







详情请点击下方:
欢迎报名!2024年GBD数据库挖掘培训班6.1-6.2,快速撰写SCI论文!
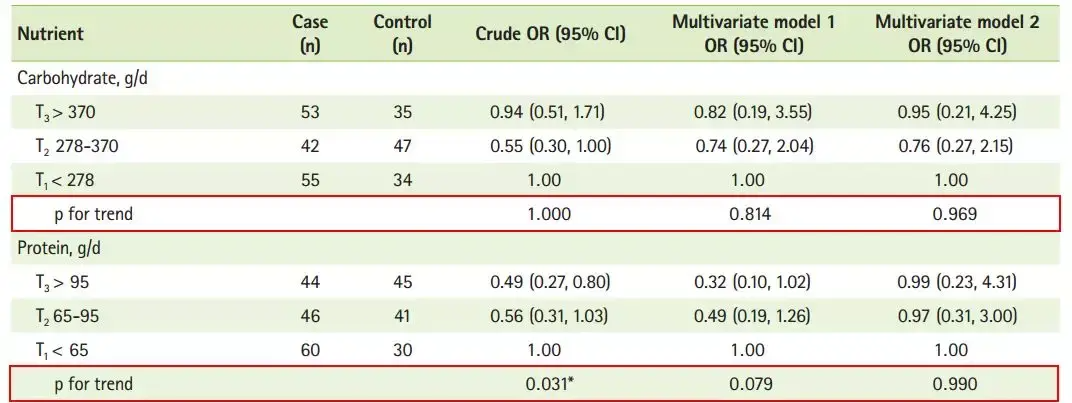
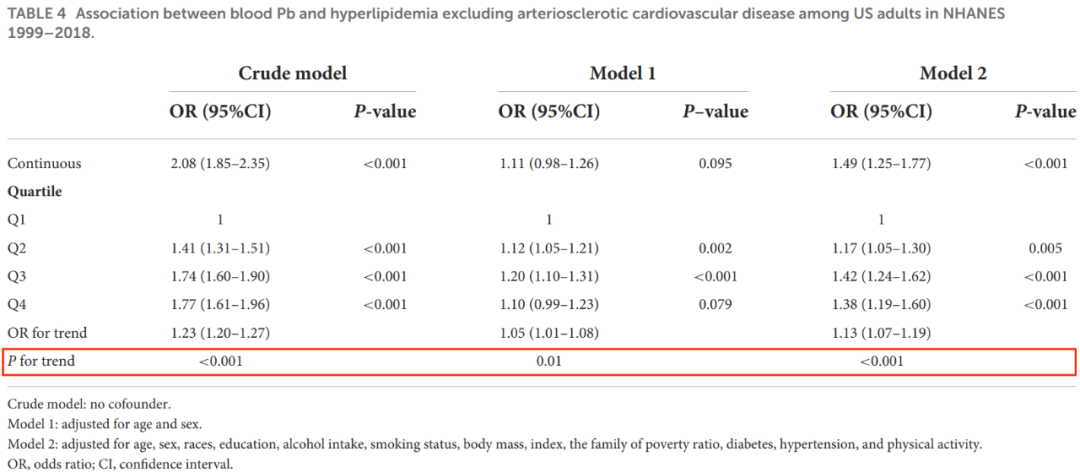
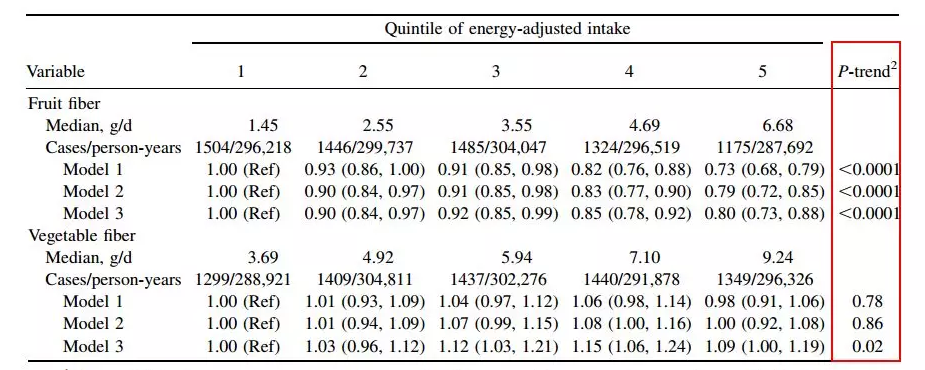
在SCI文章中,经常可以见到P trend,并且P trend的出现场景比较的单一,基本都是针对原数据是连续变量,接着通过分位数转换等级变量后开展回归并计算P trend。
文中的分组方式涉及3等分、4等分、5等分......,各式各样都有。
|
|
|
|
|
|
但是现实中实操来说,进行定量数据分位数转换还是有点麻烦的,R语言与SPSS都需要先进行数据的描述统计,确定截断值,再进行数据的转换。
那么有没有简便快捷方式对定量数据进行分组呢?还真有!——风暴统计,一键完成数据的分位数转换,直接生成分组变量与组中位数,超快速计算出P trend!
下面我们就结合一份实操数据来为大家详细介绍一下具体的操作步骤吧!
实操具体网址:https://shiny.medsta.cn/trend/
或者百度、必应Bing搜索“风暴统计”
本平台上线的所有工具都是免费的

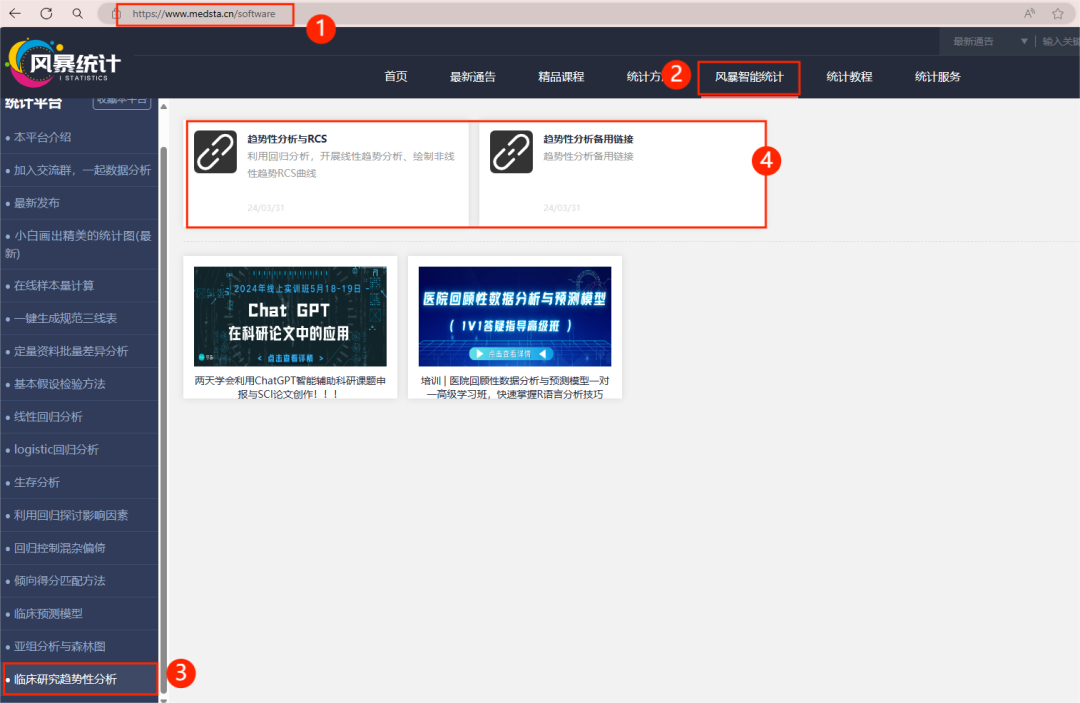
1.进入风暴统计平台
首先,浏览器搜索风暴统计,依次点击"风暴智能统计"——"临床研究趋势分析"——"趋势性分析与RCS"!进入分析界面后,根据提示,完成数据的导入与整理。
这里我们不再赘述数据的导入与整理过程,详细教程大家可以点击下方链接:
定量暴露的分位数转换,是在“趋势性分析变量转换”模块开展的!
2.定量数据分位数转换
风暴统计仅需3步!快速给出分位数分组与组中值!
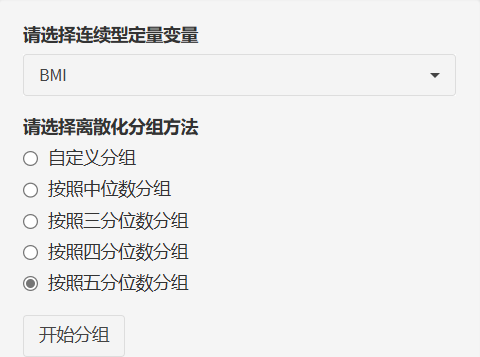
第一步,选入我们想要开展分析的连续型变量。
第二步,选择离散化分组方式,平台给出了多种分组方式。
-
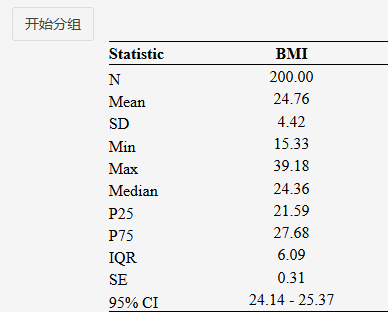
"自定义分组":可以自行决定分组截断值。平台会给出定量变量的统计描述结果,有最大值,最小值,中位数,标准差,标准误等......
-
”分位数分组“:中位数、三分位数、四分位数、五分位数,风暴统计平台统统搞定!以五分位数为例,平台还会会给出各组的样本量,组中值,最小值,最大值,直观展现数据情况。
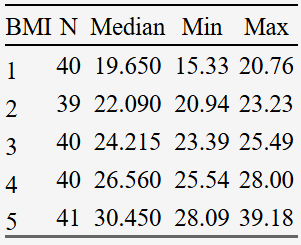
第三步,点击”开始分组“。接着右侧数据预览模块就会出现分位数分组结果以及各组的组中值了!
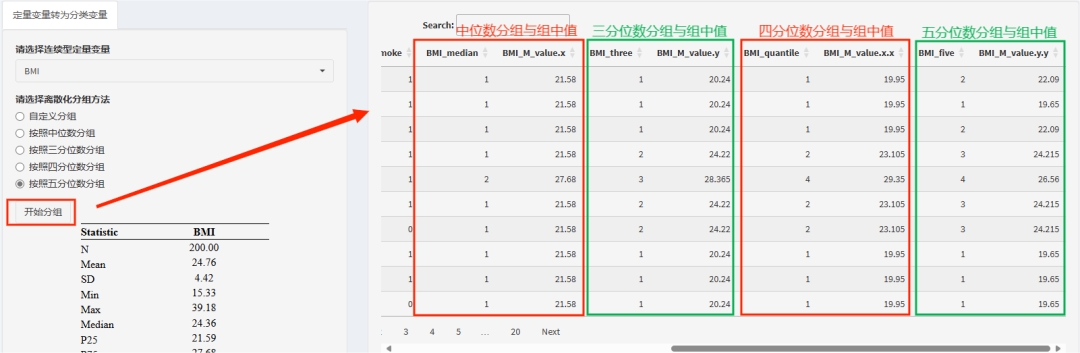
以"median"、"three"、"quantile"、"five"为后缀的变量名,分别代表中位数、三分位数、四分位数、五分位数转换后的等级数据,在数据探索阶段,可以都进行尝试,看看结果有什么不同。
其他统计软件分析一种结果的时间,风暴统计平台可以探索4-5种结果,效率超高!
以"M_value"为后缀的变量名,则是用每组的中位数重新赋值。这个变量就是计算P for trend的核心变量了!
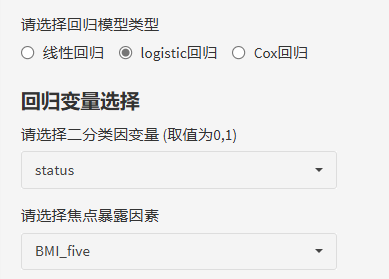
3.回归分析
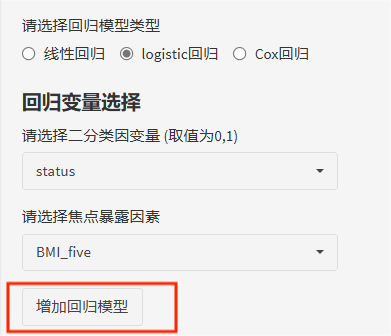
同样是3步出结果:选择模型——选择因变量——选择焦点暴露。
这里的暴露是以"median"、"three"、"quantile"、"five"为后缀的等级变量哦!
页面右侧部分就直接出现了回归分析结果!
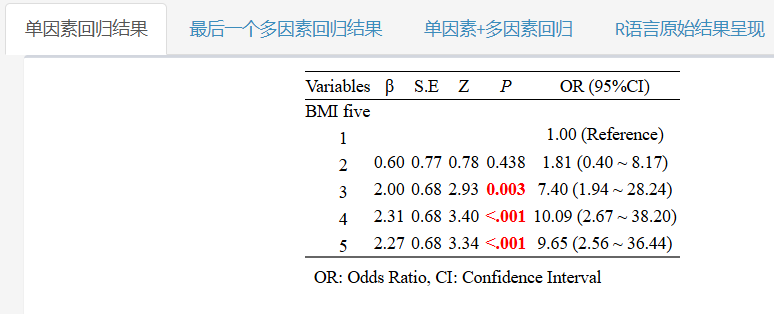
4.计算P trend
计算P trend也需要回归分析,不过需要多1步!
前3步相同操作:选择模型——选择因变量——选择焦点暴露。
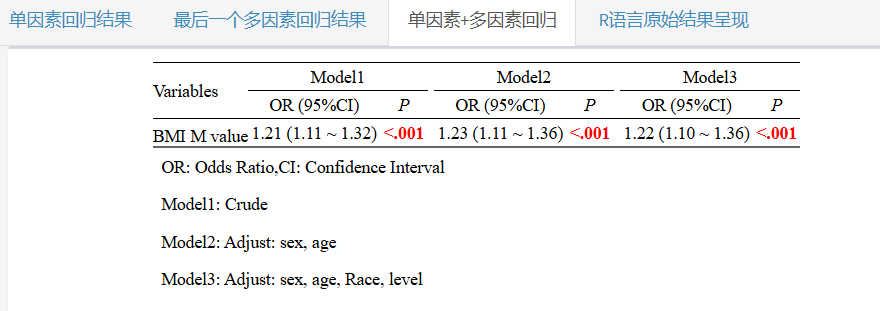
P trend的暴露是以"M_value"为后缀的连续变量哦!
最后一步!在"分类变量"选框中取消勾选,这样变量就会以连续变量的形式纳入分析了。
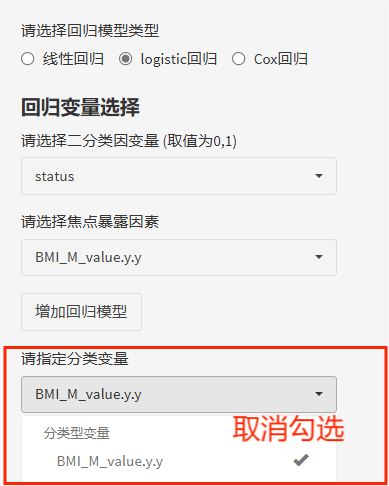
这时候,我们回归分析的P值就是我们的P trend啦!

最后,如果需要调整协变量,进行多因素回归,可以点击"增加回归模型",最多可以有5个回归模型。
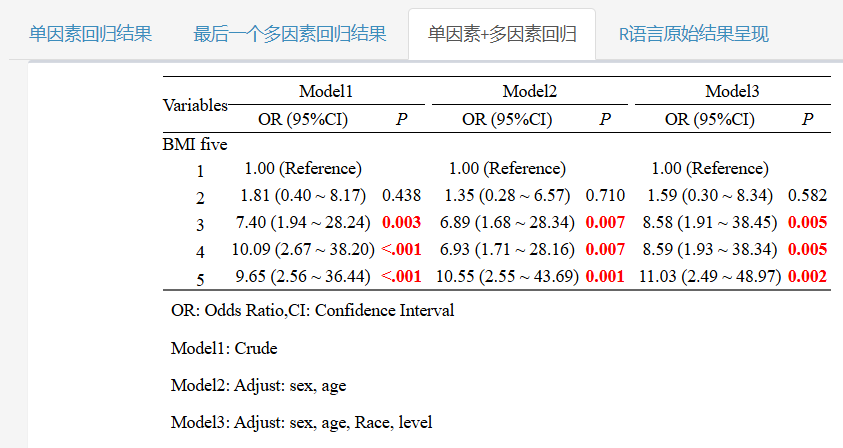
这里的多模型结果就和推文开头的示例很像啦!回归分析结果与P trend结果都有!
如果您在风暴统计平台的使用过程中有任何的建议或疑问,欢迎加入我们的讨论群!群里郑老师与助教会在群内解答!

统计机器人交流群


















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









