







目录
架构设计
基于 VxWorks 的 RapidIO 通用接口架构设计如 图所示。图中所示 RapidIO 数据并不经过 TCP / IP 协议层,而是经过一个 RIO 协议层,该方法明显 的区别于 IPover RapidIO 的方式。该方法不仅保留 了 TCP / IP 协议层,而且在性能上大约是 IPover RapidIO 的 3.5 倍左右。
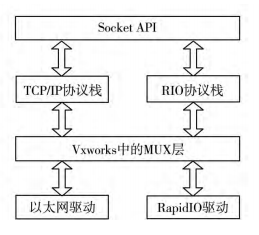
整个架构的最底层为 RapidIO 驱动程序,负责最基本的 RapidIO 数据的接收和发送,此 RapidIO 驱动挂接在 MUX 层下,属于 END( Enhanced Network Driver) 驱动程序。END 驱动是一种基于 MUX ( 多路开关) 的模式,MUX 位于数据链路层与网络层 之间,为多个网络协议提供访问硬件驱动的机 制。MUX 层使得数据收发过程变得简单,驱动不需要挂接钩子程序来向上层传递数据。 RIO 协议层对应以太网的 TCP / IP 层,该层负责 数据的 CRC校验,分片重组,帧头解析,参数配置。 相较于 TCP / IP 层非常复杂的协议过程,RIO 协议层 精简了许多,保证了数据的高效传递; 在 RIO 协议层加入了 CRC校验,所以协议层精简之后仍能保证数据的可靠性。RIO 协议层具体组成如图所示。

RIO 协议层实现
RIO 协议层注册
本文实现的是为用户提供一套完整的类 UDP 接口,来实现 RapidIO 网络通信,即提供 socket、 bind、sendto、recvfrom、close 等,这些接口的编程模式 和以太网下的 socket 编程模式一样,没有任何区别。 在向内核注册自定义协议层的时候,为了区分 TCP / IP 协议族,自定义协议族 AF_RIO = 7。
在 VxWorks 6.8 系统中,函数 ipnet_sock_register_ops 是用来向系统注册 TCP / IP 协议族的,本文也用该函数来完成向系统注册自有的协议族。协议层的实现是一系列的函数构成的,这些函数保存在 Ipnet_sock_inet_ops 的结构体中,本文主要实现了如下函数,
ops->sock.domain = RIO_INET; /* RIO_INET = = 7*/
ops->sock.hdr _ space = RIO_HEADER_SIZE; /* 16*/
ops->usr_recv = rio_usr_sock_recvmsg;
ops->sock.init = ipnet_sock_rio_init;
ops->sock.bind = rio_sock_bind;
ops->sock.send = ipnet_rio_sendto; /* add rio header*/
ops->network_send = rio_ip4_sendto; /* call the rio driver*/
ops->sock.getname = rio_sock_ip4_getname;
ops->sock.close = rio_sock_close; 为了区分以太网协议类型,本文自定义协议类 型为 RIO_DGRAM = 2,协议号为 RIO_IPPROTO_UDP = 42,即:
ops→inet.sock.type = RIO_DGRAM;
ops→ inet.sock.proto = RIO_IPPROTO_UDP; 除此之外,还得向系统注册 sockLib 的实现,使用函数 sockLibAdd 进行注册。在应用层调用 socket 接口时,系统会通过调用 sockLib 中的实现来调用 Ipnet_sock_inet_ops 中的函数。sockLib 主要实现了 如下几个函数:
static SOCK_FUNC rio_windnet_sockfuncs =
{
.socketRtn = rio_windnet_socket,
.bindRtn = rio_windnet_bind,
.sendtoRtn = rio_windnet_sendto,
.recvfromRtn = rio_windnet_recvfrom,
.ioctlRtn = rio_ioctl,
.getpeernameRtn = ipcom _windnet _getpeername,
.getsocknameRtn = ipcom _windnet _ getsockname,
.getsockoptRtn = rio_windnet_getsockopt,
.setsockoptRtn = rio_windnet_setsockopt,
.closeRtn = rio_windnet_close,
};基于 RapidIO 的 socket 接口
int socket( int family,int type,int proto) ;
family: 协议族,使用 AF_RIO,数值为 7; type: 使用 RIO_DGRAM,数值为 2; proto: 使用 RIO_IPPROTO,数值为 42。
调用该函数创建一个 RapidIO 网络的套接字, 创建的套接字会放在自己定义的一个链表中,此处并不适用内核的套接字链表,因为这样会与以太网下的套接字相冲突。 该函数会调用 rio_windnet_socket,进而调用 ipnet_sock_rio_init 函数完成一个 RapidIO 网络套接字的创建。
int bind ( int sockfd,struct sockaddr * maddr, socklen_t addrlen) ;
该函数用来绑定一个套接字的地址、协议、端口号,同时检查被绑定的端口号是否被调用,如果端口号已被使用,则返回 - ERROR,成功绑定反回 0。参数 maddr 的 IP 地址填写 RapidIO 的设备 ID,即: maddr.sin_addr.s_addr = deviceID; 该函数调用 rio_windnet_bind,进而调用 rio_sock_bind 函数完成套接字端口和设备 ID 的绑定。
int sendto( int sockfd, void * buf, size_t len, unsigned flags, struct sockaddr * addr, int addrlen) ;
RapidIO 数据使用 DMA 传输,驱动设置的每个收发缓存大小为 60kB,所以 len 支持最大 60kB 数据的传输,大于 60kB 的数据要在 RIO 协议层进行数据分片,在接收端要进行数据的重组。参数 addr 中的 IP 地址直接填写 RapidIO 端点的设备 ID,即 addr.sin_addr.s_addr = deviceID; 其余的与以太网下的参数一样。该函数调用 rio_windnet_sendto 函数,进而调用 rio_ip4_sendto 函数和 muxSend 函数, 把发送数据送入驱动的发送缓存,发送成功返回发送的字节数。
int recvfrom( int sockfd,void * buf, size_t size, int flags, struct sockaddr * addr int addr_len) ;
该函数阻塞等待底层有数据到来,具体来说是判断 sockfd 的接收队列是否为空,有则返回,没有则阻塞,该函数用法和参数与以太网下一样,通过该函 数可以得到的 addr 中的 ip 地址为发送端的 deviceID,接收的最大长度 size 为 60kB。该函数调用 rio_windnet_recvfrom,进而调用 rio_usr_sock_recvmsg 检查套接字的接收队列是否为空,若为空,则阻塞等待,若不为空则返回接收的字节数。
int close( int sockfd) ;
关闭一个 RapidIO 网络套接字,具体操作是把套接字链表中对应的套接字删除,同时释放套接字的接收缓存和发送缓存,清除套接字的使用内存,设置套接字的传输状态为关闭。该函数调用 rio_windnet_close,进而调用 rio_sock_close 完成套接字资源 的释放,关闭一个套接字。
基于 RapidIO 的 socket 的编程模式如下
(1) 客户端模式
#include<sys/socket.h >
#include<netinet/in.h>
#include<sys/types.h>
#include<arpa/inet.h>
#define AF_RIO 7
int main()
{
fd = socket(AF_RIO,2,42);
sendto(fd, dataBuf, dataLen, 0, (struct sockaddr *) addr, len);
close(fd);
}(2) 服务端模式
#include<sys/socket.h >
#include<netinet/in.h>
#include<sys/types.h>
#include<arpa/inet.h>
#define AF_RIO 7
int main()
{
fd = socket(AF_RIO, 2, 42);
bind (fd, (struct sockaddr *) &addr, sizeof (struct sockaddr_in) );
recvfrom (fd, dataBuf, MAX_SIZE, 0, (struct sockaddr*) &recvaddr,&addrlen);
printf(“recvData = %s, source ID:%d\n”, dataBuf, recvaddr.sin_addr.s_addr);
close(fd);
}RIO 协议层的数据发送和接收过程
接收数据过程分成上半部和下半部两个部分,如图所示,上层应用程序调用 recvfrom 函数,首先判断 sock 的接收队列是否为空,为空则阻塞,非空则进行数据的拷贝,并在用户层返回收到的字节数。 下半部的接收程序专门接收来自驱动的数据,同时 负责对数据进行重组的功能。
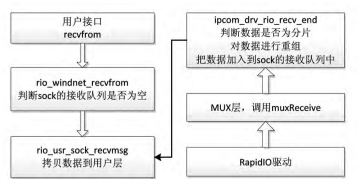
在下半部的接收过程中,RapidIO 驱动接收到 数据之后,通过调用 muxReceive 函数将数据往上层 协议传递,协议的接收函数收到数据之后,首先检查数据是否分片,若不是分片,则把数据直接加入到对应的 sock 的接收队列中去,若是分片,则把该数据加入到一个二维列表中,直到所有分片都接收完成之后,才把队列头部的分片加入到 sock 的接收队列中。
在协议层的发送数据过程中,主要有两部分,第一部分判断数据是否需要分片,第二部分填充包头, 包头的格式如图 4 所示,其中源 id 和目的 id 对应 TCP / IP 的 IP 地址,cmd 用于区分 doorbell 的消息类型,数据总长度、分片标签和分片偏移用来作为拷贝数据的依据,判断数据是否需要分片和数据重组, CRC 校验使用的是 CRC-16[7],版本号是 0xffff,对应“RapidIO socket”的意思。填充完包头之后,直接 调用 MUX 层的发送函数 muxSend,把数据传递到驱动层,由驱动把数据发送出去。

RapidIO 驱动层实现
驱动层注册
RapidIO 驱 动 为 VxWorks 下 的 标 准 END 驱动,注册过程符合 VxWorks 下 END 驱动规范。 VxWorks 下驱动层和协议层之间有个 MUX 层, MUX 管理网络协议接口和底层硬件接口之间的 交互,将硬件从网络协议的细节中隔离出来,协议和驱动是彼此独立的,这使得新的协议和驱动的添加更加容易。本文的 RapidIO 驱动实现了以下功能。
LOCAL NET_FUNCS rioFucTable =
{
(FUNCPTR) rioStart, /* start func.*/
(FUNCPTR) rioStop, /* stop func.*/
(FUNCPTR) rioUnload, /* unload func. */
(FUNCPTR) rioIoctl, /* ioctl func.*/
(FUNCPTR) rioSend, /* send func.*/
(FUNCPTR) NULL, /* multicast add func.*/
(FUNCPTR) NULL, /* multicast delete func.*/
(FUNCPTR) NULL, /* multicast get fun.*/
(FUNCPTR) rioPollSend, /* polling send func.*/
(FUNCPTR) rioPollRcv, /* polling receive func.*/
NULL,
(FUNCPTR) pktDataGet,
};其中 rioStart、rioIoctl 为 END 设备初始化和注册调用的函数。rioStop、rioUnload 为驱动的停止和卸载的函数。rioSend 为驱动的发送函数,接收协议层传递过来的数据报,pktDateGet 用来区分收到的数据报是否为 RapidIO 数据,并指定上传至哪个上层 协议,这里指定上传至自定义协议层。rioPollSend 和 rioPollRcv 函数并没有实现任何内容,此处有这两个函数 END 驱动才能注册成功,故这两个函数出 现在这里。
数据的发送接收
RapidIO 互联协议定义了在两个节点之间快速传递 2 字节的通信方式,即门铃通信。本文使用发送门铃来控制数据的传输,在系统中预先分配好接收 buff 和发送 buff,并在加载 END 驱动的时候完成 RapidIO 设备的初始化工作。
下图是进行一次 RapidIO 数据收发的过程,本 文使用了接收进程、发送进程、doorbell 中断和 RDMA 传输来实现数据在用户态进程的传输。接收端用户进程调用函数 recvfrom 进入内核,等待数据的 到来; 发送端用户进程调用函数 sendto 进入内核,

首先判断发送缓存是否已满,若满了,则进入阻塞等待,若没有满,则把用户层的数据拷贝到发送缓存区,并发送一个 dataSend 的门铃消息给接收端; 接 收端的门铃中断函数接收到 dataSend 门铃消息之 后,调用 rioNread 函数,进行一次 DMA 操作,读取发 送端发送缓存中的数据,完成之后,给发送端发送一 个 ack_msg 的门铃消息,通知发送端数据已经被取 走,同时唤醒阻塞的接收进程,接收进程把数据拷贝 至用户层; 发送端收到 ack_msg 的门铃消息之后,把 对应的发送 buff 置为 empty,以使该 buff 可以进行 下一次的数据发送。
本文的驱动有简单的流量控制机制,在接收端进行 Nread 操作时,要先判断是否有空的接收缓存, 如果有则接收,没有则不接收。当不进行接收时,发送方就不能收到 ack_msg,这样就能同步发送方的发送速率和接收方的接收速率,达到一个简单的流量控机制。在测试中发送速率和接收速率基本都稳定在 256MB / s 左右。
实验结果分析
实验环境为两个 Freescale 公司的 8641D 芯片, 中间通过 RapidIO 交换机相连,RapidIO 的物理链路 采用 8 /10 编码,速率为 4 × 3.125Gbps。
在测试中,一个 8641D 芯片上运行 server 程序,另一个芯片上运行 client 程序,数据由 client 发向 server,每次发送的数据大小为 60kB,不停地发送,测试结果如下。同时进行了稳定性测试,即两块开发板进行乒乓测试长达 7 个小时,系统没有出现故障,没有出现死机或者数据传输错误的情况。
通过注册 RapidIO 以太网卡,上层走 TCP / IP 协议栈的速率如表 1 所示,通过挂载 RapidIO END 驱 动,上层走 RIO 协议栈的速率如表 2 所示。表中的数据量是每次发送数据的数据量,可以看到通过 socket API 走自定义的协议栈的速率几乎是 TCP / IP 的 3.5 倍,并且充分发挥了 RapidIO 数据链路的性能,同时也向用户提供了一套标准的 socket 接口,使得开发人员可以像以太网下面程序设计一样去编写 RapidIO 应用程序。

转自: 张南, 柴小丽, 王浩,等. 基于VxWorks的RapidIO网络通用接口设计[J]. 信息技术, 2017, 000(009):159-163.















 1051
1051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









