







文章思想
PLM有两种形式,一种是Unidirectional PLMs(类似于GPT),一种bidirectional PLMS(类似于Bert)。
文章提出**利用两种PLM实现zero shot的NLU task,**即分类任务。
A unidirectional PLM generates class-conditioned texts guided by prompts, which are used as
the training data for fine-tuning a bidirectional PLM
大致来说,是利用GPT模型在给出prompt下的情况下,生成训练文本。
然后利用BERT 模型对上述文本进行分类,完成下游任务。
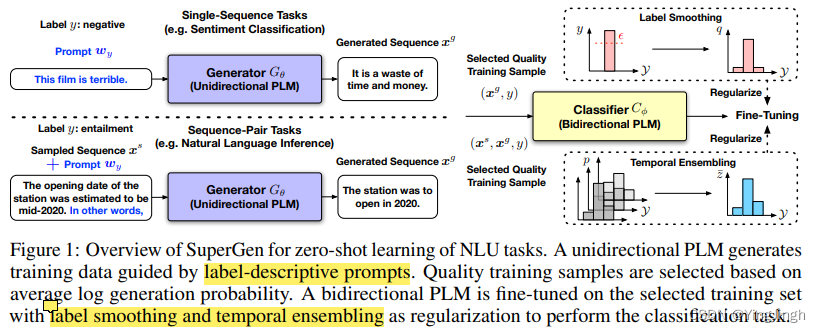
模型细节
1. valid dataset

2. 生成模型的repeat 生成的问题
one approach is to discourage repetition by reducing the logits of tokens that are already in the sequence before performing sampling

通过设置α<1和β>1,我们可以促进x s中未在x g中出现过的代币有更大的机会被生成,并阻止x g中重复代币的生成,以减轻退化性重复。
3. 生成数据的选择
选择最可能与所需标签y有关的生成文本x g。

在计算数据instance的概率时,使用算数平均作为概率值。
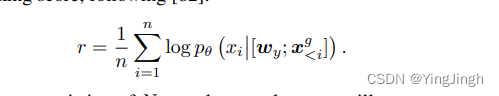
4. regularization
label smoothing trains the classifier Cφ to minimize the standard cross-entropy loss between the label and the classifier’s prediction

temporal ensembling:我们在不同的训练步骤中记录Cφ对每个训练样本(x g , y)的预测pφ = pφ(x g ),并使用累积的移动平均预测值z¯来规范最新的模型训练。

最终的训练函数:从模型预测中加入KL发散正则化项,以λ为权重的合集预测。

















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











