




1.数据导入方法(两种方式)
(1)在菜单data----data editor中, 将原始数据复制粘贴到表格中,注意第一行是否变量名
(2)菜单file-import ,然后导入对应格式数据(或者用命令import 文件格式 路径 文件名 第一行是否变量名等)
导入后,可利用菜单file---Save as进行保存,保存成stata格式,后缀为 .dta
以陈强老师的高级计量经济学数据为例,导入数据
import excel "I:\陈强高级计量经济学及stata应用(第二版)全部数据\nerlove.xls", sheet("NERLOVE") firstrow或者菜单file---import---Excel
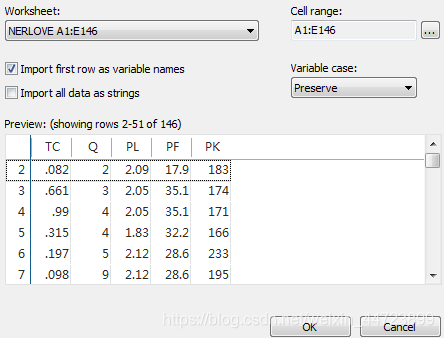
2.打开数据
采用file--open 打开数据,这里主要打开stata自身格式的数据。注意:日期数据导入到 stata内部,所有日期变量的存储格式均为“elapsed data",从1960年1月1日到目前经历了多少单位(年、月、日)
3.变量标签
在菜单data ---variables Manager下进行变量属性设置, 注意stata区分大小写
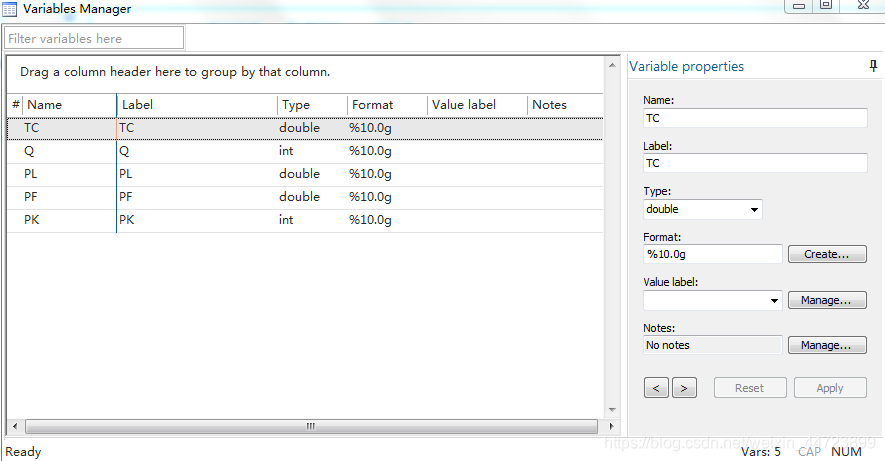
4.数据基本展现
(1)数据概貌
describe 描述数据样本量、变量数、变量属性等,可简写为“d"
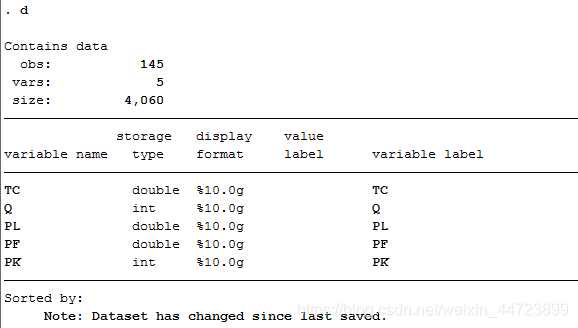
(2)看变量具体数值
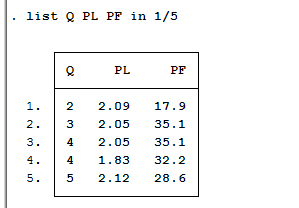
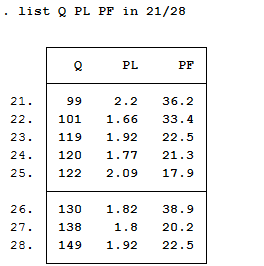
list v1 v2 看变量名为v1、v2的数值,如果只想看前5个数值,可用list v1 v2 in 1/5,
如果要观察第21到28个观测值,则用list v1 v2 in 21/28
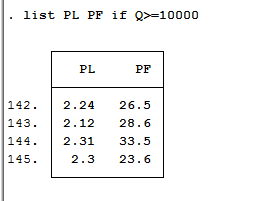
如果要看满足条件的数据,比如q >=10000条件下的v1 v2,则可用list v1 v2 if q>=10000,不等于表示为~=
(3)数据的统计特征
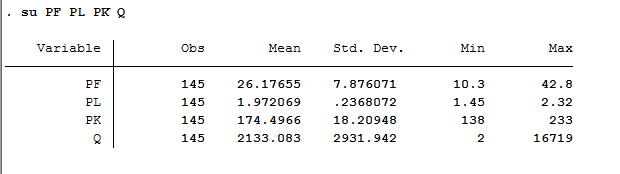
描述统计用summarize v1 将显示变量v1的均值,最大,最小,标准差等描述统计量(可简写为su)
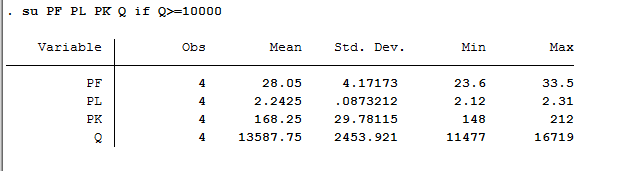
满足条件的可以用 if su v1 if q>10000
如果想看百分位数,偏度,峰度等可使用 su v1,detail
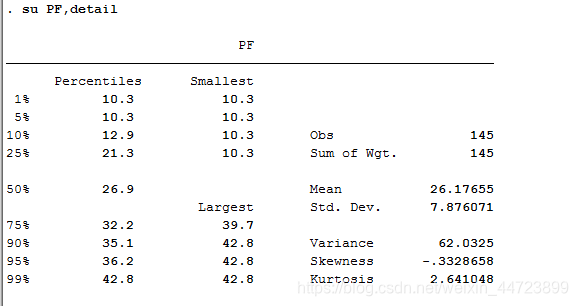
显示变量的经验累积分布函数,可使用 tabulate v1

显示变量间相关系数可用 pwcorr v1 v2 v3,sig star(0.05) sig表示显示显著性水平,star表示小于等于0.05的打上星号,不指定变量表示对数据集所有变量求相关系数
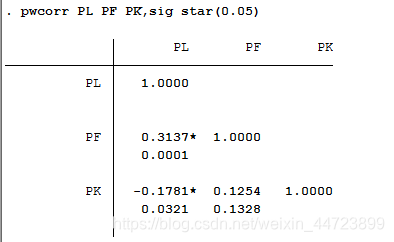
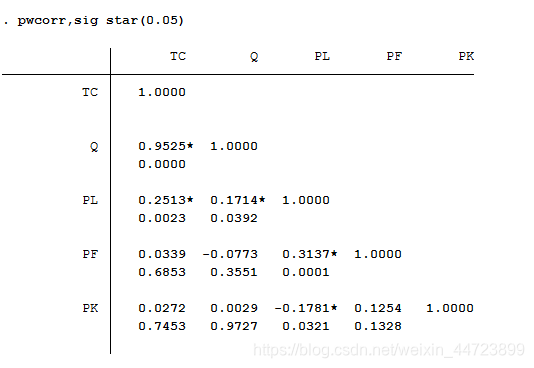


















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











