







基本概念
凸函数:在函数上任取两点,两点的线段均在这个函数的平面上。
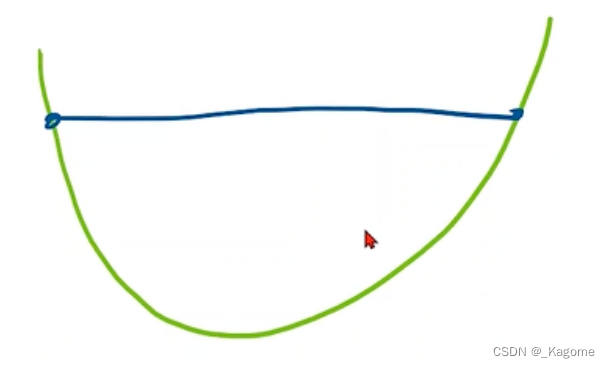
分治法:找到最近的,不断进行小方格划分,直到找到最优点。
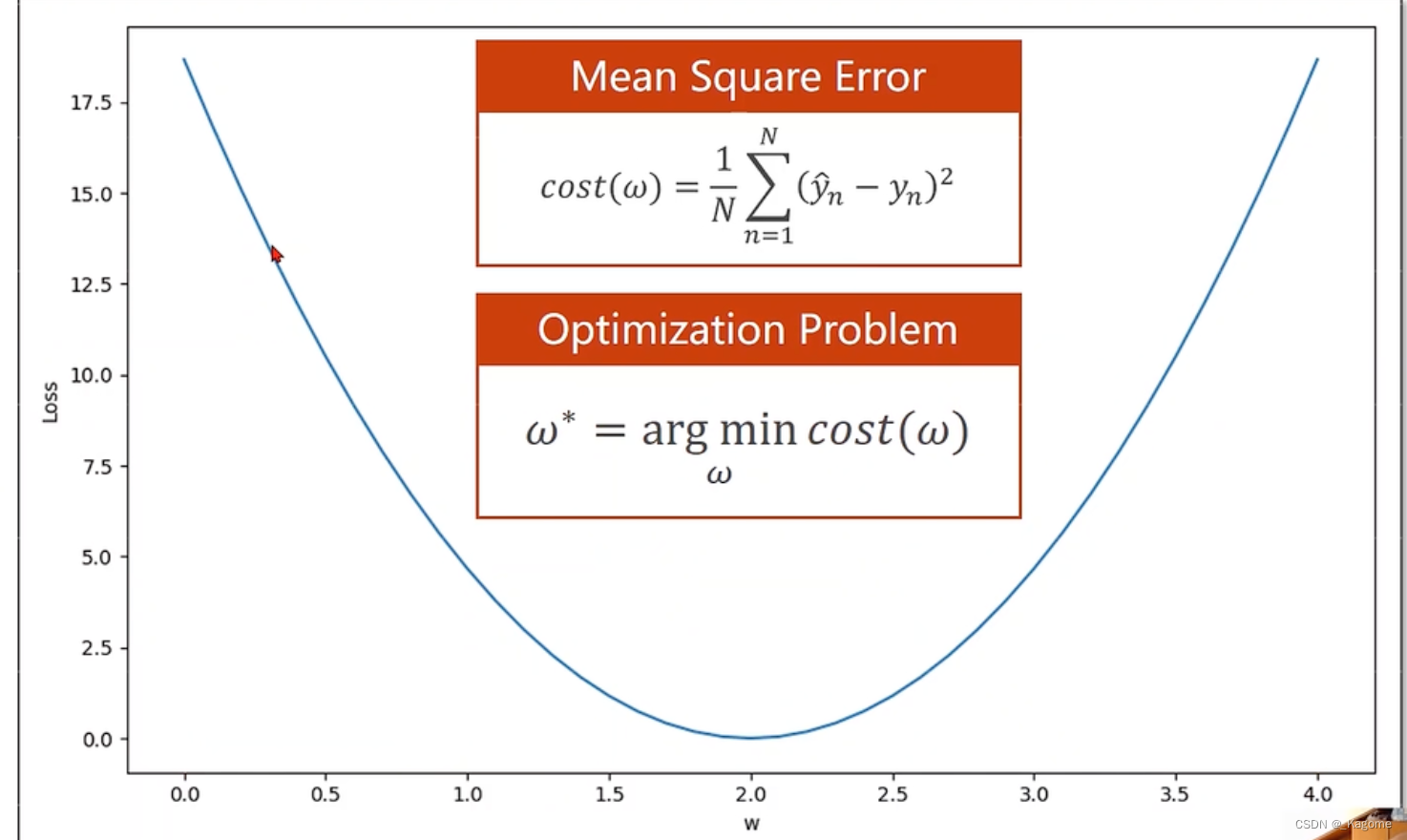
以上为优化问题,求最小值,N代表总数len(XS)。
算法
α代表学习率,取得小一点,保持收敛,每次都选择梯度下降的最快的方向,这就类比是算法中的贪心算法,只看眼前最好的选择,不一定得到最优的结果(全局),只能得到局部最优。
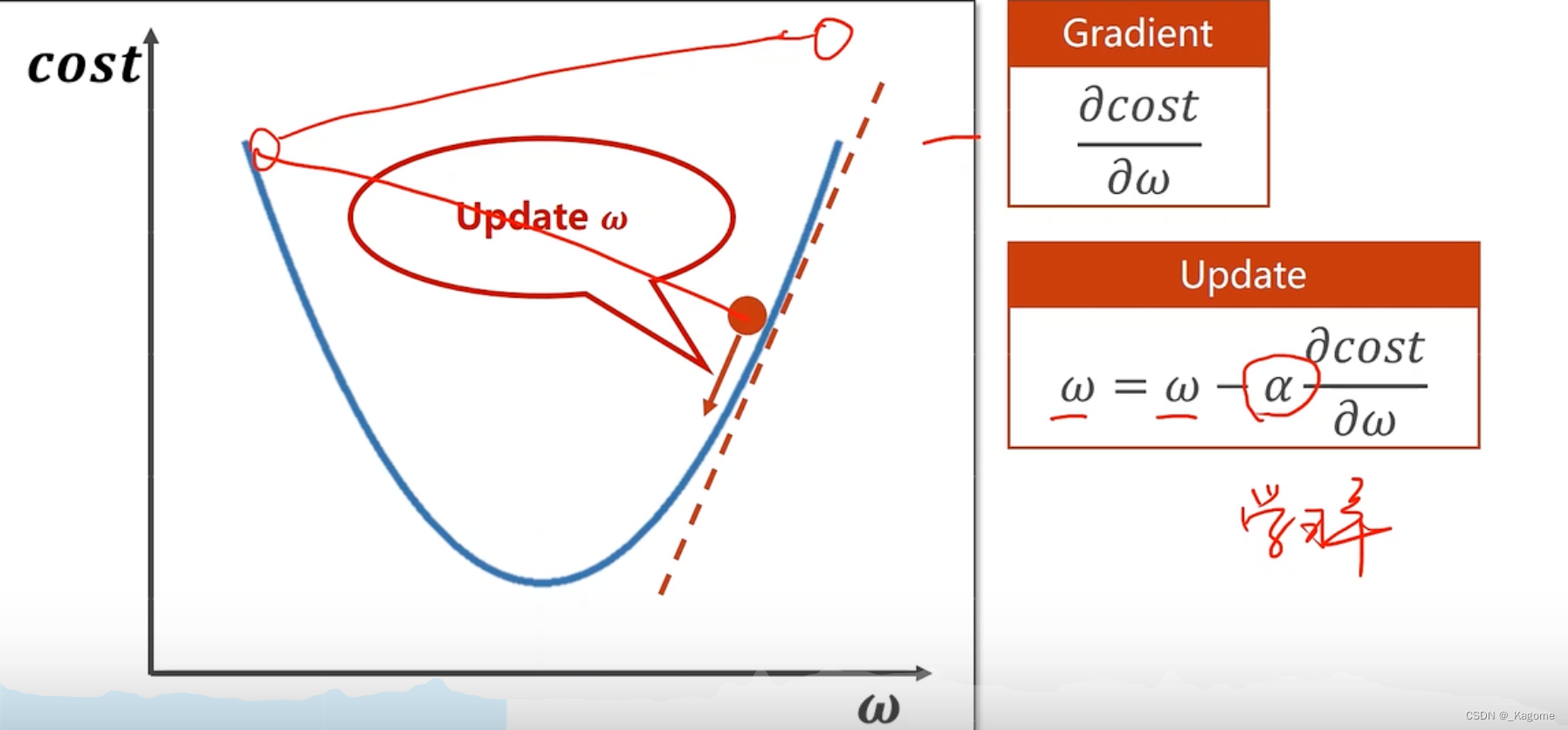
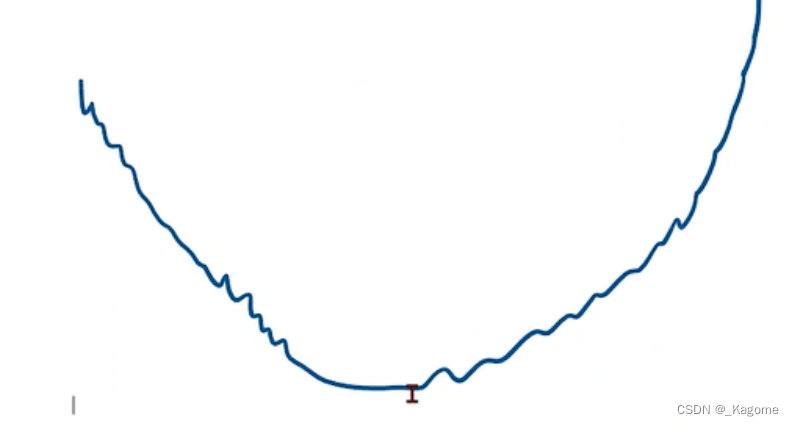
打个比方,如上图,从高点下落,此时梯度下降最快,但是爬升时梯度是正的,切非最快,所以就要往低点行进,最终回落到局部最小点,但是此时的局部最小点不是全局最小点。此函数称为非凸函数,即取两个点,连成直线,不能保证线的所有点都在函数上方。
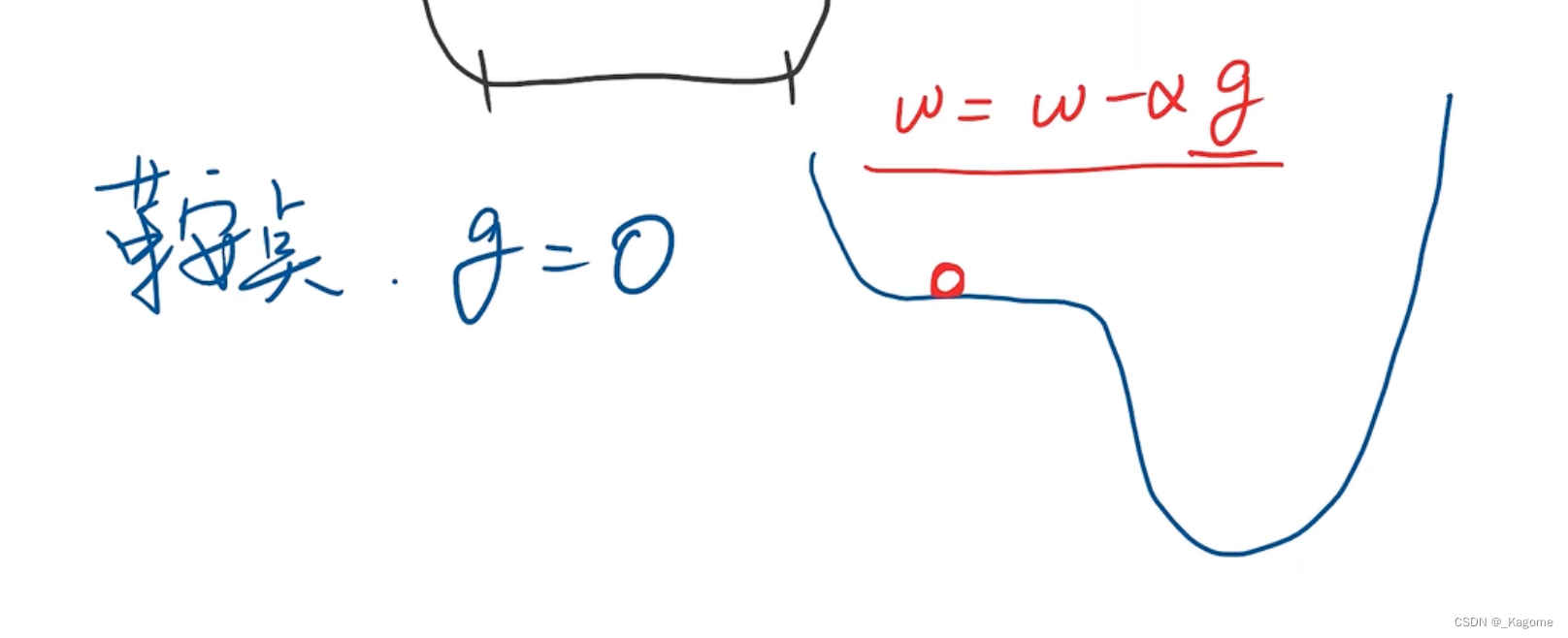
鞍点处梯度不变。
Cost(w)就相当于纵坐标y,W就相当于横坐标x。

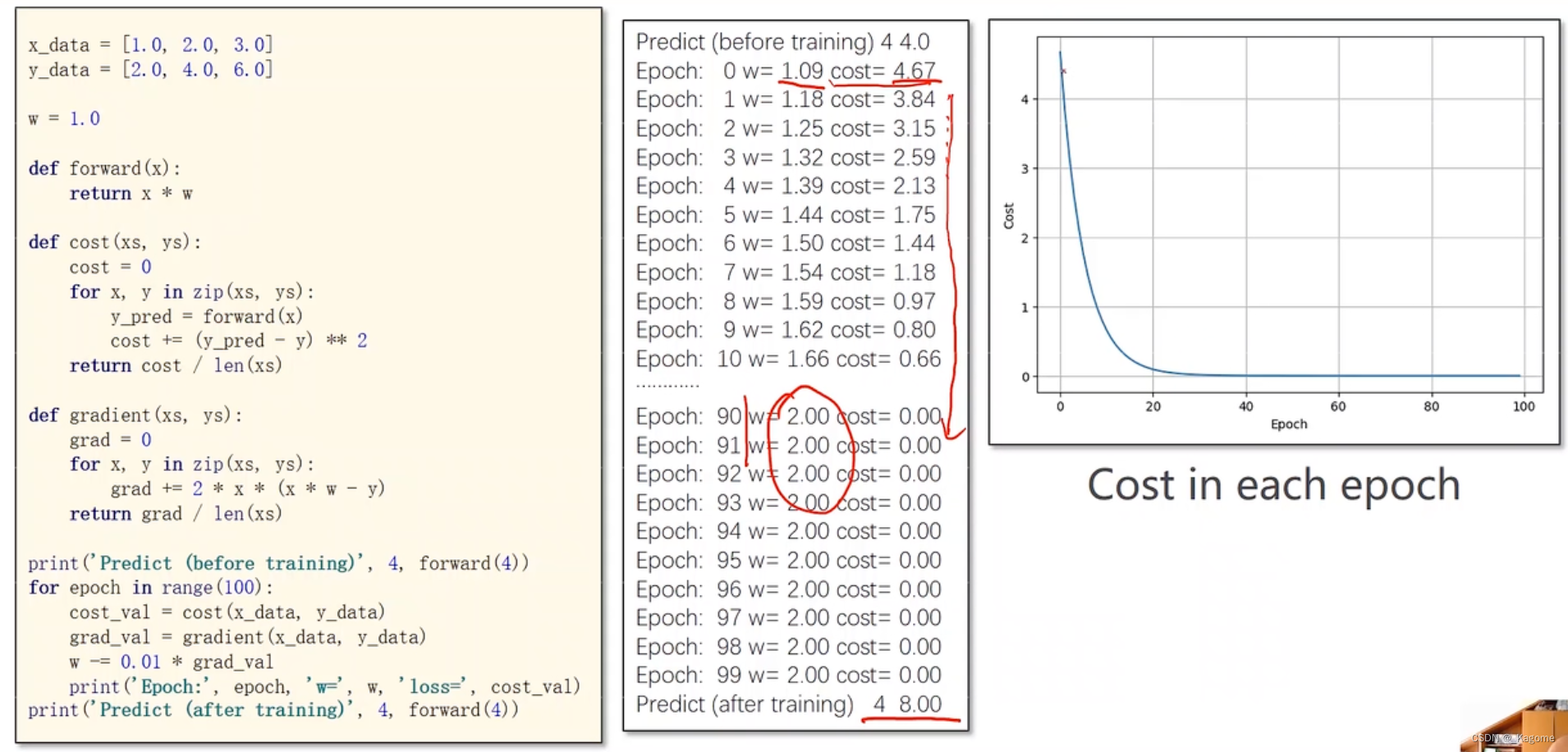
计算MSE的目标函数

套公式( )

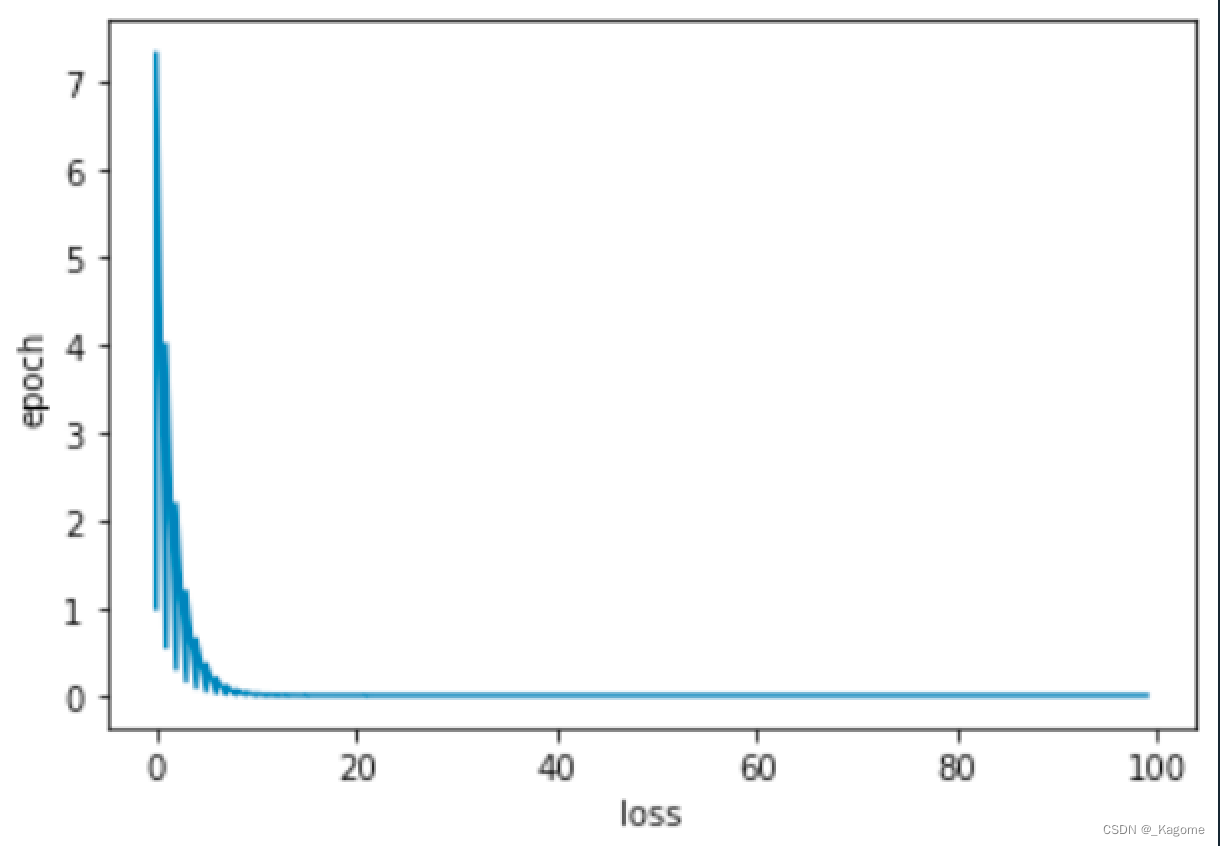
epoch进行100轮的训练

损失函数不断衰减,趋于收敛稳定
此图像为训练发散了,学习率取的太大
梯度下降:用整个成本均值的平均损失作为梯度下降的依据
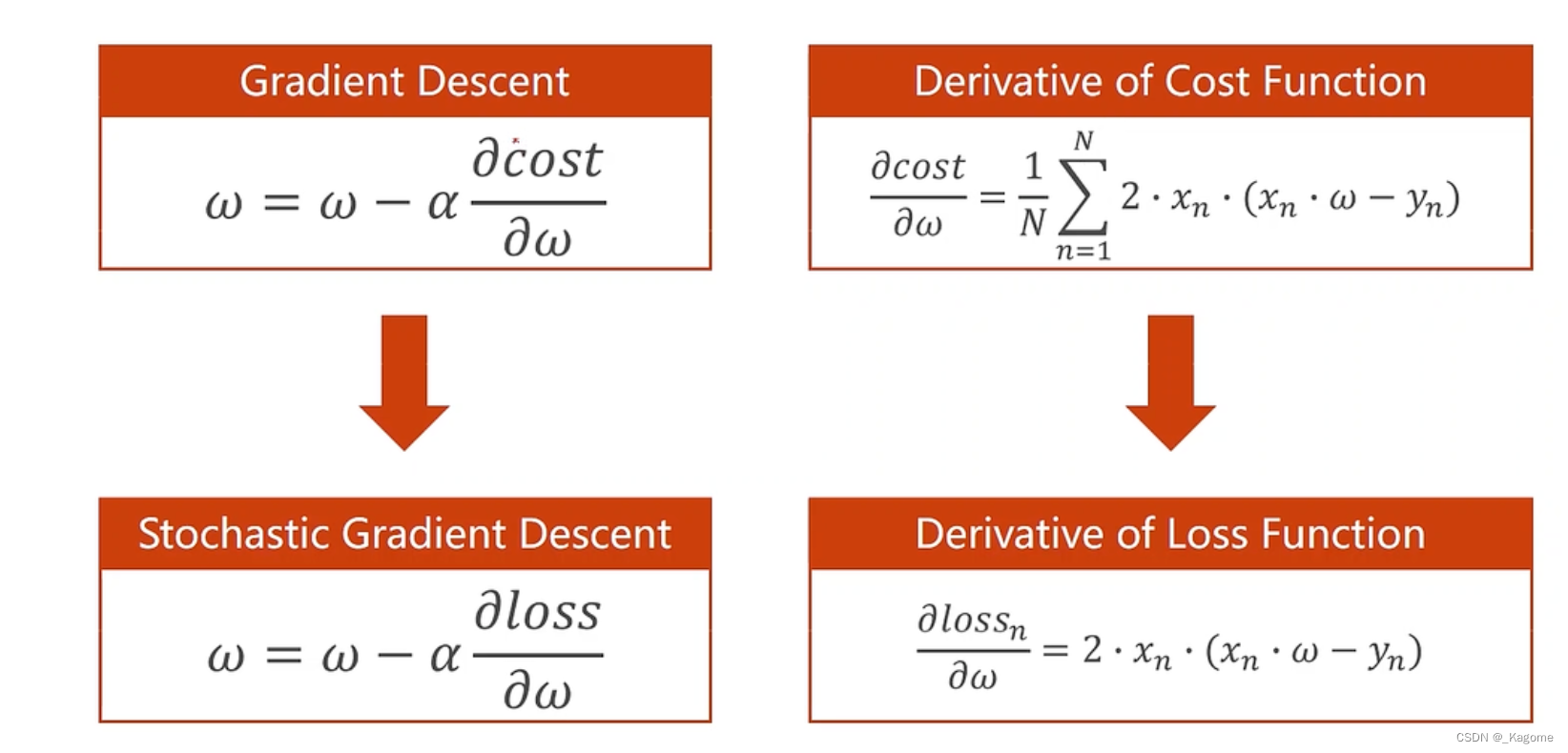
随机梯度下降:指的是,N个数据从中随机选一个数据,所以公式就是单个样本的损失函数对权重求导
eg:
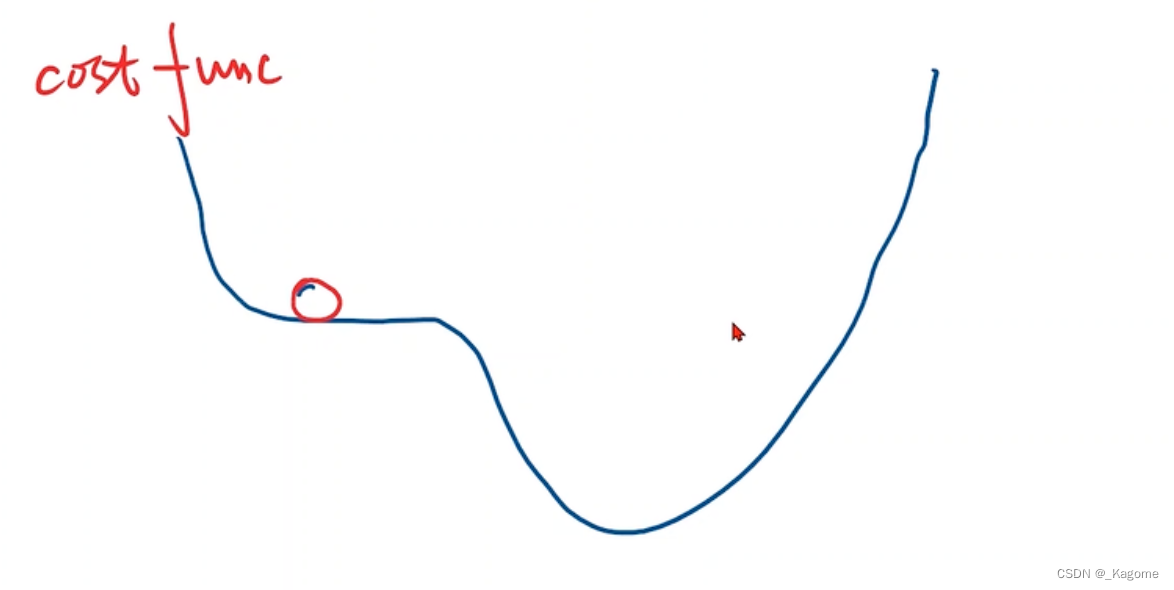
梯度下降是所有样本的,这样陷入到鞍点,就动不了
但是随机梯度下降:因为取的是随机样本,又因为带有噪声,所以会推动行进
单个样本以上

拿一个样本进行更新
更新:每一个样本对梯度进行更新
随机 梯度下降:拿单个样本的损失函数对权重求导,然后进行更新
综上:
批量梯度,批量随机梯度
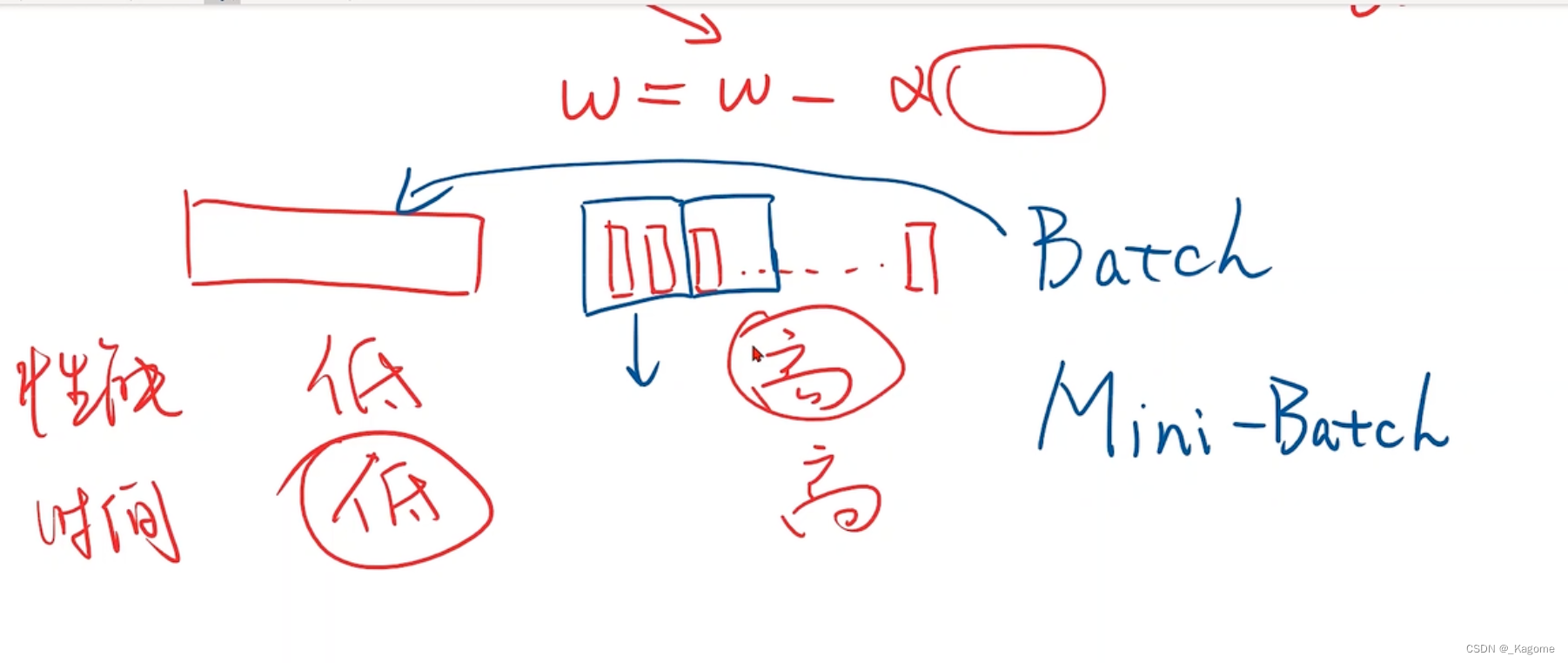
深度学习就是要看epoch轮数与损失之间的图像
代码实践
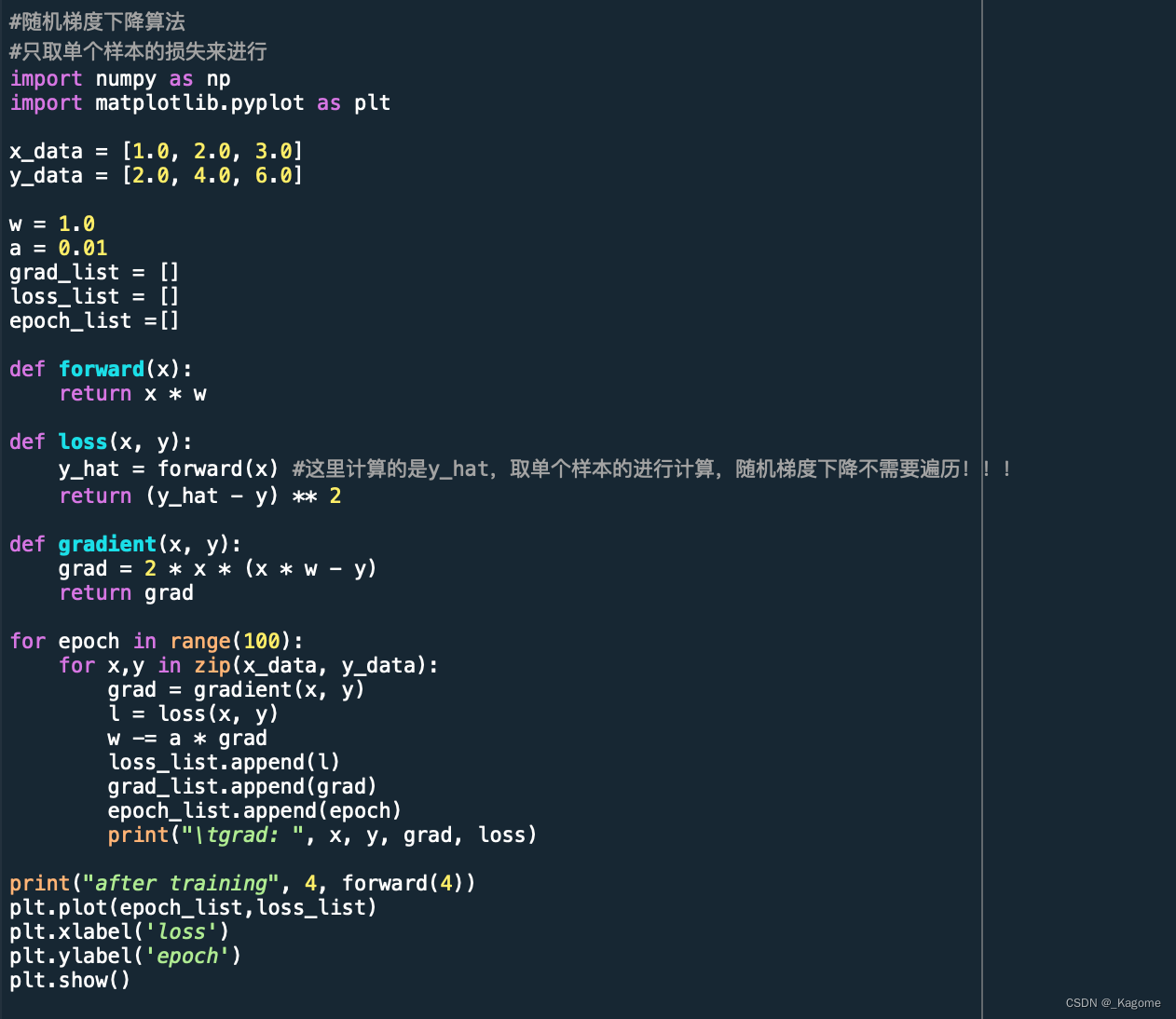
随机梯度下降,定义函数无需遍历所有。
函数也是向着收敛方向。
梯度下降需要遍历所有的点。
结果是收敛的。
















 3169
3169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









