







2020_DARCN_A Recursive Network with Dynamic Attention for Monaural Speech Enhancement
论文地址:https://www.isca-speech.org/archive/interspeech_2020/li20x_interspeech.html
摘要:对于连续的语音处理,动态注意有助于优先处理,因此,我们提出了一个将动态注意力和递归学习结合在一起的框架,称为 DARCN,用于单声道语音增强。除了主要的降噪网络之外,我们还设计了一个分离的子网络,它自适应地生成注意力分布以控制整个主要网络的信息流。引入递归学习以通过在多个阶段重复使用网络来动态减少可训练参数的数量,其中每个阶段的中间输出使用记忆机制进行细化。通过这样做,可以获得更灵活和更好的估计,我们在 TIMIT 语料库上进行实验。实验结果表明,就 PESQ 和 STOI 分数而言,所提出的架构始终比最近最先进的模型获得更好的性能。
1.注意力门结构
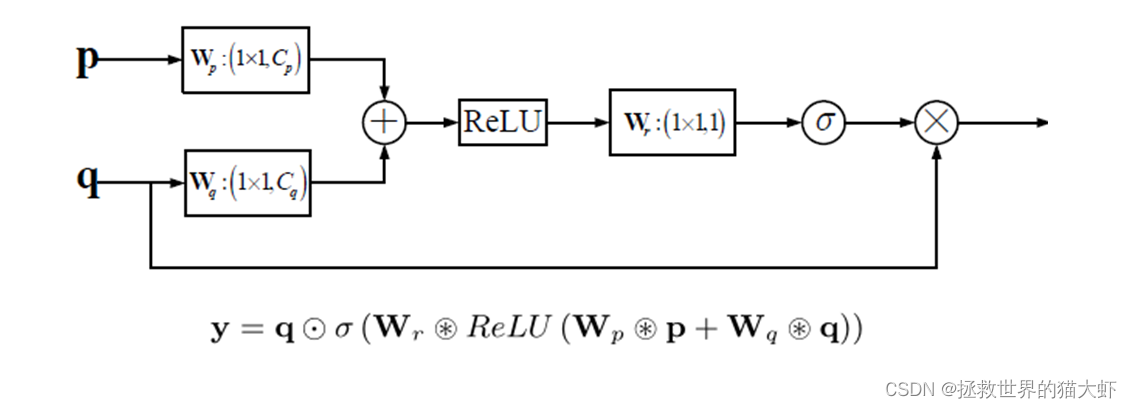
由于频谱中含有丰富的频率成分,低频区域常以共振峰为主,而高频区域分布稀疏,因此需要引入注意力机制来区分不同权重的频谱区域。
一个分支合并两个输入的信息并通过Sigmoid函数生成注意系数,另一个分支复制Q的信息并将系数相乘。在获得AG的输出后,将其与相应解码层沿信道维度的特征级联,作为下一解码层的输入。
2.门控循环单元GRU和门控线性单元GLU
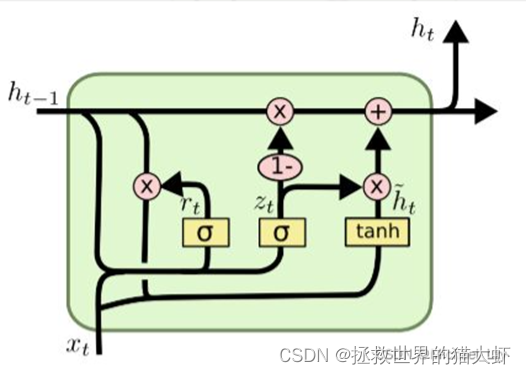
2.1GRU

2.2GLU
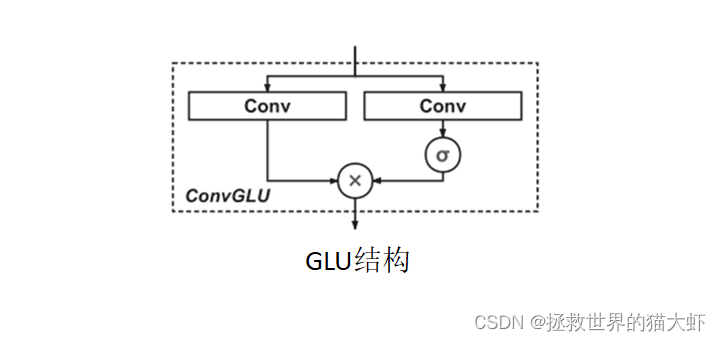
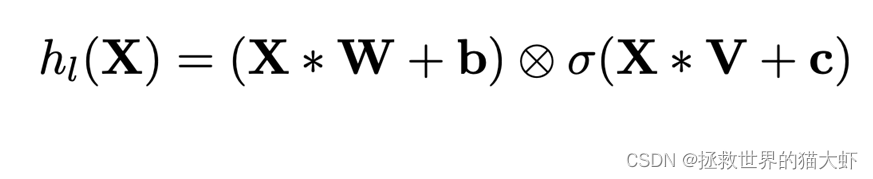
其主要结构跟原始的CNN并无很大差异,只不过在卷积层引入了门控机制,将卷积层的输出变成了上面的公式,即一个没有非线性函数的卷积层输出*经过sigmod非线性激活函数的卷积层输出。
本文使用六个串联 GLU 被设置为有效地探索上下文相关性。
3.激活函数
3.1ELU激活函数
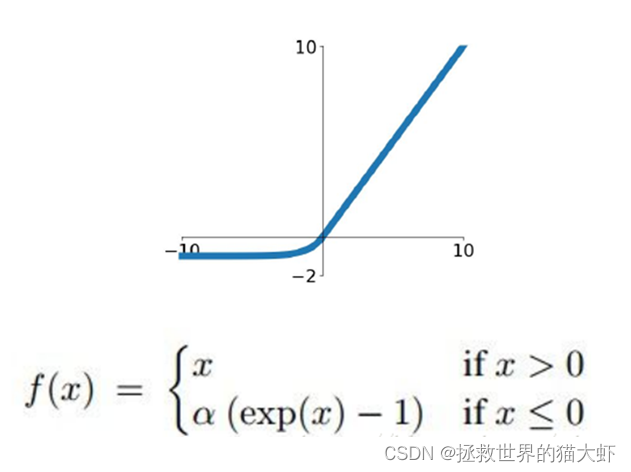
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。
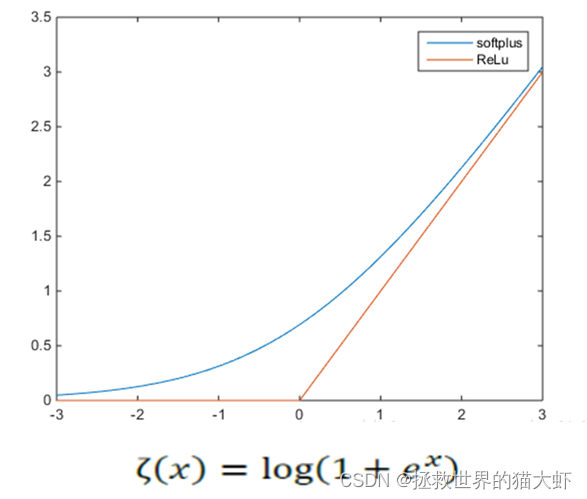
3.2softplus激活函数
4.整体网络架构
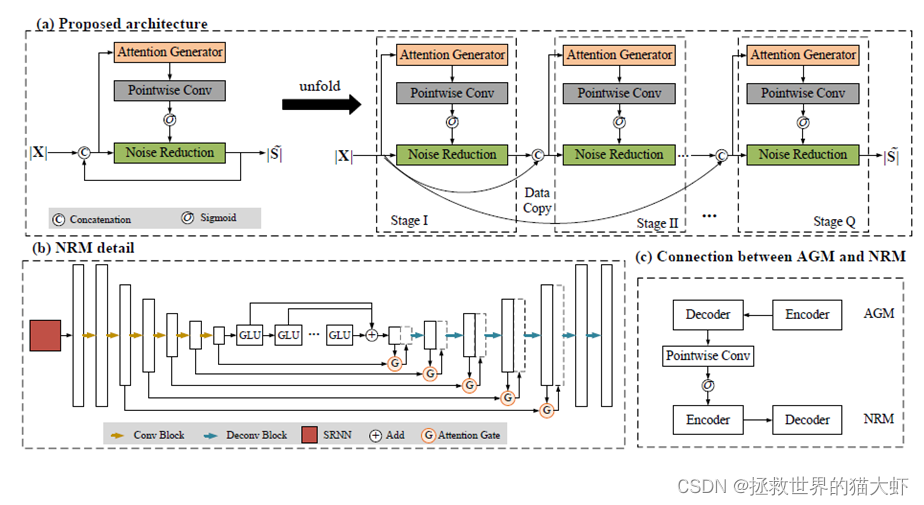
它有两个模块,即AGM(Attention Generator Module)和NRM(Noise Reduction Module),这两个模块被设计成在整个过程中交错执行。该体系结构采用递归过程操作,即整个前向流可以分成多个阶段展开。在每一级中,将原始噪声谱和最后一级的估计值连接起来,作为网络输入。它被发送到AGM,生成当前注意力集合,代表当前阶段的注意力分布。随后将其应用于NRM,以控制整个网络中的信息流。NRM也接收输入来估计幅度谱(Magniude Spectrum, MS)。因此,AGM的输出动态地影响了最后阶段对MS的估计,即AGM能够根据来自降噪系统的先前反馈来重新加权注意力分布。
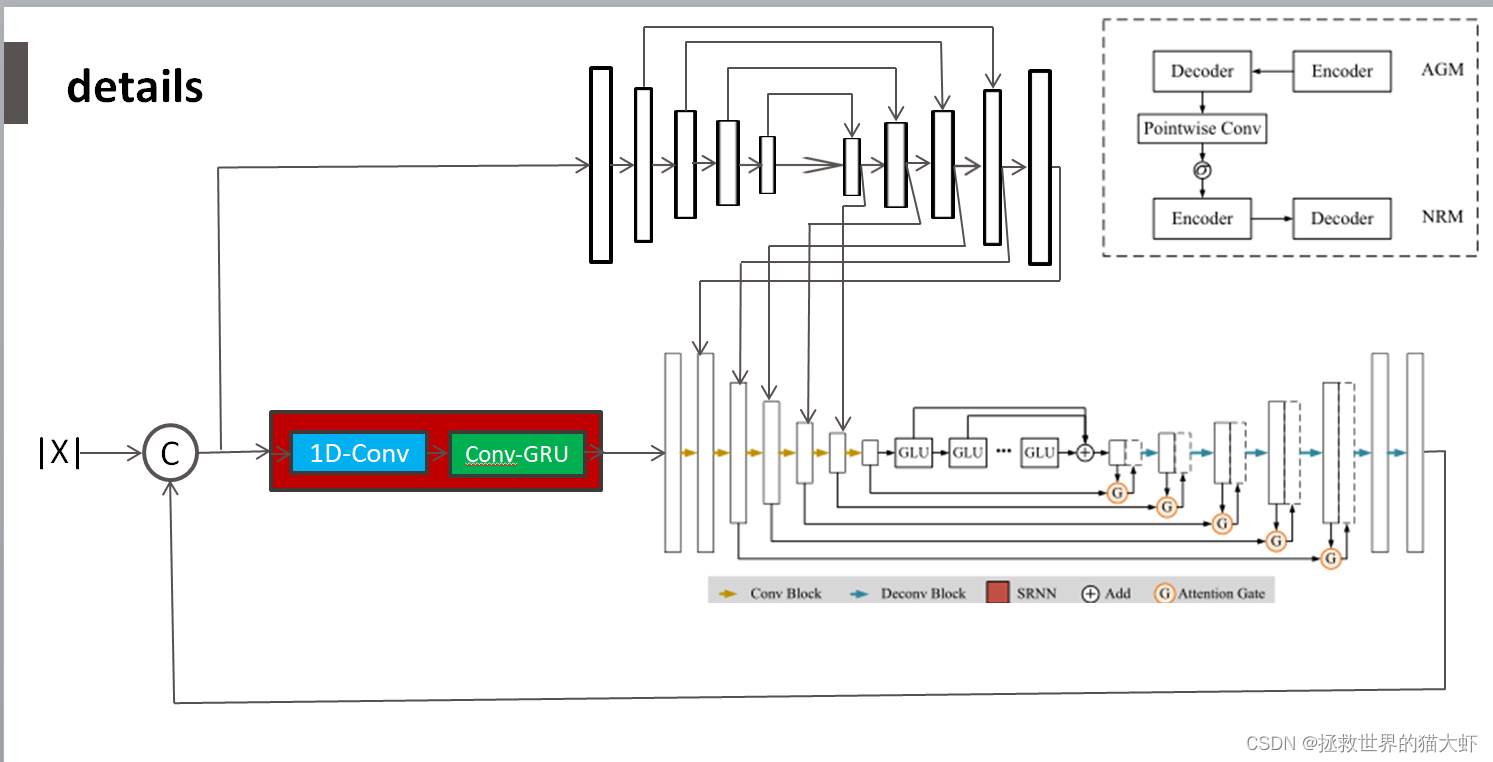
AGM模块:首先输入x为原始噪声幅度谱,与整个网络的输出(也就是NRM的输出)curr-x进行拼接 ,为了保证模型维度的一致,初始状态curr-x用原始噪声幅度谱代替(即两个x进行拼接)进入AGM模块,他是一个普通U-net模块(与图中NRM模块相比没有6个GLU门控线性单元和注意力门G),采用直接跳过连接,每层采用BN层+ELU激活函数,每层的输出att存入att-list[]列表。
NRM模块:拼接后的x进入GRU门控线性单元,GRU的初始隐藏状态h为0,通过GRU后得到h',对应att-list[]里att进行逐点卷积后再通过一个Sigmoid后与h'相乘,再通过BN+ELU激活函数,得到的每层输出存入x-list[]最后一个输出为x',这些是NRM的encoder部分。然后x'通过6个GLU得到x'',x''和x-list[]里对应x'进入注意力门G,得到X-out。X-out再与x''进行cat拼接,进入下一反卷积层,最后通过一个softplus层得到curr-x即估计幅度谱(MS)。
得到的curr-x再进入AGM模块,循环Q次
按照源码自己画了一下完整网络的框架
每层有一个BN+GLU激活函数
5.实验结果
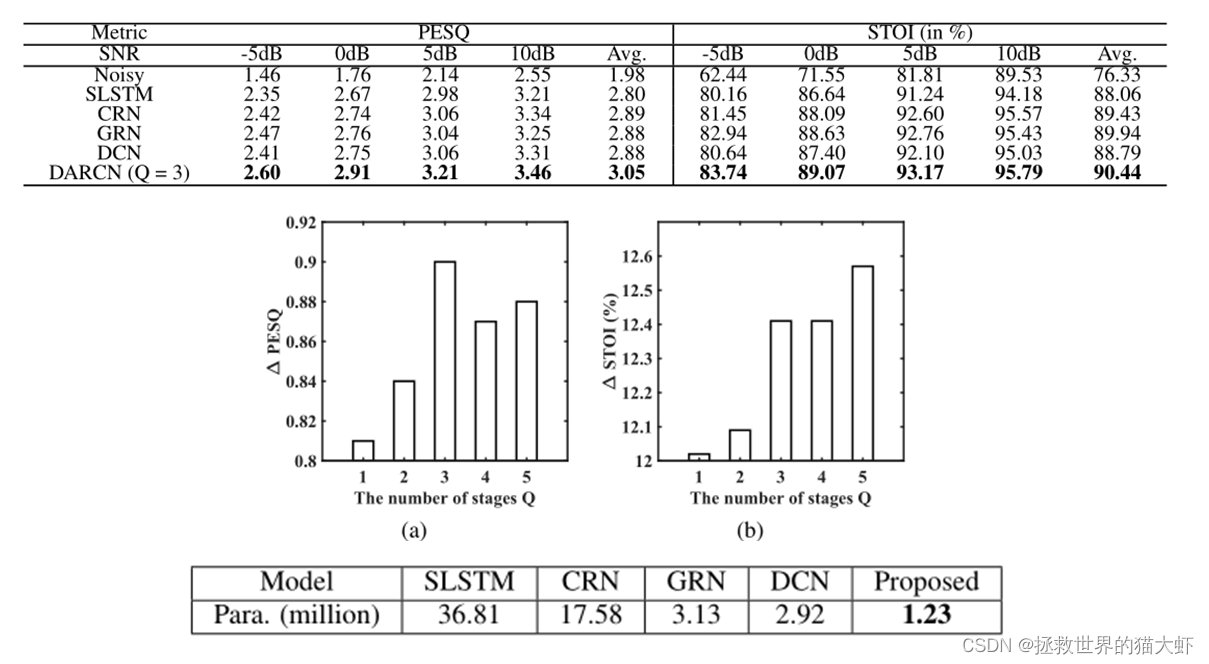
至于为什么是3个stage效果最好,我觉得随着阶数的增加,网络的性能提升不多,且网络容易饱和,因为每个stage都是共享参数,所以这么大型的网络有比较小的参数数量。
6.结论
在复杂的场景中,一个人通常会动态调整注意力以适应连续说话的环境变化。基于这种神经现象,我们提出了一个结合动态注意力和递归学习的框架。为了自适应地控制降噪网络的信息流,设计了一个单独的子网络来更新每个阶段的注意力表示,并随后应用于主网络。由于采用递归范式进行训练,因此网络可在多个阶段重复使用。结果,我们逐步实现了精细的估计。实验结果表明,与之前最先进的强模型相比,所提出的模型在进一步降低参数负担的同时实现了始终如一的更好性能。
(仅个人理解,如有错误请大佬指出)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









