







基于深度神经网络的猫狗图像分类
一、实验目的
1.掌握卷积神经网络、循环神经网络等深度学习的各项基本技术。
2.加强对pytorch、tensorflow等深度学习框架的使用能力。
二、实验要求
1.任选一个深度学习框架,实现在给定数据集上的基于DNN、CNN、RNN的图片分类模型。
2.测评指标采用各个类别的准确率。
三、实验内容
1.数据读取
train中有2000张cat和dog的训练图片,val中有500张待测试图片

- 构造函数里迭代读取img的目录和label
- 对__getitem__重载,用transform转换关系返回img和label的pytorch类型(tensor)
- __len__返回数据集大小
#数据预处理
datatransform=transforms.Compose([
transforms.Resize((200,200)),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
]
)
class Datasets(data.Dataset):
def __init__(self,dir,full_dir):
self.dir=dir
self.img_list=[]
self.label_list=[]
self.datasize=0
self.transform=datatransform
if self.dir == 'train':
full_dir+='/train/'
elif self.dir == 'val':
full_dir+='/val/'
else:
print('Unknown dir!')
for file in os.listdir(full_dir):
self.img_list.append(full_dir+file)
self.datasize+=1
cls=file.split('.')
if cls[0]=='cat':
self.label_list.append(0)
else:
self.label_list.append(1)
def __getitem__(self,item):
if self.dir=='train':
img=Image.open(self.img_list[item])
label=self.label_list[item]
return self.transform(img),torch.LongTensor([label])
else:
img=Image.open(self.img_list[item])
return self.transform(img)
def __len__(self):
return self.datasize
2.CNN部分
这部分我用了两个网络结构,第一个是我自己设计的,第二个是用Resnet50。
①MyNet
I 结构
CNN部分我用了两个网络,先用自己设计的结构,3层卷积、3层池化、三层全连接,下图为结构图。
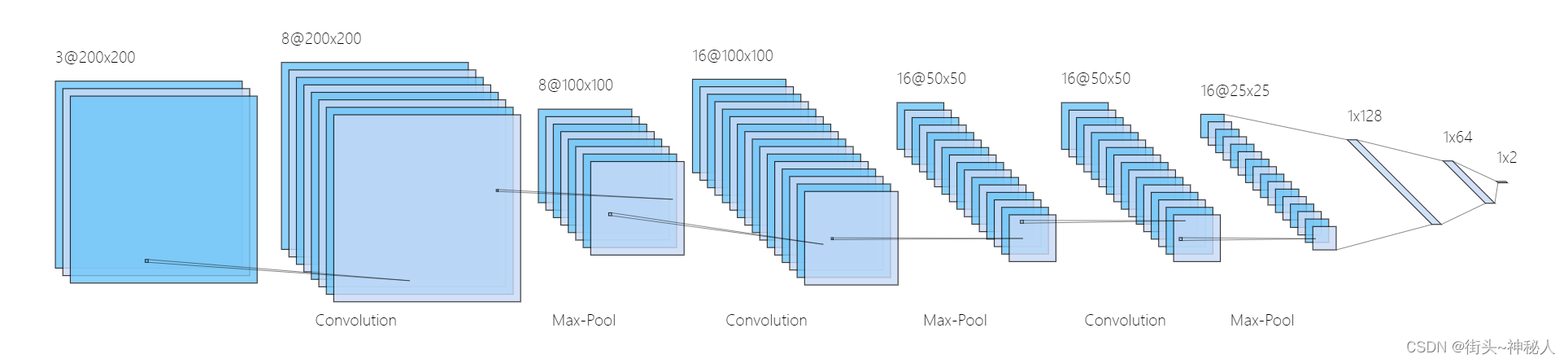
class MyNet(nn.Module):
def __init__(self):
super(MyNet,self).__init__()
self.conv1=nn.Conv2d(in_channels=3,out_channels=8,kernel_size=3,padding=1)
self.conv2=nn.Conv2d(in_channels=8,out_channels=16,kernel_size=3,padding=1)
self.conv3=nn.Conv2d(in_channels=16,out_channels=16,kernel_size=3,padding=1)
self.fc1=nn.Linear(25*25*16,128)
self.fc2=nn.Linear(128,64)
self.fc3=nn.Linear(64,2)
def forward(self,x):
x=self.conv1(x)
x=F.relu(x)
x=F.max_pool2d(x,2)
x=self.conv2(x)
x=F.relu(x)
x=F.max_pool2d(x,2)
x=self.conv3(x)
x=F.relu(x)
x=F.max_pool2d(x,2)
x = x.view(x.size(0), -1)
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
|| 训练
- 设置超参数
- 通过Datasets和DataLoader读取数据
- 实例化网络
- 训练时存储best_loss时的pth
- 使用plt和tensorboard记录训练数据和画曲线
#设置超参数
batch_size=16
epochs=10
device=torch.device('cuda')
lr=0.0001
def train():
#读取数据
dataset=Datasets('train','../../Data')
dataloader=DataLoader(dataset=dataset,batch_size=batch_size,shuffle=True)
print('Loaded dataset! The length of train_set is {0}'.format(len(dataset)))
#实例化网络
CNN_Model=MyNet()
CNN_Model.train()
# model=MyNet()
# tw.draw_model(model,[1,3,200,200])
#优化器
opt=torch.optim.Adam(CNN_Model.parameters(),lr=lr)
#交叉熵损失函数
loss_func=torch.nn.CrossEntropyLoss()
CNN_Model.cuda()
#训练
best_loss=1
loss_list=[]
for epoch in range(1,epochs+1):
sum_loss = 0
for batch_idx,(img,label) in enumerate(dataloader):
img,label =Variable(img).cuda(),Variable(label).cuda()
output=CNN_Model(img)
loss=loss_func(output,label.squeeze())
# loss_s.append(loss.data.cpu())
opt.zero_grad()
loss.backward()
opt.step()
sum_loss+=loss.item()
if (batch_idx+1) % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)] \tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(img), len(dataloader.dataset),
100. * (batch_idx + 1) / len(dataloader), loss.item()))
ave_loss = sum_loss / len(dataloader)
writer.add_scalar("loss", ave_loss, epoch)
if ave_loss<best_loss:
best_loss=ave_loss
torch.save(CNN_Model,'pth_dir/best.pth')
torch.save(CNN_Model,'pth_dir/last.pth')
loss_list.append(ave_loss)
print('epoch:{},loss:{}'.format(epoch, ave_loss))
plt.figure('CNN_loss')
plt.plot(range(epochs),loss_list,label='loss')
plt.legend()
plt.show()
||| 测试
- 使用best_loss下的pth进行预测
- 由于测评指标采用各个类别的准确率,所以我分别计算cat和dog的Acc数量和准确率,也计算了总的Acc。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def val():
acc=0
count=0
Acc_cat=0
Acc_dog=0
CNN_Model=torch.load('pth_dir/best.pth')
CNN_Model.eval()
CNN_Model.to(device)
dataset=Datasets('val','../../Data')
print('Loaded dataset! The length of val_set is {0}'.format(len(dataset)))
for index in range(dataset.datasize):
print(index+1)
img=dataset.__getitem__(index)
img.unsqueeze_(0)
img=Variable(img).to(device)
label=dataset.label_list[index]
output=CNN_Model(img)
output=F.softmax(output,dim=1)
print(output)
if (output[0, 0] > output[0, 1] and label == 0 ):
Acc_cat=Acc_cat+1
count = count+1
elif (output[0, 0] <= output[0, 1] and label==1):
Acc_dog=Acc_dog+1
count = count+1
acc = count/dataset.datasize
print('Acc_cat:{} {}% | Acc_dog:{} {}%'.format(Acc_cat,100*Acc_cat/250,Acc_dog,100*Acc_dog/250))
print('Acc_Pic:{} | Acc Pic_Count:{}'.format(count,dataset.datasize))
print('Acc:{}%'.format(100*acc))
训练
10epoch
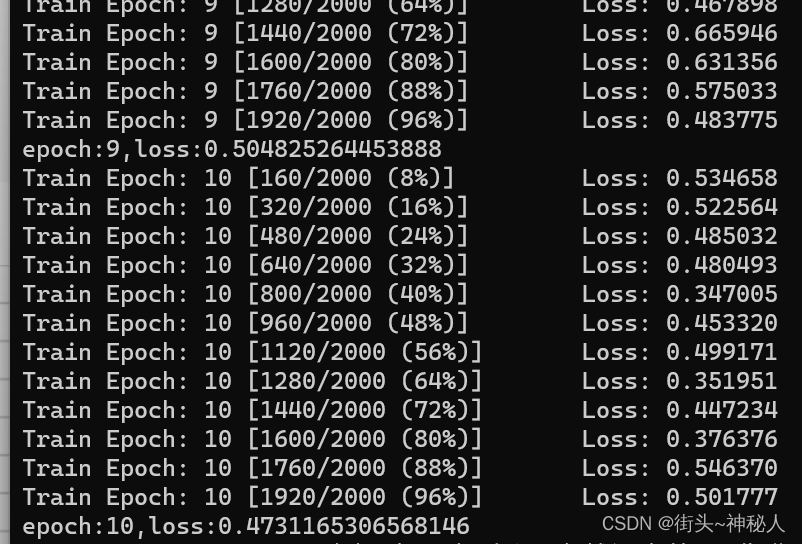
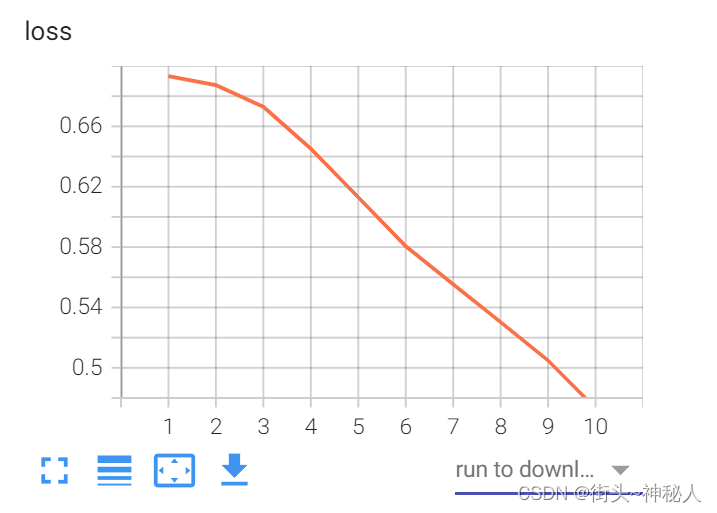
通过下面命令查看tensorboard的loss曲线
tensorboard --logdir=tensorboard_dir
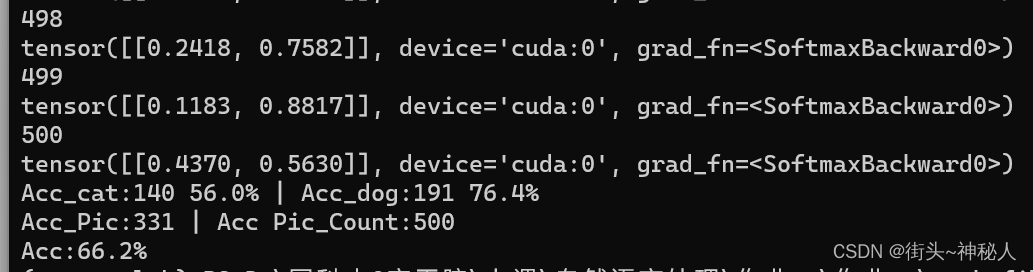
测试
10epoch的分类准确率:cat为56%,dog为76.4%;总的准确率为66.2%。
30epoch的loss曲线
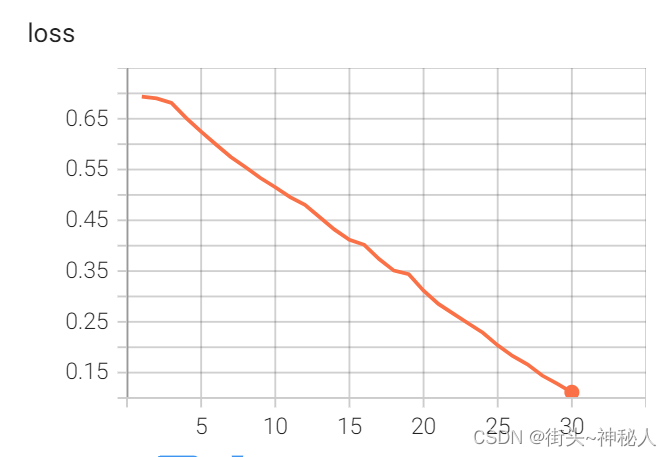
30epoch的分类准确率:cat为54%,dog为73.6%;总的准确率为63.8%,不升反降。说明了虽然loss在下降,但是已经过拟合了。

②Resnet50
使用pytorch的Resnet50,并且使用预训练权重
#实例化网络
CNN_Model=torchvision.models.resnet50(pretrained=True)
num_ftrs = CNN_Model.fc.in_features
CNN_Model.fc = nn.Linear(num_ftrs, 2)
I 训练
10epoch的loss
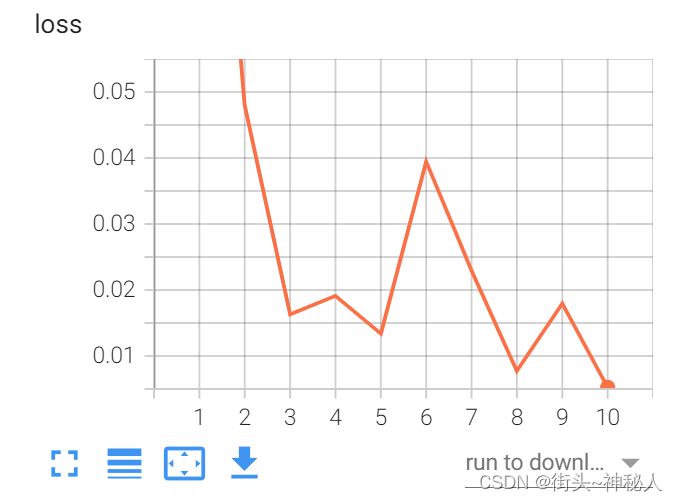
用Resnet50训练10epoch能达到很高的准确率
分类准确率:cat为99.2%,dog为97.6%;总的准确率为98.4%。

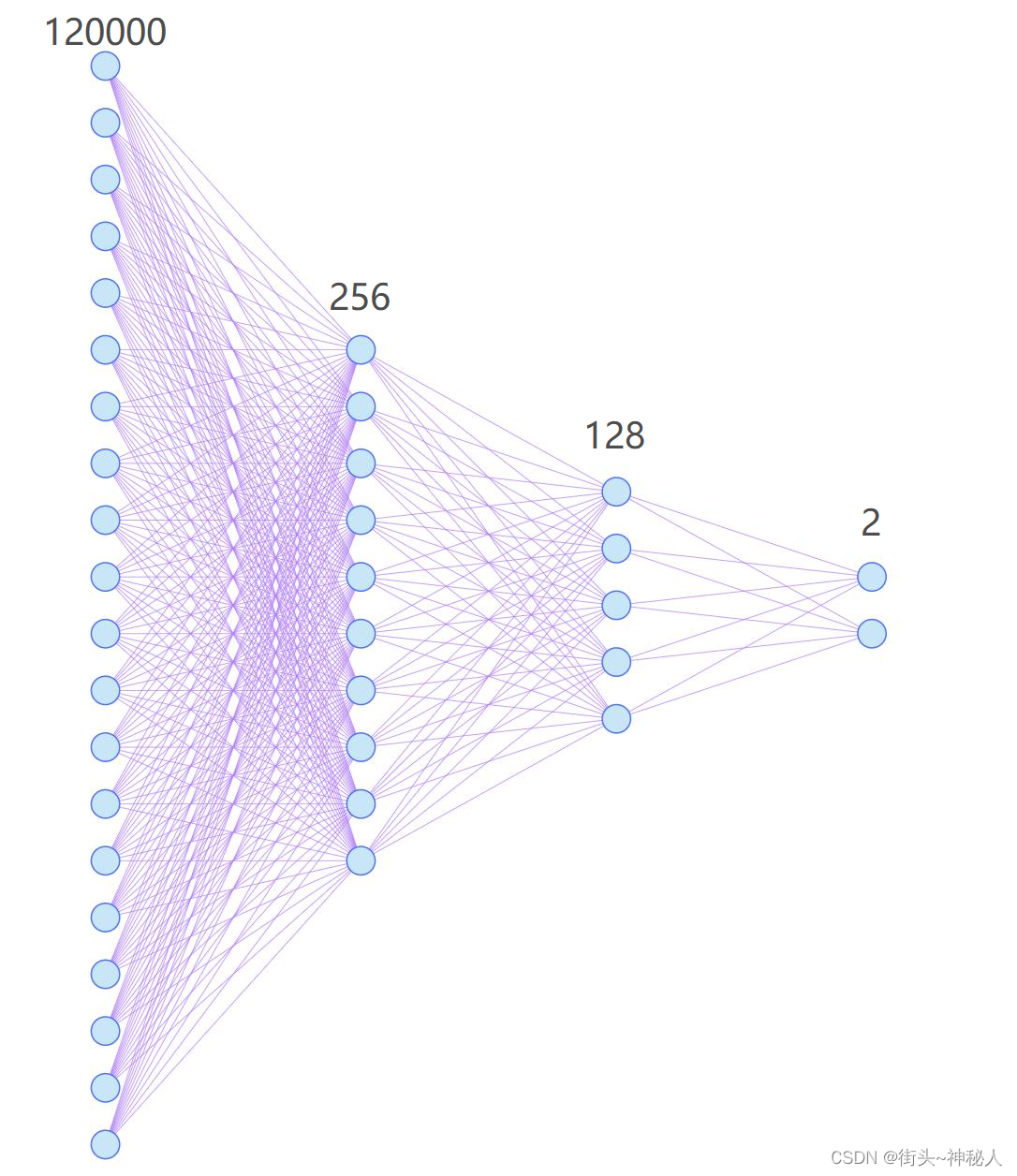
3.DNN部分
结构
三层全连接
self.layers=nn.Sequential(
nn.Linear(200*200*3,256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,2),
nn.Softmax(dim=1),
)
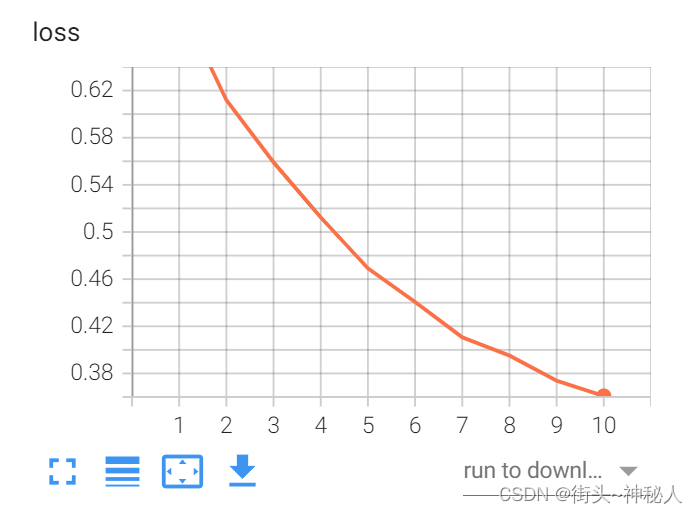
训练
DNN训练10epoch
测试
DNN的分类准确率不佳
cat为62.0%,dog为56.8%;总的准确率为59.4%。

4.RNN部分
结构
self.RNN=nn.LSTM(
input_size=120000, #200*200*3
hidden_size=100, #隐藏层神经元数
num_layers=1,
batch_first=True,
)
self.out=nn.Linear(100,2)
训练
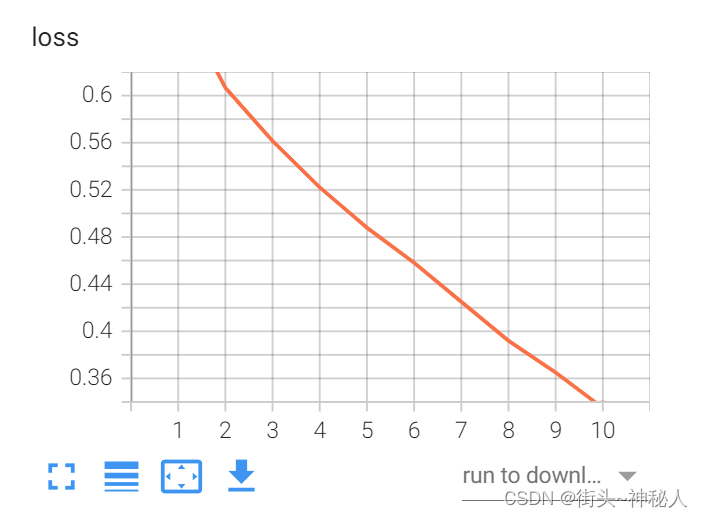
测试
cat为58.0%,dog为58.8%;总的准确率为58.4%。

总结和思考
1.从我的实验结果上来看,处理图像分类问题的最好结构是CNN结构,其次是DNN,最后是RNN
2.好的CNN网络能够对分类结果起到质的提升,比如我用Resnet50进行训练,在同样的epoch下其能达到98.4%的准确率

















 5490
5490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









