







摘要
-
在MLTC任务中在这篇文章以前大多使用的方法是关注到文本的表示,相关的特征提取任务的优化,或者是针对于标签上的注意机制;要么就是注意到相关标签的关联性;但是这些内容都没有注意到实例的相似性,通过相似实例之间的有可能相似的实例标签可以给本实例的标签提供辅助的标记作用;
-
文中就使用了KNN模型来实现这种捕捉测试实例和他周围相近的邻居之间的相关性信息,最终将周围这些相近的邻居的label信息放到本test sample中,用来辅助当前sample的标签分类任务;
-
但是这种情况可能对于标签预测的时候,模型并没有意识到KNN这种机制的存在,就有可能导致引入一些噪声,从而影响模型的性能,这里使用的方法是,引入对比学习的方法将标签重合的部分称为是正例,不重合的label称为negative;
-
这里的模型同时还考虑了对于多标签问题可能是部分重合的情况,即部分的标签是重合的,还有一部分是不同的;模型中使用了对比学习系数 β \beta β 使得模型在学习的时候可以捕捉到更加细粒度的标签关联性信息;即表示这些实例之间的标签重合性信息;

-
文中提到Linyang Li, Demin Song, Ruotian Ma, Xipeng Qiu, and Xuanjing Huang. 2021. KNN-BERT: fine-tuning pre-trained models with KNN classifier. CoRR, abs/2110.02523. 这篇文章中也使用了KNN+CL的方式来构建分类器,但是这种方法并没有用到多标签分类任务中,因为他忽略了在每一个实例中的不同的/不重合的labels信息,即没有像本文中那样使用到更加细粒度的标签相关性信息,文中解决这种问题的方法如4中所示;
引言部分
-
文中提到文中提到的这种KNN+CL的方法的衍生的历史;首先,之前在MLTC上的工作都是关注于得到一个较好的text表示或者是使用针对于label上的一些注意力机制,或者是通过标签相关性来提升MLTC的性能;但是,上面提到的这些目标都并没有关注到实例相关性,文中使用一个生动的实例:
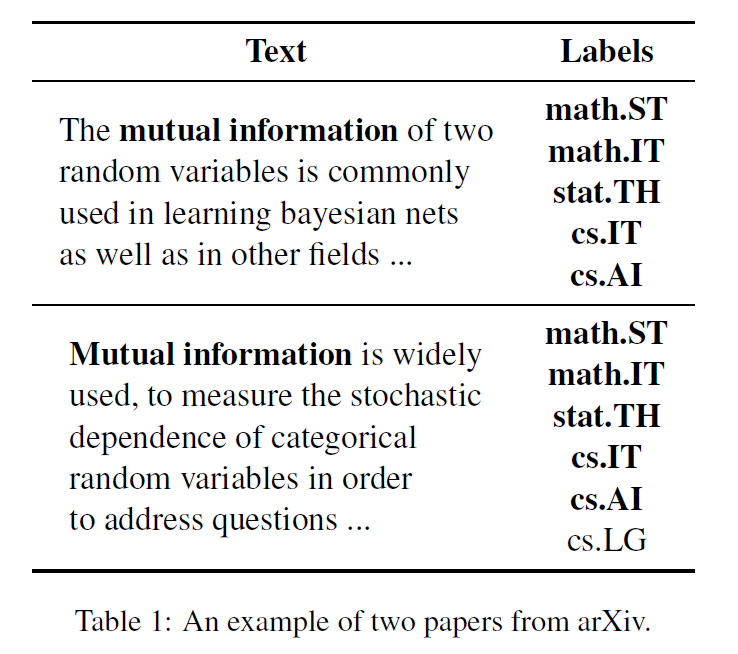
其中我们可以观察到这个这两个文本是从arxiv上中的两篇文献中提取出来的文本,这两个文本中的labels部分的第一段文本中所有的label在第二段文本中都有体现,可见如果我们在对于第二段文本执行多标签分类任务的时候,可以及时的关注到第一段文本和第二段文本之间的相关性,并使用第一段文本中的标签信息引入到对于第二段文本的分类任务中,这样可以进一步的提升对于第二段文本的分类精度;
即从实例相似度相近的实例中获取得到这个实例的标签,放入到当前的实例分类的模型中,来辅助当前的实例多标签分类任务,从而使得分类的精度更高
-
文中的模型用来捕捉相近的实例的办法是使用KNN框架来捕捉跟当前实例相似的sample,并将这个sample的labels信息引入到对于当前sample处理的模型中,从而提升对于当前sample处理的精度;
但是这种做法也是有缺陷的,就是这种做法可能在使用KNN来提取相近的samples,并且将这些samples的label信息输入到当前的sample的分类模型中时,有可能捕捉到噪声信息,或者是跟中心的sample相关性并不高的信息;
对于这种问题的解决办法是使用对比学习的思想,来提升KNN捕捉临近相似的文本;
最初使用CL这种思想是用在多类分类设定上的,这跟目前的多标签设定是不同的,因为多类问题是这个实例一共就一个标签,即一个positive;即两个实例的相关程度要么是完全相似要么就是完全不相似,这完全是取决于打上positive的label是哪个class;但是多标签问题是不同的,一个实例具有的标签数是不固定的,这就出现了完全相似、部分相似、完全不相似;
-
模型中为了解决上面这种将CL引入到multi-label上的标签完全相似、部分相似和完全不相似的这些不同程度上的标签重合问题,使用的方法是引入了一个动态系数 β \beta β , 对于每一个实例对基于标签的相似度,来定义这个动态系数,从而实现了更加细粒度的标签重合问题的区分;
-
通过上面的设定目标函数,通过这种目标函数可以使得模型对于两个在标签上有更多相同labels的实例在文本表示上更加接近;反之,如果两个文本的标签是完全不同的,将会将这两个文本的表示推离;
-
最终 KNN模型将会捕捉得到更加相似的实例信息,即这个实例跟中心实例之间包含有更多相关的标签数
-
文章贡献点:
- 首先,模型使用了KNN机制来捕捉更加跟中心实例相似的实例,通过这个实例包含的label信息来辅助本实例的多标签分类;
- 齐次,这个模型通过使用了对比学习来使得KNN机制更加高效,忽略噪声信息;
- 最终对于CL在multi-label上设定进行了补充,使用了动态对比学习系数来获得更加细粒度的相关性信息;
Related Work
- 文中在相关工作中,提到了在本文之前的多标签文本分类关注的都是如何去学到一个更好地文本表示,或者是利用标签相关性。
- 对于做出一个好文本表示,文中提到有使用CNN和RNN来捕捉相关的特征信息、还有额外使用针对于标签的注意力机制来捕捉相关token的表示信息,最终得到token的表示信息;
- 还有使用图神经网络来捕捉标签相关性信息;
- 但是这些方式都没有利用到现存的大量实例相关性信息,文中就是在这方面做文章;
- 文中使用了KNN机制来捕捉跟正预测text相近的实例,通过依靠相近的实例信息最终辅助当前的text进行多标签文本分类;但是如果单纯的使用KNN机制来捕捉跟当前实例相近的一些实例信息,这种方式将会捕捉到噪声信息,或者说引入噪声信息,为了解决这种缺点,模型中使用了CL来提升KNN的性能;这种方法之前在Linyang Li, Demin Song, Ruotian Ma, Xipeng Qiu, and Xuanjing Huang. 2021. KNN-BERT: fine-tuning pre-trained models with KNN classifier. CoRR, abs/2110.02523. 这篇文章中也使用过,但是这篇文中并没有考虑CL在多标签分类中的设定,即部分重合的labels信息,所以,模型中做出的改进就是添加了动态参数 β \beta β ;
Proposed Method
-
文中首先对于如何构建供KNN机制使用的数据仓库以及如何在这个MLTC任务中使用KNN机制进行叙述;
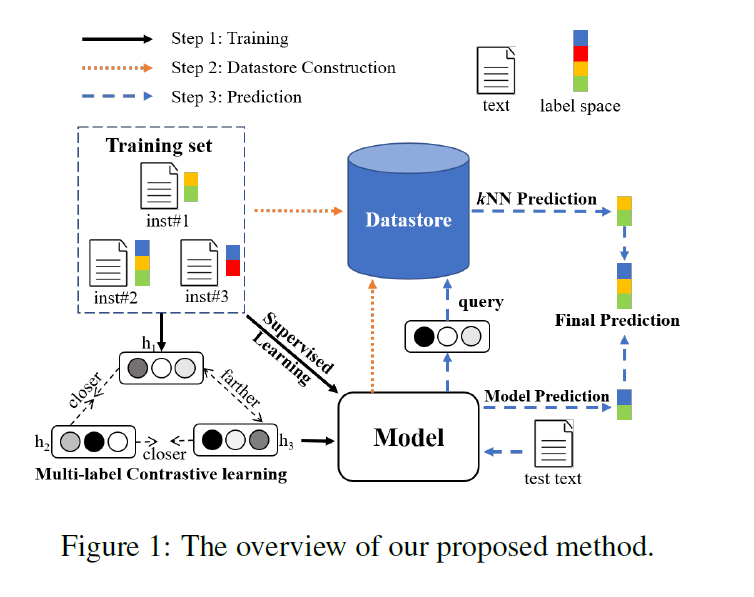
如上图中所示;
-
第一步是构建Datastore;首先图中的橘黄色的线表示的是这个步骤 ,这个步骤就是将原始train set中的 ( x i , y i ) ∈ D (x_i,y_i)∈D (xi,y
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









