







 本文详细解释了C++中的深拷贝和浅拷贝概念,强调了当对象包含指针时浅拷贝可能导致的问题,即指针悬挂。通过示例代码展示了浅拷贝导致的内存泄漏和程序崩溃,并提出了通过自定义深拷贝构造函数来解决这一问题。理解深拷贝和浅拷贝对于防止内存错误至关重要。
本文详细解释了C++中的深拷贝和浅拷贝概念,强调了当对象包含指针时浅拷贝可能导致的问题,即指针悬挂。通过示例代码展示了浅拷贝导致的内存泄漏和程序崩溃,并提出了通过自定义深拷贝构造函数来解决这一问题。理解深拷贝和浅拷贝对于防止内存错误至关重要。
什么是深拷贝和浅拷贝
关于此问题我们首先要知道这是共性问题,在不少程序语言中都存在。
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存(分支)。
- 浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。
- 如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址里的值,就会影响到另一个对象。
深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象,是“值”而不是“引用”(不是分支)
- 拷贝第一层级的对象属性或数组元素
- 递归拷贝所有层级的对象属性和数组元素
- 深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。
再看这个问题:为什么要使用深拷贝?
根据上述浅拷贝和深拷贝的对比,答案很显然,我们希望在改变新的数组(对象)的时候,不改变原数组(对象)
在JS中,深拷贝和浅拷贝是只针对Object和Array这样的引用数据类型的。
深拷贝和浅拷贝的示意图大致如下:
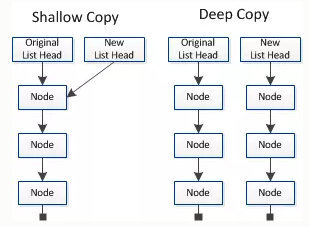
C++中的深拷贝和浅拷贝
C++中的深拷贝和浅拷贝和上一节所说的情况基本类似,但也有些许不同点。
-
在未定义显示拷贝构造函数的情况下,系统会调用默认的拷贝函数——即浅拷贝,它能够完成成员的一一复制。当数据成员中没有指针时,浅拷贝是可行的;但当数据成员中有指针时,如果采用简单的浅拷贝,则两个类中的两个指针将指向同一个地址,当对象释放时,会调用两次析构函数,而导致指针悬挂现象,所以,此时,必须采用深拷贝。
-
深拷贝与浅拷贝的区别就在于深拷贝会在堆内存中另外申请空间来储存数据,从而也就解决了指针悬挂的问题。简而言之,当数据成员中有指针时,必须要用深拷贝。
指针指向非法的内存地址,那么这个指针就是悬挂指针,也叫野指针。意为无法正常使用的指针。
#include<iostream>
using namespace std;
class Test
{
private:
int* p;
public:
Test(int x)
{
this->p=new int(x);
cout << "对象被创建" << endl;
}
~Test()
{
if (p != NULL)
{
delete p;
}
cout << "对象被释放" << endl;
}
int getX() { return *p; }
};
int main()
{
Test a(10);
Test b = a;//会调用默认的拷贝构造函数
return 0;
}
在VS2019中运行得到如下结果:
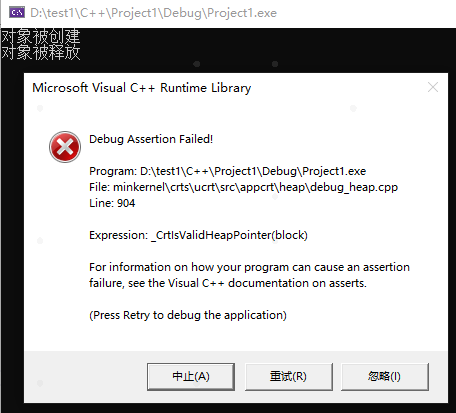
那么为什么造成崩溃?
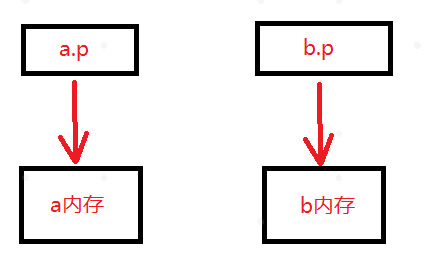
这里构造函数中有堆内存的分配,b=a也是调用的默认的拷贝构造函数,那么就会形成如下图的情况,a和b指向了同一块内存空间,所以当调用析构函数的时候,内存空间会被析构两次,所以这将导致内存泄露或程序崩溃。
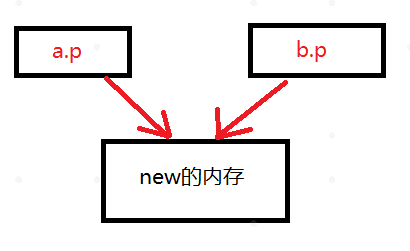
如何解决
利用深拷贝,在自定义拷贝构造函数中,在堆内存中另外申请空间来给新创建的对象储存数据
#include<iostream>
using namespace std;
class Test
{
private:
int* p;
public:
Test(int x)
{
this->p=new int(x);
cout << "对象被创建" << endl;
}
~Test()
{
if (p != NULL)
{
delete p;
}
cout << "对象被释放" << endl;
}
int getX() { return *p; }
//深拷贝(拷贝构造函数)
Test(const Test& a)
{
this->p = new int(*a.p);
cout << "对象被创建" << endl;
}
//浅拷贝(拷贝构造函数)
//Test(const Test& a)
//{
// this->p = a.p;
// cout << "对象被创建" << endl;
//}
};
int main()
{
Test a(10);
Test b = a;//如果有我们手动写的拷贝构造函数,C++编译器会调用我们手动写的
return 0;
}
运行结果(没有再出现崩溃问题):
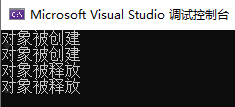
这时的内存分配如下图所示:
【参考鸣谢】
https://blog.csdn.net/wue1206/article/details/81138097
https://blog.csdn.net/u014183456/article/details/117380821 【优质】


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











