







一、Attention 的架构
二、Self-attention代码
三、Encoder代码
四、Decoder代码
五、整体项目代码
六、说明
=======================================================
Attention架构
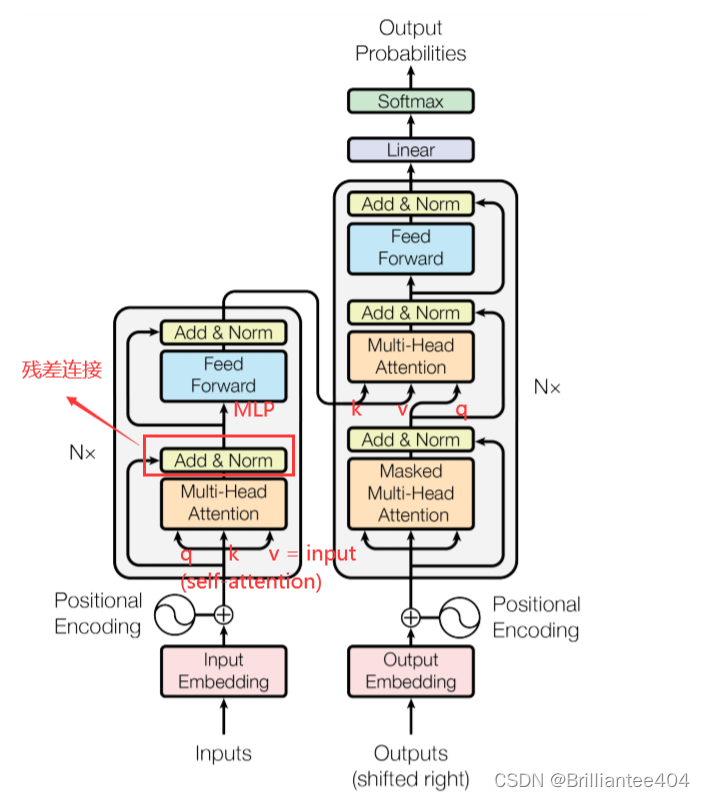
大概流程如下:
首先输入数据,经过向量表示成计算机可识别的数据后加入相关的位置信息此时的输入记为x。然后经过Encoder编码器,将X分别赋值给Q,K,V。(这里的Q,K,V含义不明白的可以看原论文)
然后经过注意力层,该层主要进行如下计算:

将得到的attention经过层归一化和残差连接后输入到一个类似于MLP的网络作为Encoder的输出。这里有以下几个疑问:
1.为什么采用LayerNorm而不采用BatchNorm?
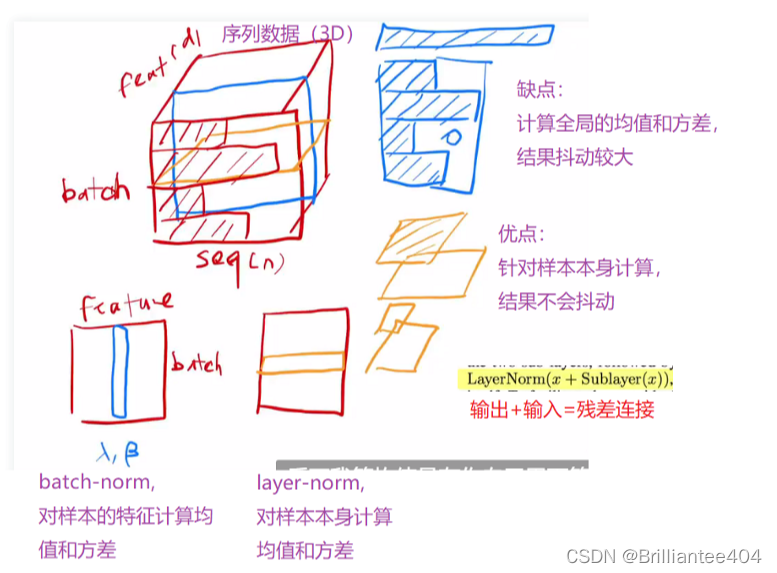
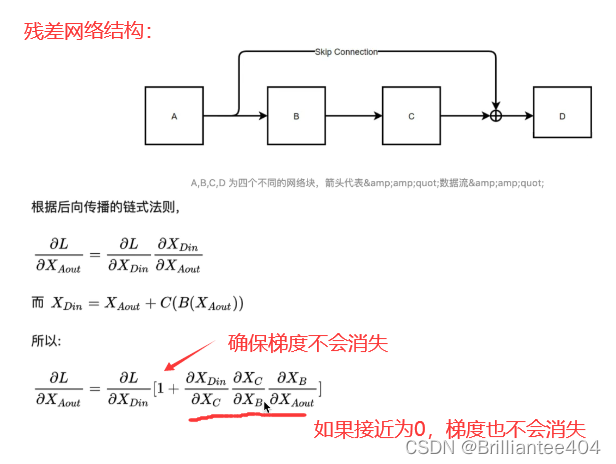
2. 为什么要采用残差连接(即输出的数据加上输入的数据)
从Encoder编码器的输出作为Decoder解码器的K,V参数值。此时的Q由前面的输出来进行相关的查询,此时用变量z来表示Encoder的输出。
在解码器中z经过Output和positioin的Embedding表示后经过带有mask的注意力机制网络后的结果作为Q,在进行类似于编码器的操作。最后通过线性层和归一化层输出最终的结果。
这里,解释一下mask的作用:
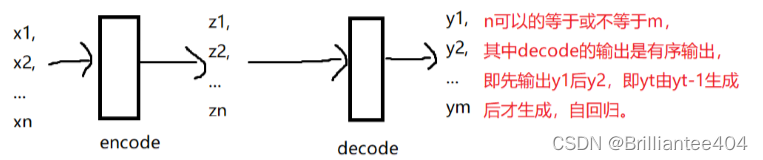
如上图所示,经过decoder后的输出结果y1,y2…yn是有序生成的,即必须先生成y1然后y2最后…yn,但生成y1的时候是不能知道y2的相关信息的。
而在进行attention计算时是计算Q与全局K的点击,所以需要mask机制来避免上述情况的产生。具体如何进行mask可看代码部分。
Self-attention代码
class SelfAttention(nn.Module):
def __int__(self,embed_size,heads):
#参数初始化
super(SelfAttention,self).__int__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size
#断言是否能分成多头注意力
assert(self.head_dim*heads == embed_size), "Embed size needs to be div by heads"
#规定相关参数的维度
self.values = nn.Linear(self.head_dim,self.head_dim,bias=False)
self.keys = nn.Linear(self.head_dim,self.head_dim,bias=False)
self.queries = nn.Linear(self.head_dim,self.head_dim,bias=False)
self.fc_out = nn.Linear(heads*self.head_dim,embed_size)
def forward(self,values,keys,query,mask):
# 返回该数组的行数
N = query.shape[0]
# 返回该数组的列数,分别赋值给qkv
value_len,key_len,query_len = values.shape[1],keys.shape[1],query.shape[1]
#将相关表示分成多个快(多头注意力机制)
values = values.reshape(N,value_len,self.heads,self.head_dim)
keys = keys.reshape(N,key_len,self.heads,self.head_dim)
queries = query.reshape(N,key_len,self.heads,self.head_dim)
#为相关参数进行赋值操作
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
#公式中的Q×K
energy = torch.einsum("nqhd,nkhd→nhqk",[queries,keys])
#mask操作,将位置为0的数用负无穷小代替
if mask is not None:
energy = energy.masked_fill(mask == 0 , float("-1e20"))
#计算attention,具体看公式
attention = torch.softmax(energy/(self.embed_size**(1/2)),dim=3)
out = torch.einsum("nhql,nlhd→nqhd",[attention,values]).reshape(N,query_len,self.heads*self.head_dim)
#最后经过类MLP层输出最终的结果
out = self.fc_out(out)
return out
Encoder代码
class TransformerBlock(nn.Module):
def __int__(self,embed_size,heads,dropout,forward_expansion):
super(TransformerBlock,self).__int__()
#调用SelfAttention计算注意力分数
self.attention = SelfAttention(embed_size,heads)
#从Encoder架构中看到有两个Norm层(残差连接那里)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
#定义一个类MLP的网络
self.feed_forward = nn.Sequential(
nn.Linear(embed_size,forward_expansion*embed_size),
nn.ReLU(),
nn.Linear(forward_expansion*embed_size,embed_size)
)
#设置丢弃率
self.dropout = nn.Dropout(dropout)
def forward(self,value,key,query,mask):
#通过QKV计算
attention = self.attention(value,key,query,mask)
#残差连接1
x = self.dropout(self.norm1(attention+query))
#经过类MLP网络
forward = self.feed_forward(x)
#残差连接2
out = self.dropout(self.norm2(forward+x))
#返回Encoder的输出
return out
class Encoder(nn.Module):
#初始化超参数
def __init__(self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
):
super(Encoder,self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size,embed_size)
self.position_embedding = nn.Embedding(max_length,embed_size)
# 定义Transformer层
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout = dropout,
forward_expansion = forward_expansion,
)for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self,x,mask):
N,seq_length = x.shape
#计算位置编码信息
positions = torch.arange(0,seq_length).expand(N,seq_length).to(self.device)
#将词表示加上位置表示后作为Encoder的输入
out = self.dropout(self.word_embedding(x)+self.position_embedding(positions))
#经过N层的Encoder
for layer in self.layers:
out = layer(out,out,out)
return out
Decoder代码
class DecodeBlock(nn.Module):
def __int__(self,embed_size,heads,forward_expansion,dropout,device):
super(DecodeBlock,self).__int__()
#计算注意力机制
self.attention = SelfAttention(embed_size,heads)
#Decoder的残差连接那里
self.norm = nn.LayerNorm(embed_size)
self.transformer_block = TransformerBlock(
embed_size,heads,dropout,forward_expansion
)
self.dropout = nn.Dropout(dropout)
def forward(self,x,value,key,src_mask,trg_mask):
attention = self.attention(x,x,x,trg_mask)
#残差连接
query = self.dropout(self.norm(attention+x))
out = self.transformer_block(value,key,query,src_mask)
return out
class Decoder(nn.Module):
# 初始化超参数
def __int__(self,
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length
):
super(Decoder,self).__int__()
self.device = device
self.word_embedding = nn.Embedding(trg_vocab_size,embed_size)
self.position_embedding = nn.Embedding(max_length,embed_size)
# 定义解码器中注意力层
self.layers = nn.ModuleList(
[DecodeBlock(embed_size,heads,forward_expansion,dropout,device)
for _ in range(num_layers)]
)
self.fc_out = nn.Linear(embed_size,trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self,x,enc_out,src_mask,trg_mask):
N,seq_length = x.shape
positions = torch.range(0,seq_length).expand(N,seq_length).to(self.device)
x = self.dropout((self.word_embedding(x)+self.position_embedding(positions)))
for layer in self.layers:
x = layer(x,enc_out,enc_out,src_mask,trg_mask)
out = self.fc_out(x)
return out
整体项目代码
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size=256,
num_layers=6,
forward_expansion=4,
heads=8,
dropout=0,
device="cuda",
max_length=100):
super(Transformer,self).__init__()
self.encoder = Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length
)
self.decoder = Decoder(
trg_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length
)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self,src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask.to(self.device)
def make_trg_mask(self,trg):
N,trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len,trg_len))).expand(N,1,trg_len,trg_len)
return trg_mask.to(self.device)
def forward(self,src,trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src,src_mask)
out = self.decoder(trg,enc_src,src_mask,trg_mask)
return out
说明
相关参考资料:
(1)Transformer经典论文解读















 3383
3383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









