









Datawhale组队学习第27期:集成学习
本次学习的指导老师萌弟的教学视频
本贴为学习记录帖,有任何问题欢迎随时交流~
部分内容可能还不完整,后期随着知识积累逐步完善。
开始时间:2021年7月26日
最新更新:2021年8月1日(Task7 Stacking和案例一)
一、Blending
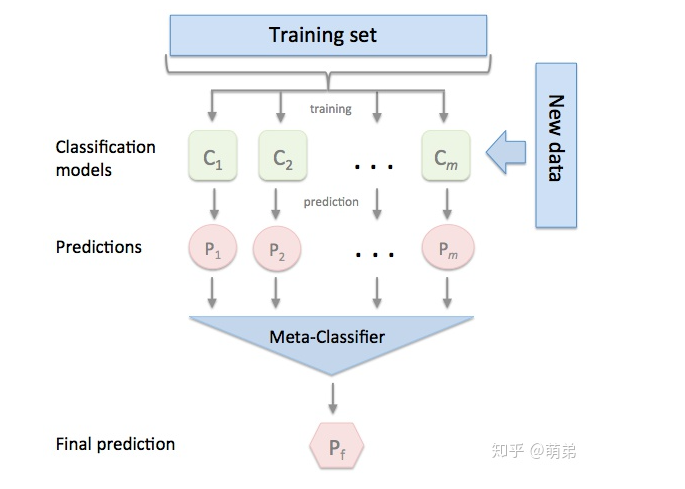
1. 集成方式
- 划分训练集和测试集
T
e
s
t
Test
Test
- 这里的训练集用于训练最优模型
- 测试集用于判断模型性能
- 训练集进一步划分训练集
T
r
a
i
n
Train
Train和验证集
V
a
l
Val
Val
- 这里的训练集是训练给定的超参数下的模型
- 验证集是用于调参模型的超参数以达到最优模型
- 创建第一层的
K
K
K个模型,使用
T
r
a
i
n
Train
Train进行
K
K
K个模型训练
- K K K个模型可以同质,也可以是异质
- 训练好的模型对
V
a
l
t
r
u
e
Val_{true}
Valtrue和
T
e
s
t
t
r
u
e
Test_{true}
Testtrue 进行预测,得到
V
a
l
p
r
e
d
Val_{pred}
Valpred和
T
e
s
t
p
r
e
d
Test_{pred}
Testpred
- 集多种模型的特性和最优结果
- 创建第二层的单个模型,使用
V
a
l
p
r
e
d
Val_{pred}
Valpred进行训练,对
T
e
s
t
p
r
e
d
Test_{pred}
Testpred进行预测
- 将多种模型的预测结果作为特征进行训练
- 第二层的预测结果作为整个测试集的结果
2. 特性
-
简单且易实现,需要的理论分析少
-
验证集只留出一部分,数据利用率低(这里衍生出后面交叉验证的用法!)
-
实现步骤(对于二分类问题):
- 划分数据集(训练集、验证集、测试集)
- 构造第一层模型,选择多种分类器(SVM、LR、KNN、RF…)
- 对训练集进行训练,调整超参数,输出验证集的预测和测试集的预测
- 构造第二层模型,选择单种分类器
- 对验证集的预测进行训练模型,对上面测试集的预测再进一步预测
- 模型评价(交叉验证)
二、Stacking
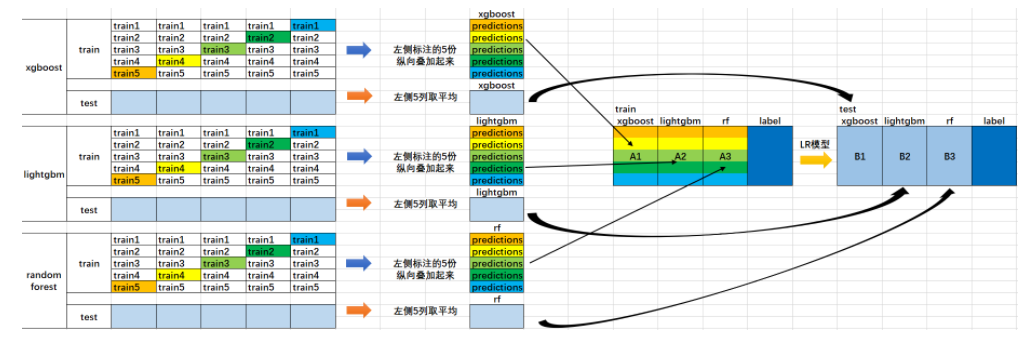
1. 集成方式
-
划分训练集 T T T和测试集 T e s t Test Test,这里是与Blending是类似的。
- 这里的训练集用于训练最优模型
- 测试集用于判断模型性能
-
训练集 T T T进一步划分训练集 T r a i n Train Train和验证集 V a l Val Val,与Blending的区别在于这里采用了交叉验证的方式训练模型
- 这里的训练集是训练给定的超参数下的模型
- 验证集是用于调参模型的超参数以达到最优模型
- 假设是类似5折交叉验证,那么原训练集 T T T会被随机分成五份,每一轮中都有一份是作为验证集
-
创建第一层的 K K K个模型,使用 T r a i n Train Train进行 K K K个模型训练,对 V a l t r u e Val_{true} Valtrue和 T e s t t r u e Test_{true} Testtrue进行预测
-
对于第 k k k个模型,由于假设采用5折交叉验证来划分原训练集 T T T,单个模型会训练5次,因此可以得到与 T T T长度(样本量)一致的模型预测 V a l p r e d − k Val_{pred-k} Valpred−k;同时单个模型训练5次也会得到5组测试集的预测值,这里的一般思路是对测试集的预测值进行平均,从而得到 T e s t p r e d − k Test_{pred-k} Testpred−k
-
K K K个模型显然会生成两组预测数值矩阵:
V a l p r e d = ( V a l p r e d − 1 , . . . , V a l p r e d − K ) T e s t p r e d = ( T e s t p r e d − 1 , . . . , T e s t p r e d − K ) Val_{pred} = (Val_{pred-1}, ..., Val_{pred-K}) \\ Test_{pred} = (Test_{pred-1}, ..., Test_{pred-K}) Valpred=(Valpred−1,...,Valpred−K)Testpred=(Testpred−1,...,Testpred−K)
-
-
创建第二层的单个模型,使用 V a l p r e d Val_{pred} Valpred进行训练,对 T e s t p r e d Test_{pred} Testpred进行预测
- 将多种模型的预测结果作为特征进行训练
-
第二层的预测结果作为整个测试集的结果
2. 特性
- Stacking是一种模型集成的策略和思想,充分利用数据集和集合多个模型的优点。
- 实现难度大,训练速度慢。
- 实现工具:
mlxtend
3. Blending与Stacking的关系
- Blending可以看成是简化版的Stacking,Stacking可以看作是Blending的推广或改进。
- Blending简单且易实现,但容易过拟合;Stacking精度高且结果稳健,但训练速度慢。
三、Blending和Stacking的实现(待补充)
Blending的实现
- 使用鸢尾花数据集
Iris,将LR、KNN、SVM和RandomForest四个模型进行融合。 - 注意:这里划分数据集时采用的是先划分训练集和测试集,再从测试集中划分验证集和测试集。
"""
Blending Model for Iris
"""
# 导入包
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
# 随机种子
ran = 2021
np.random.seed(ran)
# 加载数据集
data = load_iris()
data.keys()
# 提取数据
x = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.DataFrame(data.target, columns=['target'])
data_set = pd.concat([x, y], axis=1)
print(data_set.shape) # 150个样本,4个特征
# 分割数据(训练集和测试集)
x_train, x_test, y_train, y_test = train_test_split(x[:100], y[:100],
test_size=0.4, random_state=ran, shuffle=True)
# 分割数据(测试集和验证集)
x_test, x_valid, y_test, y_valid = train_test_split(x_test, y_test, test_size=0.5,
random_state=ran, shuffle=True)
# 构造第一层分类器
def class_one(models, train_x, train_y, val_x, test_x):
val_pred_list = np.zeros((val_x.shape[0], len(models)))
test_pred_list = np.zeros((test_x.shape[0], len(models)))
for i, clf in enumerate(models):
clf.fit(train_x, train_y.values.reshape(-1, ))
val_pred = clf.predict_proba(val_x)[:, 0] # 记录label为1的概率
test_pred = clf.predict_proba(test_x)[:, 0]
val_pred_list[:, i] = val_pred
test_pred_list[:, i] = test_pred
return val_pred_list, test_pred_list
# 构建第二层分类器
def class_two(model, val_pred, val_true, test_pred, test_true, cv):
model.fit(val_pred, val_true.values.reshape(-1, ))
cv_res = cross_val_score(model, test_pred, test_true, cv=cv)
return cv_res
# 训练模型
md1 = [LogisticRegression(),
KNeighborsClassifier(n_neighbors=1),
SVC(probability=True),
RandomForestClassifier(n_estimators=10, n_jobs=-1, criterion='gini', random_state=ran)]
pred_val, pred_test = class_one(md1, x_train, y_train, x_valid, x_test)
md2 = LinearRegression()
res = class_two(md2, pred_val, y_valid, pred_test, y_test, cv=5)
print(res)















 4651
4651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









