






临床预测模型(clinical prediction model),是指利用数学模型估计研究对象当前患有某病的概率或者将来发生某种结局的可能性。也就是说,临床预测模型是通过已知特征来预测未知,而模型就是一个数学公式,也就是把已知的特征通过这个模型计算出未知结局发生的概率。
临床预测模型作为临床研究的“高阶玩法”,不仅仅是改变临床实践的重要途径,更是发表高分SCI文章的热门选择。但不论零基础的小白,还是已经了解过临床预测模型的同学,刚开始都会一头雾水。虽然简单概括,Cox回归预测模型的基础统计策略离不了“一表四图”,即均衡性表、列线图、校准图、ROC图、DCA图。但是通过R语言完成需要几百行代码,想想就头大。
这里为大家介绍一个可以一站式完成Cox回归预测模型分析的“神器”——风暴统计。操作简单,分分钟完成“一表四图”,还可以免费下载完整表格与图片结果。
今天我们就通过利用风暴统计平台复现一篇SEER数据库文章,为大家展示构建Cox预测模型的全过程并详细介绍网站的各种功能及使用方法。

主要内容包括: 一、文献解读 二、利用在线网站“风暴统计”复现 |
一、文献解读
案例文献是沈阳医学院公共卫生学院学者基于SEER数据库的一项回顾性研究,旨在建立一个列线图来预测老年恶性骨肿瘤(MBT)患者的总生存期(OS)。

1. 摘要
背景:恶性骨肿瘤(MBT)是老年患者死亡的原因之一。我们研究的目的是建立一个列线图来预测老年MBT患者的总生存期(OS)。
方法:从SEER数据库下载了2004年至2018年所有老年MBT患者的临床病理数据。他们被随机分配到训练集(70%)和验证集(30%)。采用单因素和多因素Cox回归分析确定老年MBT患者的独立危险因素。基于这些危险因素构建列线图,以预测老年MBT患者的1年,3年和5年OS。然后,利用一致性指数(C指数)、校准曲线和受试者工作曲线下面积(AUC)来评价预测模型的准确性和判别力。决策曲线分析(DCA)用于评估列线图的临床潜在应用价值。根据列线图上的分数,将患者分为高风险组和低风险组。Kaplan-Meier(K-M)曲线用于测试两名患者之间的生存差异。
结果:从SEER数据库下载了2004年至2018年所有老年MBT患者的临床病理数据。他们被随机分配到训练集(70%)和验证集(30%)。采用单因素和多因素Cox回归分析确定老年MBT患者的独立危险因素。基于这些危险因素构建列线图,以预测老年MBT患者的1年,3年和5年OS。然后,利用一致性指数(C指数)、校准曲线和受试者工作曲线下面积(AUC)来评价预测模型的准确性和判别力。决策曲线分析(DCA)用于评估列线图的临床潜在应用价值。根据列线图上的分数,将患者分为高风险组和低风险组。Kaplan-Meier(K-M)曲线用于测试两名患者之间的生存差异。
结论:我们建立了一个新的列线图来预测老年MBT患者的1年,3年,5年的OS。该预测模型可以帮助医生和患者制定治疗计划和后续策略。
2. 数据介绍
文献共纳入1641名2004-2018诊断的老年MBT患者的临床病理数据。暴露因素包括年龄、种族、性别、诊断年份、组织学类型、分级、分期、原发位置、TNM分期、肿瘤大小、是否化疗、是否放疗及手术方式。
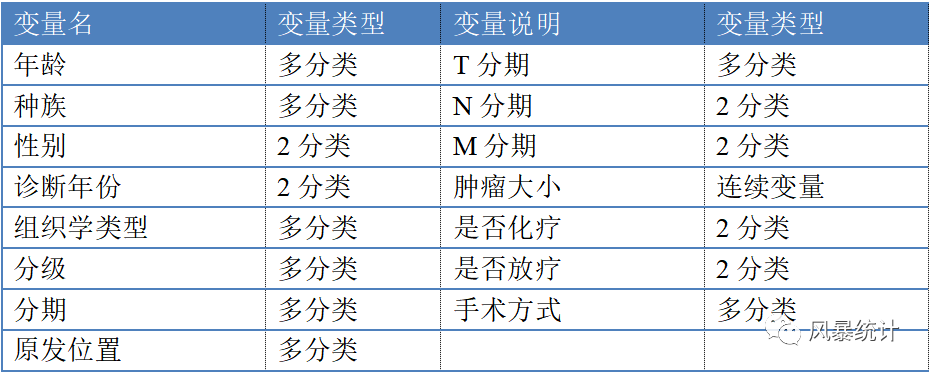
3.研究结果
这篇文献构建Cox回归预测模型的统计思路十分清晰。首先按照7:3将数据集进行拆分获得训练集与验证集,然后做均衡性检验,比较训练集和验证集的差异性,再做单因素和多因素Cox回归,筛选变量构建列线图预测模型,最后通过校准图、ROC曲线、DCA曲线对模型的校准度、区分度以及临床决策的实际需要进行评价。
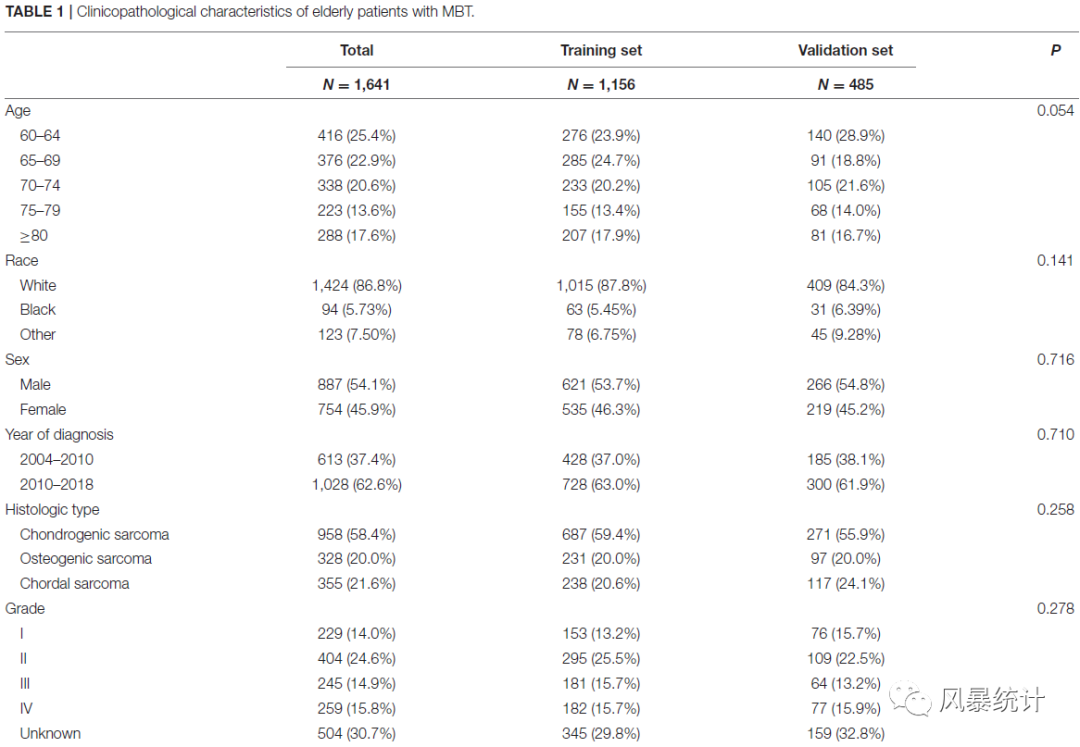
①基线均衡表
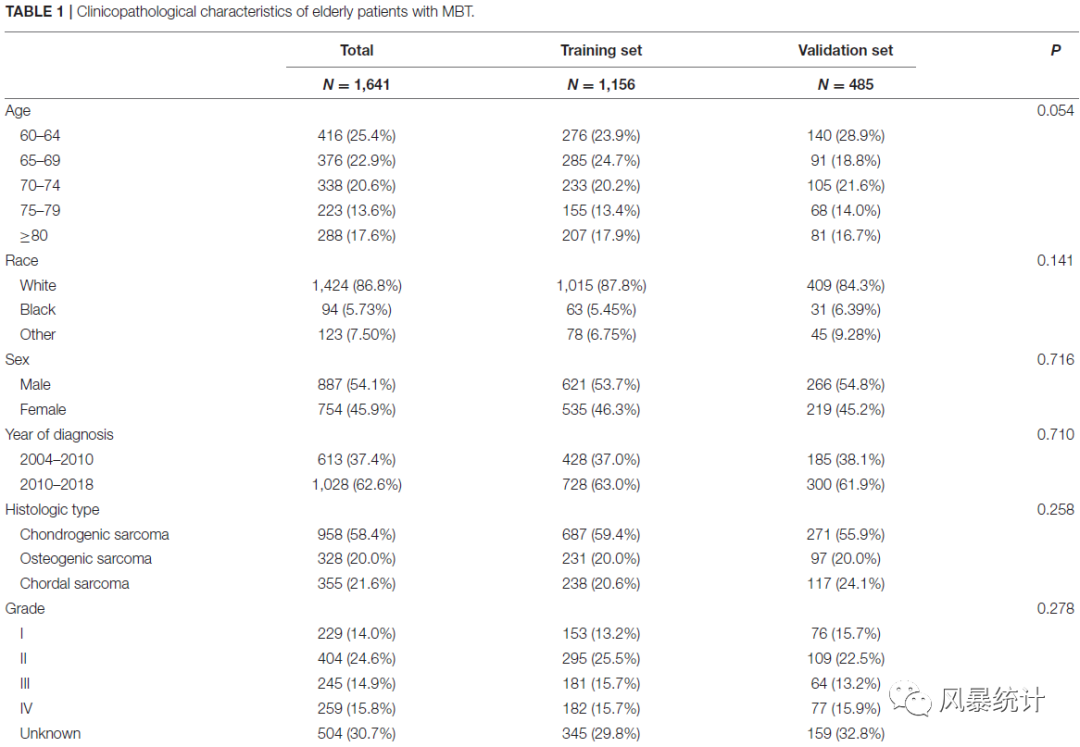


②列线图的建立
利用训练集数据,通过单因素Cox回归与多因素Cox回归筛选预测变量。这里作者并未使用先单后多或者是逐步回归法筛选预测变量,可能从临床实际考虑的更多,在实操过程中推荐大家使用逐步回归法进行筛选。


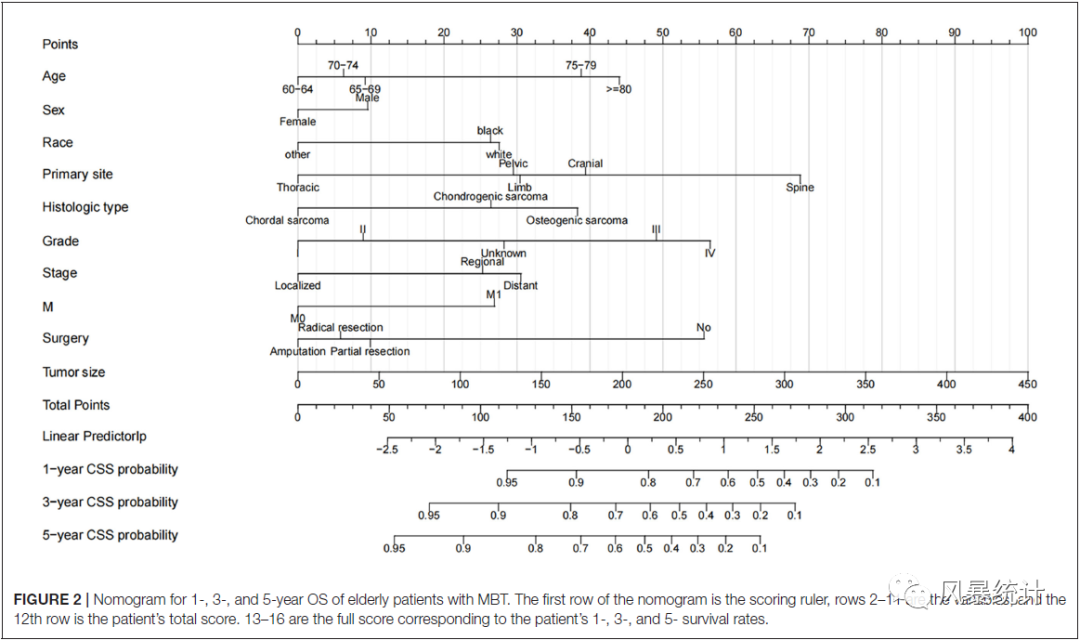
最终纳入10个变量建立了列线图。通过患者的个体特征对照列线图相加可以获得总分,表明每个患者的MBT的特异性生存概率。
②模型校准度验证——校准图
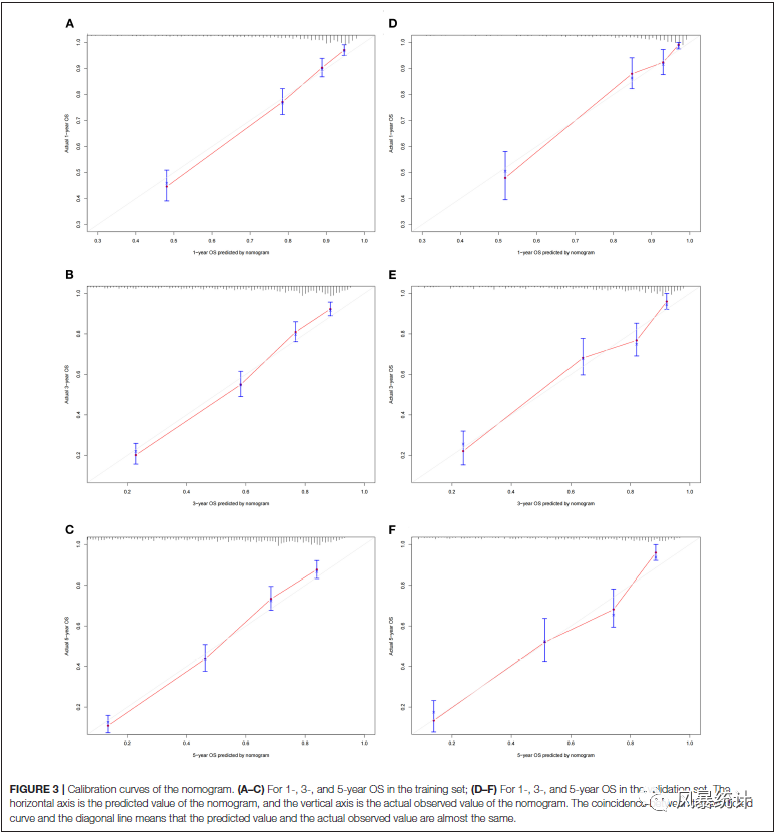
A-C是训练集1年、3年、5年患者的总生存期校准图,D-F是验证集1年、3年、5年患者的总生存期校准图。曲线与对角线重合度越高,说明模型的校准度越好。
③模型区分度验证——ROC曲线(AUC面积)
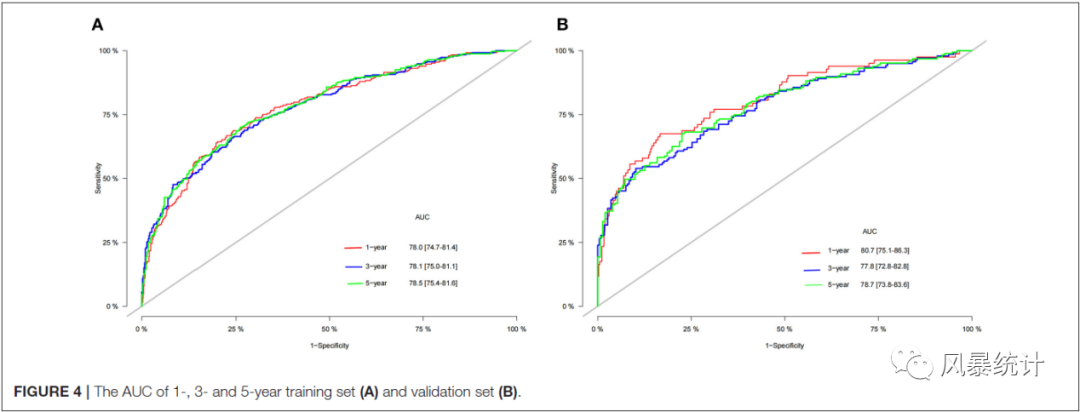
A图是训练集1年、3年、5年患者的总生存期的ROC曲线;B图是验证集1年、3年、5年患者的总生存期的ROC曲线。ROC曲线下面积又叫AUC面积,这个值越大说明预测模型的而判别区分能力越好。
④模型临床决策实际需求评估——DCA曲线
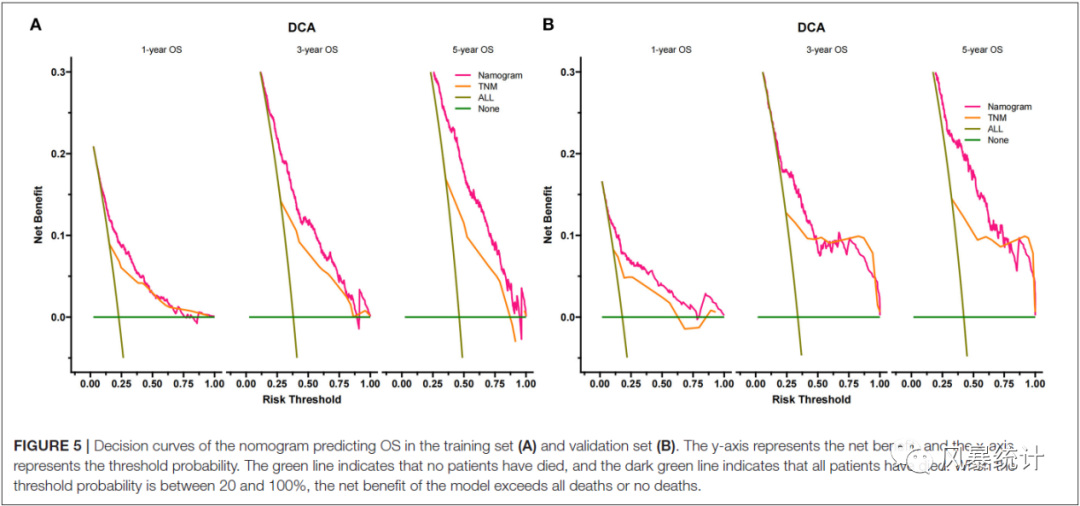
A图是训练集1年、3年、5年患者的总生存期的DCA曲线;B图是训练集1年、3年、5年患者的总生存期的DCA曲线,红色线条代表列线图模型(包括构建模型的10个变量),黄色线条代表TNM模型(仅纳入TNM分期3个变量),两个模型对比,线条越靠上说明在实际临床中的应用价值越大,可参考性越强。
二、利用在线网站“风暴统计”复现
如果没有代码基础,或者希望通过更便捷的方式进行统计分析,推荐使用这个智能在线统计分析平台——风暴统计。可以一站式完成Cox预测模型基础统计分析,便捷又快速。
它的网址是www.medsta.cn/software(在电脑端浏览器打开)
浏览器输入medsta.cn即可(medical statistics缩写)

1.进入网站分析模块
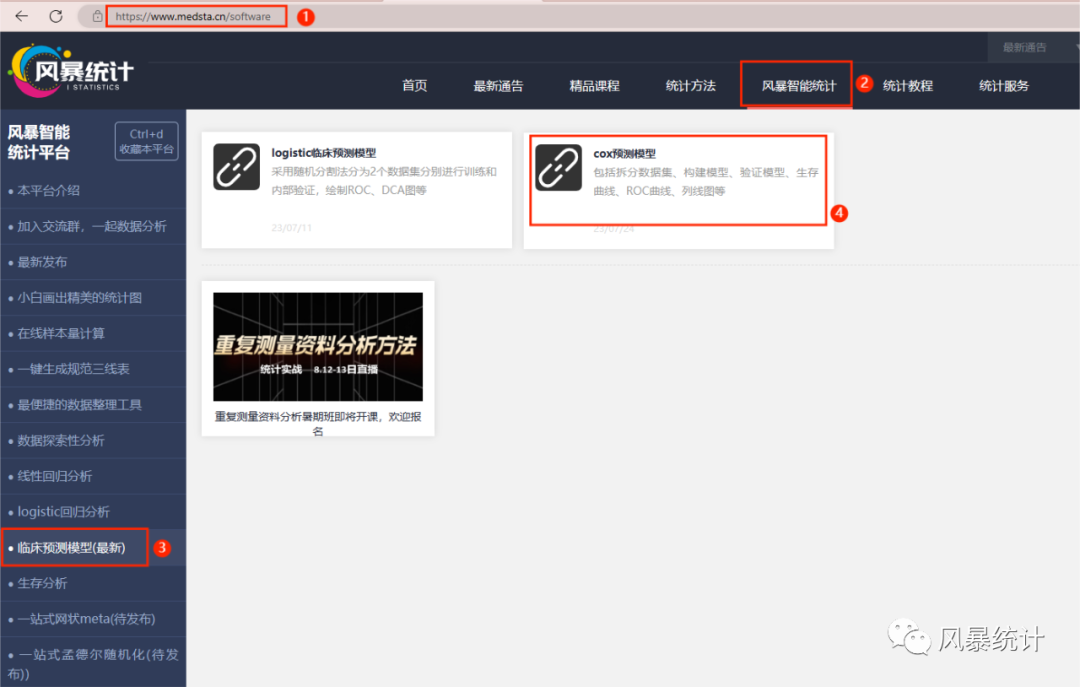
电脑端打开风暴统计平台——“风暴智能统计”模块,点击“临床预测模型(最新)”,进入“cox预测模型”页面。
2.导入数据集
导入的数据是我们利用SEERStat根据纳入排除标准,提取文献涉及的相关数据。最终共纳入1,574名患者(原文献1,641)。介于SEERStat数据库会有更新,因此提取的样本量与原文会有所出入,这里请大家多关注统计方法的运用!
包含的暴露因素有年龄、种族、性别、诊断年份、组织学类型、分级、分期、原发位置、TNM分期、肿瘤大小、是否化疗、是否放疗及手术方式。
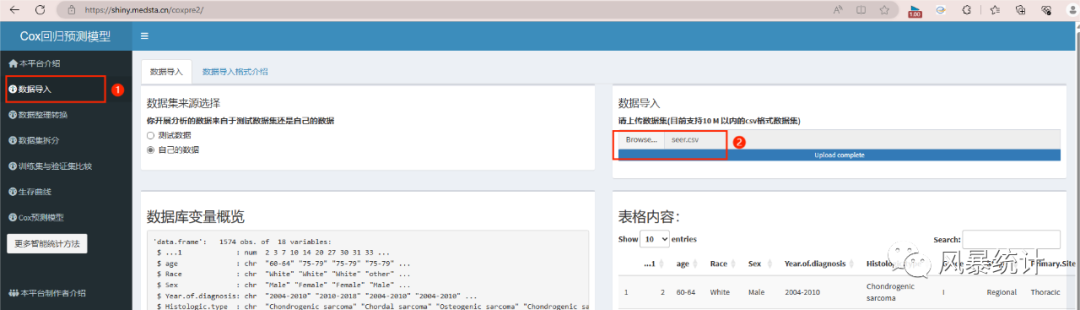
3. 数据的整理转换
(1)定量变量转分类数据
首先点击“数据整理转换”模块,选择定量变量(以年龄为例),选择“自定义分组”,输入分组临界值,点击开始分组,即可产生一个新变量“age_group”.(如遇显示不全,可下载新数据查看)
注意:网站分组按照输入的分组临界值,分组区间为左闭右合,所以将年龄分为"<=65", "66-71", ">71"的临界值为66和72,即[0,66),[66,72),[72,∞)。
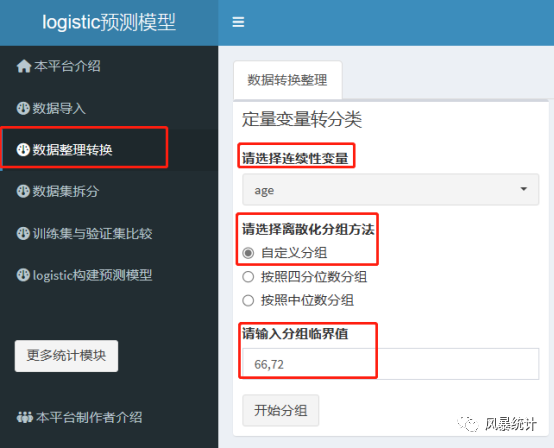
(2)分类变量值标签设置
以上一步分组的年龄为例,选择变量“age_group”,对应分组类别添加值标签,可以在原变量基础上修改,也可生成新的变量,切记一定要点“保存”!
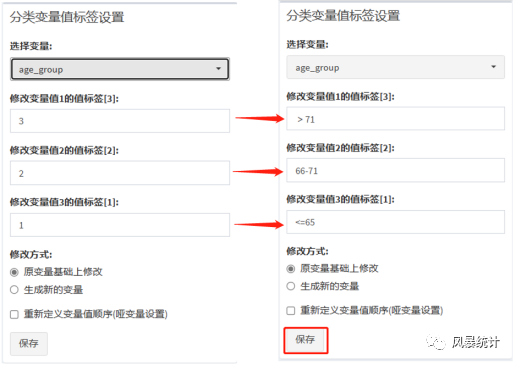
(3)重新定义变量值顺序(哑变量设置)
只需要勾选“重新定义变量值顺序(哑变量设置)”,将变量值按自己的需要排序,同样排在第一位的为对照,切记“保存”。
注意:第二步和第三步最好分开进行,否则会混乱。
(4)产生新变量
可以通过计算产生新变量,但本文不需要此功能,可做了解。
(5)变量重命名
(6)整理好的数据集可以直接下载
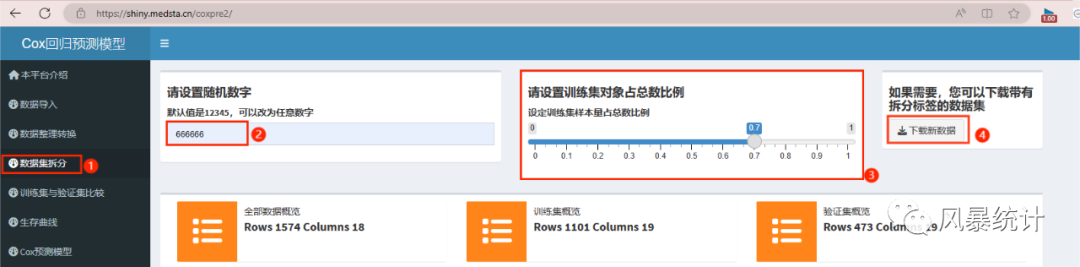
3.数据集的拆分
点击“数据集拆分”,可以设置随机种子与拆分比例,简简单单就完成了拆分工作,如果需要下载拆分好的数据集,也可以点击最右侧“下载新的数据集”。
4.选择变量,绘制均衡表
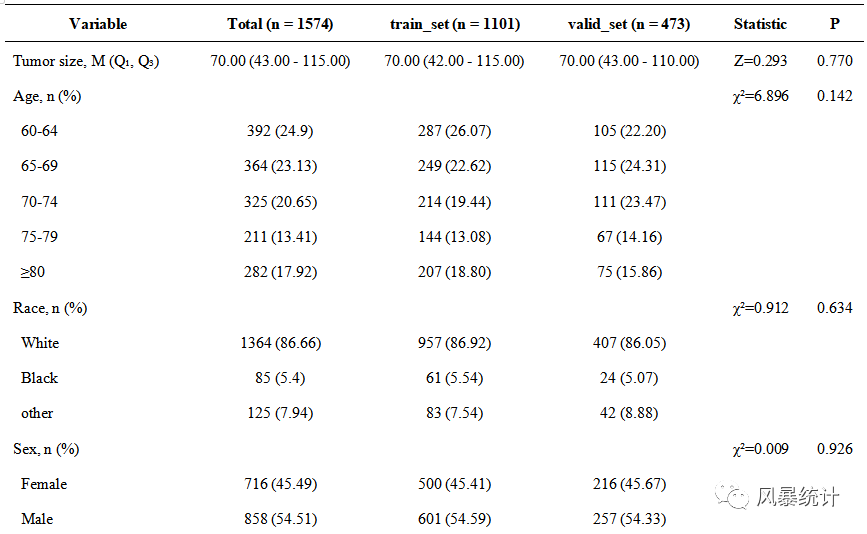
点击“训练集与验证集比较”,分别选入正态变量、偏态变量、分类变量,在右侧直接生成三线表格。制作好的三线表同样可以直接下载使用,有excel版和word版可以选择。
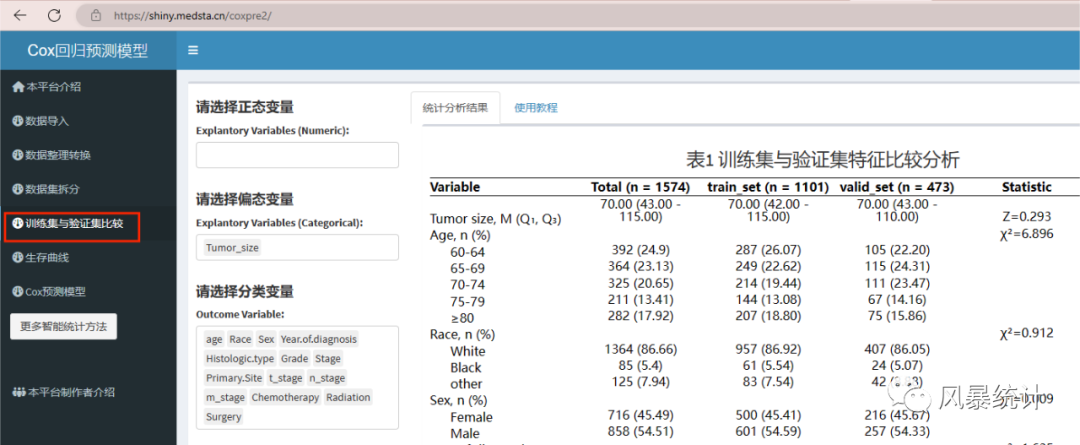
一般会选择下载word版报告,结果十分的清晰,直接是三线表格式,超便捷!


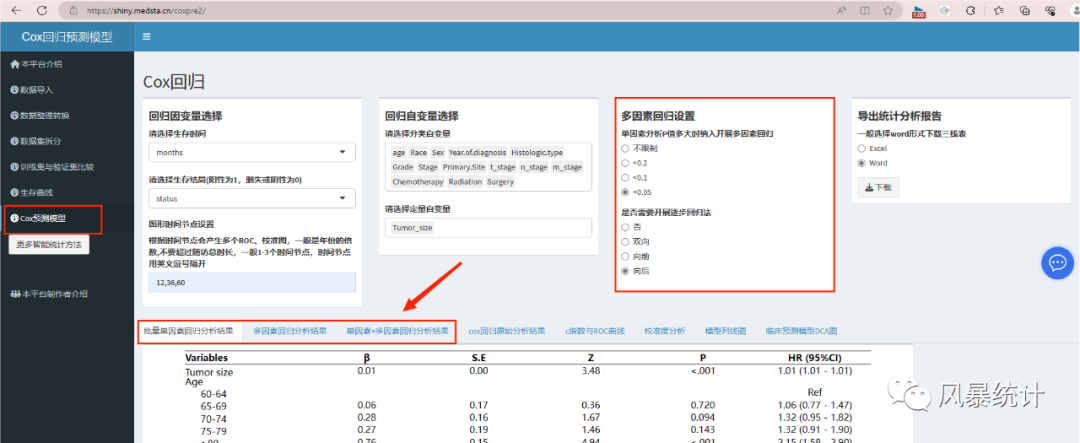
5.筛选预测变量
点击进入“Cox预测模型”模块,将回归因变量与回归自变量分别选入,此外时间节点的设置与研究数据相对应。
这里要特别注意回归方法的选择,如果仅使用先单后多进行筛选,则逐步回归法选择否,如果选择开展逐步回归法,可以通过多因素回归P值进行阈值的设定,下方的多因素回归结果即逐步回归结果,可以分别查看单因素、多因素(逐步)或先单后多的结果,同样支持导出excel或word三线表结果。
6.列线图
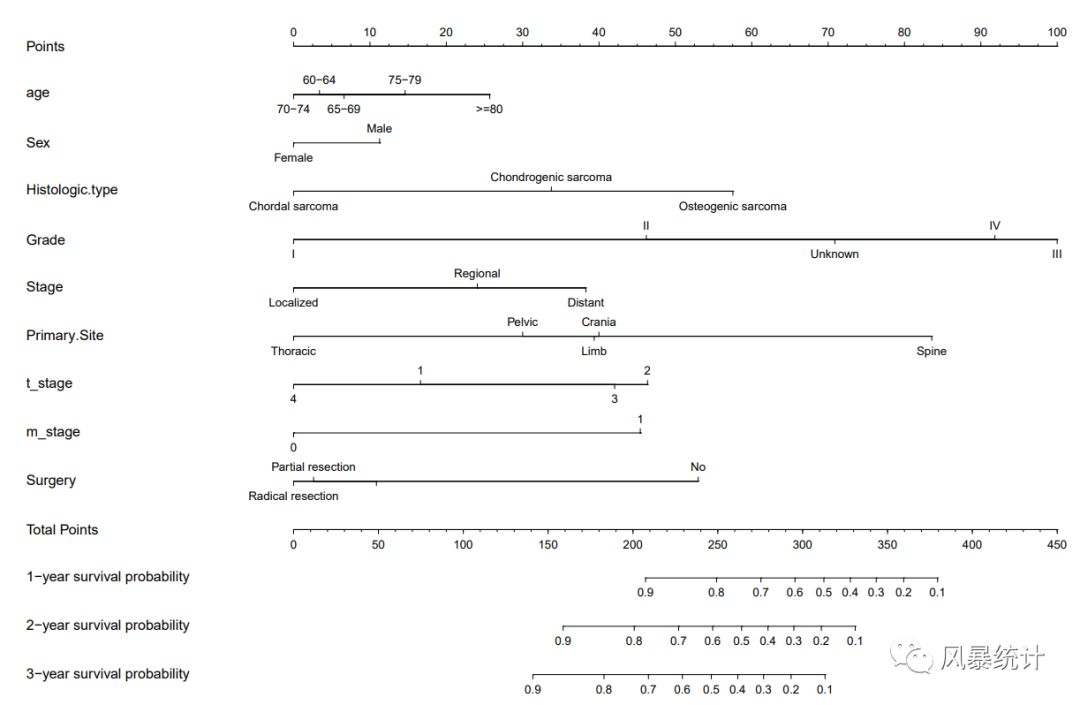
在“Cox预测模型”板块,预测因子设置完成后,可以在下方直接查看列线图。如果需要通过右侧对图形进行美化调整,须在左侧勾选“自定义设置”,下图为默认设置下的列线图,已经比较简洁美观了。另外,网站支持下载PDF版或PNG版图片,高清便捷。
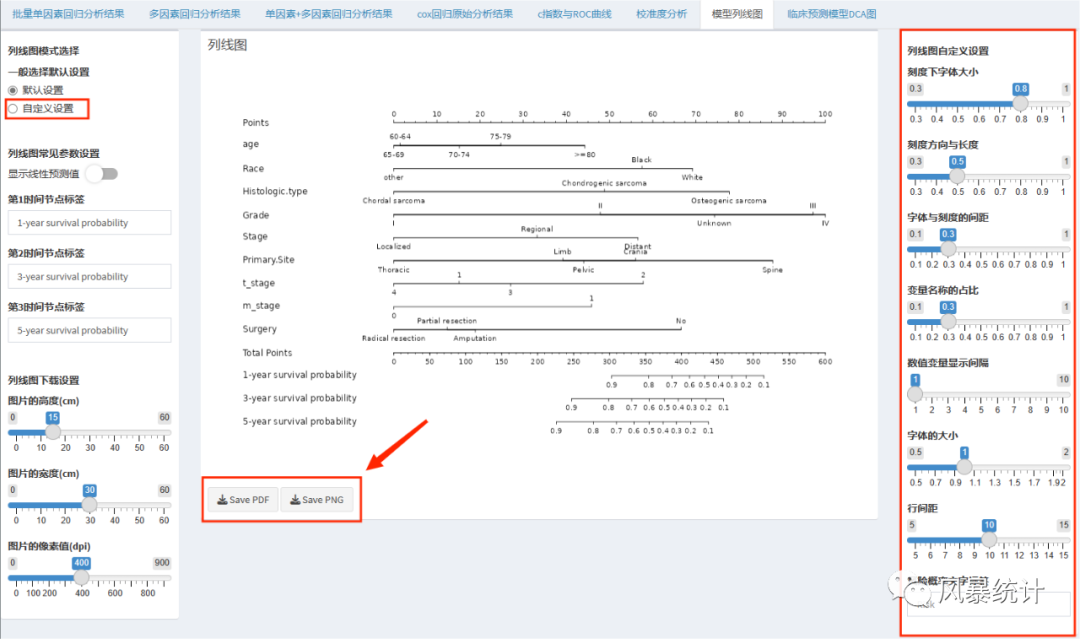
网站显示的数轴标注有所挤压,也不够清晰,但是下载的电子版图片就没有这个问题了,十分的高清美观!
7.校准曲线
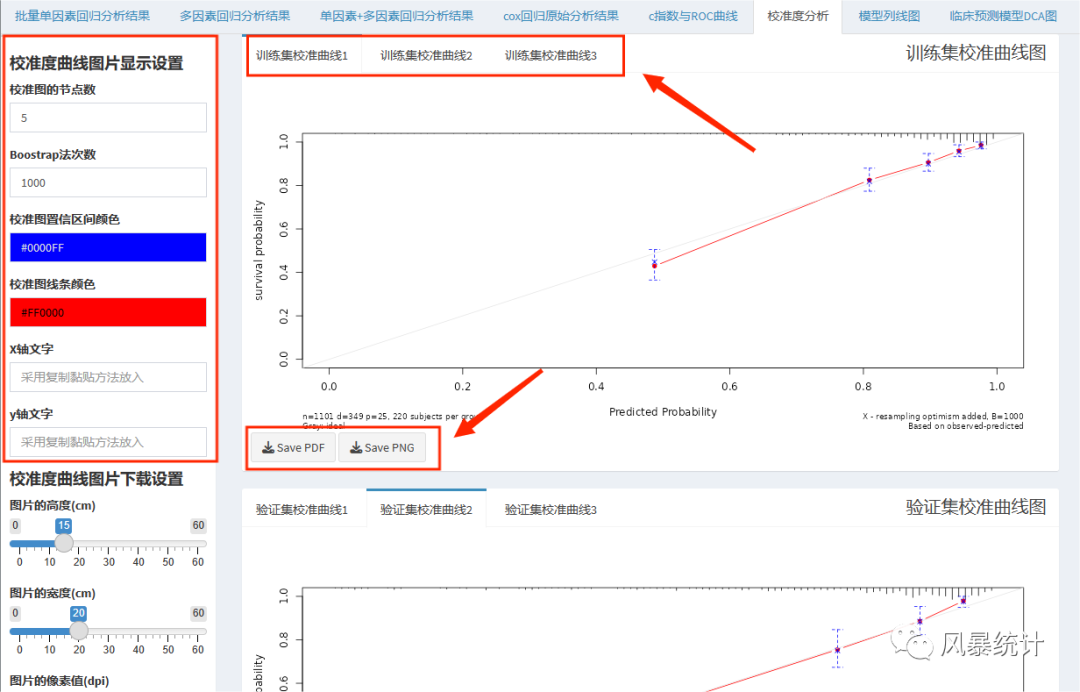
同样在“Cox预测模型”板块,预测因子设置完成后,此外,更加方便的是直接给出训练集与验证集,不同时间点的6个图形,省去R语言诸多代码的烦恼。另外,通过左侧可以设置重采样次数,通常为500或1000,以及校准图的节点数。最后可以下载校准图的PDF版或PNG版。
8.ROC曲线
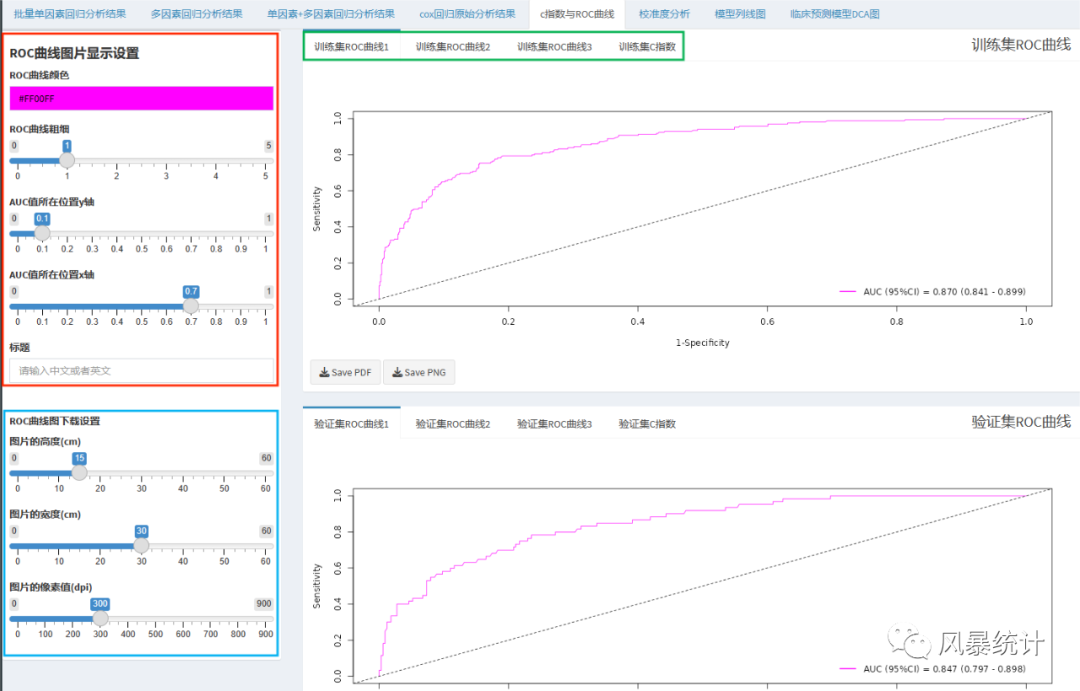
同一模块,ROC曲线直接给出结果,包括训练集与验证集3个不同时间点的6张校准曲线图,在左侧可以直接调整图形的线条粗细,AUC95%可信区间注释的位置。小白式操作也可以绘制出精美的图形。
9.DCA曲线
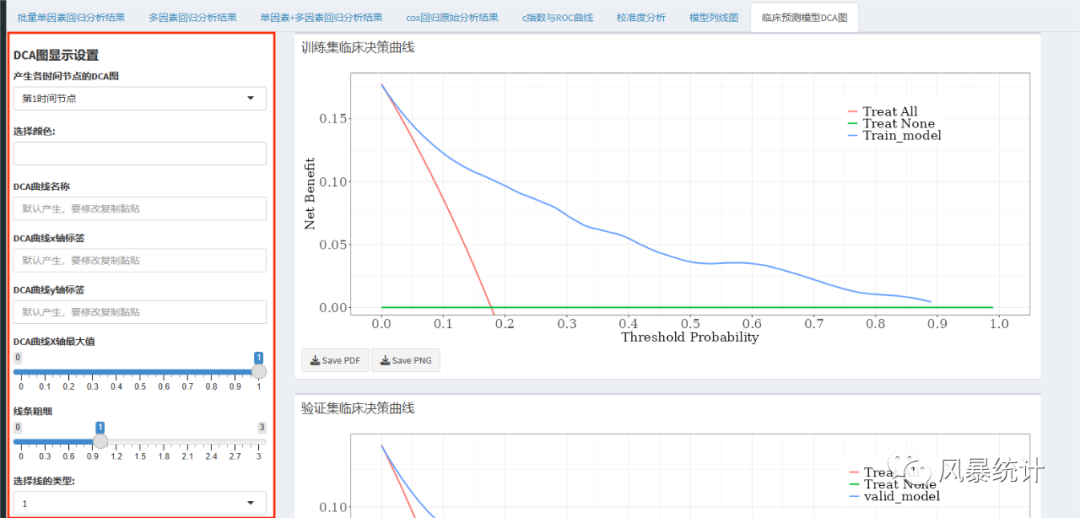
同样给出训练集与验证集在3个不同时间点的DCA曲线,在左侧可以调整线条的粗细、虚实以及X轴的最大刻度值,可以下载图片的PDF或PNG,对新手小白十分友好!
到这里,就已经完成Cox预测模型文章中基础统计策略的全部流程啦!内容丰富但操作十分简单,您也不妨尝试一下!!!
本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10门课。如果您有需求,不妨点击查看: 发表文章后退款!2023年郑老师团队多门科研统计直播课程,欢迎报名 二、统计服务 为团队发展,我们将与各位朋友合作共赢,本团队将开展统计分析服务,帮忙进行临床科研。欢迎了解详情: 医学统计服务| 医公共数据库论文一对一指导 |

















 2183
2183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









