









转自:https://www.jianshu.com/p/6039042a3aaf
Dice系数
是一种集合相似度度量函数,通常用于计算两个样本的相似度(范围为[0, 1])
公式
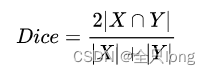
在语义分割中,X是Ground Truth分割图像 ,Y是预测的分割图像
由此可以得到dice loss
dice loss的提出就是解决前景比例太小的问题

Dice系数是分割效果的一个评判指标,其公式相当于预测结果区域和ground truth区域的交并比,所以它是把一个类别的所有像素作为一个整体去计算Loss的。因为Dice Loss直接把分割效果评估指标作为Loss去监督网络,而且计算交并比时还忽略了大量背景像素,解决了正负样本不均衡的问题,所以收敛速度很快
举例:
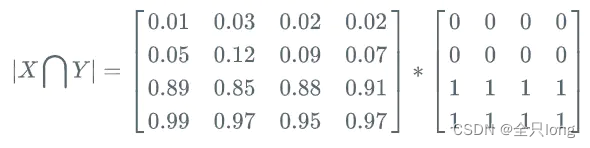



Dice Loss和交叉熵函数的比较:
交叉熵损失函数中交叉熵值梯度计算形式类似于p-t,其中,p 是softmax输出,t为target。
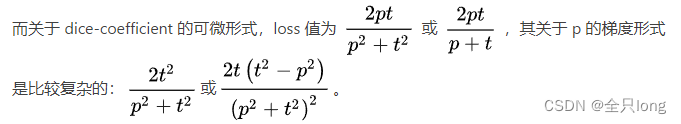
极端场景下,当 p 和 t 的值都非常小时,计算得到的梯度值可能会非常大. 通常情况下,可能导致训练更加不稳定。
直接采用 dice-coefficient 或者 IoU 作为损失函数的原因,是因为分割的真实目标就是最大化 dice-coefficient 和 IoU 度量。而交叉熵仅是一种代理形式,利用其在 BP 中易于最大化优化的特点。
另外,Dice-coefficient 对于类别不均衡问题,效果可能更优。然而,类别不均衡往往可以通过简单的对于每一个类别赋予不同的 loss 因子,以使得网络能够针对性的处理某个类别出现比较频繁的情况。因此,对于 Dice-coefficient 是否真的适用于类别不均衡场景,还有待探讨。















 2840
2840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









