









摘要
- 基于注意力的transformer已成为捕获变化的主流方法,但是,transformer编码器中自注意力操作会导致网络具有较高的参数和计算复杂度等问题。
- 为此,提出Sparse Focus Transformer (SFT),主要有三个组件组成:
- CNN用于高级特征提取;
- 基于sparse focus attention mechanism的transformer编码器用于定位和捕获双时态图像的变化区域,同时降低了参数量和计算复杂度。
- 字幕解码器结合图像和单词生成描述差异的句子。
- 在各种数据集上的实验结果表明,即使transformer编码器的参数和计算复杂度降低了90%以上,提出的网络仍然可以与其他最先进的RSICC方法相比获得具有竞争力的性能。
- 论文链接:https://arxiv.org/abs/2405.06598
- 代码链接(空项目):https://github.com/sundongwei/Lite_Chag2cap
动机
基于注意力机制的方法显著提高了变化描述的准确性。尽管如此,由于注意力机制的高复杂性和参数量,特别是在transformer架构中,在计算资源有限的工业环境中的部署和实际应用仍然具有挑战性。因此,需要设计一个包含注意力机制的轻量级算法,以确保高精度和易部署性。
方法
Lite_Chag2cap总体结构如下图所示。

-
Sparse Focus Network
-
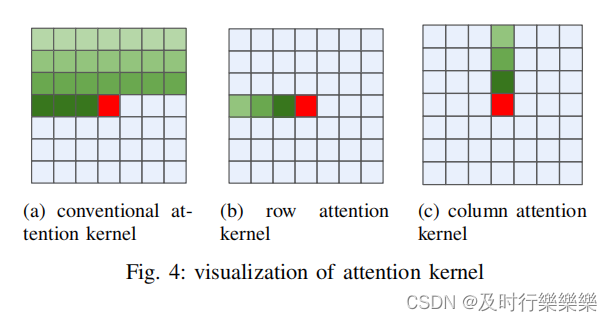
attention kernels的稀疏分解方法可视化。图4(a)说明了传统卷积attention kernels的计算,其中对当前像素的预测(用深红色表示)涉及到对一定范围内像素(浅色区域)的利用。图4(b)展示了一个row-wise attention kernels,其中当前像素(用深红色表示)的预测只涉及同一行中的像素(浅色区域)。类似地,图4(c)遵循相同的基本原理,说明了一个column-wise attention kernels,其中对当前像素的预测只涉及同一列内的像素。
-
-
基于此,设计了Sparse Focus注意力。该模块将水平和垂直的 attention kernels集成到一个新的 attention kernels中。在arse Focus注意力中,设计了两种不同类型的 attention kernels,如图5和图6所示。根据如何计算影响像素预测的行长和列长区分,分别被称为“ full length”和“ fixed length”。前者计算整个W×H特征图中影响当前像素P的行和列长度,而后者计算整个特征图中固定的像素注意力长度。
-

-
在Sparse Focus编码器中,分别将不同时间步长对应的特征映射通过Sparse Focus Transformer(SFT)进行特征定位和提取。最后,将输出结果连接起来。
-
- Generation Decoder
- 解码器包括几个transformer解码器层,每个层由一个掩蔽的多头注意力子层和一个前馈网络组成。为了保持信息传播和确保模型的鲁棒性,这些子层采用了残差连接和层归一化操作。最终,输出嵌入通过一个线性层和一个最大Softmax激活函数得到。

实验
数据集:LEVIR-CC Dataset、Dubai-CC Dataset
Results Analysis
Accuracy Analysis

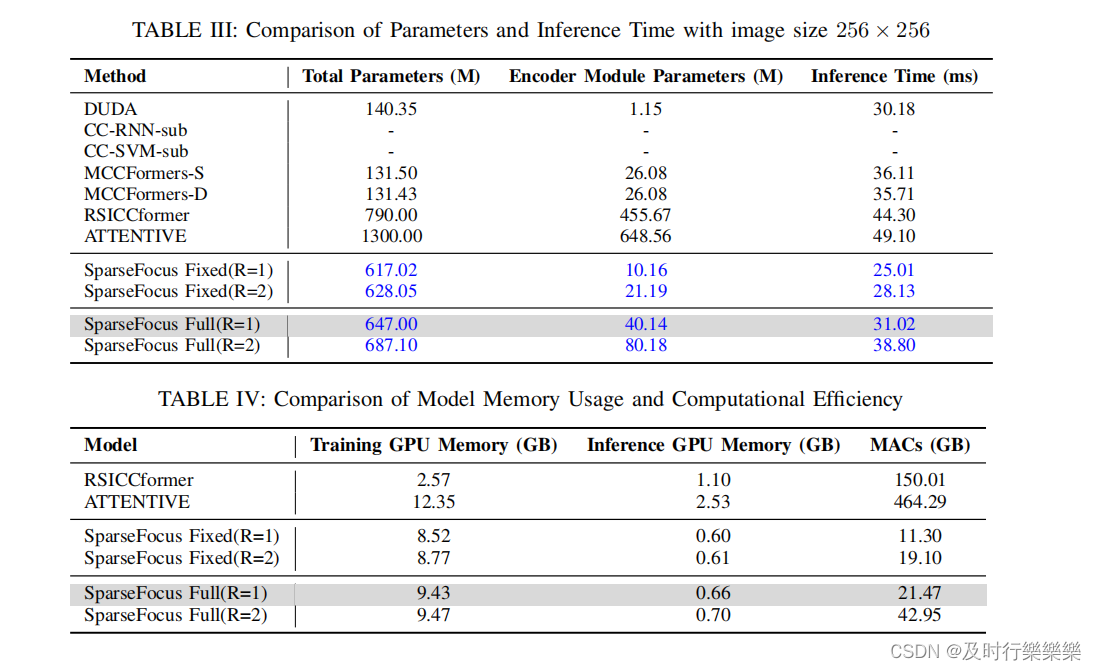
Parameter and complexity analysis
Ablation Studies
LEVIR CC and
DUBAI CC Ablation

Qualitative Visualization

















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









