实验结果:
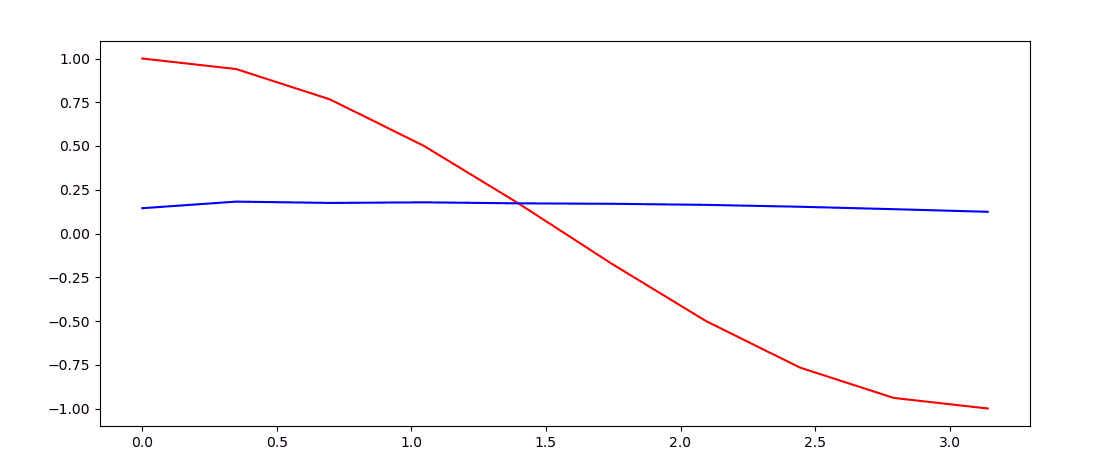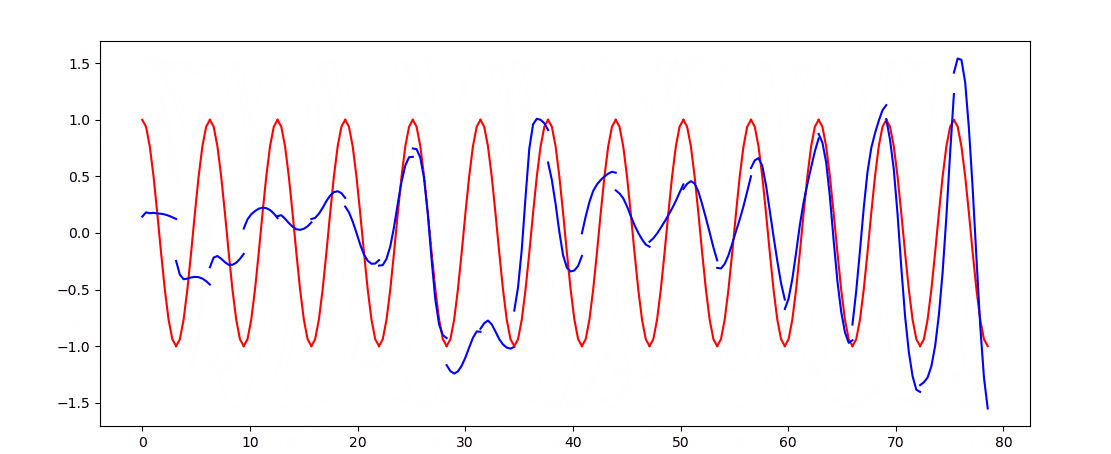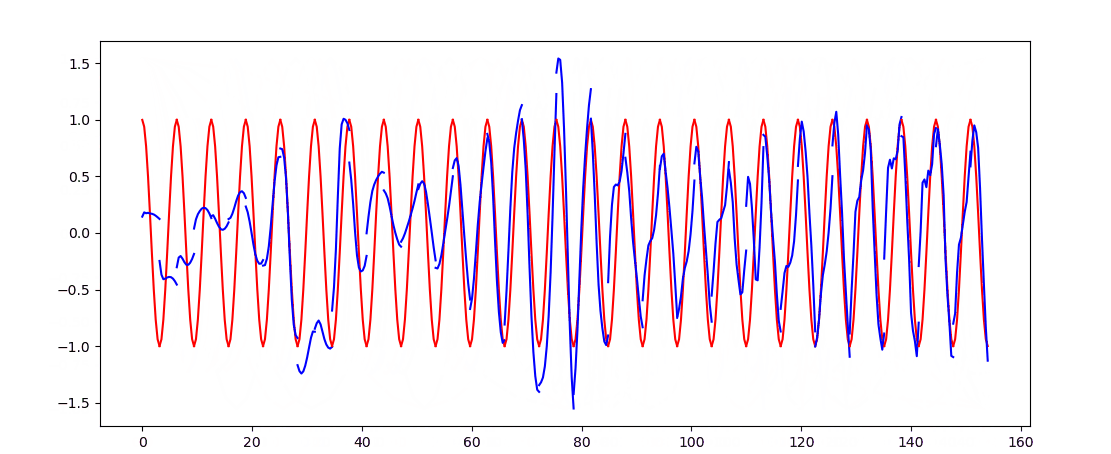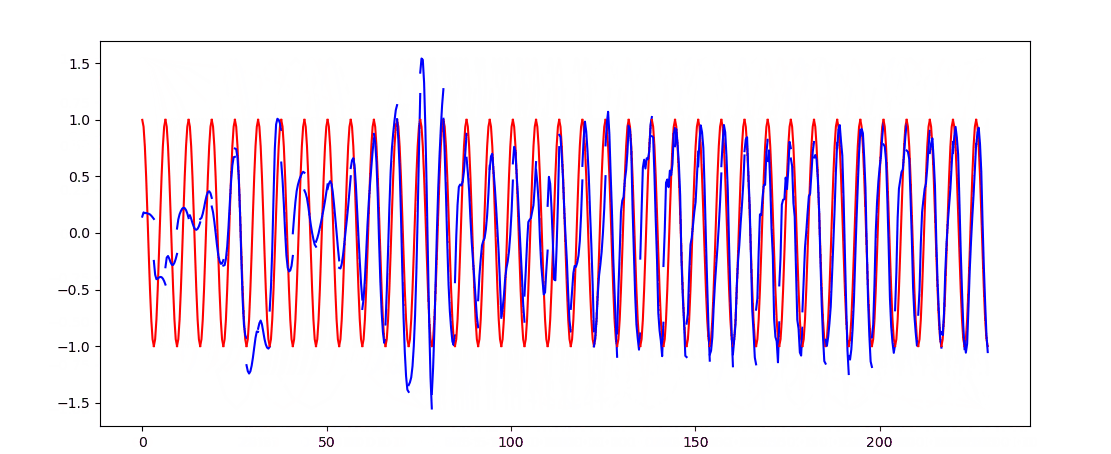
- 这次用RNN_LSTM实现回归任务
- 这里主要讲解搭建RNN部分,其他部分和前文中CNN搭建类似。
🌵 搭建RNN(该任务使用RNN足矣)
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
)
self.output_layer = nn.Linear(in_feature, out_feature)
def forward(self, x, h_state):
rnn_out, h_state = self.rnn(x, h_state)
out=[]
for time in range(rnn_out.size(1)):
every_time_out = rnn_out[:, time, :]
out.append(self.output_layer(every_time_out))
return torch.stack(out, dim=1), h_state
完整代码:
"""
作者:Troublemaker
日期:2020/4/11 10:59
脚本:rnn_regression.py
"""
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
class RNN(nn.Module):
"""搭建rnn网络"""
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,)
self.output_layer = nn.Linear(in_features=hidden_size, out_features=output_size)
def forward(self, x, h_state):
rnn_out, h_state = self.rnn(x, h_state)
out = []
for time in range(rnn_out.size(1)):
every_time_out = rnn_out[:, time, :]
out.append(self.output_layer(every_time_out))
return torch.stack(out, dim=1), h_state
input_size = 1
output_size = 1
num_layers = 1
hidden_size = 32
learning_rate = 0.02
train_step = 100
time_step = 10
steps = np.linspace(0, 2*np.pi, 100, dtype=np.float32)
x_np = np.sin(steps)
y_np = np.cos(steps)
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=learning_rate)
loss_function = nn.MSELoss()
plt.figure(1, figsize=(12, 5))
plt.ion()
h_state = None
for step in range(train_step):
start, end = step * np.pi, (step+1) * np.pi
steps = np.linspace(start, end, time_step, dtype=np.float32)
x_np = np.sin(steps)
y_np = np.cos(steps)
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
pridect, h_state = rnn(x, h_state)
h_state = h_state.detach()
loss = loss_function(pridect, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, pridect.detach().numpy().flatten(), 'b-')
plt.draw()
plt.pause(0.05)
plt.ioff()
plt.show()























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









