







字母异位词C语言暴力解法思路
一、解题思路与步骤
本题的解题思路:首先将strs字符串中的每个字符的ASCII码提取出来,对每个码进行从小到大的排序,再将排序后的ASCII码重新转换成对应的字符组成字符串,保存在新的字符串数组strs1中(大小与strs一样),然后两两比较strs1中的字符串strs1[i]、strs1[j],若strs1[i]==strs1[j],则将原字符串数组strs中的strs[i]、strs[j]存入返回的三维字符数组stsr2中.
1、定义一个与传入数组strs大小一样的二维字符数组strs1,传入数组str的行数为strsSize,列数为cols;
2、定义qsort函数的排序顺序为从小到大(compare函数);
3、循环取出传入字符串数组strs的每一个字符串(实际是该二维数strs的一行);
①创建一个与大小为cols-1的整数数组c,用来存储字符串中每个字符的ASCII码(例如:c[j]=(int)strs[i][j]);
②数组c获得第i行字符串的每一个字符的ASCII码后,用qsort函数对数组c进行排序;
③对于排序后的字符数组c,将其里面的每一个元素值即ASCII码,重新转成对应字符,存进数组strs1中(strs1[i][n]=c[n]);
例如,字符数组为“eat",那么c[3]=[101,97,116],排序后c[3]=[97,101,116],重新转成字符再平常字符串为"aet";
经过 (3)后,strs1中存的是strs中每个字符经过排序后的字符串:
strs[6][4]=[“eat”, “tea”, “tan”, “ate”, “nat”, “bat”] 👉 strs1[6][4]=[“aet”, “aet”, “ant”, “aet”, “ant”, “abt”]
4、先创建一个三维数组,其大小是strsSize个strsSize*cols的二维矩阵,后面若空间有多,再用realloc函数重新调整大小;
①创建一个used数组,大小是strsSize个整数大小,用来标识strs1中的元素是否已经被访问过, groupcount记录字母异 位词的组数;
②创建一个groupsize数组,用来辅助记录每类字母异位词的数量,大小是strsSize;
③创建一个used数组,用来标识strs1中的元素是否已经被访问过;
④每次循环前,先将取得的第一个字符串存进strs2[groupcount][0]中,然后使用字符串比较函数strcpy()比较strs1中的 strs1[t]和strs1[t+1]是否相等,若相等,则将原字符数组strs中的strs[t+1]存进strs2[grouncount][groupsize[groupcount]] 中,完成一次查找,重复循环,直至全部字母异位词均被查过;
⑤完成一组的查找后,根据字母异位词的组数以及每组字母异位词的个数,用realloc函数将三维数组中的未使用的二维 数组空间以及某个二维数组的剩下行的空间释放掉,避免浪费空间;
5、最后将调整后的三维数组strs2以及统计到的字母异位词的组数groupcount返回,并且释放groupsize、used的空间.
具体的代码思路流程图如下:

二、具体知识点
(1)多维数组的初始化、怎么理解数组名与指针的关系以及多级指针的使用;
(2)malloc、calloc、realloc三种内存分配函数的使用与区别;
(3)变量的作用范围、申请堆区与栈区的内存,其生命周期的区别;
(4)数组名作为函数的参数、字符串函数strcpy与strcmp函数的使用、strcpy与strncpy的区别(详细看此链接);
(5)continue与break的区别.
三、需要注意的地方
(1)函数的参数是数组名时,不能在函数内部使用sizeof(数组名)来计算数组的长度,因为此时数组名退化为一个指针函数只会将其当作是一个指针,那么指针的大小在64位系统中大小是8个字节,但在main函数中,sizeof(数组名)是会计算整个数组所占内存空间的大小,此时在sizeof中,数组名并不表示数组首元素的地址,而表示整个数组。这就是数组名不表示数组首元素地址的例外情况;
(2)如何来动态调整返回三维数组的大小,以避免空间浪费;
(3)提取字符串每个字符的ASCII码时,注意最后一个结束标志’\0’不要提取,否则排序后会出现错误;
(4)如何更新strs2的数组下标,使得找到的每一组字母异位词都能正确的存进去.
四、具体代码
//(1)定义整数数组的排序属顺序(从小到大)
int compare(const void *a, const void *b) {
return (*(int*)a - *(int*)b);
}
//(2)寻找字母异位词,并用三维字符数组返回
char*** groupAnagrams(int strsSize,int cols,char** strs,int* returnSize) //strsSize是二维数组的行数[strsSize][cols]
{
char strs1[strsSize][cols];
//先对字符串的每个字符进行排序,得到一个新的字符数组
for (int i = 0; i < strsSize; i++)
{
int c[cols-1]; //定义一个数组存储字符串的每个字符对应的ASCII码
for (int j = 0; j < cols-1; j++)
{
c[j] = (int) strs[i][j];
}
//对数组c中的ASCII码进行从小到大排序
qsort(c, cols-1, sizeof(int), compare);
//将数组C中的ASCII码转成对应的字符,再拼接成对应的字符串,存回strs1[i]这个位置
for (int n = 0; n <=cols-1; n++)
{
if(n==cols-1)
{
strs1[i][n]='\0';
}
else
{
strs1[i][n] = (char) c[n];
}
}
}
//上面已经完成:将字母的ASCII码排序后重新转成对应的字母,存到新的数组strs1中,
//先申请内存来存储找到的字母异位词,申请内存使用malloc函数,否则内存在函数调用结束后会自动销毁
char*** result=(char***)malloc(strsSize * sizeof(char**));
if(result==NULL)
{
printf("nei cun bu zu \n");
return NULL;
}
//记录三维数组中每个的大小
int* groupsize=(int*) calloc(strsSize,sizeof (int));
if(groupsize==NULL)
{
printf("groupsize nei cun bu zu \n");
free(result);
return NULL;
}
//记录字母异位词的数量
int groupcount=0;
//标记某字符串是否已经被分组
int* used=(int*)calloc(strsSize,sizeof (int ));
if(used==NULL)
{
printf("used nei cun bu zu \n");
free(result);
free(groupsize);
return NULL;
}
for(int t=0;t<strsSize;t++)
{
if(used[t])
{
continue;
}
result[groupcount]=(char **) malloc(strsSize*sizeof (char*));
if(result[groupcount]==NULL)
{
printf("result groupcount nei cun bu zu");
for (int k = 0; k < groupcount; k++)
{
free(result[k]);
}
free(result);
free(groupsize);
free(used);
return NULL;
}
result[groupcount][0]=(char *) malloc(cols*sizeof (char ));
strcpy(result[groupcount][0],strs[t]);
groupsize[groupcount]=1;
used[t]=1;
for(int m=t+1;m<strsSize;m++)
{
if(used[m])
{
continue;
}
if(!strcmp(strs1[t],strs1[m]))
{
result[groupcount][groupsize[groupcount]] = (char*)malloc(cols * sizeof(char));
strcpy(result[groupcount][groupsize[groupcount]], strs[m]);
groupsize[groupcount]++;
used[m] = 1;
}
}
result[groupcount][groupsize[groupcount]] = NULL;
//将三维数组中某个矩阵的剩下行的空间释放掉,避免浪费空间
result[groupcount] = (char**)realloc(result[groupcount], (groupsize[groupcount] + 1) * sizeof(char*));
/*for(int e=groupsize[groupcount]+1;e<strsSize;e++)
{
free(result[groupcount][e]);
}*/
groupcount++;
}
//调整结果数组的大小
result=(char***) realloc(result,groupcount*sizeof (char**));
// 更新返回的组数
*returnSize = groupcount;
// 释放不再需要的内存
free(groupsize);
free(used);
return result;
}
//(3)主函数
int main() {
int strsSize = 8;
int maxLen = 4;
char **strs = (char **) malloc(strsSize * sizeof(char *));
if (strs == NULL) {
printf("内存分配失败\n");
return 1;
}
for (int i = 0; i < strsSize; i++) {
strs[i] = (char *) malloc(maxLen * sizeof(char));
if (strs[i] == NULL) {
printf("内存分配失败\n");
// 释放已分配的内存
for (int j = 0; j < i; j++) {
free(strs[j]);
}
free(strs);
return 1;
}
}
// 初始化二维数组
char *words[] = {"eat", "tea", "tan", "ate", "nat", "bat", "tab","adc"};
for (int i = 0; i < strsSize; i++) {
strncpy(strs[i], words[i], maxLen);
}
int returnsize = 0;
char ***result = groupAnagrams(strsSize, maxLen, strs, &returnsize);
printf("%d\n", returnsize);
if(result)
{
for (int i = 0; i < returnsize; i++) {
printf("Group %d:\n", i + 1);
for (int j = 0; result[i][j] != NULL; j++) {
printf("%s ", result[i][j]);
free(result[i][j]);
}
printf("\n");
free(result[i]);
}
free(result);
}
return 0;
}
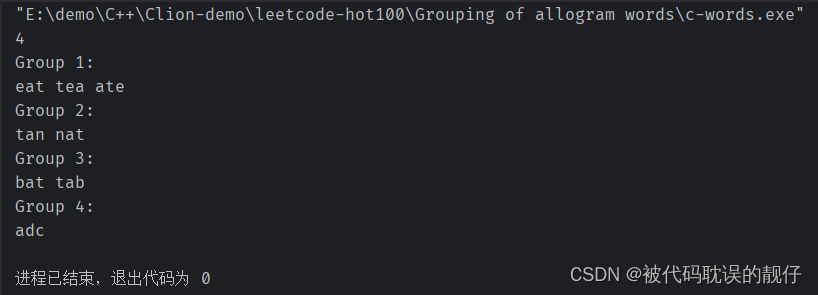
五、代码运行结果
4是找到了4组的字母异位词
六、总结
这个思路是比较容易理解的,但是代码读起来会比较难懂,其中涉及到了C语言比较细碎的知识点,后面将会更新C++版本的非暴力解法(使用哈希表、vector的解法).















 6582
6582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









