







论文评价:
发表于NIPS2022,链接如下:链接。这篇文章探讨的是如何提升”某种意义上“的zero-shot性能。重点讨论的是双向模型的NLU(自然语言理解)性能。
论文创新点:
提出了一种基于生成训练数据的方法来创造了一种”zero-shot“的能力(这里打括号是因为本质上,这其实是对模型进行了训练,但由于确实没有用到对应domain的训练集,所以可以视作zero-shot)。
论文思路:
1.整体思路:
使用单向的生成模型根据标签生成数据内容(也就是反向的训练,正常来说都是用内容去判断标签),然后用生成的数据内容拿去训双向模型,你就说用没用到训练集吧
2.细节补充
对于NLU任务有许多的下游任务,本文中讨论的主要是NLU里的分类任务,例如情感分析,文本蕴含等,它们大致可以分为一个句子(或者说一段话)输出一个类别,和需要判断两句话(两段话)的相互关系两类。
根据生成训练样本的思路,对于一个句子输出类别的任务,采用的是根据类别写一个prompt,然后让模型根据prompt生成数据内容的方法,对于两个句子输出类别的任务,采用的是根据类别和prompt先写第一句话,根据prompt,第一句话写第二句话。具体如下,为前一句话,
为后一句话:
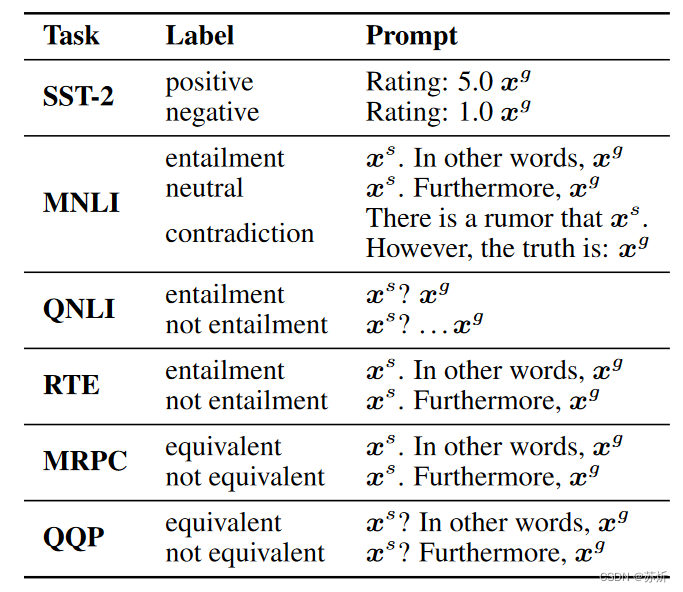
3.筛选数据集
生成的东西直接拿来当训练样本肯定是不行的,需要进行进一步的筛选。
注:作者觉得这有两方面的原因,第一是因为我们拿来训单向模型的数据集和测试双向模型的测试集可能不是一个domain。第二是生成的东西本来有噪音,质量不太好说。
(1)挑概率高的
我们要挑出一些更像是这个类别的数据,具体来说,当然单向模型生成的时候概率高的就是它认为更像的,为了减少对短文本的偏好,用的是所有token的几何平均数。
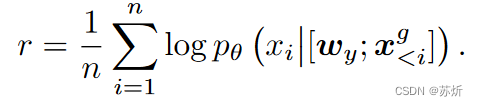
(2)label-smoothing
由于生成的数据中可能有噪声,如果直接用的是one-hot编码,那就相当于我们认为它没有噪声,所以我们对生成文本的标签进行了标签平滑,来抵消这种噪声的影响。
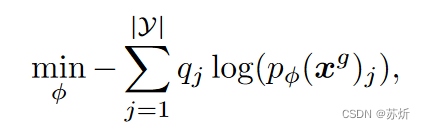
![]()
(3)temporal ensembling
由于模型在早期训练的时候其实对数据的噪声容忍度比较高(因为它还没认识到数据分布到底是什么样子),所以我们为每一个样本记录了模型可以辨别出它的程度,并每隔n个Batch更新一次(不一定更新的到这个样本)。
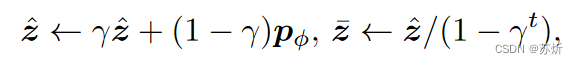
这个公式里面,都是超参数,当
小于等于某个阈值(人为设定)时,我们就筛除这个例子。
最终双向模型优化的内容其实是:
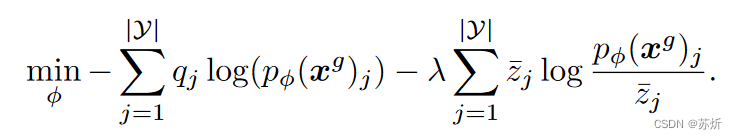
论文当中还有一些其他的小tricks,请参考原文就好啦
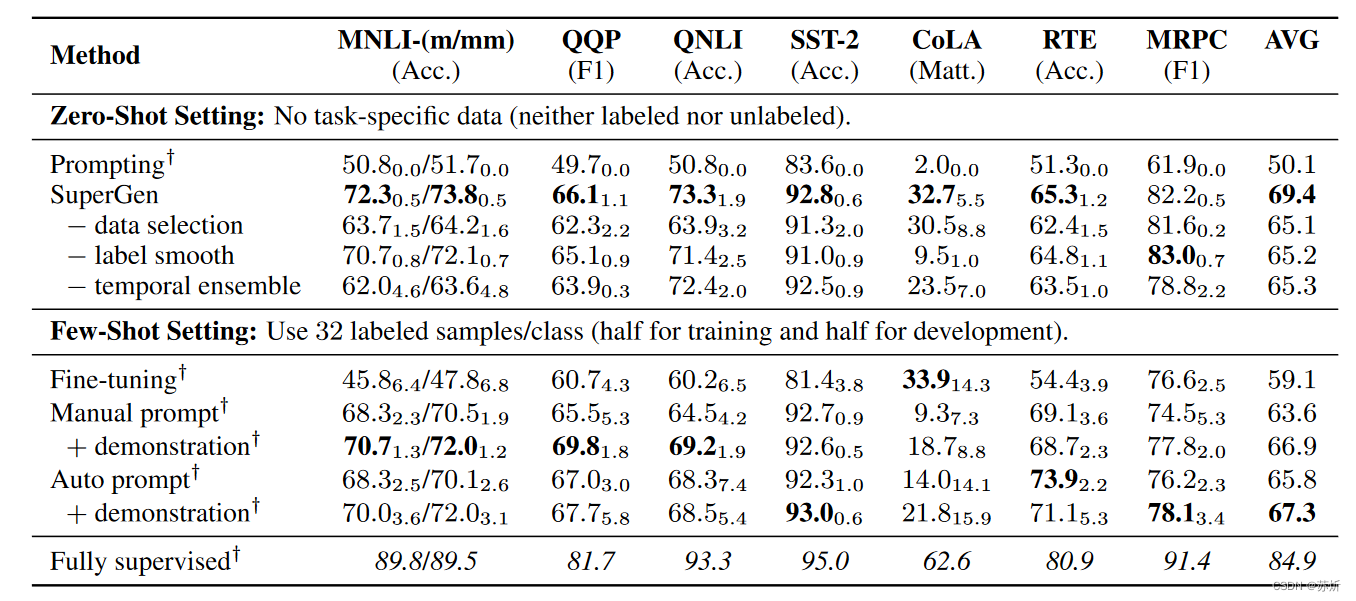
实验结果















 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









