









摘要
- Transformer已成功地应用于遥感变化检测(RSCD),并取得比CNN更好的结果,但是依然存在两个主要问题:
- transformer计算复杂度随着图像空间分辨率的增加呈二次增长,不利于超高分辨率遥感图像。
- 现存的transformer网络往往忽略了细粒度特征的重要性,导致变化较大的对象边缘完整性和紧致性较差。且微小变化对象易被忽略。
- 为此,本文提出Lightweight Structure-aware Transformer (LSAT)网络,具有两个优点:
- 设计了一个具有线性复杂度的Cross-dimension Interactive Self-attention (CISA)模块代替普通自注意力,有效降低计算复杂度,同时提高LSAT的特征表示能力。
- 设计了一个Structure-aware Enhancement Module (SAEM),以增强差异特征和边缘细节信息,通过差分细化和细节聚合实现双重增强,从而获得双时态图像的细粒度特征。
- 和大多数先进的CD方法相比,LSAT显著的提高了检测精度,并在精度和计算成本之间提供了更好的权衡。
- 论文链接:https://arxiv.org/abs/2306.01988
方法
总体架构如图1所示
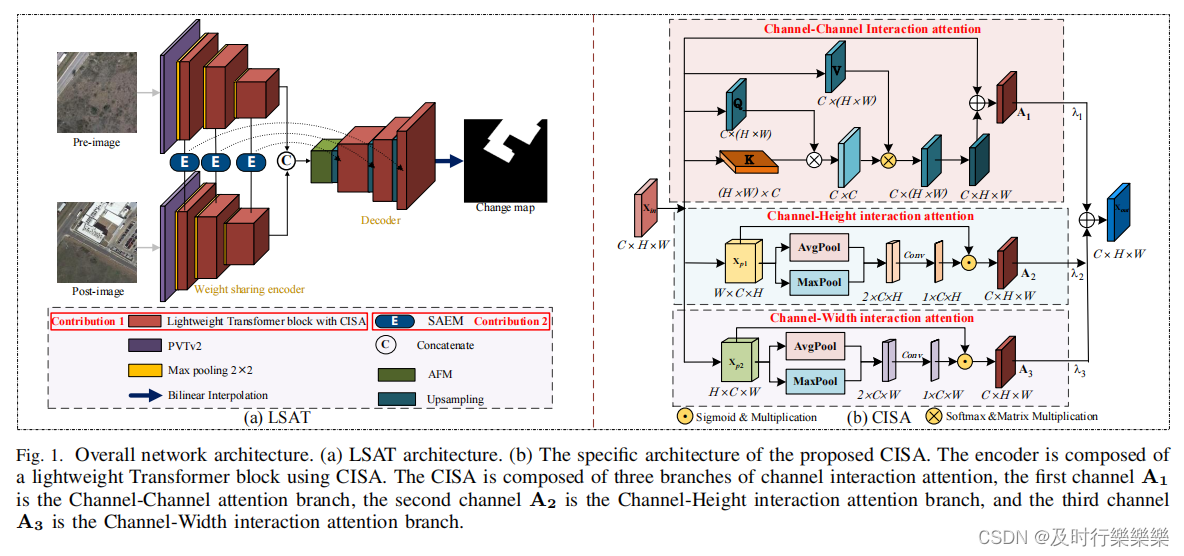
- LSAT包含:
- Cross-dimension Interactive Self-attention (CISA)
- 作为编码器提取双时态图像的层次语义特征。
- query、key和value由深度可分离卷积投影生成,而非线性投影,加强上下文连接,减少普通自注意力机制引起的语义歧义。
- 之后执行通道间编码生成通道-通道注意力映射
。为了捕获跨通道长依赖关系,在特征图上进行了通道-高度
和通-宽度
的双分支交互注意力,以增强通道和空间维度之间的跨维度交互作用。提高模型的全局信息提取能力。计算如下:
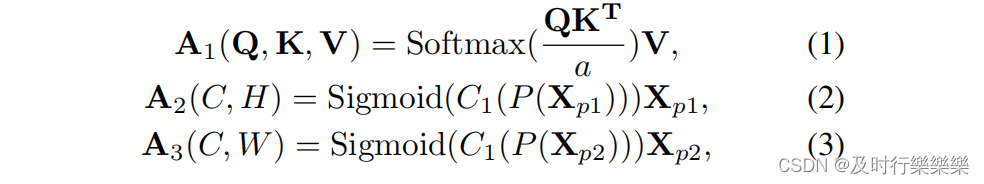
- 其中,
和
是分别对输入特征
进行维度变换后的张量,
表示
卷积运算,P表示最大池化和平均池化的并行云端,最后注意力计算为:
,其中
是超参数。
- 该模块的计算复杂度为
。
- Structure-aware Enhancement Module (SAEM)
- 如图2所示,增强细粒度的差异特征。
- 单分支增强的特征表达能力有限,且计算成本高。SAEM和单分支差异增强不同,使用双分支(差异细化、细节聚合)学习细粒度特征。
- 差异细化分支:利用卷积操作进一步增强了双时态特征,然后使用轻量级三维注意力SimAM来生成更细粒度的特征,并改进了检测结果的轮廓;
- 细节聚合分支:细分为两条路径,一是通过合并卷积特征来增强细节信息。二是连接卷积特征,然后利用注意力来提取更丰富的详细信息。
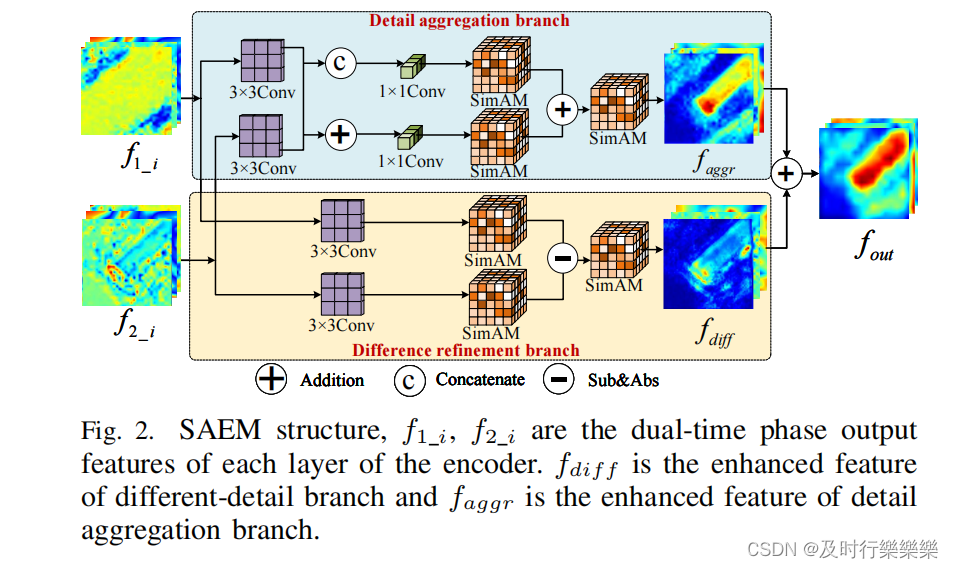
- SAEM可以减少噪声和错位引起的错误变化,从而获得更有用的细粒度变化特征,提高模型的鲁棒性。
- 基于注意力的融合模块(AFM)
- 用于生成细粒度的变化图
- Cross-dimension Interactive Self-attention (CISA)
实验
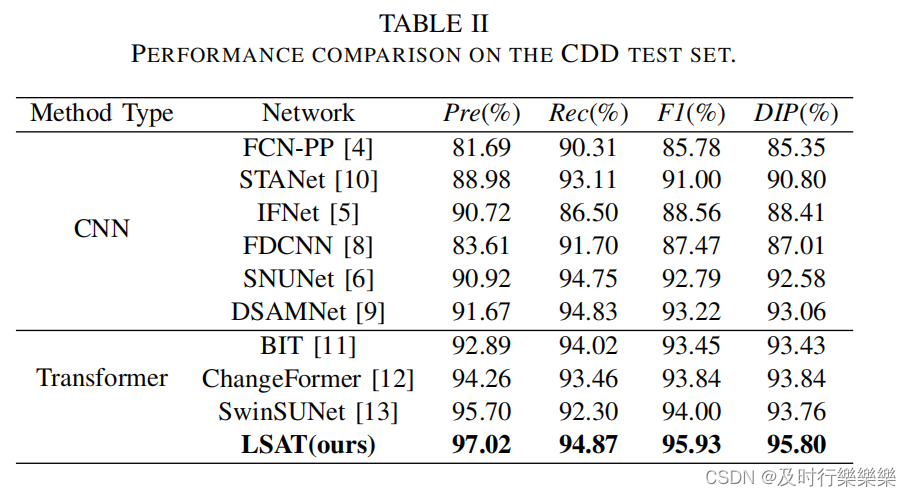
Comparison with State-of-the-art


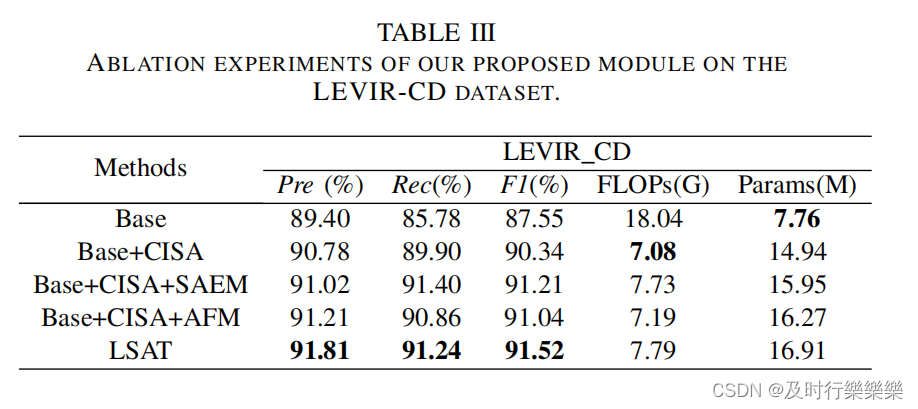
Ablation Study
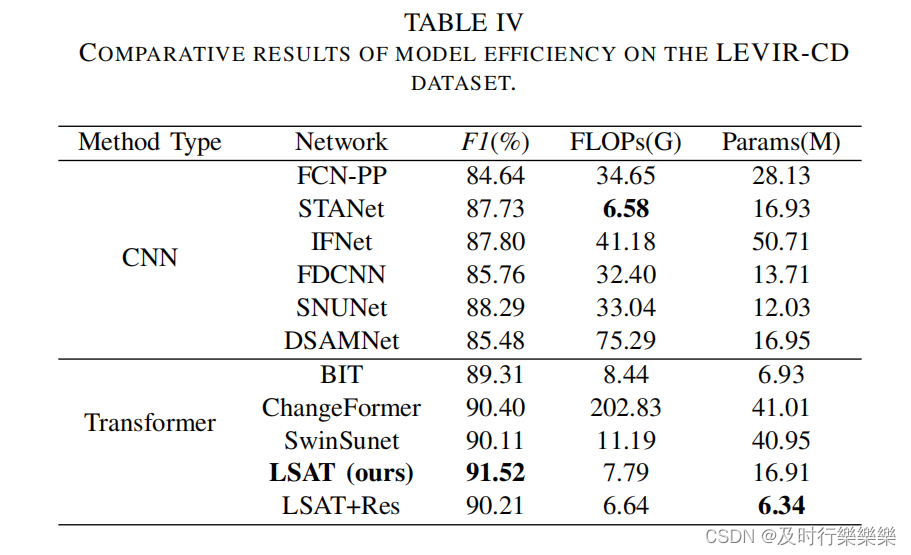
Model Efficiency
















 3453
3453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









