







论文地址:https://arxiv.org/abs/1611.07004
1 论文概述
《Image-to-Image Translation with Conditional Adversarial NetWorks》讲的是如何用条件生成对抗网络实现图像到图像的转换任务。图像、视觉中很多问题都涉及到将一副图像转换为另一幅图像(Image-to-Image Translation Problem),这些问题通常都使用特定的方法来解决,不存在一个通用的方法。但图像转换问题本质上其实就是像素到像素的映射问题,论文提出“条件生成对抗网络(CGAN)”能够解决这一问题。如下图所示,这些图片的输入输出就是论文中采用CGAN,实现了语义/标签到真实图片、灰度图到彩色图、航空图到地图、白天到黑夜、线稿图到实物图的转换。使用完全一样的网络结构和目标函数,仅更换不同的训练数据集就能分别实现以上的任务。

2 Tricks
2.1 CGAN介绍
生成器使用了“U-Net”结构,而判别器使用了卷积“PatchGAN”分类器(只在patch的规模下惩罚结构)。GANs是一个学习随机噪声向量z到输出图像y的映射的生成模型:G:z→y。相反的,条件GANs学习观察到的图像x和随机噪声向量z到y的映射:G:{x,z}→y。训练生成器G产生判别器D无法辨别真伪的图像,训练判别器D尽可能检测出生成器的“伪造”图像。
通过https://blog.csdn.net/weixin_44855366/article/details/119734833可以看到GAN的目标函数为:
![]()
而在D和G中均加入条件约束y时,实际上就变成了带有条件概率的二元极小化极大问题,和原始的生成对抗网络相比,条件生成对抗网络CGAN在生成器的输入和判别器的输入中都加入了条件y,这个y可以是任何类型的数据(可以是类别标签,或者其他类型的数据等)。目的是有条件地监督生成器生成的数据,使得生成器生成结果的方式不是完全自由无监督的。CGAN的目标函数为下:
![]()
在生成器模型中,条件变量y实际上是作为一个额外的输入层(additional input layer),它与生成器的噪声输入p(z)组合形成了一个联合的隐层表达;在判别器模型中,y与真实数据x也是作为输入,并输入到一个判别函数当中。实际上就是将z和x分别于y进行concat,分别作为生成器和判别器的输入,再来进行训练。Conditional Generative Adversarial Networks的基本框架如下图:
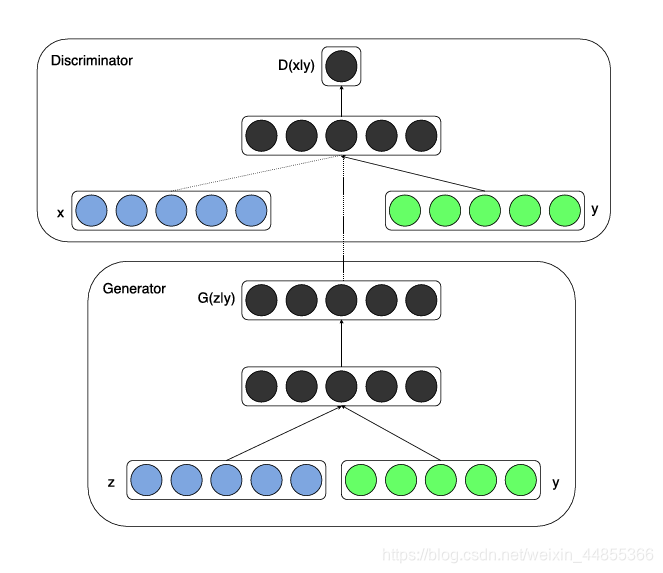
条件GAN先前的方法发现使用传统的loss(比如L2距离)有利于混合GAN目标方程:判别器的工作保持不变,但是生成器不仅要欺骗判别器,还要尽可能生成真实的图片。论文中也研究了这个方面,使用L1距离而不是L2距离,因为L1鼓励更少的模糊:
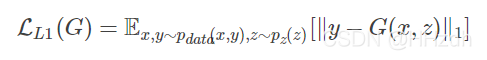
最后的目标函数为:
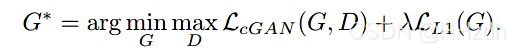
GANs在x上附加一个高斯噪声z作为生成器的输入,在最初的实验中,作者发现这个策略并没不有效——生成器只是简单的忽略了噪声输入。所以在最终的模型中,在训练和测试阶段只以dropout的形式向生成器的某几层中加入噪声。
2.2 网络结构
判别器和生成器两者都使用conv-BatchNorm-ReLu的卷积单元形式。
2.2.1 带有跳线的生成器(Generator with skips)
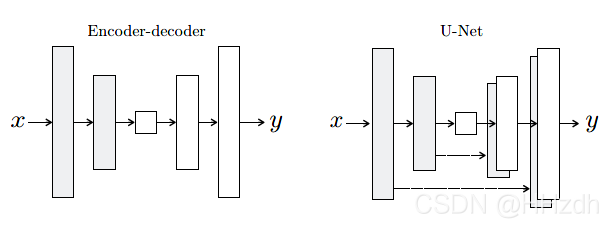
G的结构采用的是U-Net,因为image2image需要从一个高分辨率图像到另一个高分辨率图像,即输入输出虽然在表面细节不同,但是具有相同的底层大致的结构,所以输入与输出需要粗略的对齐。对于图像的任务而言,作者需要输入输出之间除了共享高层语义信息之外,还需要能够共享底层的语义信息。这样,U-Net就可以被运用起来。U-Net和FCN非常的相似,它们的结构用了一个比较经典的思路,也就是编码和解码(encoder-decoder)。

这是一个对称的生成模型,左边部分下采样进行特征提取,右边部分上采样,将浓缩的特征还原为图像。对于许多图像转换问题,在输入和输出之间存在很多可以共享的低级信息,在网络中直接传递这些信息可能会有所帮助。为了更好的传递信息,作者加了skip connections, 直接从i层传输到n-i层,n是总得网络层数,i是与n-i层之间有相应的通道。
2.2.2 马尔可夫判别器(PatchGAN)(Markovian discriminator (PatchGAN))
L1和L2 loss在图像生成问题上会有模糊的问题。比如下面的采用L1 loss生成的图像之中,明显模糊。尽管这些loss不能鼓励生成高频清晰的图像,但在许多情况下它至少能准确的捕捉到低频信息。对于这种情况下的问题,我们不需要一个全新的框架来获得低频信息的准确率,L1已经做到了。

这样做使GAN的判别器只对高频结构建模,依靠L1项来保证低频的准确性。为了对高频信息建模,关注对局部图像块(patches)就已经足够了。因此,对于低频信息的话,选取L1 loss可以达到很好的重建。但是对于高频信息,作者重新设计了一个新结构,PatchGAN,它只判断一个N*N的patch是真是假,所以能更好的判别高频信息。即使N远小于原图的大小,patchGAN依然可以产生较好的结果。并且,它具有更少的参数,运行更快,并且可以运用于任意大的图像。
2.2.3 优化与推理(Optimization and inference)
为了优化网络,使用标准的方法:交替训练判别器D和生成器G。使用minibatch SGD并应用Adam优化器。在推理的时候,用训练阶段相同的方式来运行生成器,但是多了两点,一点是drop out,另一点是BN。

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









