






GCN图卷积神经网络
顾名思义,图卷积神经网络,是对图信息进行卷积,从而获取相邻节点的信息和特征,本文将介绍和推导目前较为流行的以chebyshev ploynomials 契比雪夫多项式为核的图卷积公式,同时通过pytorch代码实现。
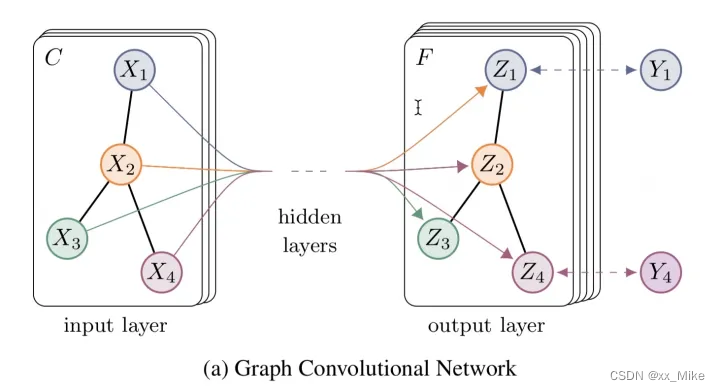
图卷积的定义
通过表示图信息的矩阵及上一层特征输入,输出该层对图信息的特征,表示如下:
H
l
=
f
(
H
l
−
1
,
A
)
H_l = f(H_{l-1},A)
Hl=f(Hl−1,A)
A代表邻接矩阵,或关于图表示的矩阵。
常用数学传播表示方式如下:
H
l
=
σ
(
D
~
−
1
2
A
~
D
~
−
1
2
H
l
−
1
W
l
−
1
)
H_l=\sigma(\widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H_{l-1}W_{l-1})
Hl=σ(D
−21A
D
−21Hl−1Wl−1)
其中 D ~ \widetilde{D} D 代表 A ~ \widetilde{A} A 的度矩阵
A ~ \widetilde{A} A 代表邻接矩阵 A A A与单位矩阵 I I I的和: A ~ = A + I \widetilde{A}=A+I A =A+I
H H H代表卷积后的特征,初始输入 H = X H=X H=X
σ \sigma σ为激活函数
推导
-
图的表示方式:
1)邻接矩阵 A A A,表示节点与节点之间是否存在连接,若存在则为1,不存在为0,对角线均为0
2)度矩阵 D D D ,只有对角线有值,表示该节点所连接边的个数
3) Laplacian 拉普拉斯矩阵: L = D − A L=D-A L=D−A 1)对称 2)非负特征值 3)正交
归一化Laplacian: L s y m = D − 1 2 L D − 1 2 = I − D − 1 2 A D − 1 2 L^{sym}=D^{-\frac{1}{2}}LD^{-\frac{1}{2}}=I-D^{-\frac{1}{2}}AD^{-\frac{1}{2}} Lsym=D−21LD−21=I−D−21AD−21
-
卷积公式:其中 F ( X ) F(X) F(X)表示傅里叶变换
f ∗ g = F − 1 ( F ( f ) ∗ F ( g ) ) f*g=F^{-1}(F(f)*F(g)) f∗g=F−1(F(f)∗F(g))
-
根据拉普拉斯矩阵正交特性,存在 U , U T U,U^T U,UT使得 L = U Λ U T L=U\Lambda U^T L=UΛUT 其中 Λ \Lambda Λ表示特征向量
则Graph Fourier可对应表示如下:
G F ( x ) = U T x GF(x)=U^Tx GF(x)=UTx
根据卷积公式,对应图卷积公式如下:
g ∗ x = U ( U T g U T x ) g*x=U(U^TgU^Tx) g∗x=U(UTgUTx)
每一次卷积操作作用域都希望在中心节点附近的区域,则我们可以将 g g g看作关于拉普拉斯矩阵 L L L的函数 g ( L ) g(L) g(L),那么,每卷积一次则相当于传递一次相邻节点信息
而由 L L L特征值特性: U T L = Λ U T U^TL=\Lambda U^T UTL=ΛUT 可知, U T g ( L ) U^Tg(L) UTg(L) 可看作是关于拉普拉斯矩阵 L L L的特征函数 g θ ( Λ ) g_\theta(\Lambda) gθ(Λ)
则图卷积表达式可写作:
g ∗ x = U ( U T g U T x ) = U g θ U T x g*x=U(U^TgU^Tx)=Ug_\theta U^Tx g∗x=U(UTgUTx)=UgθUTx
-
运算简化
由于计算 g θ g_\theta gθ需要计算拉普拉斯矩阵特征值,计算复杂,因而提出利用切比雪夫Chebyshev polynomials多项式来进行近似计算,这里并不影响特征值的计算属性,只是通过切比雪夫多项式作为核能够将特征值矩阵计算化简为L,从而跳过特征值计算的步骤,表示如下。
g θ = ∑ k = 0 K θ k T k ( Λ ~ ) g_\theta=\sum_{k=0}^{K}\theta_k T_k(\widetilde{\Lambda}) gθ=∑k=0KθkTk(Λ )
其中 Λ ~ = 2 ∗ Λ Λ m a x − 1 \widetilde{\Lambda}=2*\frac{\Lambda}{\Lambda_{max}}-1 Λ =2∗ΛmaxΛ−1,只是因为Chebyshev polynomials要求 x x x处于 [ − 1 , 1 ] [-1,1] [−1,1]
T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) T_k(x)=2xT_{k-1}(x)-T_{k-2}(x) Tk(x)=2xTk−1(x)−Tk−2(x), T 0 = 0 T_0=0 T0=0, T 1 = 1 T_1=1 T1=1
那么将上式代入卷积表达式可以得到:
g ∗ x = U ∑ k = 0 K θ k T k ( Λ ~ ) U T x = ∑ k = 0 K θ K T k ( L ~ ) x g*x=U\sum_{k=0}^{K}\theta_k T_k(\widetilde{\Lambda})U^Tx\\=\sum_{k=0}^K\theta_K T_k(\widetilde{L})x g∗x=Uk=0∑KθkTk(Λ )UTx=k=0∑KθKTk(L )x
pytorch代码实现
包需求:
import numpy as np
import torch
import torch.nn as nn
1.Laplacian 以及scaled_Laplacian:
'''D matrix 根据邻接矩阵获取度矩阵'''
def get_d_matrix(adj_matrix):
d_matrix = np.zeros((adj_matrix.shape[0], adj_matrix.shape[1]))
for i in range(adj_matrix.shape[0]):
d_matrix[i, i] = np.sum(adj_matrix[i, :])
return d_matrix
'''Laplace matrix'''
def get_laplace_matrix(adj, d):
d_turn = np.zeros((adj.shape[0], adj.shape[0]))
for i in range(adj.shape[0]):
d_turn[i, i] = np.power(d[i, i], -0.5)
res = np.eye(adj.shape[0]) - d_turn @ adj @ d_turn
return res
'''
get the rou of matrix 获取矩阵谱半径,即最大绝对值特征值
'''
def getRou(x):
lambdas, features = np.linalg.eig(x)
return np.max(np.abs(lambdas))
'''
get scaled laplacian for chebyshev ploynomials
'''
def scaled_laplacian(L):
res = (2*L)/getRou(L)-np.identity(L.shape[0])
return res
- 契比雪夫多项式的实现
'''
get chebyshev ploynomials
'''
def chebyshev_ploynomials(scaled_laplacian, K):
'''
:param scaled_laplacian: [-1,1]的拉普拉斯矩阵
:param K: 多项式项数
:return: list
'''
res = [np.identity(scaled_laplacian.shape[0]), scaled_laplacian]
if K>=2:
for i in range(2, K+1):
res.append(2*scaled_laplacian*res[i-1]-res[i-2])
return res
- pytorch 实现图卷积
'''
take chebyshev ploynomials as kernal for graph conv
'''
class Cheb_conv(nn.Module):
def __init__(self, chebyshev_ploynomials, K, in_channel, out_channel):
super(Cheb_conv, self).__init__()
self.K = K
self.chebyshev_ploynomials = chebyshev_ploynomials
self.device = chebyshev_ploynomials[0].device
self.thetaList = nn.ParameterList([nn.Parameter(torch.FloatTensor(in_channel, out_channel).to(self.device)) for _ in range(K)])
self.relu = nn.ReLU()
def forward(self, x):
'''
:param x: (batch, nodes_num, features(in_channel), seq_len)
:return:
'''
batch_size, nodes_num, in_channel, seq_len = x.shape
#(batch, seq_len, nodes_num, in_channel)
x = x.permute(0,3,1,2)
output = torch.zeros(batch_size, nodes_num, self.out_channels, seq_len).to(self.DEVICE)
for i in range(self.K):
cheb = self.chebyshev_ploynomials[i]
#(batch, seq_len, nodes_num, in_channel)
cash = cheb.matmul(x)
# (batch, seq_len, nodes_num, out_channel)
cash = self.cash.matmul(self.thetaList[i])
#(batch, nodes_num, out_channel, seq_len)
cash = cash.permute(0,2,3,1)
output += cash
return self.relu(output)


















 1714
1714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











