







对于一个长的句子,理论上我们可以无限的在时间序列上展开,
梯度离散
当一个网络层数过大时,累计后,前面的层数的loss或grad会很小,导致信息一直无法更新。
梯度爆炸
训练的时候,loss在减少,然后突然增大到一个很大的数。
解决方法:每一次计算时,检查w-grad,将其与阈值比较,大于时,用当前梯度的tensor除以它的模,改变其长度但是保持原有的方向。
loss=criterion(output,y)
model.zero_grad()
loss.backward()
for p in model.parameters():
print(p.grad.norm())
torch.nn.utils.clip_grad_norm(p,10)
optimizer.step
此处阈值范围是10。通过for循环查看是否梯度爆炸,并将每个grad信息压缩到10以内,然后可将for注释。
LSTM
LSTM在一定程度上减少了梯度离散的出现。且有较长的记忆。
LSTM:long short-item-memory
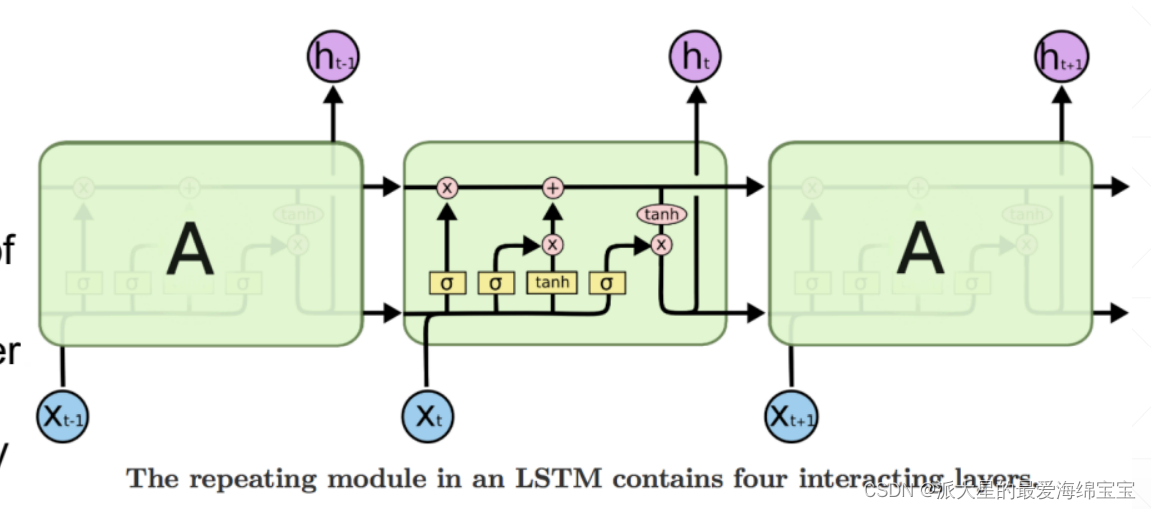
三个σ就是三道门。
相乘的符号起到信息过滤的作用,相加的符号起到信息融合的作用。

也可以理解为remenber门,是0就全部忘记,是1全部记住。
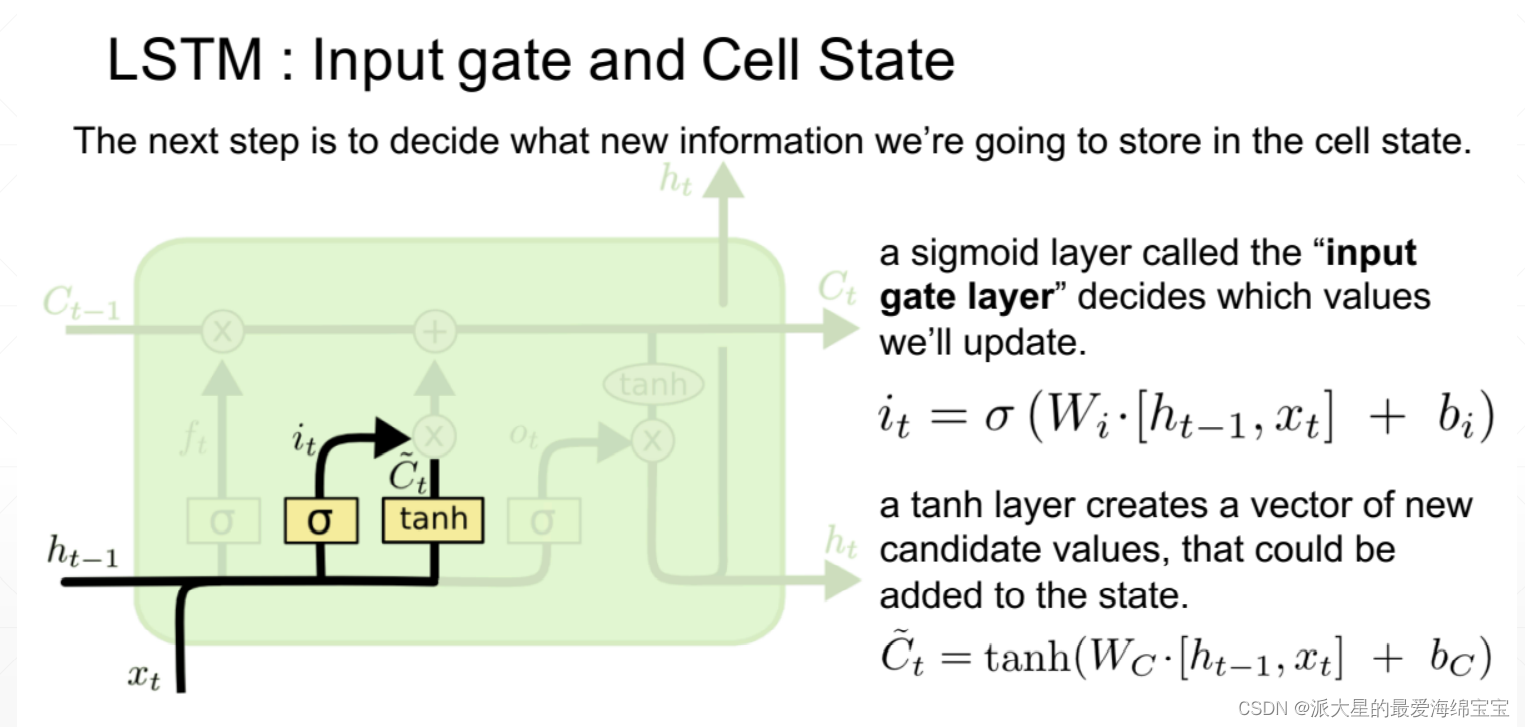
wi,wj是由算法决定的,不是人为设置的。
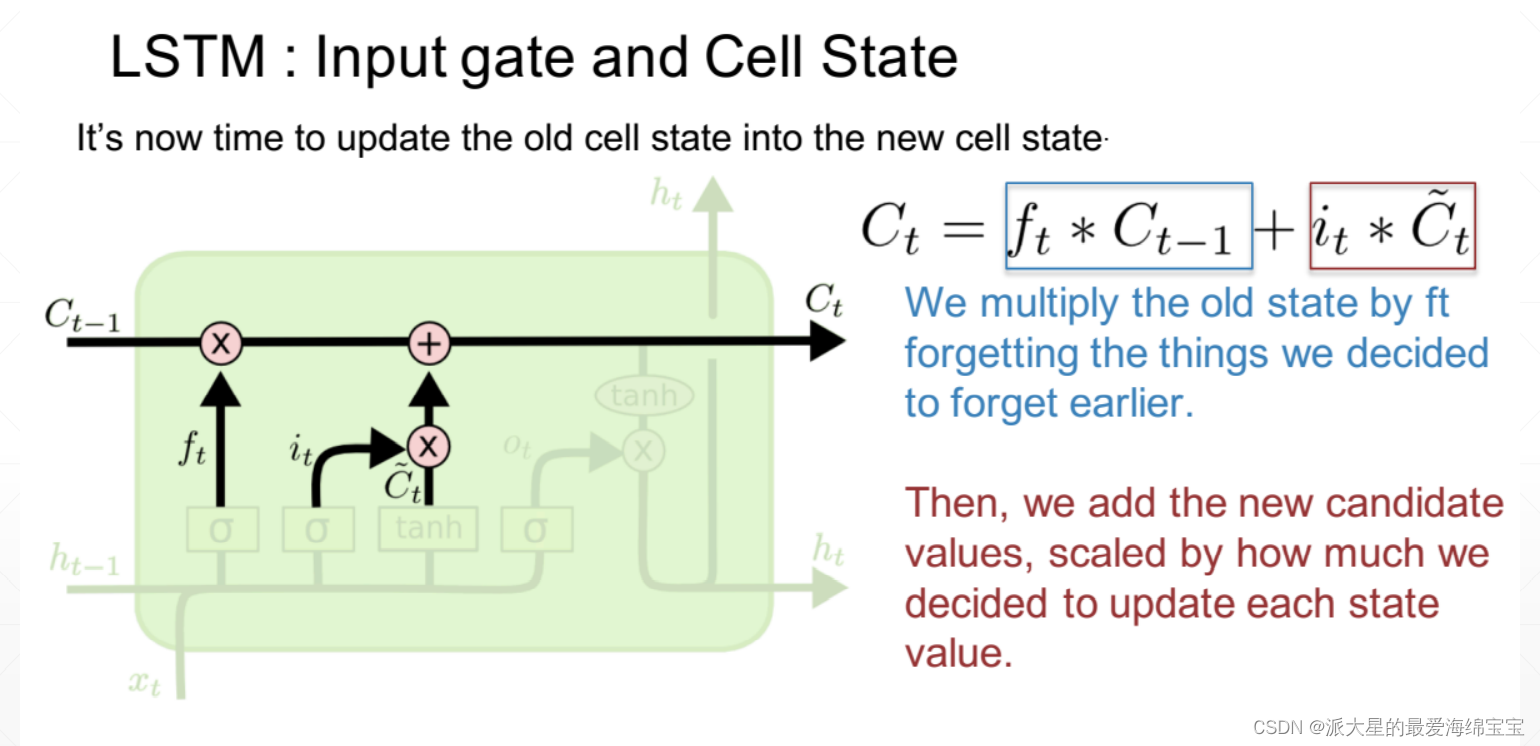

这里的输出是ht。memory会有选择的输出为ht。
LSTM避免出现Whh的k次方情况,通过4项的累加,使得4项都是大或都是小的概率很小。
LSTM使用
nn.LSTM
init
input size
hidden size
num layers
forward()
out,(ht,ct)=lstm(x,[ht_0,ct_0])
out:[seq,b,h],是所有时间戳上的最后一个ht的状态。
ht,ct:[num layers,b,h]是最后一个时间戳的ht,ct状态。
x:[seq,b,vec]
lstm=nn.LSTM(input_size=100,hidden_size=20,num_layers=4)
print(lstm)
x=torch.randn(10,3,100)
out,(h,c)=lstm(x)
print(out.shape,h.shape,c.shape)
[ht_0,ct_0]为0时,可以直接省略。

nn.LSTMCell
init
input size
hidden size
num layers
forward()
ht,ct=lstmcell(xt,[ht_0,ct_0])
xt:[b,vec],
ht/ct:[b,h]
x=torch.randn(10,3,100)
print('one layer lstm')
cell=nn.LSTMCell(input_size=100,hidden_size=20)
h=torch.zeros(3,20)
c=torch.zeros(3,20)
for xt in x:
h,c=cell(xt,(h,c))
print(h.shape,c.shape)
x[10,3,100],10个seq,共3个b,100个vec。
x=torch.randn(10,3,100)
print('two layer lstm')
cell1=nn.LSTMCell(input_size=100,hidden_size=30)
cell2=nn.LSTMCell(input_size=30,hidden_size=20)
h1=torch.zeros(3,30)
c1=torch.zeros(3,30)
h2=torch.zeros(3,20)
c2=torch.zeros(3,20)
for xt in x:
h1,c1=cell1(xt,[h1,c1])
h2,c2=cell2(h1,[h2,c2])
print(h2.shape,c2.shape)
















 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









