# 待处理音频的采样率
input_sample = 44100
# 重采样的音频采样率
output_sample = 22050
# 待处理音频的多个文件夹
#audioDirectory = ['/data/orgin/train', '/data/orgin/test']
audioDirectory = ['/workspace/tts/PolyLangVITS/preprodata/his_out']
# 重采样输出的多个文件夹
#outputDirectory = ['/data/traindataset', '/data/testdataset']
outputDirectory = ['/workspace/tts/PolyLangVITS/datasets/his[KO]']
start_time=time.time()
# for 循环用于遍历所有待处理音频的文件夹
for i, dire in enumerate(audioDirectory):
# 寻找"directory"文件夹中,格式为“ext”的音频文件,返回值为绝对路径的列表类型
clean_speech_paths = librosa.util.find_files(
directory=dire,
ext=audioExt,
recurse=True, # 如果选择True,则对输入文件夹的子文件夹也进行搜索,否则只搜索输入文件夹
)
# for 循环用于遍历搜索到的所有音频文件
for file in tqdm.tqdm(clean_speech_paths, desc='No.{} dataset resampling'.format(i)):
# 获取音频文件的文件名,用作输出文件名使用
fileName = os.path.basename(file)
# 使用librosa读取待处理音频
y, sr = librosa.load(file, sr=input_sample)
# 对待处理音频进行重采样
y_16k = librosa.resample(y, orig_sr=sr, target_sr=output_sample)
# 构建输出文件路径
outputFileName = os.path.join(outputDirectory[i], fileName)
# 将重采样音频写回硬盘,注意输出文件路径
sf.write(outputFileName, y_16k, output_sample)
end_time=time.time()
runTime=end_time - start_time
print("Run Time: {} sec ~".format(runTime))
如果输出为空的话,参考【PS1】
最终的数据格式(只需要wav语音文件,内有wisper会转文本并分割训练验证集,并处理为音素对应文本)
2.3.训练
用法:python main.py 语言 模型名 采样率
python main.py {language} {model_name} {sample_rate}如果GPU小于12GB的话,运行
python main_low.py {language} {model_name} {sample_rate}如果数据配置已完成,并且您想要恢复训练,请输入以下代码:
python main_resume.py {model_name}2.3.1.训练1
python main.py ko vits 22050 如果出现错误,请参考【PS】
作者把数据处理一并实现
最终模型输入为 【输入的文件名,说话人,数据处理后的文本】
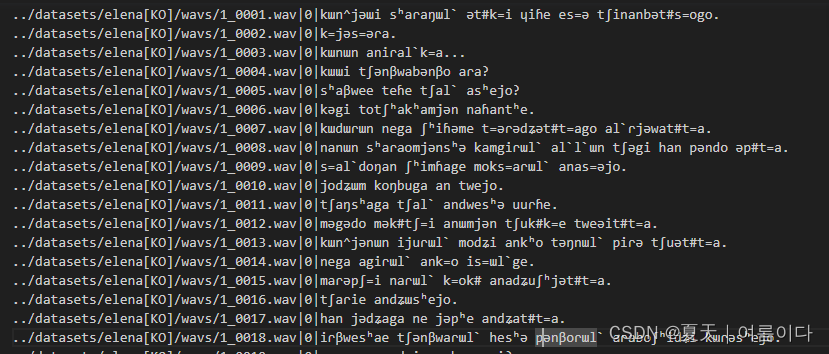
下载VITS模型的预训练权重

一个D_0.pth,一个G_0.pth
2.3.2.训练2(可选)
如果GPU的RAM少于12GB,使用以下命令训练:
python main_low.py ko vits 220502.3.3.继续训练
如果中间偶然停止,重新训练时需要修改main.py文件
修改后
import os
import subprocess
import sys
os.chdir('./datasets')
#subprocess.run(["python", "integral.py", sys.argv[1], sys.argv[2], sys.argv[3]])
os.chdir('../')
#subprocess.run(["python", "get_pretrained_model.py", sys.argv[1], sys.argv[2]])
#config_path = f"../datasets/{sys.argv[2]}.json"
#这里指定配置文件,配置文件训练前可修改batch size和其他参数等
config_path = f"/workspace/tts/PolyLangVITS/datasets/his.json"
model_name = sys.argv[2]
os.chdir('./vits')
subprocess.run(["python", "train_ms.py", "-c", config_path, "-m", model_name])
再次运行训练命令
python main.py ko vits 22050会接着上一次的权重值接着训练~
换数据集重新训练的情况(可选)
格式相同
修改数据集的配置文件路径(config_path),位置在main.py中的
消除第6行的注释,利用wisper进行语音识别,完成数据预处理,如图


2.3.4.多数据集训练
数据格式

修改main.py处的配置文件,运行
python main.py data1_data2(自定义模型名称) 22050(数据采样率) 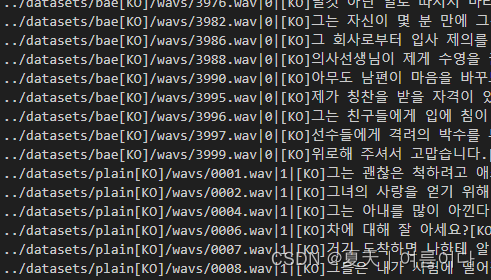
推理
单个推理
模型名(Model_name)是自定义的存放模型相关文件的文件夹,模型步数(model_step)是训练后得到的权重部署
# python inference.py {model_name} {model_step}
python inference.py vits 69000 推理速度
批量推理
#matplotlib inline
import matplotlib.pyplot as plt
import IPython.display as ipd
import os
import json
import math
import time
import torch
import sys
import langdetect
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
import commons
import utils
from data_utils import TextAudioLoader, TextAudioCollate, TextAudioSpeakerLoader, TextAudioSpeakerCollate
from models import SynthesizerTrn
from text.symbols import symbols
from text import text_to_sequence
from scipy.io.wavfile import write
def get_text(text, hps):
text_norm = text_to_sequence(text, hps.data.text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
def langdetector(text):
try:
lang = langdetect.detect(text)
if lang == 'ko':
return f'[KO]{text}[KO]'
elif lang == 'ja':
return f'[JA]{text}[JA]'
elif lang == 'en':
return f'[EN]{text}[EN]'
elif lang == 'zh-cn':
return f'[ZH]{text}[ZH]'
except Exception as e:
return text
hps = utils.get_hparams_from_file(f"./models/{sys.argv[1]}/config.json")
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model).cuda()
_ = net_g.eval()
_ = utils.load_checkpoint(f"./models/{sys.argv[1]}/G_{sys.argv[2]}.pth", net_g, None)
output_dir = f'./vitsoutput/{sys.argv[1]}'
os.makedirs(output_dir, exist_ok=True)
speakers = len([f for f in os.listdir('./datasets') if os.path.isdir(os.path.join('./datasets', f))])
start=time.time()
# single
#input_text ="语音合成 测试文本"
# Batch
with open('/workspace/tts/PolyLangVITS/batch_text.txt', 'r',encoding='utf-8') as f:
numbers= f.readlines()
print("Number:",numbers)
for i in range(len(numbers)):
text = numbers[i]
print(text)
text = langdetector(text)
print("Text:",text)
speed = 1
#idx = 0
for idx,t in range(speakers):
sid = torch.LongTensor([idx]).cuda()
stn_tst = get_text(text, hps)
for i in range(11):
with torch.no_grad():
x_tst = stn_tst.cuda().unsqueeze(0)
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()
audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=1 / speed)[0][0,0].data.cpu().float().numpy()
write(f'{output_dir}/output{idx}.wav', hps.data.sampling_rate, audio)
print(f'{output_dir}/output{idx}.wav 생성완료!')
end = time.time()
runTime = end - start
print('run time: {} sec'.format(runTime))
微调
修改训练
首先修改数据的输入路径相关
将PolyLangVITS/vits/utils.py第144行改为自己的路径
def get_hparams(init=True):
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--config', type=str, default="./configs/base.json",
help='JSON file for configuration')
parser.add_argument('-m', '--model', type=str, required=True,
help='Model name')改为
def get_hparams(init=True):
parser = argparse.ArgumentParser()
# parser.add_argument('-c', '--config', type=str, default="./configs/base.json",
parser.add_argument('-c', '--config', type=str, default="/workspace/tts/PolyLangVITS/datasets/so.json",
help='JSON file for configuration')
#parser.add_argument('-m', '--model', type=str, required=True,
parser.add_argument('-m', '--model', type=str, default="so",
help='Model name')修改后运行
自己新建一个train.py
#-*- coding: utf-8 -*-
# train.py
import os
import json
import argparse
import itertools
import math
import torch
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.multiprocessing as mp
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.cuda.amp import autocast, GradScaler
import librosa
import logging
logging.getLogger('numba').setLevel(logging.WARNING)
import commons
import utils
from data_utils import (
TextAudioSpeakerLoader,
TextAudioSpeakerCollate,
DistributedBucketSampler
)
from models import (
SynthesizerTrn,
MultiPeriodDiscriminator,
)
from losses import (
generator_loss,
discriminator_loss,
feature_loss,
kl_loss
)
from mel_processing import mel_spectrogram_torch, spec_to_mel_torch
from text.symbols import symbols
torch.backends.cudnn.benchmark = True
global_step = 0
def main():
"""Assume Single Node Multi GPUs Training Only"""
assert torch.cuda.is_available(), "CPU training is not allowed."
n_gpus = torch.cuda.device_count()
print("Number of GPUs :",n_gpus)
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '1010'
hps = utils.get_hparams()
mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
def run(rank, n_gpus, hps):
global global_step
if rank == 0:
logger = utils.get_logger(hps.model_dir)
logger.info(hps)
utils.check_git_hash(hps.model_dir)
writer = SummaryWriter(log_dir=hps.model_dir)
writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
dist.init_process_group(backend='gloo' if os.name == 'nt' else 'nccl', init_method='env://', world_size=n_gpus, rank=rank)
torch.manual_seed(hps.train.seed)
torch.cuda.set_device(rank)
train_dataset = TextAudioSpeakerLoader(hps.data.training_files, hps.data)
train_sampler = DistributedBucketSampler(
train_dataset,
hps.train.batch_size,
[32,300,400,500,600,700,800,900,1000],
num_replicas=n_gpus,
rank=rank,
shuffle=True)
collate_fn = TextAudioSpeakerCollate()
train_loader = DataLoader(train_dataset, num_workers=8, shuffle=False, pin_memory=True,
collate_fn=collate_fn, batch_sampler=train_sampler)
if rank == 0:
eval_dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps.data)
#eval_loader = DataLoader(eval_dataset, num_workers=4, shuffle=False,
eval_loader = DataLoader(eval_dataset, num_workers=8, shuffle=False,
batch_size=hps.train.batch_size, pin_memory=True,
drop_last=False, collate_fn=collate_fn)
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,**hps.model).cuda(rank)
net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank)
optim_g = torch.optim.AdamW(
net_g.parameters(),
hps.train.learning_rate,
betas=hps.train.betas,
eps=hps.train.eps)
optim_d = torch.optim.AdamW(
net_d.parameters(),
hps.train.learning_rate,
betas=hps.train.betas,
eps=hps.train.eps)
net_g = DDP(net_g, device_ids=[rank], find_unused_parameters=True)
net_d = DDP(net_d, device_ids=[rank], find_unused_parameters=True)
try:
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g, optim_g)
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d, optim_d)
global_step = (epoch_str - 1) * len(train_loader)
except:
epoch_str = 1
global_step = 0
scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
scaler = GradScaler(enabled=hps.train.fp16_run)
for epoch in range(epoch_str, hps.train.epochs + 1):
if rank==0:
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, eval_loader], logger, [writer, writer_eval])
else:
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, None], None, None)
scheduler_g.step()
scheduler_d.step()
def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers):
net_g, net_d = nets
optim_g, optim_d = optims
scheduler_g, scheduler_d = schedulers
train_loader, eval_loader = loaders
if writers is not None:
writer, writer_eval = writers
train_loader.batch_sampler.set_epoch(epoch)
global global_step
net_g.train()
net_d.train()
for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers) in enumerate(train_loader):
x, x_lengths = x.cuda(rank, non_blocking=True), x_lengths.cuda(rank, non_blocking=True)
spec, spec_lengths = spec.cuda(rank, non_blocking=True), spec_lengths.cuda(rank, non_blocking=True)
y, y_lengths = y.cuda(rank, non_blocking=True), y_lengths.cuda(rank, non_blocking=True)
speakers = speakers.cuda(rank, non_blocking=True)
with autocast(enabled=hps.train.fp16_run):
y_hat, l_length, attn, ids_slice, x_mask, z_mask,\
(z, z_p, m_p, logs_p, m_q, logs_q) = net_g(x, x_lengths, spec, spec_lengths, speakers)
mel = spec_to_mel_torch(
spec,
hps.data.filter_length,
hps.data.n_mel_channels,
hps.data.sampling_rate,
hps.data.mel_fmin,
hps.data.mel_fmax)
y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length)
y_hat_mel = mel_spectrogram_torch(
y_hat.squeeze(1),
hps.data.filter_length,
hps.data.n_mel_channels,
hps.data.sampling_rate,
hps.data.hop_length,
hps.data.win_length,
hps.data.mel_fmin,
hps.data.mel_fmax
)
y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice
# Discriminator
y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
with autocast(enabled=False):
loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)
loss_disc_all = loss_disc
optim_d.zero_grad()
scaler.scale(loss_disc_all).backward()
scaler.unscale_(optim_d)
grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
scaler.step(optim_d)
with autocast(enabled=hps.train.fp16_run):
# Generator
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
with autocast(enabled=False):
loss_dur = torch.sum(l_length.float())
loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
loss_fm = feature_loss(fmap_r, fmap_g)
loss_gen, losses_gen = generator_loss(y_d_hat_g)
loss_gen_all = loss_gen + loss_fm + loss_mel + loss_dur + loss_kl
optim_g.zero_grad()
scaler.scale(loss_gen_all).backward()
scaler.unscale_(optim_g)
grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
scaler.step(optim_g)
scaler.update()
if rank==0:
if global_step % hps.train.log_interval == 0:
lr = optim_g.param_groups[0]['lr']
losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_dur, loss_kl]
logger.info('Train Epoch: {} [{:.0f}%]'.format(
epoch,
100. * batch_idx / len(train_loader)))
logger.info([x.item() for x in losses] + [global_step, lr])
scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr, "grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g}
scalar_dict.update({"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/dur": loss_dur, "loss/g/kl": loss_kl})
scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)})
scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)})
scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)})
image_dict = {
"slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()),
"slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()),
"all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy()),
"all/attn": utils.plot_alignment_to_numpy(attn[0,0].data.cpu().numpy())
}
utils.summarize(
writer=writer,
global_step=global_step,
images=image_dict,
scalars=scalar_dict)
if global_step % hps.train.eval_interval == 0:
evaluate(hps, net_g, eval_loader, writer_eval)
utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "G_{}.pth".format(global_step)))
utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "D_{}.pth".format(global_step)))
old_g=os.path.join(hps.model_dir, "G_{}.pth".format(global_step-2000))
old_d=os.path.join(hps.model_dir, "D_{}.pth".format(global_step-2000))
if os.path.exists(old_g):
os.remove(old_g)
if os.path.exists(old_d):
os.remove(old_d)
global_step += 1
print('global_step =>',global_step)
if rank == 0:
logger.info('====> Epoch: {}'.format(epoch))
def evaluate(hps, generator, eval_loader, writer_eval):
generator.eval()
with torch.no_grad():
for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers) in enumerate(eval_loader):
x, x_lengths = x.cuda(0), x_lengths.cuda(0)
spec, spec_lengths = spec.cuda(0), spec_lengths.cuda(0)
y, y_lengths = y.cuda(0), y_lengths.cuda(0)
speakers = speakers.cuda(0)
# remove else
x = x[:1]
x_lengths = x_lengths[:1]
spec = spec[:1]
spec_lengths = spec_lengths[:1]
y = y[:1]
y_lengths = y_lengths[:1]
speakers = speakers[:1]
break
y_hat, attn, mask, *_ = generator.module.infer(x, x_lengths, speakers, max_len=1000)
y_hat_lengths = mask.sum([1,2]).long() * hps.data.hop_length
mel = spec_to_mel_torch(
spec,
hps.data.filter_length,
hps.data.n_mel_channels,
hps.data.sampling_rate,
hps.data.mel_fmin,
hps.data.mel_fmax)
y_hat_mel = mel_spectrogram_torch(
y_hat.squeeze(1).float(),
hps.data.filter_length,
hps.data.n_mel_channels,
hps.data.sampling_rate,
hps.data.hop_length,
hps.data.win_length,
hps.data.mel_fmin,
hps.data.mel_fmax
)
image_dict = {
"gen/mel": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy())
}
audio_dict = {
"gen/audio": y_hat[0,:,:y_hat_lengths[0]]
}
if global_step == 0:
image_dict.update({"gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy())})
audio_dict.update({"gt/audio": y[0,:,:y_lengths[0]]})
utils.summarize(
writer=writer_eval,
global_step=global_step,
images=image_dict,
audios=audio_dict,
audio_sampling_rate=hps.data.sampling_rate
)
generator.train()
if __name__ == "__main__":
main()
然后运行
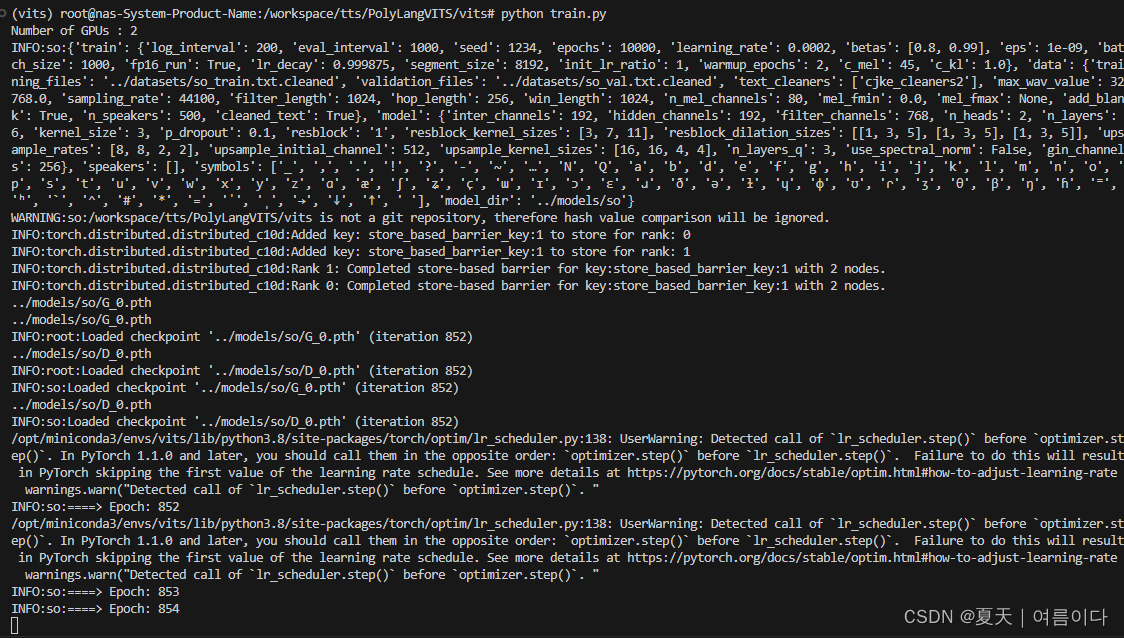
python train.py如果出现错误请参考【PS4/5】
训练batch_size 最好等于32,300,400,500,600,700,800,900,1000
数据1325个语音数据集 batch_size 设置为32,
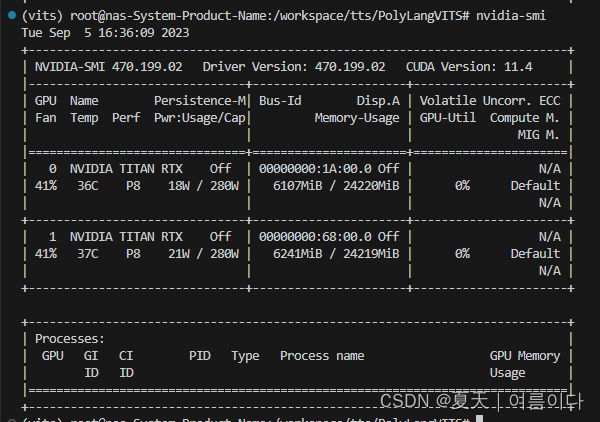
数据3000个语音数据集 batch_size 设置为32,每张卡占用16700MiB左右
总结
各模型之间的比较
| Model | VITS | PolyLangVITS | ms_istft_vits | ms_istft_vits2 |
| 合成速度 | MOS值接近真实值的,速度比较快,0.08-0.4秒左右(我的生成0.27~0.29) | 并未修改vits网络结构,与vits合成速度相似 | 特点是性能是vits的4倍左右,速度更快,0.06-0.1秒左右,MOS值接近真实值。 | 基于vits2开发,合成速度没有ms_istft_vits快 |
| 训练 |
| 5000语音文件,Batch size 64,训练天5000epochs |
|
|
| 优势 | baseline | 训练速度快 | 合成速度快 | 合成语音更自然 |
模型运行
- vits模型多人训练以AISHELL-3 多人(174人,8万多条语音)中文数据集8K采样率,batch_size=16,需要训练到500K步效果比较好。T4 GPU 16G大概需要训练10天左右。AISHELL单人1万条女声44K采样率,模型大概需要9天左右,240K步效果比较好,可以克隆荷塘月色。
- 多音字方面:需要维护自己的多音字字典。
- 加速方面:量化、转onnx或script模型失败,代码不支持,其中转traced_model成功,但性能很低,需要10秒。
过程中遇到的错误与解决【PS】
【PS1】音频采样后,输出为空

可能是语音的路径问题,不用特殊符号[]^等
修改后就正确啦
【PS2】FileNotFoundError: [Errno 2] No such file or directory: '../datasets/vits_train.txt.cleaned'
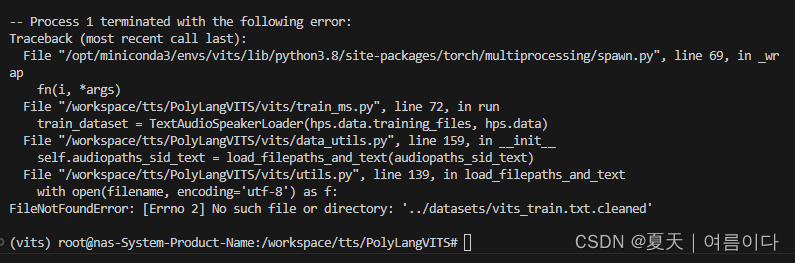
输入命令错误
解决办法:查看
/workspace/tts/PolyLangVITS/datasets/integral.py文件,其中输入的语言类型为小写,
python main.py ko vits 22050再次运行后出现
IndexError: Replacement index 2 out of range for positional args tuple
数据采样率错误,需要对数据进行重采样。
因为数据集有俩个,一个是22050,一个是44100HZ,需要进行重采样。
【PS3】CUDA of out me
方法 1:修改num_workers
train_ms.py第81行
train_loader = DataLoader(train_dataset, num_workers=8, shuffle=False, pin_memory=True,方法 2:修改batch_size
PolyLangVITS/datasets/integral.py的第374行
"batch_size": 8,# 默认32【PS4】RuntimeError: The server socket has failed to listen on any local network address. The server socket has failed to bind to [::]:8000 (errno: 98 - Address already in use). The server socket has failed to bind to 0.0.0.0:8000 (errno: 98 - Address already in use).
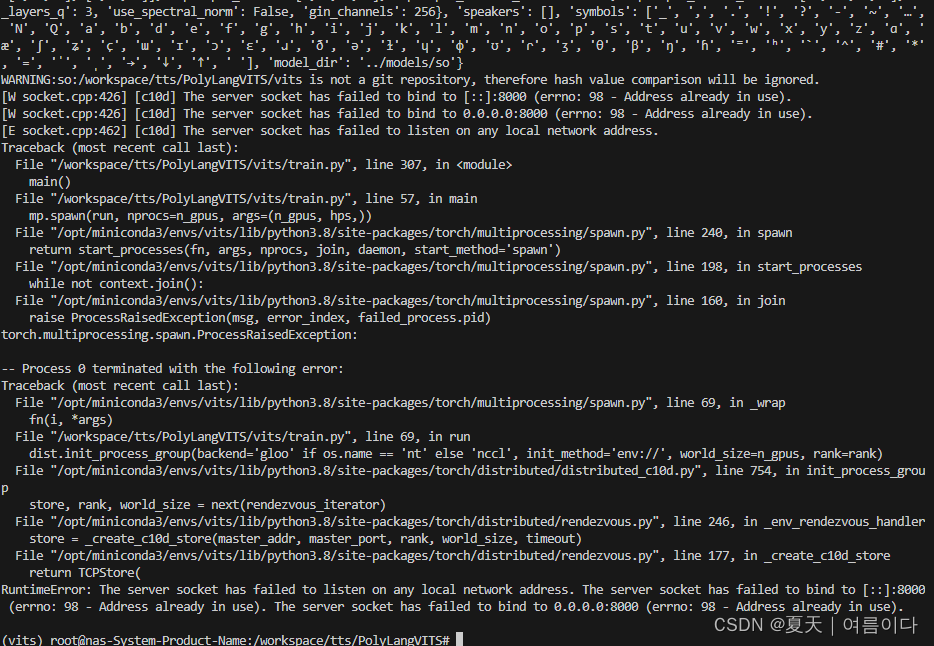
解决办法:
修改train.py中55行的IP地址, os.environ['MASTER_PORT'] = '1026'
【PS5】 FileNotFoundError: [Errno 2] No such file or directory: '../datasets/so_train.txt.cleaned'
错误描述:文件夹下明明有此文件,却提示没有
运行脚本的位置不对
在PolyLangVITS/下运行会出现此问题
解决方法:在PolyLangVITS/vits/下运行
【PS6】× Getting requirements to build wheel did not run successfully.

安装cmake
apt install cmake
#
export PATH=$PATH:/home/bnu/cmake-3.6.0-Linux-x86 64/bin
#查看版本
cmake --version安装后还是出错,在配置中其实有cmake,不是cmake未安装的问题
后来每50个分别安装后,发现有一项是pyopenjtalk==0.2.0 pyaudio==0.2.13
先把俩项删掉,安装就会成功。

最终解决方案
安装依赖项,不指定版本的话,pyopenjtalk可以安装
apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
pip install pyopenjtalk
pip install pyaudio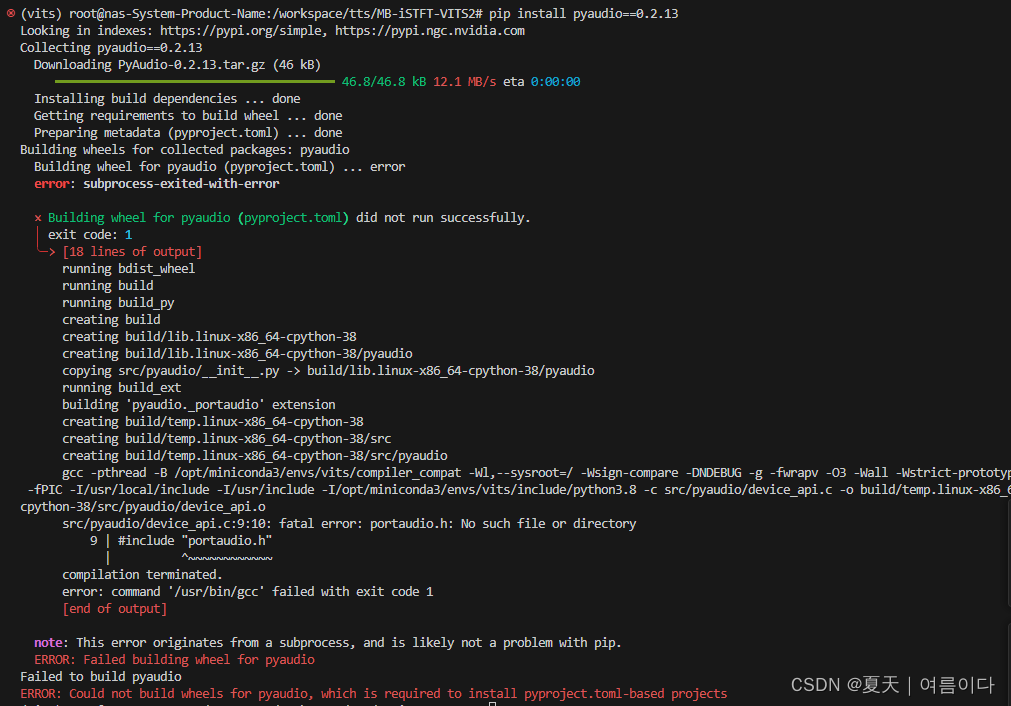 pyaudio仍旧无法安装,但是项目正常运行。
pyaudio仍旧无法安装,但是项目正常运行。
pip install pyaudio无法安装解决
再次查找后
sudo apt-get install portaudio19-dev
sudo apt-get install python3-all-dev
pip install pyaudio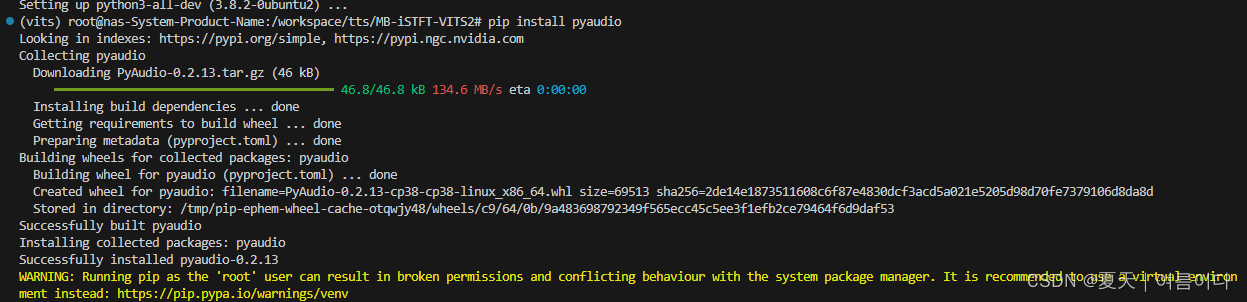
pip install pyopenjtalk 无法安装解决
配置cmake,如果apt装过cmake,pip 又装了的话,pip卸载cmake
pyopenjtalk是关于日语处理的库,如果在文本处理过程中,不涉及到日语的话删掉相关库的操作就可以啦
【PS7】在加载ASR时,出现AttributeError: module 'onnxruntime' has no attribute 'SessionOptions'
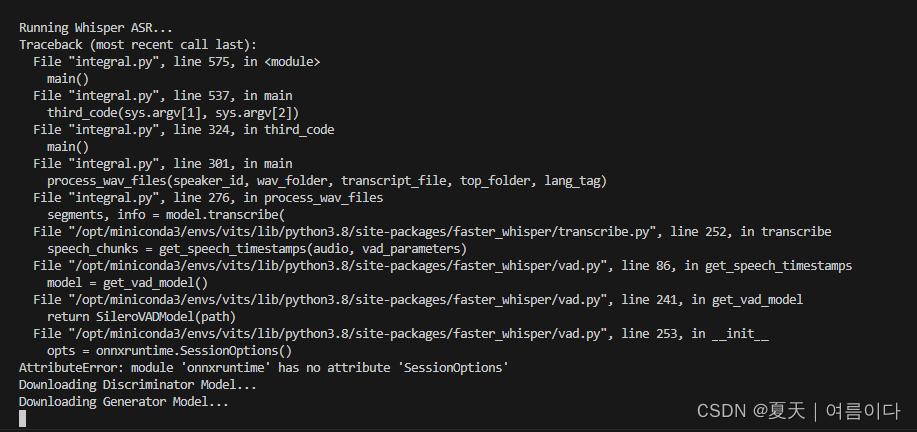
onnxruntime版本问题
pip uninstall onnxruntime
pip uninstall onnxruntime-gpu
# 重新安装
pip install onnxruntime
然后就解决啦
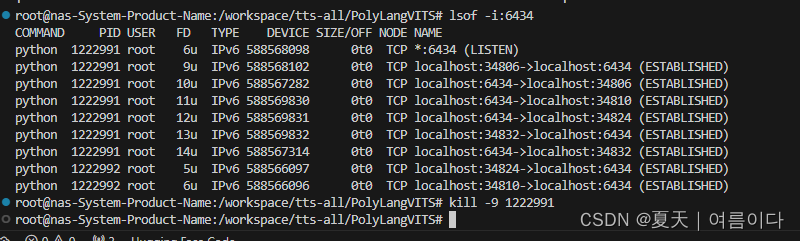
【PS8】RuntimeError: The server socket has failed to listen on any local network address. The server socket has failed to bind to [::]:6434 (errno: 98 - Address already in use). The server socket has failed to bind to 0.0.0.0:6434 (errno: 98 - Address already in use).
因为 端口被占用出现错误
解决办法:删除被占用端口或者换一个端口号
查询删除端口命令
lsof -i:6434 # 查询指定端口号
kill -9 1222991 # 杀掉此进程的pid,进程号换成自己的
参考文献
【1】https://github.com/Plachtaa/VITS-fast-fine-tuning/blob/main/VC_inference.py
【2】举世无双语音合成系统 VITS 发展历程(2023.08.30 培训视频) - 知乎
【3】基于VITS的galgame角色语音合成+使用Kaggle的训练教程(9nine版) - 哔哩哔哩 (bilibili.com)
【4】VITS-从零开始微调(finetune)训练并部署指南-支持本地云端-CSDN博客
扩展
#
python /workspace/tts/PolyLangVITS/vits/beach_test.py ssm_vits 139000
















 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











