







Motivation
最近尝试了一些代理模型的构建方法,其中有些成功了,有些失败了,借此机会,总结一下经验。
为什么要训练代理模型?
这个问题可以转化为:如果不训练代理模型怎么样?
我之前尝试过样本空间的离散点 X = { x 1 , x 2 , . . . , x n } X=\{x_1, x_2,..., x_n\} X={x1,x2,...,xn}对应的结果 Y = { y 1 , y 2 , . . . , y n } Y=\{y_1, y_2, ..., y_n\} Y={y1,y2,...,yn} 对应起来然后放到数据库当中,如果数据当中有足够的 { x : y } \{x:y\} {x:y}配对值之后,如果有新的点,直接取临近的点代替就可以,或者通过该点周围的点进行插值。这样做可以实现比较好的展示效果。链接: 如我上一篇文章所演示的。然而,这样做的其中一个弊端是:不好部署!
什么意思呢?举个例子,如果我的 x x x 才两个维度,每个维度计算100个值,那在二维空间当中便会有10000个值,也就是说,y的值也会有10000个。而像有限元结果,y的值往往会有应力、应变、位移,单元数轻轻松松就会上几十万。即便用了数据库,很快也会炸了。
代理模型便会为上述问题提供一个解决方案。 一般说利用数据来进行学习的代理模型,如SVM, RBF, DNN本质上都是一个拟合过程 Y = F ( X ) Y = F(X) Y=F(X), 代理模型便代表了 F ( ⋅ ) : X → Y F(\cdot):X\rightarrow Y F(⋅):X→Y这个映射关系。
代理模型如何训练?
最简单的视角就是按照数据拟合的角度去看待。为什么要着重强调这一点呢?因为当我对代理模型这个东西觉得神秘的时候,会觉得代理模型这个东西非常高大上,但后来觉得不过如此。
先简单介绍一下我的需求, 我需要做一个demo, 输入是两个力,输出是27000个节点的位移幅值(应力、应变等类似),我想要尝试用已经配对好的数据来训练一个代理模型自动学习其中的映射关系,让我能够摆脱繁重的数据库。
我主要尝试了三种方法:RBF, GAN, MLP, 由于时间的原因,RBF和GAN训练都失败了,而MLP效果还不错。
RBF是是径向基神经网络,也是目前代理模型最为常见的一种。我构建的模型代码如下:
class RBFN(nn.Module):
"""
以高斯核作为径向基函数
"""
def __init__(self, centers, n_out=21704):
"""
:param centers: shape=[center_num,data_dim]
:param n_out:
"""
super(RBFN, self).__init__()
self.n_out = n_out
self.num_centers = centers.size(0) #
self.dim_centure = centers.size(1) #
self.centers = nn.Parameter(centers) #训练中心点
self.beta = nn.Parameter(torch.ones(1, self.num_centers)* 10, requires_grad=True) #训练方差
# 对线性层的输入节点数目进行了修改
self.linear = nn.Linear(self.num_centers, self.n_out, bias=True)
self.initialize_weights() # 创建对象时自动执行
def kernel_fun(self, batches): #高斯核操作
n_input = batches.size(0) # number of inputs
A = self.centers.view(self.num_centers, -1).repeat(n_input, 1, 1)
B = batches.view(n_input, -1).unsqueeze(1).repeat(1, self.num_centers, 1)
C = torch.exp(-self.beta.mul((A - B).pow(2).sum(2, keepdim=False)))
return C
def forward(self, batches):
radial_val = self.kernel_fun(batches)
class_score = self.linear(radial_val)
return class_score
def initialize_weights(self, ):
"""
网络权重初始化
:return:
"""
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.ConvTranspose2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
def print_network(self):
num_params = 0
for param in self.parameters():
num_params += param.numel()
print(self)
print('Total number of parameters: %d' % num_params)
因为我想即时看到训练效果,相比于将其导入到Unity去看云图的渲染效果,我直接用时域和频域展示原数据和代理模型生成的结果。
原数据将其展开成时域和频域的结果如下:
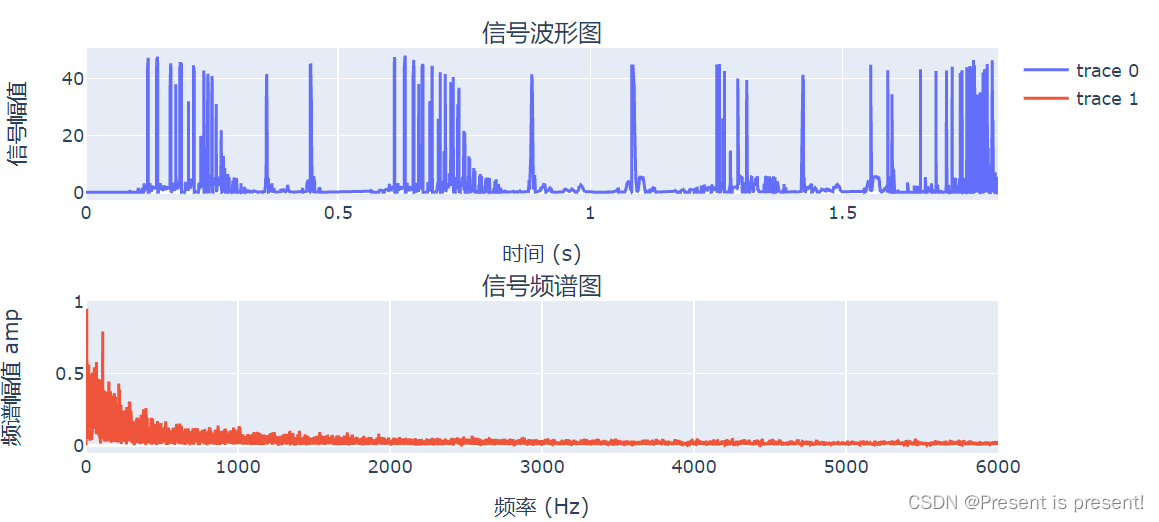
1、RBF最后训练的输出倒是和这个差不多,但是它好像只学习到了这一种情况:
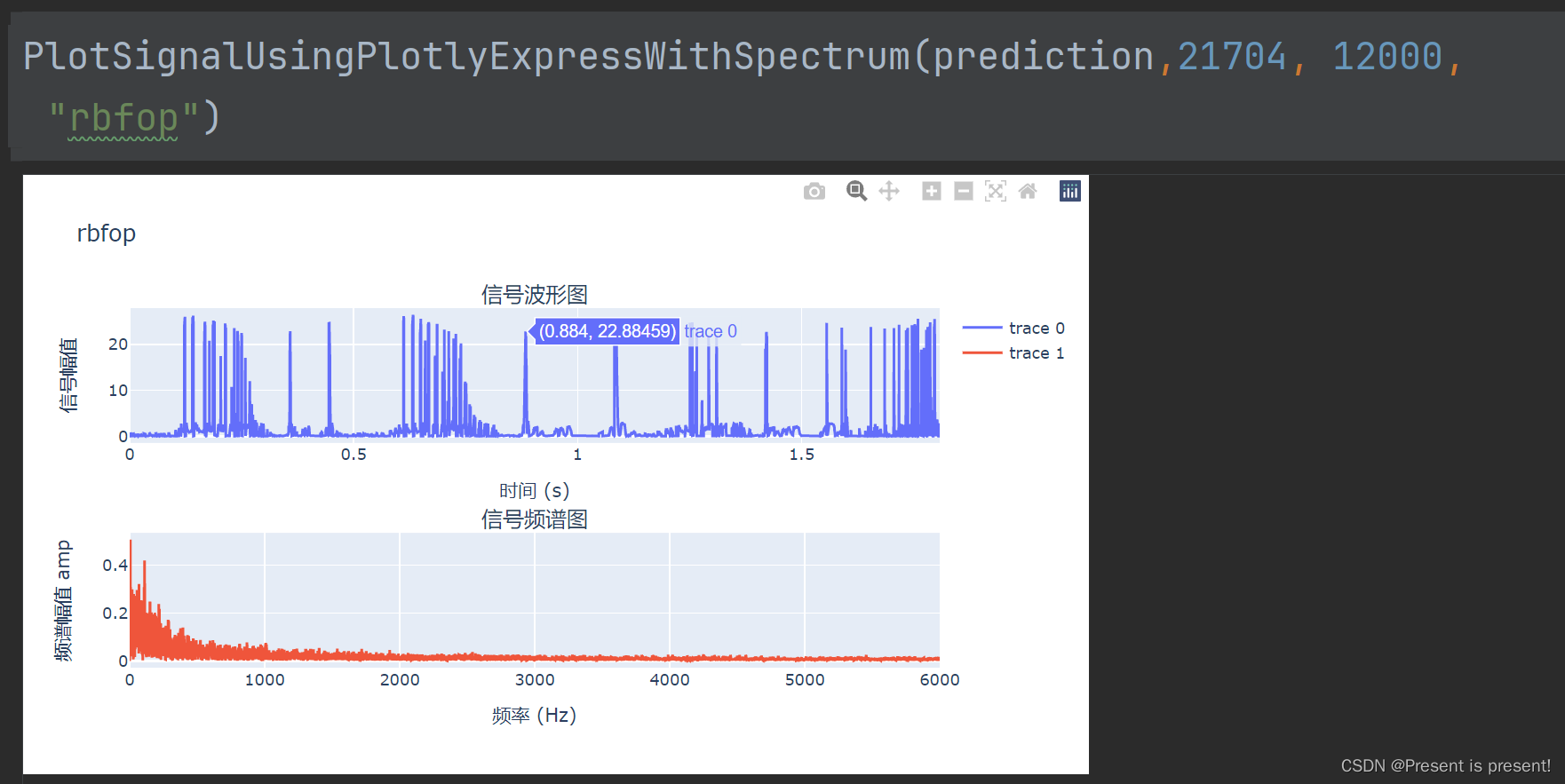
导入到Unity当中的效果和实测数据差不多,但是没有明显的颜色的变化。

2、GAN太难训练了,GAN的Genenrator还没学习到这种情况就收敛了。

导入到Unity当中的效果是这样的:
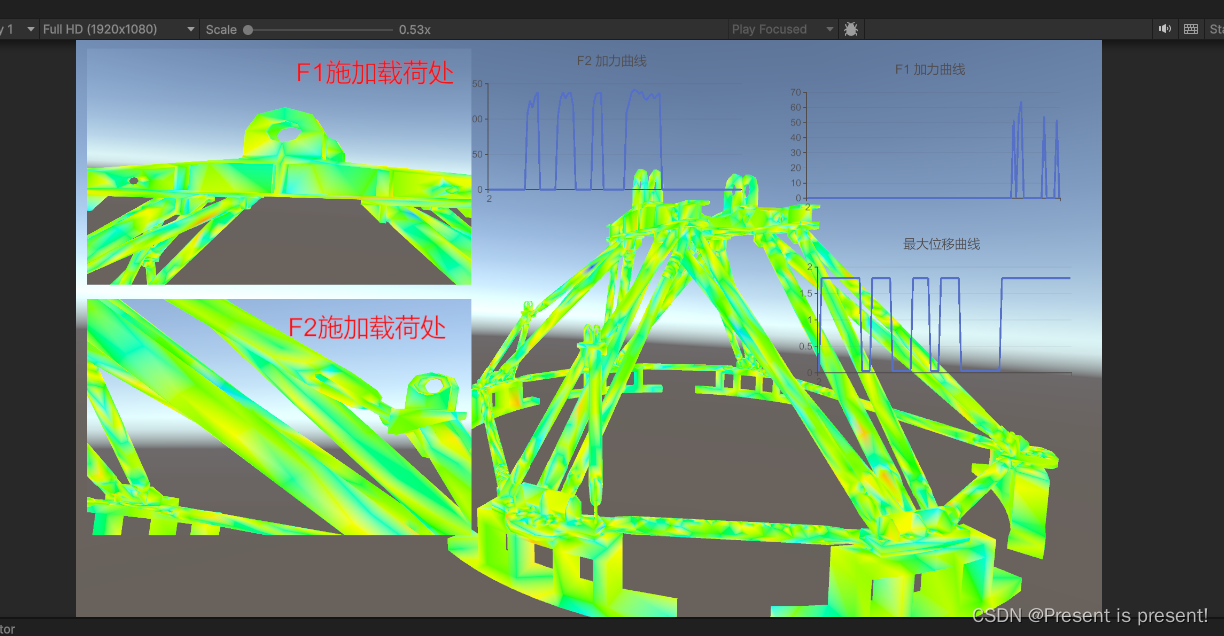
3、用MLP则是出乎意料得训练成功了。模型特别简单:
# 神经网络结构
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layer1 = nn.Linear(2, 128)
self.layer2 = nn.Linear(128, 21704)
def forward(self, x):
x = torch.relu(self.layer1(x))
x = self.layer2(x)
return x
导入到Unity当中的效果和用实测数据差不多,效果很好。视频演示放B站了。


















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









