







开始写一写论文的总结,慢慢补

1.《BadNets Identifying Vulnerabilities in the Machine Learning Model Supply Chain》
概述:在一张图片上增加一个或者几个像素点来扰乱模型的准确性,导致在某些特定的训练集上精度异常低。
2.《Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images》
概述:利用遗传算法生成图像来扰乱模型,导致用户无法识别图像,电脑却可以识别图像。文章中使用了一种MAP-Elites的遗传算法来进行对抗样本的图片的生成。由于MAP-Elites算法的代码我并没有找到,(还在找),因此我使用了另一种比较普通的遗传进行测试,实验结果发现,当训练到一定的周期时,可以达到算法模型可以识别,但是人眼无法识别的地步(由于遗传算法原因,我的图像在一些眼尖的人中可以识别出来)。
3.《Explaining and Harnessing Adversarial Examples》
概述:利用 Fast Gradient Sign Method(快速梯度下降法)来对训练好的模型进行攻击,论文不对模型的参数造成攻击,而是在训练过程中依靠梯度反向生成对抗样本,举个例子,如果一个图片的某个像素点在一次训练的反向传播中为了让loss减少,应该是加上某个偏导数,而为了生成对抗样本,则反向的减去一些值,让这个loss反而增大。由于增加噪音无法指定让模型由正确的分类器转变为某个特定的错误分类,因此FGSM属于无目标攻击。
论文中给目标增加的噪音公式如下。其中sign为符号函数,即只判断正负,x为图片像素,y为真实标签值,前面那个希腊字母是学习率。学习率越大,噪音也越大,后面sign()的只影响正负。
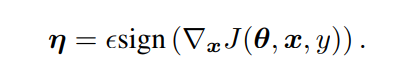
所以对抗样本的图片应该是 y_wrong=y_init+上述的噪音
ps:这里的噪音并非是一定要反向传播的梯度的相反值,可以自行设置,经过测试,少量噪音人对图片的分辨并不影响,但影响人工智能模型,但是过多的噪音不但影响人工智能模型,还影响人,这与论文2恰恰有点相反。
用python(pytorch)为图片增加噪音
def fgsm_attack(image, epsilon, data_grad):
sign_data_grad = data_grad.sign() # 获取梯度的符号,正为1,负为-1
perturbed_image = image + epsilon * sign_data_grad #epsilon 为增加噪音的度 本案例使用0 到 0.3 step=0.05
perturbed_image = torch.clamp(perturbed_image, 0, 1) # 将数值裁剪到0-1的范围内,超出1为1,小于0为0
return perturbed_image
下图为epsilon 0 到 0.3 step=0.05,生成的准确率,可以看到准确率下降的十分快

下图为从测试样例中抽取出来几个样本进行观察,可以发现,在epsilon=0.1时,图片与原图片差距不是十分明显,但是超过0.1后,就有点变样了,且识别的错误率也相当高。

后面还有个改良版的FGSM,也成为迭代式的FGSM,后期再补
《Adversarial examples in the physical world》
迭代式的FGSM,也就是I-FGSM,大题思想和FGSM差不多,但是FGSM使每张图片的像素点都改变了一个epsilon值,改动过于大,而迭代式则根据梯度下降,将每次下降的值累加起来,下图是我训练的IFGSM的结果,和FGSM差不多,只需要修改fgsm_attack方法和少量的test方法即可。
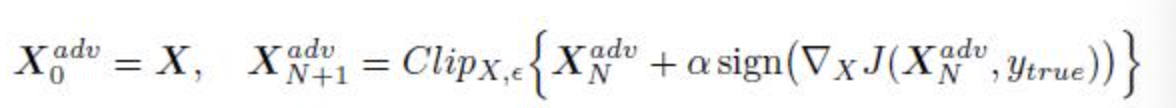
其中Clip为剪枝,阿尔法为学习率,这里xn adv为第n次迭代后的对抗样本

4.《Practical Black-Box Attacks against Machine Learning》
概述:提出了一种基于黑盒攻击的方式,在不知道模型的参数、结构等情况下,训练一个跟想要攻击的目标模型完成同样任务的替代模型,基于当前的模型去生成对抗样本,这些对抗样本最终被用于攻击原目标模型。
5.《Privacy and Security Issues in Deep Learning: A Survey》
概述:对人工智能安全的一个总结,由于水平不够,这篇文章先放到一边,晚点再看。
两种攻击方式 1.模型提取攻击——>目标复制部署的模型参数
2.模型反演攻击——>利用可用信息进行推演
安全威胁:
1.敌对攻击——>黑盒 与 白盒
2.中毒攻击
解决隐私问题
1.差分隐私
2.同态加密
3.安全多方计算
4.可信执行环境
深度学习安全性
1.输入预处理
2.恶意软件检测
3.提高模型鲁棒性
4.对抗性训练(最有用)
6《Adversarial Transformation Networks: Learning to Generate Adversarial Examples》
该文主要以训练一个深度网络模型,将原图作为输入,从而输出一个对抗样本。
以下为笔者对该文的理解,如有偏差,请指出
以Mnist网络为例,首先有两个网络,一个为f(x) 网络 ,一个是F(x)网络,f(x)为已知正常的训练网络,输入一张图片,输出预测的值。F(x)为我们需要训练的网络,输入图像x,输出对抗样本图像X。要求F(x)训练出来的图片,不但能保证让生成的图片和原图片保持相似,又要让f(x)能错误的分类为t。因此有了如下的损失函数:
其中r(y,t) 是reranking公式,其作用就是把输出的每一类的得分进行修改,对于我们想要网络误判我们的对抗样本为某个类t,就把其在原网络中的得分乘以一个倍数,且α>1,而其他类的得分保持不变。因此该目标其实是想达到一个目的,以MNIST作为假设,也就是若我们初始的每个分类的得分按从大到小排序为[3,8,5,0,4,1,9,7,6,2],在我们攻击后期待结果假设为7的话,则每个分类的得分按从大到小排序则为[7,3,8,5,0,4,1,9,6,2],即保持其他类别的分类置信度大小顺序不变,只把攻击的目标类置信度提高到最大。这么做的好处在于,在一定程度上另对抗样本更接近原样本,因为Top-2的预测结果是真实标签。
7.《UPSET and ANGRI : Breaking High Performance Image Classifiers》
这篇文章介绍了两种生成对抗样本的方法,分别为UPSET和ANGRI。UPSET 仅根据输入中的目标类别信息为每个类别产生单个扰动,因此该扰动对于每个目标类别都是通用的。在推断过程中,UPSTE 非常快。另一方面,ANGRI 可以访问输入图像,因此对于类似级别的视觉保真度,与 UPSET 相比,它可以产生更好的对抗图像。
UPSET方法中对抗样本X的生成方法为:
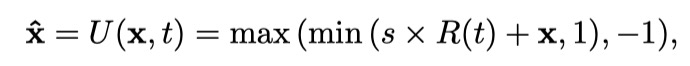
这里的max(min(x,1),-1)其实就是一个裁剪函数,让图像值在[-1,1]之间,不让他失效
x为原图像,x头上顶个帽子是生成的图像,R(t)为残次网络,s为调节的比例系数
ANGRI方法中对抗样本X的生成方法为:
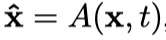
这个函数无力吐槽,鬼知道这个A是啥玩意?
两个的损失函数一致:
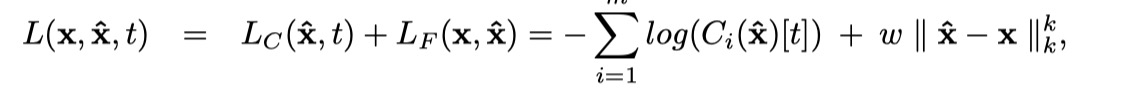
误差函数由两部分组成, LC表示分类器损失, LF表示保真度损失。
LC对不能产生目标攻击类进行惩罚,LF保证输出的对抗样本和原始样本足够相似
权重 w用来折中两个损失指标的,k的选择应该使它不会促进稀疏性,否则一些小的区域会很明显。这里感觉和论文6的损失函数有点像,一个保证图像相似,一个保证分类错误。
个人总结下,没get到这篇论文的创新点,具体的实现方法也没有描述出来,只给出一个损失函数+两个方法名,很泛泛的说一下(我上我也行),然后全是一些实验数据,没学到啥有价值的东西。还有两张图压根没看懂,对图的解释也没有(他咋通过审核的,来个佬解释下。















 4049
4049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









