






培训通知
Nhanes数据库数据挖掘,快速发表发文的利器,你来试试吧!欢迎报名郑老师团队统计课程,4.20直播。
最近很多人咨询关于潜变量模型的R语言代码。潜变量模型包括了基于潜变量思想的多种方法模型:
适用于定性数据的潜类别分析Latent Class Analysis (LCA)
适用于定量数据的潜剖面分析Latent Profile Analysis (LPA)
适用于纵向数据的潜类别增长模型Latent class growth analysis(LCGA)和潜类别增长混合模型Latent growth mixture modelling(LGMM)等。
因此,本文就针对上述几类模型讲述其在R语言中如何实现。
本公众号回复“沙龙”即可获得R语言代码,PPT,数据等资料。 如果您需要详细的介绍与指导,可以加入我们郑老师团队的"统计实战营",针对潜变量模型进行一对一与学习。郑老师助教微信号zz566665 |
一、轨迹模型R语言实践
1.安装和加载lcmm包和加载数据集
首先,构建轨迹模型需要安装和加载lcmm包,并加载好数据集。
可以看到数据集中,id表示研究对象的ID,age表示测量bmi时研究对象的年龄,bmi表示研究对象在当前年龄下测量的BMI,这是一个典型的纵向数据,适合构建轨迹模型。
2.使用hlme()函数构建轨迹模型
使用hlme()函数构建轨迹模型的基本形式如下图。

构建轨迹模型的第一步,我们需要构建好分组数为1的初始模型来作为后续确定最佳分组数的参照,在这里我们以构建LGMM为例。

3.根据BIC准则来选择最佳潜在类别数(ng)
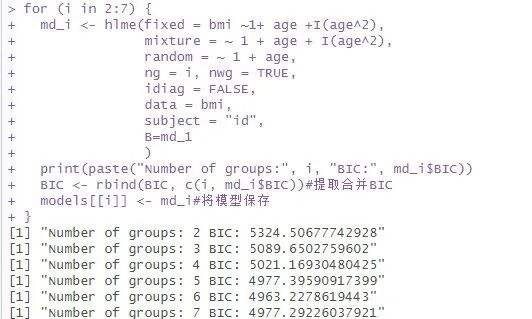
下面代码通过一个循环语句构建了分组数为2到7的潜类别增长混合模型并输出模型的BIC值。

代码运行结果如下图所示,可以看到分组数为6时的模型BIC最小。
4.查看最小的BIC值对应的最优模型及其评价指标
我们提取分组数为6的模型作为最优模型,并且可以查看模型的多个评价参数。

5.模型可视化

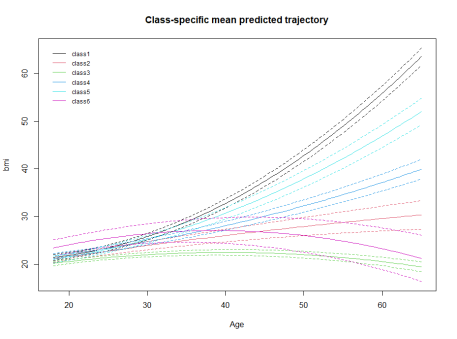
通过上面的代码来绘图,可以得到所构建模型的轨迹图如下。
6.整合数据集
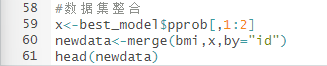
通过以上代码将构建模型所得到的潜变量提取整合到原始数据集中,整合数据如下图所示,可以看到class即为轨迹模型所生成的潜变量。
(注:本公众号回复“沙龙”即可获取R语言代码)
二、潜剖面分析R语言实践
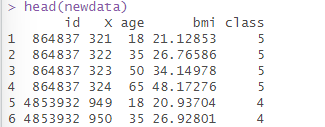
1.安装和加载mclust包和加载数据集
首先,构建轨迹模型需要安装和加载mclust包,并加载好数据集。
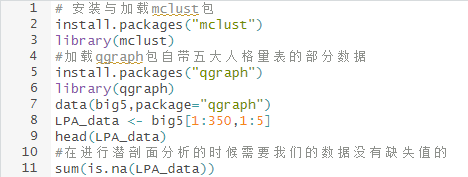
可以看到数据集中,每一列表示研究对象的某个维度评分,每一项维度评分都是从1到5分的定量数据,适合使用潜剖面分析方法,并且数据集不存在缺失。

2.根据BIC准则来选择最佳潜在剖面数:
R语言的mclust包提供了mclustBIC函数可以直接查看通过BIC准则筛选出的最优模型的分组数,代码如下。

代码运行结果如下图所示,可以看到分组数为9的EEV模型BIC最小。

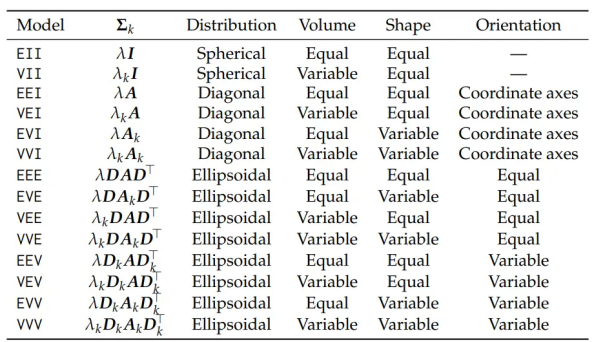
通过mclust包拟合的模型有多种不同的假设,详见下图,我们只需简单了解一下筛选出的EEV模型是其中一种假设模型即可。
3.根据ICL来选择最佳潜在剖面数:
复杂的模型通常需要多个评价指标来进行多重参考,R语言的mclust包还提供了mclustICL函数可以直接查看通过ICL指标筛选出的最优模型的分组数,代码如下。

代码运行结果如下,最优的前两个模型与BIC指标筛选出的一样是分组数分别为9和5的EEV模型。

4.根据BLRT来选择最佳潜在剖面数:
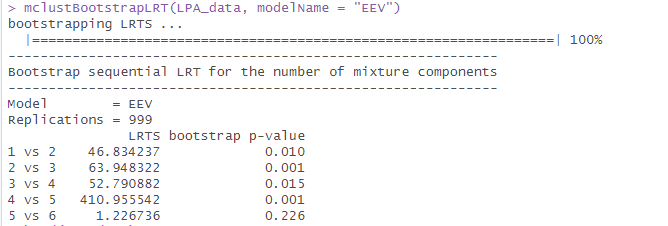
R语言的mclust包还提供了mclustBootstrapLRT函数可以直接查看通过BLRT指标评价的模型是否显著优于前一个模型,代码如下。

代码运行结果如下,EEV模型在分组数为6时已经与分组数为5的模型无显著差异了,此时我们可以结合三个指标选择分组数为5的EEV模型作为最终的模型。
5.拟合模型并查看模型信息:
我们提取分组数为5的EEV模型作为最优模型,并且可以查看模型的多个评价参数。

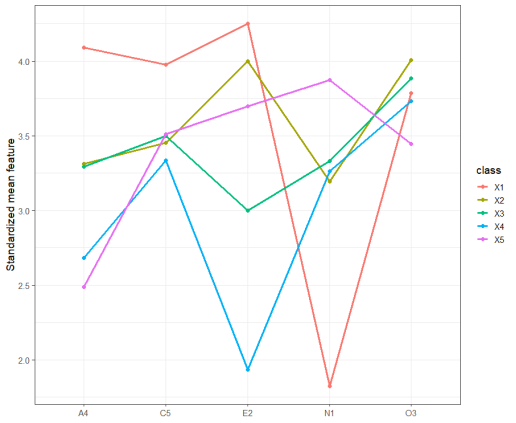
6.模型可视化

通过上面的代码来绘图,可以得到所构建模型的剖面图如下。
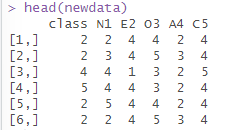
7.整合数据集

通过以上代码将构建模型所得到的潜变量提取整合到原始数据集中,整合数据如下图所示,可以看到class即为潜剖面分析所生成的潜变量。
(注:本公众号回复“沙龙”即可获取R语言代码)
三、潜类别分析R语言实践
1.安装和加载poLCA包和加载数据集
首先,构建轨迹模型需要安装和加载poLCA包,在这里为了更好地展示和实践潜类别分析,我们构建一个虚拟数据集。
可以看到数据集中,id表示研究对象的ID,sex表示研究对象的性别,race表示研究对象的种族,married表示研究对象的婚姻状况,三个变量都是定性数据,适合使用潜类别分析。
2.使用poLCA()函数构建轨迹模型
使用poLCA()函数构建轨迹模型的基本形式如下图。

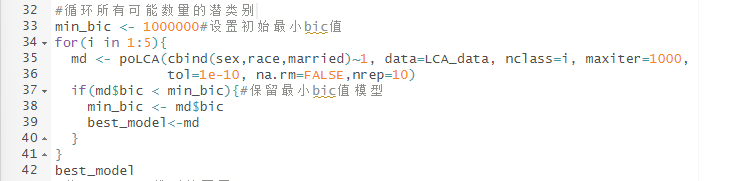
3.根据BIC准则来选择最佳潜在类别数并查看模型
下面代码通过一个循环语句构建了分组数为1到5的潜类别模型并输出BIC最小的模型。
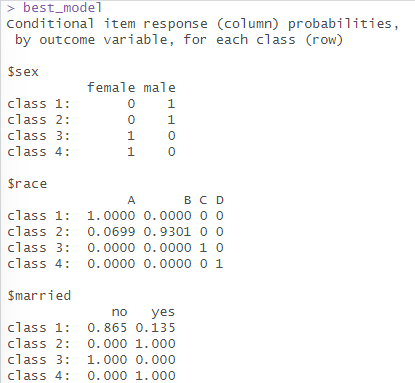
代码运行结果如下图所示,可以看到通过BIC准则筛选出的最优模型分组数为4,还可以查看模型的一系列常见的评价参数。

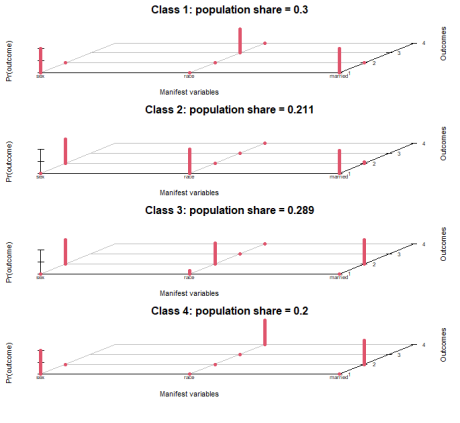
4.模型可视化

通过上面的代码可以直接得到所构建模型的可视化3D图如下。
5.整合数据集

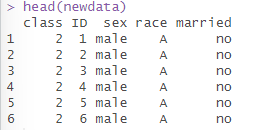
通过以上代码将构建模型所得到的潜变量提取整合到原始数据集中,整合数据如下图所示,可以看到class即为潜类别分析所生成的潜变量。
本公众号回复“沙龙”即可获得R语言代码,PPT,数据等资料。 如果您需要详细的介绍与指导,可以加入我们郑老师团队的"统计实战营",针对潜变量模型进行一对一与学习。
|

本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10余门课。如果您有需求,不妨点击查看: 二、数据分析服务 浙江中医药大学郑老师团队接单各项医学研究数据分析的服务,提供高质量统计分析报告。有兴趣了解一下详情: |















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









