






文章目录
前言
提示:这里可以添加本文要记录的大概内容:
辨析几个概念:
- 大语言模型
- 大模型
- 多模态大模型
- AI Agent
- 智能体
提示:以下是本篇文章正文内容,下面案例可供参考
一、大语言模型 V.S 大模型
1. 大语言模型(LLM)
通俗来讲,大语言模型主要是指专注于处理文本数据的模型, 其核心能力是文本生成、理解与推理。通常基于深度学习的**自然语言处理(NLP)**技术,如Transformer架构,通过大量文本数据训练,学习语言的语法、语义和上下文关系。
2. 大模型(General Foundation Models)
广义上指参数规模庞大且具备通用能力的基础模型,涵盖LLM、多模态模型、具身智能模型等。涵盖LLM、多模态模型、具身智能模型等。其核心特征是参数规模大(通常超百亿)、通用性强、支持零样本或小样本学习。例如,GPT-4 pro、deepseek-r1既可归类为LLM(文本处理),也可作为多模态大模型(处理图像)
大模型可以根据功能进行分类:
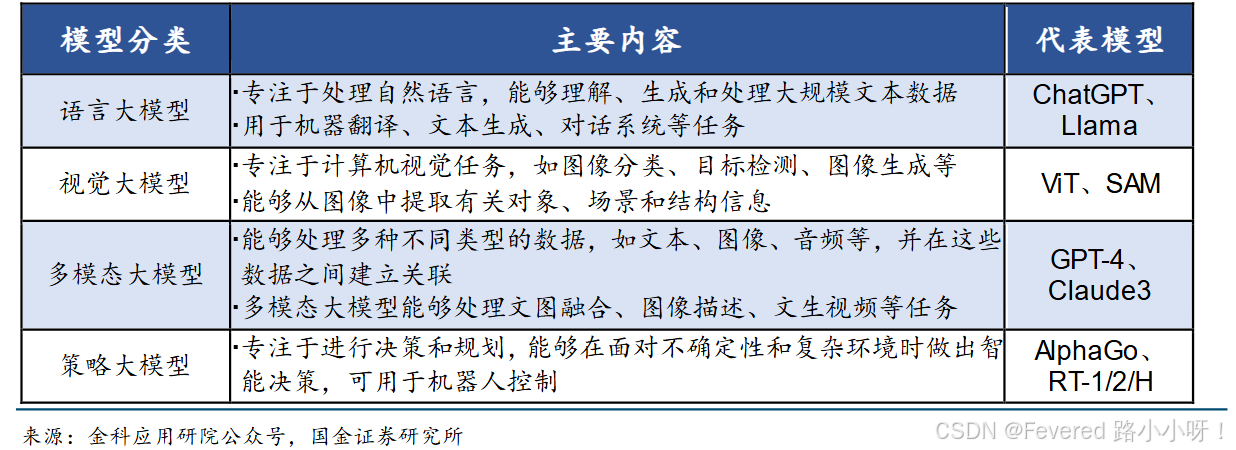
3. 多模态大语言模型(MM-LLMs)
从简单的角度来讲,多模态大语言模型(MLLM)是结合了大语言模型(LLM)推理能力与多模态信息(包括视觉、音频或视频等)输入、推理和输出能力的模型。可以看做各种大模型的集成化,大语言模型的一种扩展。
通常来说,多模态大语言模型主要由一个用于图像编码的视觉编码器和一个用于文本生成的大语言模型所组成,进一步这两个模型通过连接模块进行组合,从而将视觉的表示对齐到文本语义空间中。
以论文MM-LLMs:RecentAdvancesinMultiModalLargeLanguageModels为例理解
1. 多模态大模型的概述
-
为什么研究
随着模型和数据集的规模不断扩大,传统的MM 模型会产生大量计算成本 -
关键问题
不同类别的大模型都被单独训练过了, 那核心挑战是如何有效地将其他模式的LLM 算法模型连接起来,以实现协同工作。 -
研究内容
最初的研究主要集中在 MM 内容理解和文本生成方面,例如:图像-文本理解等任务
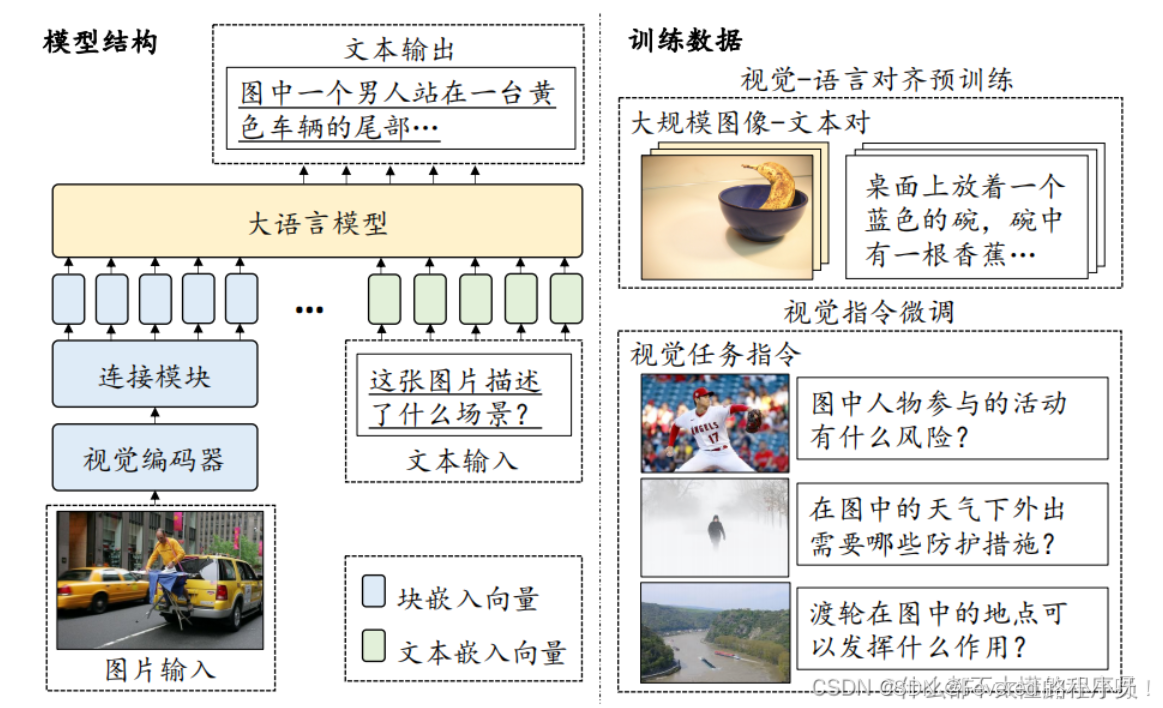
此外还有视频-文本理解,音频-文本理解等项目。
后来,MM-LLM 的能力被扩展到支持特定模态输出。这包括图像-文本输出任务,以及语音/音频-文本输出任务。
目前,最近的研究工作主要集中在模仿人类的任意模式到任意模式的转换【也就是灵活度更高,集成性更强】
2. 模型架构
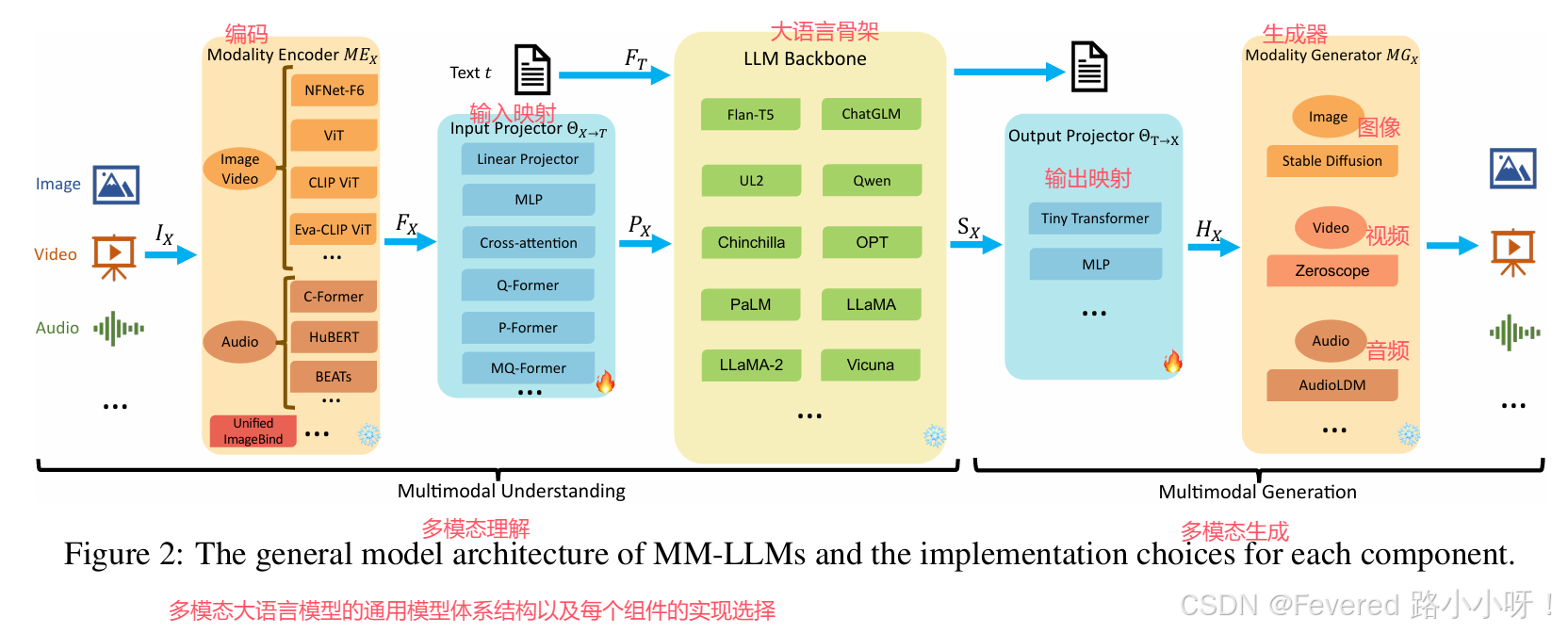
- 主流编码器
ViT
CLIP ViT
Eva-CLIP ViT
- 输入映射
输入映射θx→t的任务是使其他模式的编码功能与文本特征空间t保持一致。
3. 训练
多模态大语言模型的训练过程主要包括两个阶段:视觉-语言对齐预训练和视觉指令微调。
LLM采用 自回归预训练(如GPT系列)或掩码语言建模(如BERT)
4. 现状MM-LLMs

二、Agent and 智能体
目前搜索agent或者智能体,都会得到这样的答案


问题1:所以这两个是等价概念吗?
问题2: 人也是智能体吗? 那人工智能agent的终极目标是达到“人”级别的智能体吗?
1.AI Agent 真的 = 智能体吗?
- AI Agent
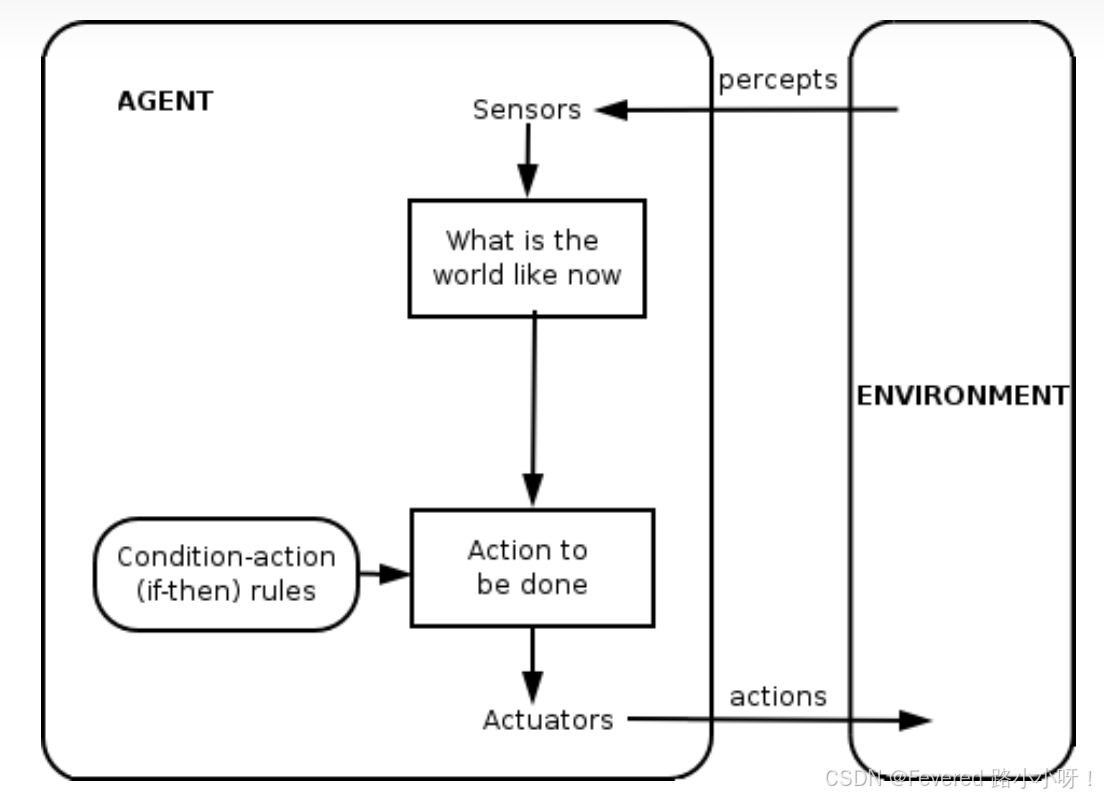
AI Agent 是一种能够感知环境、进行决策和执行动作的智能实体。它具备自主性、适应性和交互性,能够在复杂环境中独立运作。

早在1998年论文中,曾经提到的agent
[1] Jennings, Nicholas R., Katia Sycara, and Michael Wooldridge. “A roadmap of agent research and development.” Autonomous agents and multi-agent systems 1 (1998): 7-38.

首先界定agent的本质是计算机系统, “所处环境”指的是输入(输入的各种信息,包括物理世界和虚拟世界),外所处环境 也就是所谓的“情境性”。 也就是在不同输入情况下,能执行自主行动的 计算机系统。
对于以上定义中 Autonomy,也就是“自主”是如何界定的呢? 自动化?,文中作者想表达的自主为:“即系统应该能够在没有人类(或其他代理)直接干预的情况下行动,并且能够控制自己的行动和内部状态。”也就是所谓的“自主性”
最后一点“灵活性”, 包含:1. 反应灵敏,感知其所处的环境,并及时对环境中发生的变化做出反应; 2. 表现出机会主义的、以目标为导向的行为,并在适当的时候采取主动行动【原文用pro-active表述,有点像中文的未雨绸缪的感觉】; 3. 社交【个人倾向于交互】 能在适当的时候与其他人工代理和人类互动,以完成自己的问题解决并帮助他人完成活动。
从定义的角度来说,自1998年至今有不变的内核,也就是 感知环境 + 思考(自主)+ 行动的东西(实体?系统?)
- 智能体
一个问题:智能体这个词语是由agent英语衍生出来的新词还是原本就有的中文词语呢?【不太知道】
从字典来看, 就是表达辅助别人,帮别人做事。

那如此也可以将ai agent理解为“智能业务助理”
智能体(agent) 这一概念最早由 马文·明斯基 提出,他认为某些问题可经由社会中的一些个体经过协商后解决,这些个体就是智能体。 并且他还认为智能体具备社会交互性和智能性 。(百度百科)
如此来看,在中文表达中,将具有感知环境、决策并执行行动的 实体,描述为智能体 也就将这两个概念划上了等号。
那从这种表达来看 具有这些能力的是否都是智能体呢?比如人是智能体吗? 好像也没有人强调智能体是要基于人工智能。

【比起智能体,个人感觉ai agent更倾向于用 智能助理这个词语,这样的话,我们平时多说的“智能体/agent” 基本可以表述为“大模型+提示词+思维链+决策+执行”】
其他不同表述:
己搭建一个知识库,每次使用大模型的时候都会从知识库中获取知识输入到大模型,以获得更好的结果;而再高级一点的就是使用提示词+知识库+思维链+外部工具(API,功能代码等)来实现人类才能做到的事情。
这个依靠大模型本身的能力是无法完成的,因此就需要使用外部工具,而这也叫做Agent(代理)技术。
————————————————
原文链接:https://blog.csdn.net/bagell/article/details/142873205
2. Agent种类
符号逻辑 Agent: 早期AI研究依赖符号逻辑Symbolic,通过规则和符号表示知识(如关键词),模拟人类思维,但面临处理不确定性和大规模问题的局限性。
响应式 Agent: 不同于符号逻辑 Agent,响应式Reactive Agent注重快速响应,直接映射输入输出,计算资源需求低,但缺乏复杂决策能力。
强化学习 Agent: 强化学习使Agent通过环境交互学习,追求累积奖励。深度强化学习提升了处理高维输入的能力,但面临训练效率和稳定性挑战。
迁移学习和元学习被引入以提升Agent的学习效率和泛化能力,减少对新任务的样本依赖,尽管存在源任务与目标任务差异导致的挑战。
大模型 Agent: 由于LLM已经展示出令人印象深刻的新兴能力,并受到广泛欢迎,研究人员已经开始利用这些模型来构建AI Agent。具体来说,他们采用 LLM 作为这些Agent的大脑或控制器的主要组成部分,并通过多模态感知和工具利用等策略来扩展其感知和行动空间。通过思维链(CoT)和问题分解等技术,这些基于 LLM 的Agent可以表现出与Symbolic Agen相当的推理和规划能力。它们还可以通过从反馈中学习和执行新的行动,获得与环境互动的能力,类似于Reactive Agent。同样,大型语言模型在大规模语料库中进行预训练,并显示出少量泛化的能力,从而实现任务间的无缝转移,而无需更新参数。
LLM-based Agent已被应用于各种现实世界场景、如软件开发和科学研究。由于具有自然语言理解和生成能力,它们可以无缝互动,从而促进多个Agent之间的协作和竞争。
参考:https://zhuanlan.zhihu.com/p/657937696
比较有趣的一张图,说清大语言模型-智能体-通用人工智能的关系
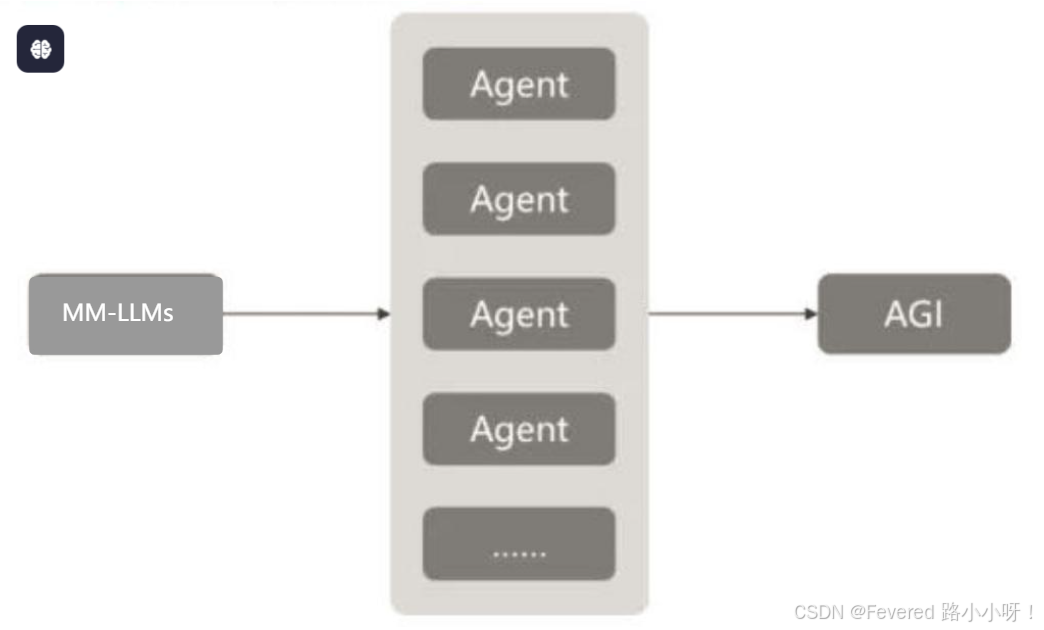
3. Agent和LLM研究的双向关系
LLM作为AI Agent的认知核心,这些模型的发展为完成这一步骤提供了质量保证。
从Agent的角度来看待LLM,对LLM研究提出了更高的要求,同时也扩大了LLM的应用范围,为实际应用提供了大量机会。

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









