







PatchmatchNet
论文:PatchmatchNet: Learned Multi-View Patchmatch Stereo(2020)
1.Introduction
出发点: 由于 3D CNN 通常耗费时间和内存,因此一些方法在特征提取期间对输入进行下采样,并以低分辨率计算成本量和深度图。然而,以低分辨率提供深度图会损害准确性。
主要工作: 提出了 PatchmatchNet,将patchmatch的算法思想结合到cascade当中,旨在减少高分辨率多视图立体的内存消耗和运行时间
cascade方法简介
这种方法的优点是减少计算量和内存。首先进行多尺度特征提取,然后先使用最低分辨率的特征构建包含所有视差范围(0-192)的cost volume,进行代价聚合和视差回归得到初始视差图;然后在下一阶段中只需要根据初始视差图构建一个包含较小视差范围的cost volume,从而减少计算量和内存。

cascade方法相关论文:
(1)Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching
(2)CFNet: Cascade and Fused Cost Volume for Robust Stereo Matching
Patchmatch算法简介
PatchMatch相关知识:Patchmatch-笔记_粟悟饭&龟波功的博客-CSDN博客
2. Method
PatchmatchNet 的结构如下图所示。它由多尺度特征提取、包含在从粗到细的框架中的基于学习的 Patchmatch模块和空间细化模块组成。

2.1 Multi-scale Feature Extraction
金字塔多尺度特征提取
2.2 Learning-based Patchmatch
设计的patchmatch模块具体结构如下图所示,左边是通过多尺度特征提取得到的各个视图的特征图,右边的的输出是深度图。首先介绍每个模块的功能。

2.2.1 Initialization and Local Perturbation
在 Patchmatch 的第一次迭代中,以随机方式执行初始化以促进多样化。基于预定义的深度范围 [dmin, dmax],在逆深度范围内对每个像素的 Df 深度假设进行采样,对应于图像空间中的均匀采样。为了确均匀地覆盖深度范围,将(逆)范围划分为 Df 区间,并确保每个区间都被一个假设覆盖。
对于阶段 k 的后续迭代,为每个像素生成一个随机扰动N,来进行随机搜索,随机搜索的范围逐渐减小。
2.2.2 Adaptive Propagation
传统的传播只在邻域内传播,如图(b)所示,存在的问题是因为深度值的空间一致性一般只存在于来自同一物体表面的像素,所以不同物体表面的传播没有太大的作用。因此,作者使用的是自适应传播,自适应传播的示意图如下图(c)所示,其传播的像素来自于同一个物体表面。
自适应传播的实现(基于Deformable Convolution Networks的思想):简单的说就是在原来的基础上加上一个偏置offest,假设当前像素的坐标为(x,y),则其上方像素坐标为(x,y+1),传统的传播就直接使用这个坐标来传播,自适应传播则要加上一个偏置,即传播的像素不是(x,y+1)而是(x+offestx,y+offesty)。这些偏置是使用2D卷积从参考图中学习到的,每个像素都有其不同的偏置,通过这些偏置,窗口就不再限定于正方形了。

2.2.3 Adaptive Evaluation
自适应评估模块执行以下步骤:可微扭曲、匹配成本计算、自适应空间成本聚合和深度回归。
Differentiable Warping
warping的公式如下,K是相机的内参矩阵,R是旋转,t是平移。
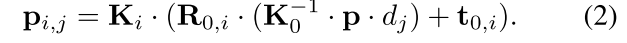
Matching Cost Computation
相似性的计算公式如下图所示,i是视图索引,j是视差,C是通道数,
F
0
F_0{}
F0是参考图的特征,
F
i
F_i{}
Fi是视图的特征。公式的意思是将特征在通道维度上分成G组,然后点乘,每个组取均值,即类似于GWC-Net构建cost colume的方法。
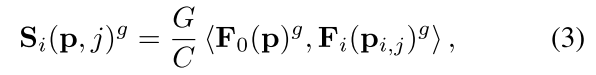
计算完成后
S
i
S_i
Si的维度为
S
i
∈
R
W
×
H
×
D
×
G
S_i{}\in R^{W\times H\times D\times G}
Si∈RW×H×D×G。
每个视图的
S
i
S_i
Si最终要加起来得到最后的相似性矩阵
S
S
S,相加之前要乘上一个权重。本文的权重网络是由具有 1×1×1 内核和 sigmoid 非线性的 3D 卷积层组成,初始相似度
S
i
S_i
Si经过权重网络后得到
P
i
∈
P
W
×
H
×
D
P_i{}\in P^{W\times H\times D}
Pi∈PW×H×D,最终的权重
w
i
(
p
)
w_i(p)
wi(p)由下式得到:
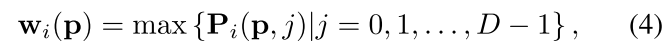
然后将各个视图得到的
S
i
S_i
Si相加得到
S
ˉ
\bar{S}
Sˉ:
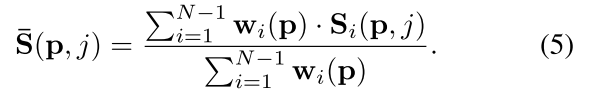
S
ˉ
\bar{S}
Sˉ的维度为
S
ˉ
∈
R
W
×
H
×
D
×
G
\bar{S}\in R^{W\times H\times D\times G}
Sˉ∈RW×H×D×G,通过 3D 卷积后得到cost volume C,C的维度为
C
∈
R
W
×
H
×
D
C\in R^{W\times H\times D}
C∈RW×H×D。
Adaptive Spatial Cost Aggregation
这里的做法其实和自适应传播相似。传统的局部代价聚合通常在正方形窗口的邻域内进行,本文使用自适应的窗口,和自适应传播一样,通过从参考图中学习偏置offest来实现,最终代价聚合的公式为:
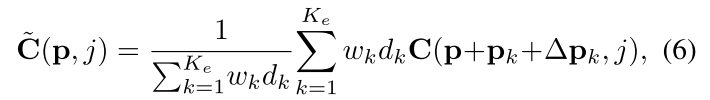
其中 wk 和 dk 是基于特征和深度相似性对成本 C 权重(详细见原文的补充材料)。
C
~
\tilde{C}
C~的维度为
C
~
∈
R
W
×
H
×
D
\tilde{C}\in R^{W\times H\times D}
C~∈RW×H×D。
Depth Regression
聚合成本
C
~
\tilde{C}
C~通过softmax后得到概率矩阵P,最后通过加权和得到初始深度估计:
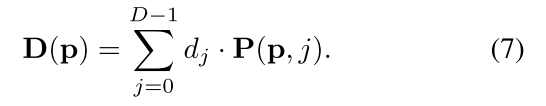
2.3 Depth Map Refinement
补充原图信息和特征信息进行卷积,学习到一个深度残差,加到初始深度估计上,得到最终的深度图。
总体步骤说明
前面说明了网络的各个模块的功能与大体实现思想,下面总结一下整体的步骤。
步骤: 每一层的patchmatch模块都需要迭代多次。在第一层的第一次迭代中,首先为每个像素随机初始化一个深度,然后通过传播和随机扰动得到更好的深度值,通过自适应评估模块得到下一次迭代的深度值,迭代一定次数后将深度图上采样输出给下一层,作为初始的深度值。这样经过三个patchmatch模块后得到初始的深度图,经过上采样和细化得到最终的深度图。
3 Conclusion
PatchmatchNet是一种基于学习的 Patchmatch 模块的的新型cascade网络,增加了基于深度特征的学习自适应传播和评估模块。 PatchmatchNet 具有低内存要求,独立于视差范围,与大多数基于学习的方法不同,PatchmatchNet 不依赖于 3D 成本量正则化。嵌入到cascade中,PatchmatchNet 进一步显示出高处理速度。尽管结构简单,但在 DTU、Tanks & Temples 和 ETH3D 上的大量实验表明,与最先进的技术相比,它具有非常低的计算时间、低内存消耗、良好的泛化特性和有竞争力的性能。 PatchmatchNet 使基于学习的 MVS 更高效,更适用于内存受限设备或时间关键应用程序。

















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









