






在医学科研、特别是观察性研究领域,无论是现况调查、病例对照研究、还是队列研究,经常遇到分类的健康结局,包括二分类(如:生存与死亡、阳性与阴性、发病与未发病)或者一些可进行分类的生理生化指标等(如:血压值、血镁值、血脂和胆固醇等)时,线性回归分析往往无法进行,此时可以考虑Logistic回归模型。
实际中,许多人习惯性使用SPSS进行回归分析,但是SPSS无法进行批量单因素分析,还需要手动绘制三线表,费时又费力。而R语言虽然可以进行批量单因素分析并制作三线表,但具有一定的门槛,需要编程基础,估计一时三刻也学不会。因此,这里结合一篇文献与实操案例为大家介绍一个智能在线免费统计分析平台——风暴统计。
logistic回归具体网址:https://shiny.medsta.cn/log/
或者百度、必应Bing搜索“风暴统计”
本平台上线的所有工具都是免费的

这里我们不再赘述数据的导入与整理过程,详细教程大家可以点击下方链接:
1.logistic回归基本过程介绍
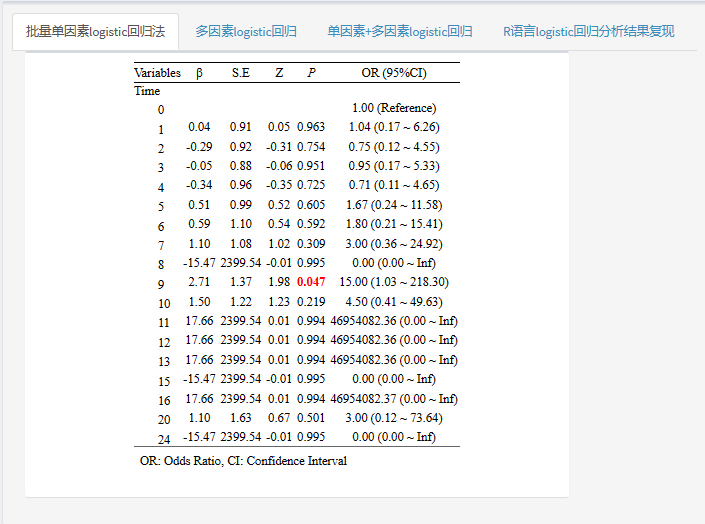
目前风暴统计平台可以非常快速准确的完成logistic回归,只需2步!
选入回归自变量
选择自变量筛选方式
全部是菜单式操作,完成后,界面直接给出规范三线表结果!还可以随着变量的调整实时更新结果,在数据探索初期,可以节省不少工作量!在撰写报告时,也不用再手工绘制三线表,填写数据了!统计小白也可以轻松上手!
2.logistic回归自变量选择
首先,选入变量,包括因变量、定量自变量、分类自变量。

①因变量
这里因变量建议使用0和1进行表示,0代表阴性结局(如:未患病、二分类变量中值较小的组),1代表阳性结局(如:患病或二分类结局中值较大的组)。
②定量自变量
平台会将分类数大于5的变量自动归为定量自变量,并在选取定量自变量时,优先显示在上方,便于选取。
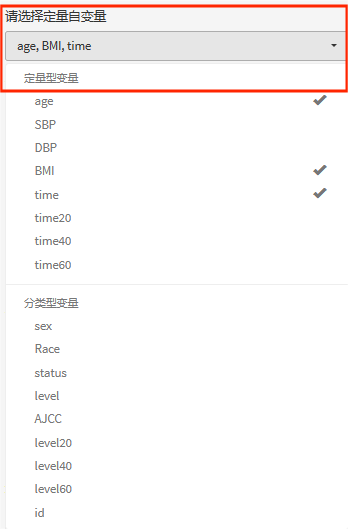
③分类自变量
同理,分类数小于5类的变量归入分类变量,在选取变量时,优先显示分类变量。
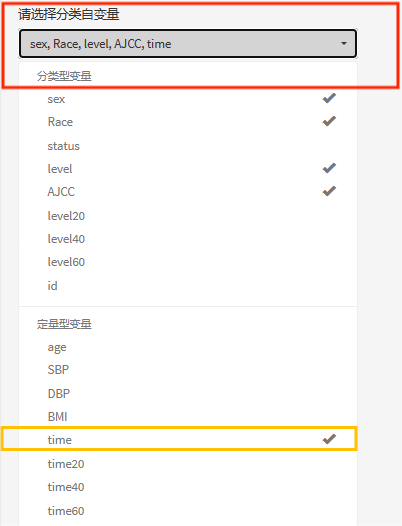
假如分析中确实存在分类数大于5的分类变量,被平台归为了定量型,那么在分类自变量这里也是可以直接选取的(如上图中的"time"变量),回归结果也将按照分类数据进行展示。
接着,选择自变量的筛选方式,包括先单后多法、逐步回归法。

3.开展先单后多方法分析
根据研究需要,如果需要开展先单后多的自变量筛选方式,那么“是否开展逐步回归分析”选择“否”。
P阈值自行选择,如果自变量个数过少,可以适当放宽标准,0.1、0.2也都是可以的。当选择不限制时,选入的全部自变量都将纳入多因素回归分析。

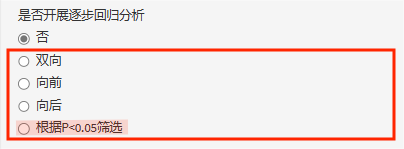
4.开展逐步回归方法分析
逐步回归方法,平台也提供了多种选择:双向逐步回归,向前逐步回归,向后逐步回归以及考虑到有时P值大于0.05的变量在逐步回归时也会留在模型中,新增了根据P<0.05的原则开展逐步回归!
注:先单后多与逐步回归是两种不同的自变量筛选方式,先单后多主要根据单因素P阈值进行筛选;逐步回归则是通过变量的逐个纳入与剔除,以AIC值最小作为最优模型选择准则。因此有些变量P值大于预设的阈值但仍保留在逐步回归模型中也是正常的哦,想要避免这种情况的发生,可以选择“根据P<0.05筛选”的逐步回归!
5.下载结果
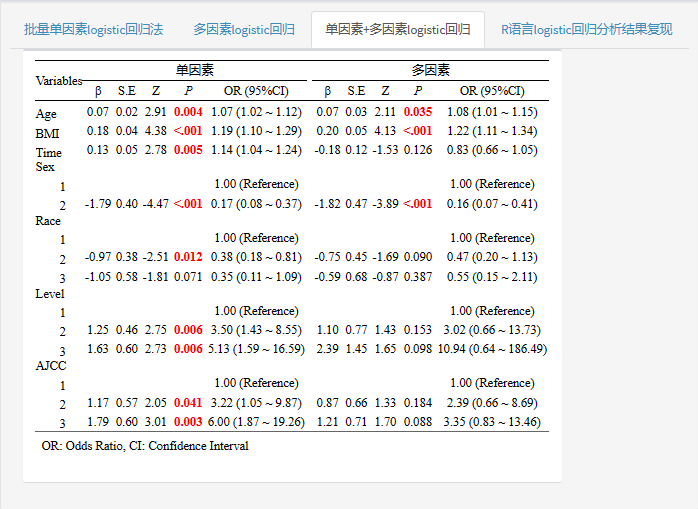
平台给出了多种结果展示,仅展示单因素回归结果,仅展示多因素回归结果,单因素+多因素显示在同一个表格中!
然后也可以选择小数位数,默认情况下,P值为3位小数,其他统计量为2位小数。指定小数位数后,P值与统计量的小数位数将会统一。调整完成后,下载最终的三线表结果,平台支持下载excel或word!
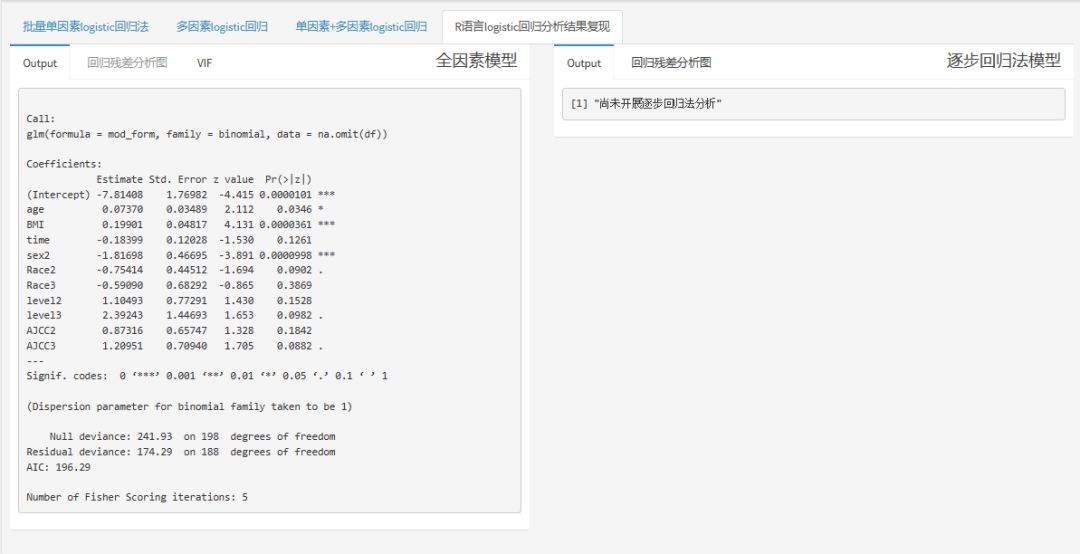
6.查看R语言分析源码
目前风暴统计还会给出R语言输出结果,回归残差分析图,方差膨胀因子(VIF)。
左侧为全因素模型,右侧为逐步回归模型。
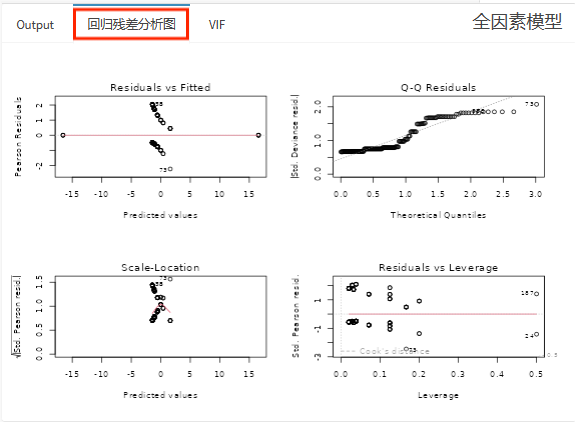
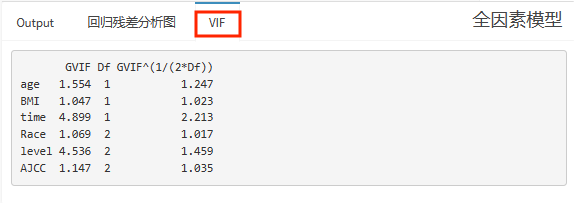
这里简单解释一下方差膨胀因子:方差膨胀因子是检验自变量间共线性问题的常用方法,如果自变量间共线性过强,会导致分析结果不稳定,还可能出现回归系数的符号与实际情况完全相反的情况,根据VIF值进行判断,如果存在共线性强的变量,建议剔出模型。
当0<VIF<5,没有共线性; 当5<VIF<10,弱共线性; 当10<VIF<100,中等共线性; 当VIF>100,严重共线性。 |
以上就是使用风暴统计一站式进行logistic回归分析的详细说明啦!目前平台建设之初,还有许多不足之处,欢迎大家多多提意见!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









