









0 回顾
- 盘块号就是连续的扇区
- 得到盘块号就能进行下列操作
1 引入文件
- 普通用户使用生磁盘,还需要盘块号,所以很不方便
- 让普通用户理解,操作系统觉得没有必要,干脆隐藏起来
- 所以OS引入更高层次的概念-文件
- 有了文件后,用户再使用信息就变得更加直观自然
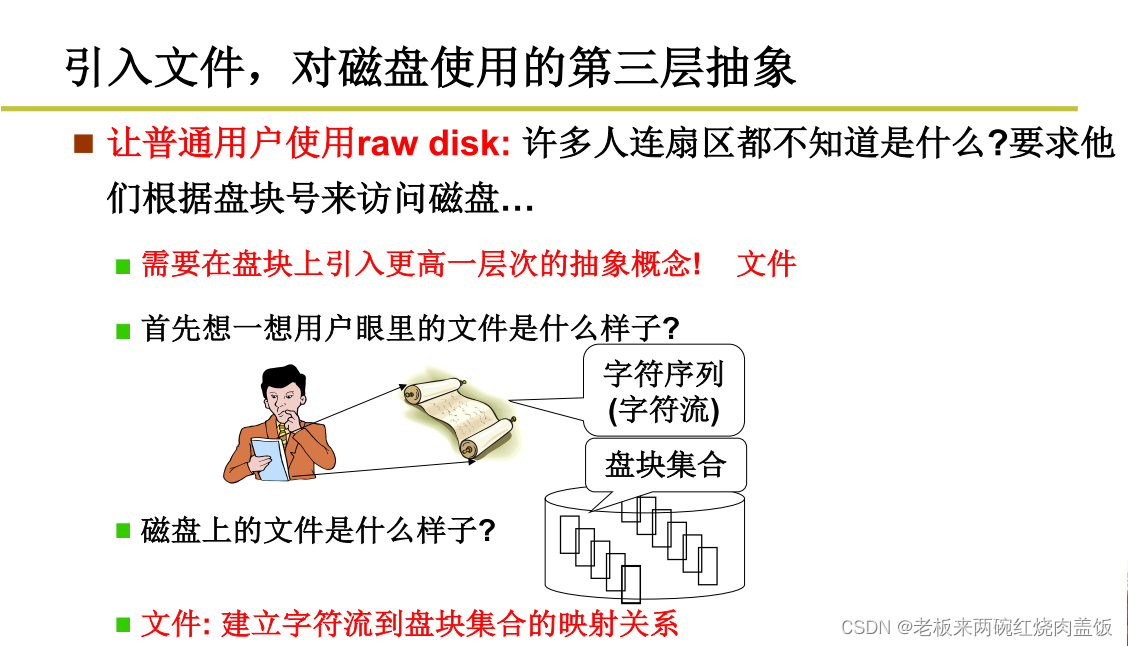
- 核心:从文件得到盘块号,建立映射关系
- 用户眼里的文件是字符流,所以无非就是建立从字符流到盘块的映射
- 得到盘块号之后,再用前一讲的方法,即可得到CHS
1.1 映射
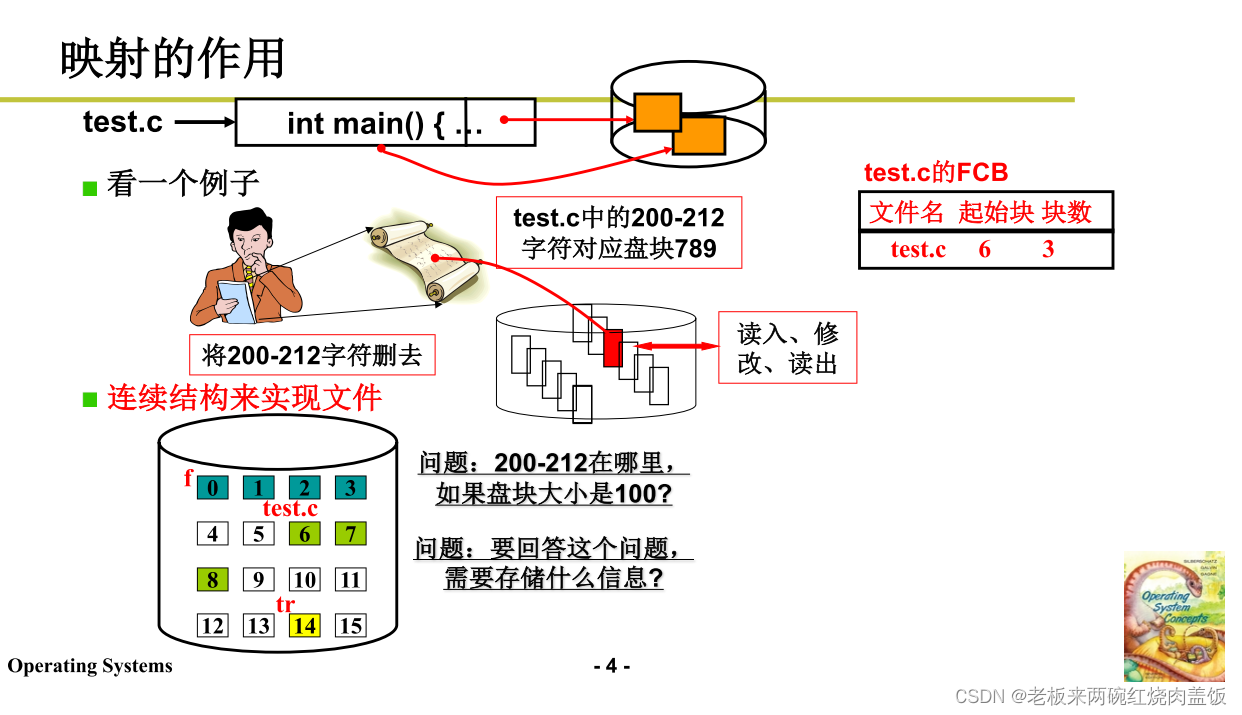
- 一个东西对应一个东西,找到200-212所对应的盘块号789
- 把盘块号发到电梯队列,到内存缓冲区
- 内存缓冲区再放到电梯队列,写出去,可能就把这几条语句删除了(如图要求是删除的)
- 所以我们对文件的使用以及操作系统对内存的使用是通过映射出来的
- 核心就是映射,映射是由操作系统进行维护的
- 空白是文件系统处理的,文件系统会对其进行缩进和调整,然后体现在内存缓冲区中,文件关闭的时候会从缓冲区写入磁盘
- 通过200-212计算盘块号
- 加入每100个字符流放到一个盘块
- 这样可以算出212在盘块8
- 那么问题来了,需要在test.c的FCB当中存储什么信息呢?
- 要存起始的盘块号
- 因为这里是以100个字符流为单位的,然后现在起始的字符流是200,除一下100(每个盘块号容纳的字符流),所以起始盘块号就是6
- 6 + 2 = 8 6 + 2 = 8 6+2=8就是计算出来的200-212对应的盘块号
- 所以这就是映射表设立的原因
- 用户随便输入进去第“多少个字符”,就可以查这个表,算出对应的 y y y值,这就建立映射了
- 综上:文件通过以上方式得到盘块号
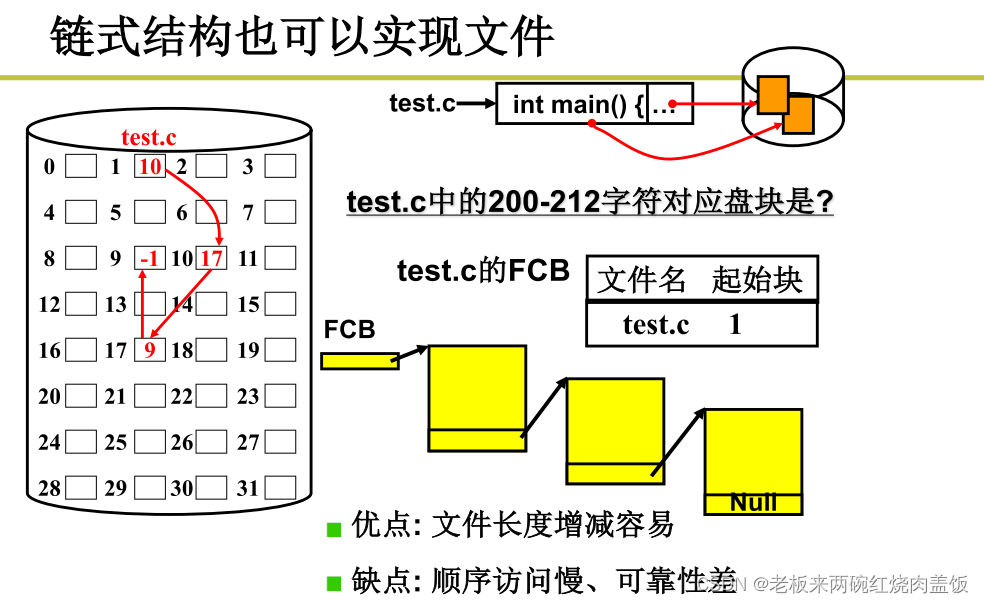
1.2 链式结构实现文件
- 增加到一定的时候,装不下了,要去到更大的空间,就很慢,这就是连续结构的缺点,以上就是数组实现,适合顺序读取,不适用动态增长
- 连续结构就是数组 O ( 1 ) O(1) O(1)时间复杂度读写,链式结构就是 O ( 1 ) O(1) O(1)增删改
- 以下为链表实现
- 根据字符流找到盘块号
- 链表更加灵活,但是是顺序存取,每次都得从起点开始读取
- 顺序不行,动态增长可以
1.3 索引结构实现文件
- index结构,inode
- 由块专门做索引
- 查找很快
- 因为这是单纯拿出一块空间来做索引
- 将文件字符流的关系映射成盘块号
- 通过索引块(目录)找到其他块(数据)
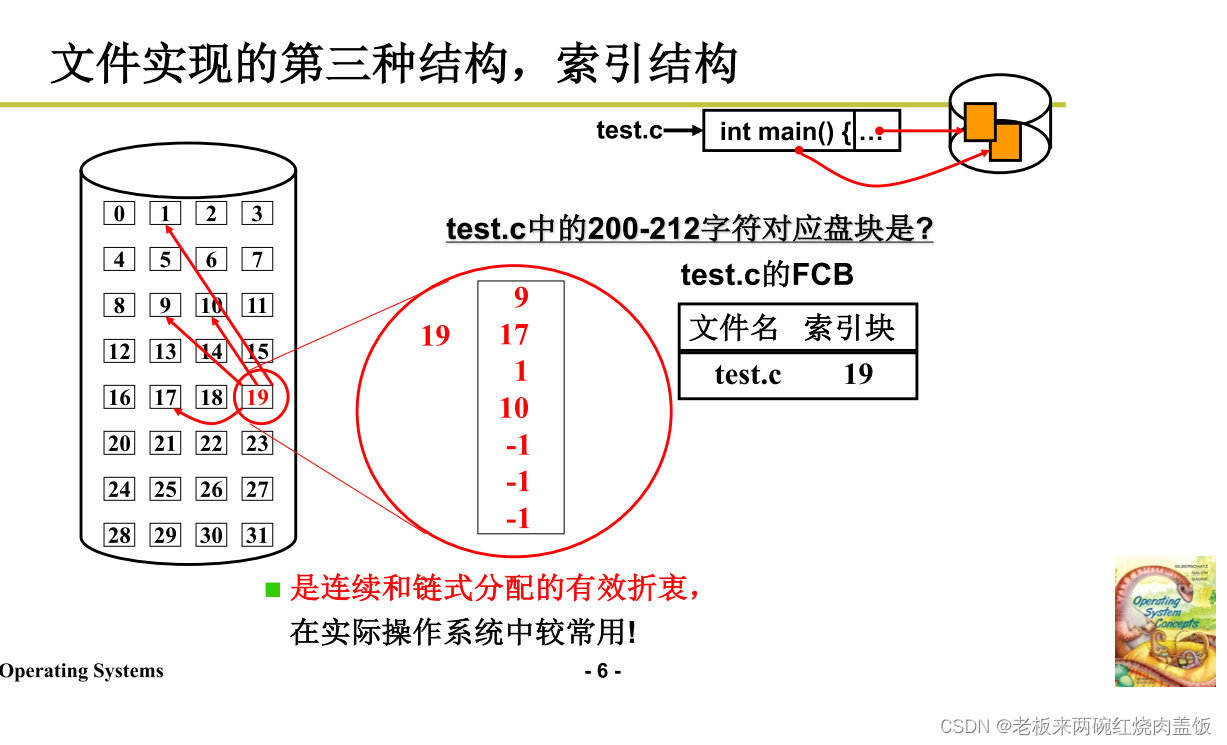
- 和内存管理一个道理,一级不够可以多级
- 盘块是多个扇区组成的,其目的就是为了减少寻址时间。当然,如果盘块也能连续,会进一步优化寻址时间

- 答案为A
2 总结
- 核心:从文件得到盘块号,建立映射关系
















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









