







Conditional BERT Contextual Augmentation
直观来看,MLM 是一种非常好的“基于上下文”的数据增强方式(后面的实验结果也证明,直接使用Bert也可以取得较好的效果。), 但是在分类任务中,人工合成的数据不应丧失“标签信息”。比如原文“The movie is good.”,good 一词被 Mask, 而预测为 bad, 则改变了标签的信息。因此在预测替换词时,不仅需要考虑上下文信息,还应该考虑标签信息, 据此本文提出了Conditional Bert。
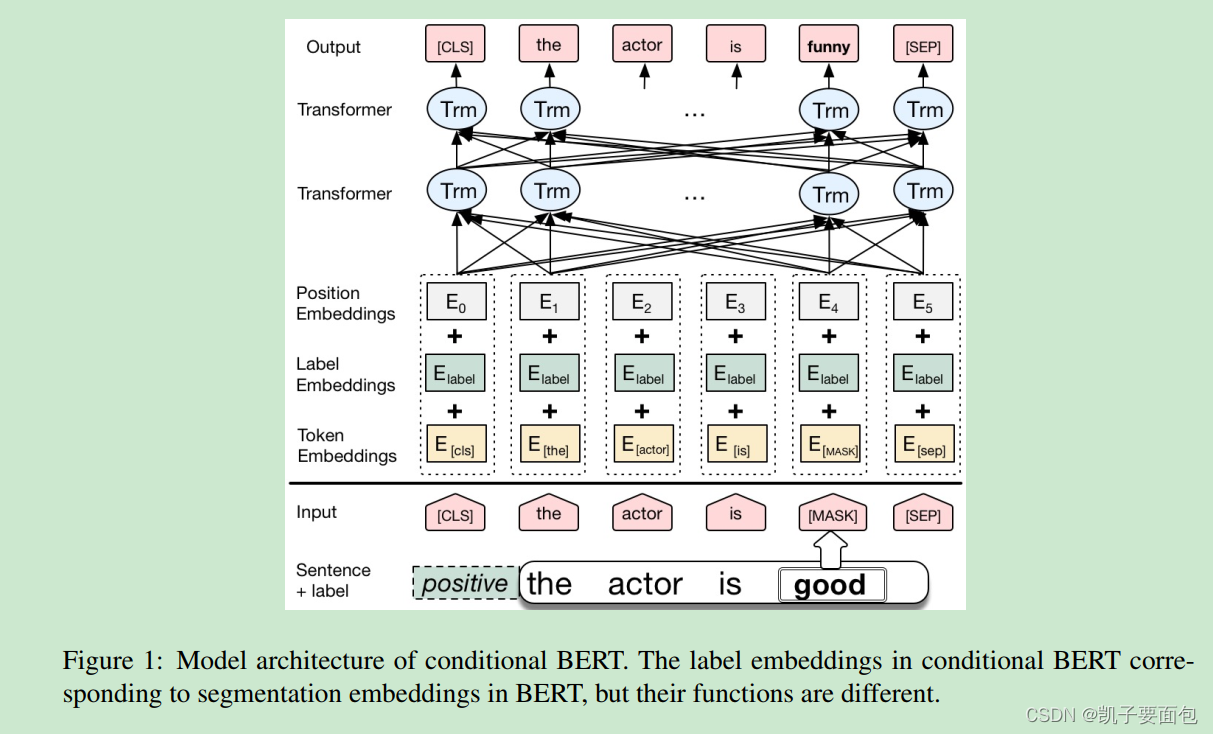
Conditional Bert
CBert 的模型结构与 Bert 完全一致,区别仅在于“输入的表征” 与 “训练过程”。在CBert 中, 标签信息是通过 Segmentation Embedding 表示的,Bert 原文中Segmentation Embedding 只有两个值,在 CBert 中需调整为 num_classes。通过该种方式,将标签信息融入到 MLM 任务中,实现了在预测替换词时,不仅考虑上下文,还考虑了标签信息,这就是论文中命名的 Conditional MLM。
训练过程方面与 Bert 也十分相似,只是 CBert 在“标注的训练语料”上 Fine-Tune 时,采用的是 CMLM 任务, 而不是 MLM任务。
最后一步就是对训练数据进行增强,将 Fine-Tune 后的 CBert 在训练语料上进行 Conditional MLM 任务,注意在预测替换词时,不应该选取概率最大对应的词,而应该在TopN范围(或其它有效方式)内随机选择一个替换词,以提高数据分布的多样性。
实验结果
有两个超参数需要记录下,Fine-Tune Cbert 的epoch 属于 [1, 50], 遮掩词的数量不是15%, 而是[1, 2]。遮掩词的数量是不是太小了?
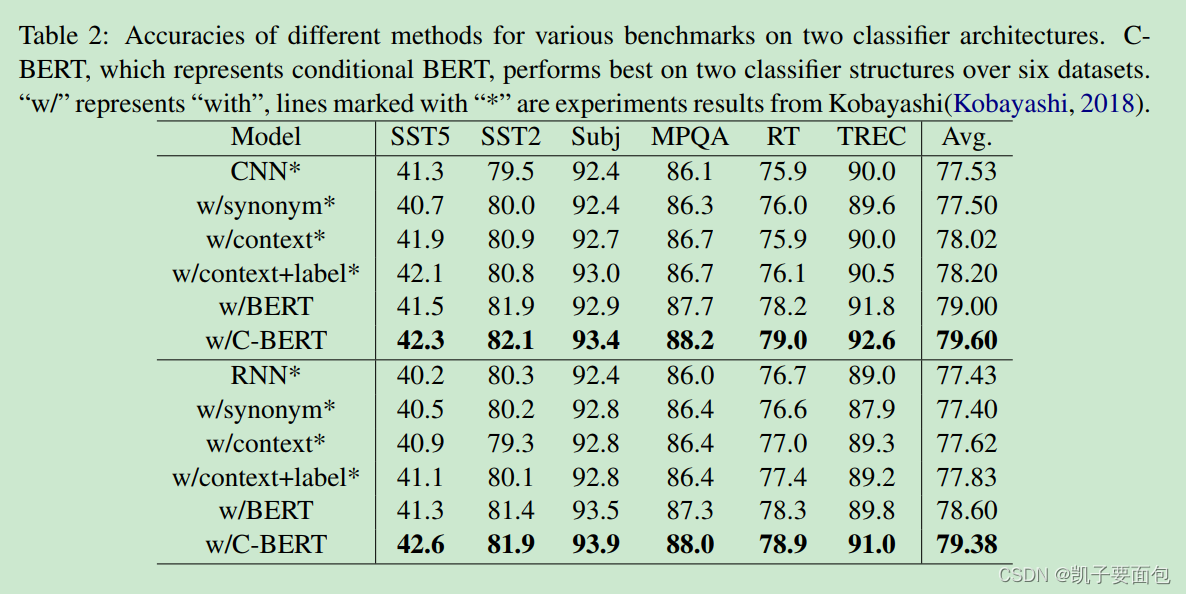
从结果来看,CBert 比 Bert 在6个数据集上,大致提升了 0.6 个百分点。

在 SST5 中, CBert 需要 Fine-Tune 5个 epoch,效果才优于 Bert。在其它数据集中epoch的数值较小,特别是那种本来就只有两种标签的数据集,是否可以推断,类别数量越大, 需要 Fine-Tune的时间就越长,因为需要重新调整 segementation embedding layer 的参数?

















 2178
2178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









