






论文阅读笔记:SCAN: Learning to Classify Images without Labels
摘要
当ground-truth缺席时,我们能自动将图像分组成语义上有意义的聚类吗?
在本文中,我们跳脱出最近的工作,而提倡一种两步方法——将特征学习和聚类解耦。首先,利用表征学习中的自监督任务获得语义上有意义的特征。其次,我们使用获得的特征作为先验知识,采用可学习的聚类方法。通过这样做,我们消除了学习依赖于(当前端到端学习方法中广泛存在的)低级特征的能力。
简介和相关工作
在有监督的设置下,网络擅长学习可随后聚集到预定类别中的区别性特征表示。然而,当在训练时无法得到ground-truth标签时,会发生什么?或者更进一步,语义的类,甚至它们的总数,都不是先验已知的?在这种情况下无监督或自监督学习技术最近出现在文献中,理想的目标是将图像按照聚类结果分组,以便相同类中的图像属于相同或相似的语义类,而不同集群中的图像在语义上是不同的。
表征学习 用自监督学习仅从图像生成特征表示,省去了昂贵的语义注释。为了实现这一点,他们使用预先设计的任务,视觉特征是通过最小化代理任务的目标函数来学习的。表征学习方法在ground-truth缺失时仍然需要独立定义和优化聚类标准(如K-means)。这种做法是次优的,因为它会导致不平衡的聚类,并且无法保证学习到的集群将与语义类对齐。
端到端学习 的pipelines将特征学习与聚类相结合。第一类方法在聚类图像之前利用CNN的体系结构。第二类方法通过最大化图像及其增强之间的互信息来学习聚类函数。
与最近的端到端学习方法相比,我们使用两步无监督图像分类方法。提出的方法名为SCAN(采用最近邻进行语义聚类,Semantic Clustering by Adopting Nearest neighbors),利用了表征学习和端到端学习方法的优点、并同时解决了它们的缺点:
- 第一步,我们通过代理任务学习特征表示。表征学习方法在学习特征表示后需要K-means聚类,这会导致聚类退化。与表征学习方法不同,我们建议基于特征相似性挖掘每个图像的最近邻。在大多数情况下,这些最近邻属于同一语义类,这使得它们适合于语义聚类。
- 第二步,我们将语义上有意义的最近邻作为先验知识整合到可学习的方法中。我们通过使用损失函数将每个图像及其挖掘的近邻分类在一起,该损失函数在softmax之后最大化它们的点积,推动网络生成一致和无偏的one-hot预测。与端到端方法不同,学习的聚类依赖于更有意义的特征,而不是网络体系结构。此外,我们发现没有必要对输入应用特定的预处理。
方法
首先,我们展示了如何从代理任务中挖掘最近邻作为语义聚类的先验知识。此外,我们还引入了额外的约束来选择合适的代理任务以产生语义上有意义的特征表示。其次,我们将获得的先验信息集成到一个新的损失函数中,将每个图像及其最近邻一起分类。此外,我们还展示了如何通过自标记方法缓解最近邻选择中固有的噪声问题。
表征学习
端到端的聚类学习对网络初始化敏感。此外,训练开始时网络尚未从图像中提取高级信息。聚类容易去抓住那些低级特征(例如颜色、纹理、对比度等),这对于语义聚类来说是次优的。为了克服这些局限性,我们采用表征学习作为一种手段来获得更好的语义聚类先验知识。
在表征学习中,一个代理任务
τ
τ
τ以自监督的方式学习一个嵌入函数
Φ
θ
Φ_θ
Φθ(由权重为
θ
θ
θ的神经网络学习),该神经网络将图像映射为特征表示。在语义聚类中,特征表示应该对图像变换保持不变。为此我们增强了代理任务,以尽量减少图像
X
i
X_i
Xi及其增强
T
[
X
i
]
T[X_i]
T[Xi]之间的距离:
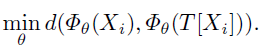
例如,图1显示了在满足等式1下检索最近邻域的结果。我们观察到相似的特征被赋予语义相似的图像。代理任务输出以图像为条件,迫使θ从输入中提取特定信息。其次,由于
Φ
θ
Φ_θ
Φθ容量有限,它必须从输入中丢弃无法预测的高级代理任务信息。因此,具有相似高级特征的图像将在的嵌入空间中靠得更近。

表征学习中的代理任务可以获得语义特征,我们将利用代理特征作为对图像进行聚类的先验条件。
语义聚类损失
挖掘最近邻。在第2.1节中,我们提出了一个来自表征学习的pretext任务可以用来获得语义上有意义的特征。然而,在获得的特征上天真地应用K-means会导致聚类退化。判别模型在学习决策边界时可能将其所有概率分配给同一个类,这导致该类主导其他类。
让我们先来考虑下面的实验。通过表征学习,我们在未标记的数据集
D
\mathcal D
D上训练模型
Φ
θ
Φ_θ
Φθ,以求解pretext任务
τ
τ
τ,即实例判别。然后,对于每个样本
X
i
∈
D
X_i∈\mathcal D
Xi∈D、 我们在Embedding空间
Φ
θ
Φ_θ
Φθ中挖掘其
K
K
K近邻。在数据集
D
\mathcal D
D中,我们将集合
N
X
i
\mathcal N_{X_i}
NXi作为
X
i
X_i
Xi的近邻样本。图2量化了挖掘的最近邻是相同语义聚类的实例,这种情况在很大程度上都是如此。根据这一观察,我们建议采用通过pretext任务
τ
τ
τ获得的最近邻作为语义聚类的先验。

损失函数
我们的目的是学习一个聚类函数
Φ
η
Φ_\eta
Φη,由具有权重
η
\eta
η神经网络参数化,将样本
X
i
X_i
Xi及其近邻
N
X
i
\mathcal N_{X_i}
NXi分类到一起。函数
Φ
η
Φ_\eta
Φη最后用softmax函数对聚类结果
C
=
1
,
…
,
C
\mathcal C={1,…,C}
C=1,…,C执行聚类到
[
0
,
1
]
C
[0,1]^C
[0,1]C的软赋值。将样本
X
i
X_i
Xi赋给
c
c
c类的概率表示为
Φ
η
c
(
X
i
)
Φ_\eta^c (X_i)
Φηc(Xi)。我们通过最小化以下目标来学习Φη的权重:
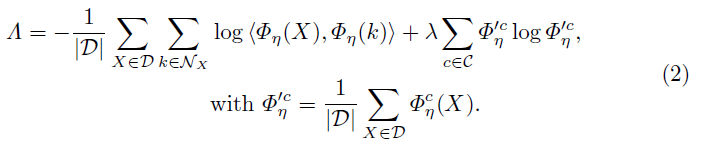
该目标函数的第一项鼓励
Φ
η
Φ_\eta
Φη保证对
X
i
X_i
Xi和他的近邻
N
X
i
\mathcal N_{X_i}
NXi预测结果的一致性。注意,当预测结果为one-hot的(高置信度)并分配给同一类(高一致性)时,将最大化点积(从而最小化第一项)。为了避免
Φ
η
Φ_\eta
Φη将所有样本分配给单个类(退化解),我们加入了一个熵项(第二项),该项将鼓励预测结果均匀地分布在所有类集合
C
\mathcal C
C上。如果类集合
C
\mathcal C
C的概率分布事先已知(此处并非如此),则该项可以用KL散度代替。
在实践中,应该能够获得集群数量的粗略估计。基于这一估计,我们可以对大量的类进行过聚类,并使类分布均匀。
实施细节
为了实际实现我们的损失函数,我们通过大量抽样来近似数据集统计数据。在训练过程中,我们随机增加样本和他们的近邻。对于角点情况K=0,仅施加样本及其增强之间的一致性。我们设定K≥ 1以引入噪声为代价捕获更多的聚类方差,即并非所有样本及其相邻样本都属于同一个聚类。第3.2节实验表明,选择K≥ 1与仅强制实施样本及其增强之间的一致性相比,显著改善了结果。
讨论
我们没有将重建项纳入损失,因为这不是我们的目标任务明确要求的。毕竟,我们只对从输入信号编码的少量信息感兴趣,而不是重建通常需要的大部分信息。值得注意的是,一致性是通过损失中的点积项在单个样本的水平上实现的,而不是在类别上联合分布的近似值上实现的。我们认为这允许以更直接的方式表达一致性。
2.3 通过自标记进行微调
第2.2节中的语义聚类损失强加了样本与其近邻之间的一致性。更具体地说,每个样本都与K≥ 1个近邻相结合,但其中一些不可避免地不属于同一语义集群。这些假阳例导致了网络不太确定的预测。同时,我们通过实验观察到,具有高置信度的预测( p m a x ≈ 1 p_{max}≈1 pmax≈1)的样本倾向于被划分到正确的类别。事实上,网络在聚类过程中形成的高度一致的预测可以被视为每个类别的“原型”。这允许我们以更可靠的方式根据预测的可信度选择样本。因此,我们提出了一种自标记方法以利用这些“原型”,并纠正由于最近邻噪声引起的错误。
在训练过程中,通过对输出概率进行阈值化,即 p m a x > p_{max}> pmax>threshold来选择可信样本。对于每个可信样本,获得其聚类后的伪标签。交叉熵损失用于更新获得的伪标签的权重。为了避免过拟合,我们计算了强增强后的可性样本的交叉熵损失。自标记步骤允许网络自我校正,它逐渐变得更加确定。
算法1总结了所提出方法的所有步骤。我们进一步将其称为SCAN,即最近邻进行语义聚类 (Semantic Clustering by Adopting Nearest neighbors) 。

3 实验
3.1 实验设置
BackBone使用标准的ResNet-18。对于每个样本,通过基于噪声对比估计(NCE)的实例判别任务确定20个最近邻。对于较小数据集上的实例识别任务,我们采用SimCLR实现,在ImageNet上采用MoCo(momentum contrastive learning)实现。所选pretext任务满足公式1中关于特征不变性的约束并施加图像增强变换。通过随机选择RandAugment中的四个变换对图像进行增强。验证准则在聚类步骤中,我们根据最小损失选择最佳模型。在自标记步骤中,我们在确认样本量稳定时保存模型的权重。
3.2 消融实验

我们通过表1量化了我们方法不同部分的性能增益。对NCE代理特征进行K-means聚类得到的准确率最低(65.9%),其特点是方差较大(5.7%)。这是意料之中的,因为聚类分配可能是不平衡的(图3),并且不能保证与ground-truth对齐。

有趣的是,对于基于端到端学习方案的无监督分类,将K-means应用于代理特征的效果优于先前的方法。这一观察结果支持了我们的主要主张,即将特征学习与聚类分离是有益的。通过SCAN损失更新网络权重——同时通过SimCLR变换增强输入图像优于K-means(+15.9%)。注意,SCAN损失与K-means有一定的关系,因为这两种方法都使用代理特征作为它们对图像进行聚类之前的特征。不同的是,我们的损失避免了聚类退化问题。我们还研究了在训练期间使用不同增强策略的效果。将RandAgument(RA)转换应用于样本及其挖掘的近邻进一步提高了性能(78.7% → \to → 81.8%)。我们假设,强增强通过施加额外的不变性有助于减小解空间。
通过自标记对网络进行微调进一步提高了聚类的质量(81.8% → \to → 87.6%)。在自标记过程中,网络会随着其逐渐变得更加复杂而自我修正(见图4)。

重要的是,为了成功应用自标记,需要改变增强方式(见图5)。我们猜测这是为了防止网络过拟合已经被很好地分类了的样本。最后,图6显示了自标记过程对阈值不敏感。

代理任务
我们研究使用不同的代理任务挖掘最近邻的效果。我们考虑两个不同的实例辨别任务的实现,表2显示了CIFAR10的结果。

首先,我们观察到所提出的方法与特定的代理任务无关:SCAN的准确率总比K-means高(>70%)。其次,满足不变性准则的代理任务更适合挖掘最近邻,即inst.discr的83.5%和87.6%。这证实了我们在第2.1节中的假设,即选择一个在图像及其增强之间施加不变性的代理任务是有益的。
近邻个数
图7显示了在聚类中使用不同数量的最近邻K的影响。结果对K值不是很敏感,当K从5增加到50时,结果甚至保持稳定。这是有益的,因为我们不必在非常新的数据集上定义K的值。事实上,当K值增加到某个值时,稳健性和准确性都会提高。我们也考虑K = 0时只执行图像及其增强的一致性预测。与K=5相比,这三个数据集的性能都有所下降,这证明通过在样本与其近邻之间执行一致性预测,可以学习更好的表示。
收敛性
图8显示了从最近邻(即属于不同类别的样本对)移除假阳例时的结果。结果可以被视为拟议方法分类精度的上限。一个满意的特征是类别迅速与ground-truth对齐,在CIFAR10和STL10上获得接近完全监督的性能。
3.3 与SOTA相比(略)

3.4 过聚类
到目前为止,我们假设已经知道了真实的类的数量,并使用匈牙利匹配算法对方法预测进行评估。但是,如果聚类的数量不再与真实类的数量匹配会发生什么?表3报告了当我们高估真实类2倍时的结果,例如,我们将CIFAR10分为20类而不是10类。CIFAR10(87.6% → \to → 86.2%)和STL10(76.7% → \to → 76.8%)的分类准确率保持稳定,CIFAR100-20(45.9% → \to → 55.1%)的分类准确率甚至有所提高。我们得出结论,该方法不需要知道集群的确切数量。CIFAR100-20在超类中将多个对象类组合在一起。在这种情况下,过聚类更适合解释类内差异。
















 9221
9221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









