






Diversity-Measurable Anomaly Detection(DMAD)
大意:作者针对基于重建的异常检测方法存在的问题,提出整合了金字塔变形模块和信息压缩模块而提出的异常检测检测框架DMAD。
- 摘要:
基于重构的异常检测模型通过抑制异常的泛化能力来达到检测目的,但这会导致正常的模式也不能很好地进行重建。虽然已经通过对样本多样性建模来缓解这个问题,但是由于不期望的异常信息的传输,它们遭受捷径学习。
在本文中,为了更好地处理权衡问题,我们提出了多样性可测量异常检测Diversity-Measurable Anomaly Detection(DMAD)框架,以提高重建多样性,同时避免不希望的泛化异常。为此,我们设计了金字塔变形模块Pyramid Deformation Module(PDM),该模块通过估计从重建参考到原始输入的多尺度变形场来模拟不同的法线并测量异常的严重程度。结合信息压缩模块(Integrated with an information compression module),PDM基本上解耦变形从原型嵌入,使最终的异常评分更可靠。
在监控视频和工业图像上的实验结果证明了该方法的有效性.此外,DMAD在污染数据和异常样正常样本面前同样有效。
- 问题:作者指出基于重构的异常检测方法在抑制异常的泛化能力的同时,会使正常模式也不能很好地得到重建;而提出地一些多样本建模方法容易遭受shortcut learning.
- 方法:因此作者提出了多样性可测量异常检测方法(diversity-measurable anomaly detection)
1.引言
-
Visual anomaly detection is a a fundamental and important problem in computer vision community, with wide applications in video surveillance and industrial inspection.(工业检测)
-
作者指出异常检测存在挑战的原因:因为异常数据分布广泛且收集成本昂贵。因此,作者的研究目标是在无监督的设置下,基于正常样本,提升判断正常与异常检测的能力。
-
作者提到基于重构的方法存在的问题,即重建多样性的正常与检测未知异常之间的权衡判断。(不知道这句翻译对不对)
However,the performance of reconstruction-based methods for anomaly detection has long been limited by a tough problem,i.e. the tradeoff between reconstructing diverse normals and detecting unknown anomalies. -
解决上述权衡问题的关键是找到正确的衡量正常和异常样本多样性的方法,该多样性与异常的严重程度正相关。
-
作者指出逐像素重建误差并不是多样性的理想测量,因为高误差区域经常将异常与不同的正常混淆,例如具有结构变形的正常和颜色接近背景的异常可能会产生不可靠的重建误差
-
为了更好地重建不同的法线,每个查询向量对应于存储器中的多个原型,即使异常投影远离原型,也可以将其组合成异常嵌入。
-
作者将异常表示为外观的显著变形,包括位置的变化和精细运动。
Inspired by 【4,15】,we wssume anomalies(e.g. in video surveillance) can be represented as significant deformation of appearances,including positional changes and fine motions. -
PPDM 是作者在PDM的基础上提出的一个变体,目的是处理纹理重建中的假阳性问题。
2.相关工作
Anomaly detection
- 一些工作通过自动编码器及其变体进行异常检测,例如引入额外的约束或者记忆单元式模型更具有判别能力。例如,稀疏编码[25,39]通过正则化减少模型的表示冗余;记忆增强自编码通过带外部存储体的训练数据来记忆正常模式;变分自编码假设正态数据的先验分布来约束非线性表示能力;HFVAD[20]使用CVAE[33]屈捕获运动之间的相关性。帧预测[19]假设视频中的异常样本不能由不包含不可见信息的过去帧表示,并迫使模型在不同帧之间编码变化。另外,**自编码可以与
外部目标检测器[7,14,20]**结合去获取与背景无关的运动。 - Although these methods generally work well,they often have difficulty in discriminating abnormal samples from anomaly-like normals due to the tradeoff between reconstruction and discrimination.从类似异常的正常样本中去判断异常,两者之间存在权衡。
- In our framework,pyramid deformation module and information compression module are leveraged to address the trade-off problem,significantly improving the performance in anomaly detection.
Memory network
- In most existing works,the memory module outputs a linear combination of memory items which may lead to undesired reconstruction of normal-like anomalies(重构出不被期望的类似于正常的异常)。.And they do not explicitly consider that instances corresponding to the same memory grid may be located at different positions of the receptive field.In our approach,we alleviate these problems via compressing embedding into a single memory item to ensure that the output is absolutely normal.在我们的方法中,我们通过压缩嵌入到单个内存项来缓解这些问题,以确保输出绝对正常.
Transformation modeling
-
Some methods [7,14,19,20] use external object detectors or optical-flow estimators to model the motion information implicitly or explicirly.(隐式地或显示地)
-
光流[13]估计连续帧之间的像素方向的运动。
3.Diversity-Measurable Anomaly Detection
3.1.The framework
然而,由于不同的数据分布,以前的方法在表示不同的正常和检测异常之间存在矛盾。本质原因是因为多样性[.,f(x)]的编码包含的冗余信息不能被准确检测到。
However,due to diverse data distribution,previous methods have to face the conflict between representing diverse normals and detecting anomalies. The intrinsic reason lies in that the encoding of diversity [.,f(x)] contains redundant information cannot be measured accurately。

3.2.Information compression module
- 根据[35],作者采用VQ-Layer作为信息压缩模型去学习φ(·)给定内嵌f(x)∈R×D×H ’ ×W '作为查询ze = f(x),内存z∈RD×N
3.3.Pyramid deformation module
- 作者将未知的异常分为三类:未见过的类别unseen class(e.g. novel objects),global anomaly(e.g.unexpected movement) and local anomaly(e.g.strange behavior and workpiece demage )of seen class见过的类别。The unseen class is easy to be detected based on reconstruction result,but the latter two types are usually confused with diverse normal.对于后者,为了区分这些异常和正常异常,我们使用可测量的变形来表示重建参考和原始输入之间的多样性,从而使正常发生轻微变形而异常发生剧烈变形。
- Inspired by STN and DCN[4,15],we introduce Pyramid Deformation Module which exlicitly learn deformation fields with hierarchical scales to model the motion,behavior and defect of different anomaly types.
3.4.Foreground-background selection
- 作者指出将背景信息存储在内存中会打破嵌入的紧凑性,且需要大量的内存项。此外,变形估计不应应用于背景。有些方法使用外部估计器去除背景干扰,但不能保证在不同情况下的泛化,不可避免地会引入额外的噪声。得益于固定视图视频的强先验性,我们使用一个可学习的模板xbg对背景建模,并使用fm生成一个二进制掩码来指示一个像素是属于前景还是背景(·)。
- 理解:我猜测作者这里的意思是指对于监控视频这样的情形下,背景不是很重要,所以开头提到了背景存在的不足。
- 下面是作者背景处理K-head的公式:
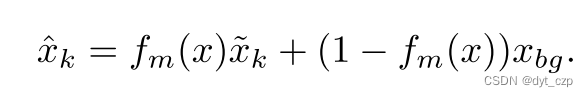
3.5.Training and inference
- Training phase
得到重构值之后,计算原图像与重构之间的距离差,来得到重构损失。还有等式3中的两个约束条件。
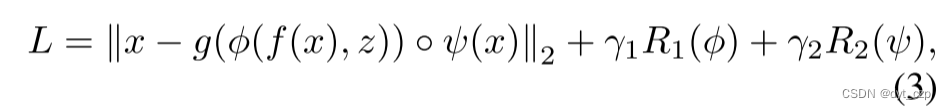
所以,作者训练阶段最小化的损失函数包括3部分:重构损失、两个约束条件
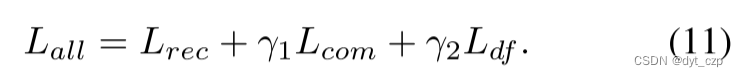
- Inference phase
作者使用O和重构损失来计算输入样本x的误差映射:
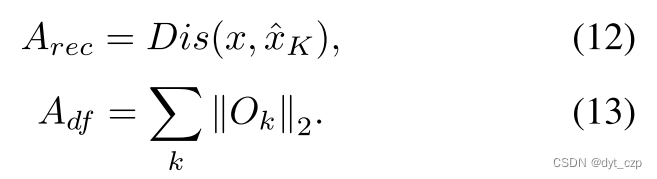
基于局部极大值计算图像级异常评分:
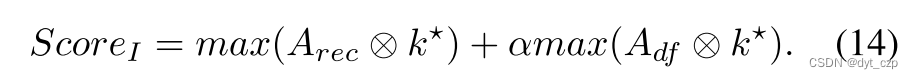
3.6.Variant of PDM
-
Modified framework with Pre-PDM
这里作者指出两点:(1)工业缺陷检测,纹理重建可能有害(如“药丸”上的斑点),应该重构高级语义特征;(2)由于金字塔形变模型PDM不适用于高维特征空间,并且干扰了训练过程。所以,作者提出了PDM的变体,pre-PMD(PPDM). -
PPDM works in sample space,and is applied to the input samples rather than the reconstructed one.
样本空间的含义:指所有可能存在的合理情况的集合,即目前能获得的训练集。

-
prevent from shortcut learning:指防止模型仅仅依赖于视觉特征中的表面、局部或次要信息来进行图像分类或识别,而忽略了图像中更深层次和有意义的结构和内容。
-
循环一致性原则cycle-consistency principle:指输入图像在进行处理变换后再转换回原始域时,应该获得与原始域相似或相同的图像。
-
Training phase

-
Inference phase
为了得到真实位置的异常图,我们使用反向变形 backward deformation 进行逆采样.
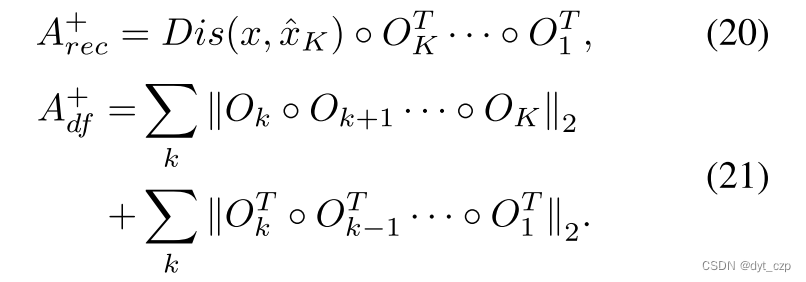
分别计算图像级异常分数与像素级异常分数:
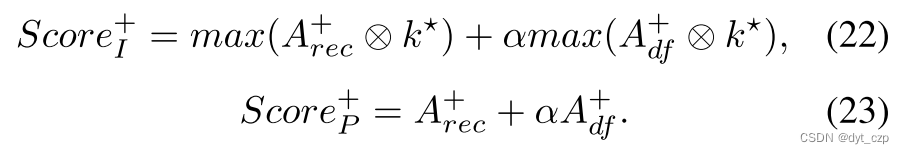
4.Experiments and Analysis
4.1.Datasets
-
Surveillance Videos.
Ped2 [27], Avenue[23]和ShanghaiTech[25]都是固定视频。异常情况包括开车、骑车、跑步、扔东西等。相互遮挡、异常行为、污染数据和不同场景是这些数据集的常见现象. -
Indusytial Images
MVTec[2]包含15种工业图像,分为5种纹理和10种对象。缺陷包括裂纹、划痕等。普通工件有不同的位置、角度和纹理。用于检测和定位任务
4.2.Toy experiment
如图6所示,我们在MNIST数据集[16]上进行玩具实验,设置类似于out-of - distribution (OOD)检测(即训练“1、3、5、7、9”,对所有类进行测试)。我们的模型为每个数字类别搜索单独的存储项,将其重构为特定类的引用,并使用PDM的变形字段对其进行分层调整。当用可见的和不可见的类进行测试时,模型将重构的引用调整为正常输入,但在异常输入上失败.
相比之下,没有多样性感知模块的存储网络不能保证类内的紧凑性和重构的多样性,从而误导模型获得数据集最优的“平均内存”,导致模糊重构和较低的识别能力。全通道跳跃连接模型存在快速学习和异常重构的缺陷,削弱了异常识别能力.
4.3.Implementation details
- 输入图像调整大小为256×256,将值归一化到[-1,1]区间;
- 根据帧预处理策略[Future frame prediction for anomaly detection-A new baseline,CVPR-2018],视频异常检测的历史长度设置为4,图像设为0.
- PDM和PPDM经过主干特征提取后,通过步进-2卷积层叠加得到不同的磁头
- 我们使用Tanh作为输出层的激活函数和剪辑函数clipping function,以保证变形值the value of deformation在[−1,1]之间。
- 除特别说明外,自动编码器的架构分别满足PDM和PPDM的MNAD[29]和RD[6]设置
- 采用帧差法去除Avenue的静态异常,因为我们的方法可以检测到所有可能被标记为正常异常的异常
- 模型优化和学习率的设置参考文献[6,21,29]
4.4.Main results
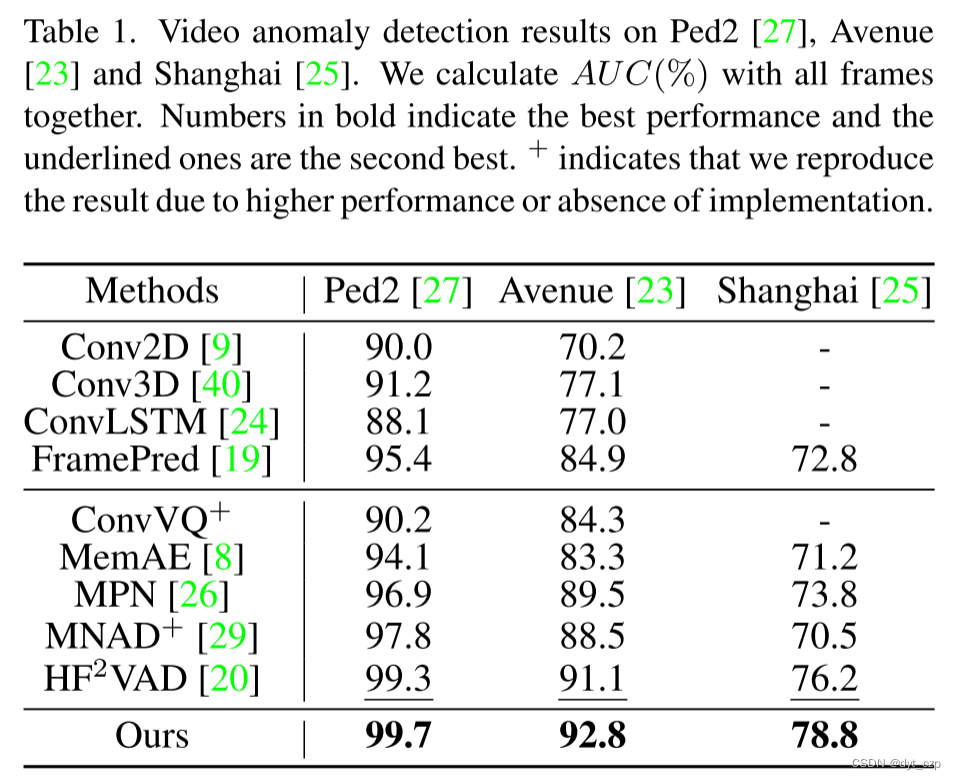
- Surveillance Videos 的结果
作者的方法优于比较方法,即使没有使用外部估计器,也没有去除训练数据中的异常帧。
此外,如果作者在文献[21]中检测到相机抖动的全局偏移,将会有额外的0.1%增益

- Industrial Images的结果
分为图像级异常检测和像素级异常定位
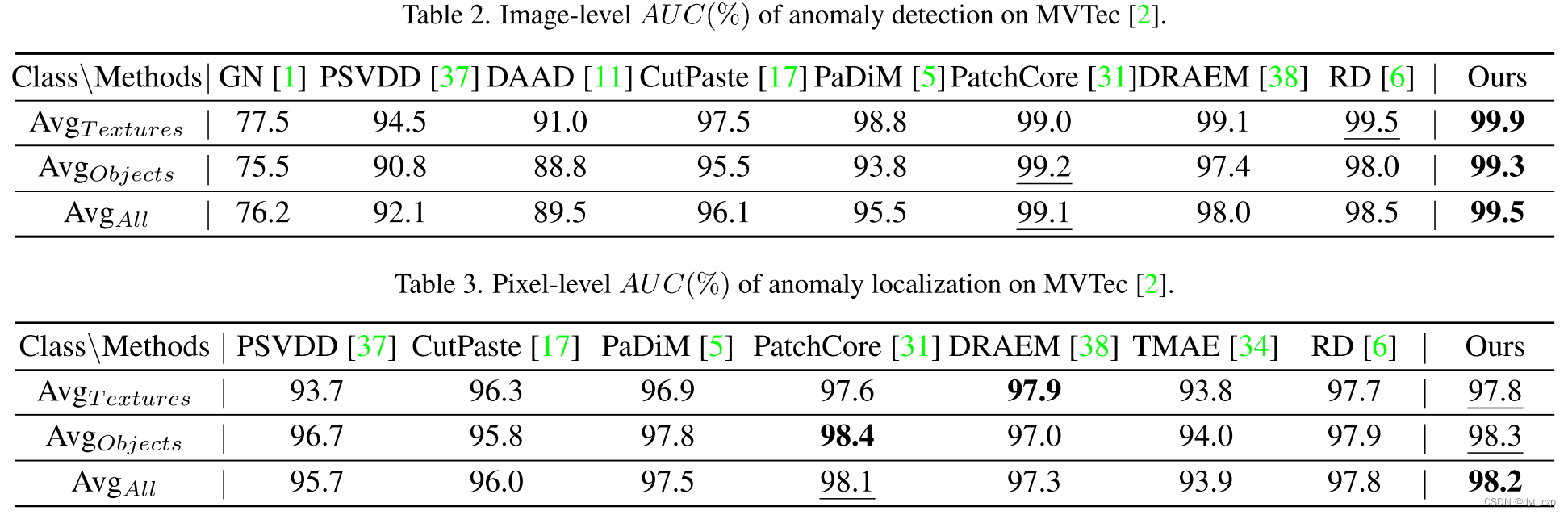
图像这里,作者没有给出定性结果,只有AUC表格数据。
4.5.Ablation study
如表4所示,没有PDM的单输出内存模块严重抑制了各种正常模式,而没有内存的单独PDM模块提供了与以前的SOTA工作时相当的性能增益,因为模块“Comp.”代替了信息压缩模块。
多尺度变形场的数量对性能也有一定的影响。我们建议“K”至少要做控制网格的规模,覆盖基本元素的大小(例如行人的四肢)。此外,前台-后台选择模块进一步提高了内存嵌入的紧凑性。
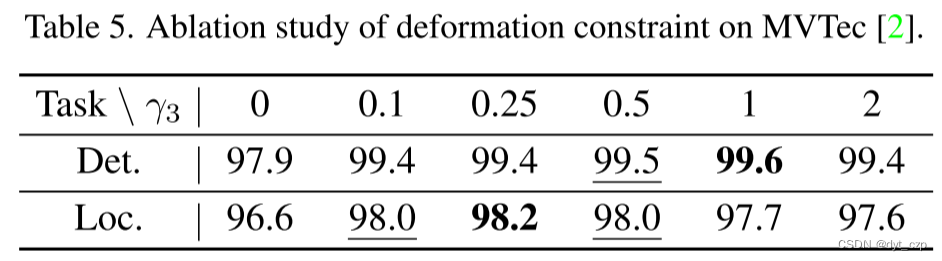
此外,如果PDM缺少约束,则异常信息会被传递,导致快速学习。特别是,循环一致性约束Lcyc也是PPDM避免退化解(−1.7%)的必要部分,因为通过消除所有必要的信息,可以使特征重构误差最小化。
在不形成退化解的情况下,弱化约束使模型更容易从细节较少的参考点恢复图像,通过将异常转换为正常模式,更准确地感知异常位置,有利于定位任务。相反,加强约束可以减少快速学习,并通过保持更多的异常细节来改善图像级结果。
4.6.Disussion
-
Contaminated data assumption
假设训练数据只包含完全正常的数据是不现实的,因为自然数据清理的工作量相当大,甚至与数据标注的成本相同。我们将训练数据与Ped2中的异常事件混合模拟污染数据,发现MNAD[29]的性能下降为−3.7%,而我们的为−1.8%。DMAD受影响较小的原因可能是PDM能够对混合异常和类异常正常样本的残余异常表示进行编码和传输,从而严格保持了主编码器的表示紧凑性和对异常样本的低泛化能力. -
Two DMAD implementations
如前所述,我们的DMAD框架由两个版本实现,分别使用PDM和PPDM,对应不同的检测目标。如图8所示,PDM从内存嵌入到各种模式中学习了可测量的量化误差(ICM引起的),增强了ICM保持类内紧凑性而不产生不可测量重构损失的潜力。与PDM不同的是,PPDM部分负责信息压缩,即PPDM利用从输入到参考的反向变形过程,去除不同的外观.
5.Conclusion
本文提出了一种基于重建的多样性可测量异常检测框架,该框架增强了异常识别能力和重建多样性。为此,提出将金字塔变形模块与信息压缩模块结合使用。PDM显式地模拟从参考到原始输入的多尺度变换域,而不依赖于外部估计。因此,可以重建多种正常模式,准确测量异常严重程度。对视频和图像基准的实证研究显示了我们工作的有效性和适用性。在未来的研究中,我们将进一步探索异常检测的多样性感知模型
Limitations
我们的方法是针对异常检测中最常见的具有可测量几何多样性的异常。然而,对于其他种类的多样性异常,如颜色,所提出的多样性测度可能与异常严重程度不呈正相关。
















 1247
1247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









