






 AlexNet是2012年在NIPS上发表的开创性论文,它在ImageNet比赛中取得显著优势,引入了ReLU激活函数、Dropout正则化、数据增强等技术。网络结构包括5个卷积层和3个全连接层,展示了端到端学习的潜力,并利用两块GPU并行训练提高效率。这些创新对后续的深度学习模型发展产生了深远影响。
AlexNet是2012年在NIPS上发表的开创性论文,它在ImageNet比赛中取得显著优势,引入了ReLU激活函数、Dropout正则化、数据增强等技术。网络结构包括5个卷积层和3个全连接层,展示了端到端学习的潜力,并利用两块GPU并行训练提高效率。这些创新对后续的深度学习模型发展产生了深远影响。
AlexNet文章源于12年发表在NIPS的论文《ImageNet Classification with Deep Convolutional Neural Networks》(地址http://www.cs.toronto.edu/~hinton/absps/imagenet.pdf ),这个网络本身被应用图像分类比赛,取得第一名的成绩, 并且和第二名有较大差距。 文章本身更像是一篇工程性质的文章而非一篇介绍理论的文章,即告诉人们这么做效果好,但是没有探究为什么这么做。同时,也是传递了一种信息端到端(end to end)的思想,即像素到结论
和过往文章比较不同的点总结起来:
数据预处理:
对于不同图片大小,文章采用的是基于图像的短边缩小到256,长边按照比例缩小,假如长边大于256。就基于图像中心为界限把两边裁掉到标准输入大小
网络部分
假如输入图像大小为n*n,过滤器(filter)为长度a * a的矩阵,padding为p,步长(stride)为s
参考:https://blog.csdn.net/fengbingchun/article/details/80262495
(1).激活函数使用ReLU替代Tanh或Sigmoid加快训练速度,解决网络较深时梯度弥散问题。
关于ReLU介绍参考:https://blog.csdn.net/fengbingchun/article/details/73872828
(2).训练时使用Dropout在全连接层前面随机忽略一部分神经元(即随机把一些隐藏层输出变为0),防止过拟合。。这个现在看来是l2 正则项优化,但是这种方式其实是没办法直接构造出对应的l2正则项数值的
关于Dropout介绍参考:https://blog.csdn.net/fengbingchun/article/details/89286485
(3).使用重叠最大池化(Overlapping Max Pooling),避免平均池化时的模糊化效果;并且让步长比池化核的尺寸小,提升特征丰富性。filter的步长stride小于filter的width或height。一般,kernel(filter)的宽和高是相同的,深度(depth)是和通道数相同的。
(4).使用LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其它反馈较小的神经元,增强了模型泛化能力。LRN只对数据相邻区域做归一化处理,不改变数据的大小和维度。关于LRN介绍参考:https://blog.csdn.net/fengbingchun/article/details/112393884
(5).数据扩充(Data Augmentation):训练时从256256的原始数据中截取224224大小的区域
(6).多GPU并行运算。
(7).AlexNet输入是一种属于1000种不同类别的一张BGR图像,大小为224*224,输出是一个向量,大小为1000。输出向量的第i个元素值被解释为输入图像属于第i类的概率。因此,输出向量的所有元素的和为1。
论文分析
论文中的网络结构截图如下:
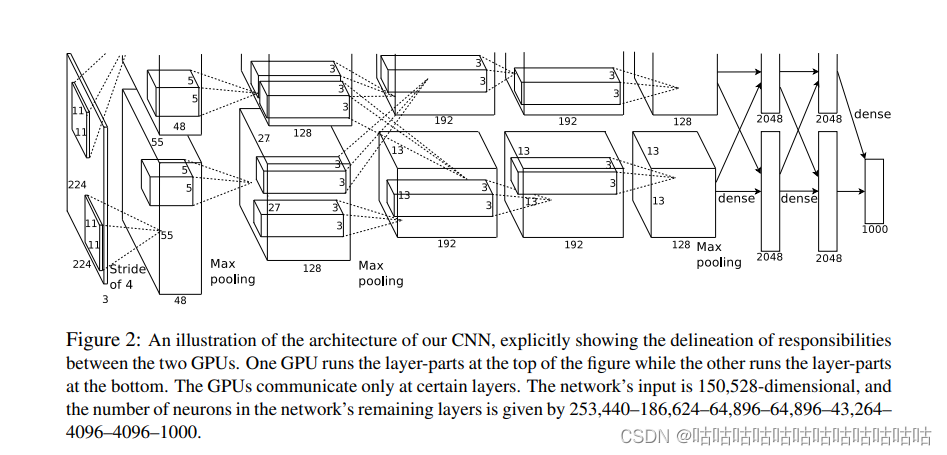
AlexNet架构:5个卷积层(Convolution、ReLU、LRN、Pooling)+3个全连接层(InnerProduct、ReLU、Dropout),predict时对各层进行说明:参照https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/deploy.prototxt
这个网络结构是一个从左到右,上下对称的网络结构。图的左侧是一张图片,rgb 3通道,通过不断的卷积,池化(就是提取模式信息,然后就行池化从低级信息提炼高级信息),最后对两块gpu上的信息进行全连接的最后走出分类。作者是通过两块gpu训练,在gpu上运行同样的代码和结构(核不一样),但是在某一些部分会进行通信连接上一层的信息(比如,在gpu 0上128通道那里,变为192通道的位置会去连接gpu 1 的在128通道卷积得到的信息),按找李沐的说法,这个算是特别工程上的实现细节,就算不用运行在两个gpu上也没关系。图的右侧则是1000类的概率向量。可以判断大概率属于什么
图上的是128通道是单卡,但是对于一整层而言是2*128 =256 通道
具体网络结构定义如下
(1).输入层(Input):图像大小2242243。如果输入的是灰度图,它需要将灰度图转换为BGR图。训练图大小需要为256256,否则需要进行缩放,然后从256256中随机剪切生成224*224大小的图像作为输入层的输入。
(2).卷积层1+ReLU+LRN:使用96个1111的filter,stride为4,padding为0,输出为555596,96个feature maps,训练参数(1111396)+96=34944。
(3).最大池化层:filter为33,stride为2,padding为0,输出为2727*96,96个feature maps。
(4).卷积层2+ReLU+LRN:使用256个55的filter,stride为1,padding为2,输出为2727256,256个feature maps,训练参数(5596256)+256=614656。
(5).最大池化层:filter为33,stride为2,padding为0,输出为1313*256,256个feature maps。
(6).卷积层3+ReLU:使用384个33的filter,stride为1,padding为1,输出为1313384,384个feature maps,训练参数(33256384)+384=885120。
(7).卷积层4+ReLU:使用384个33的filter,stride为1,padding为1,输出为1313384,384个feature maps,训练参数(33384384)+384=1327488。
(8).卷积层5+ReLU:使用256个33的filter,stride为1,padding为1,输出为1313256,256个feature maps,训练参数(33384256)+256=884992。
(9).最大池化层:filter为33,stride为2,padding为0,输出为66*256,256个feature maps。
(10).全连接层1+ReLU+Dropout:有4096个神经元,训练参数(66256)*4096=37748736。
(11).全连接层2+ReLU+Dropout:有4096个神经元,训练参数4096*4096=16777216。
(12).全连接层3:有1000个神经元,训练参数4096*1000=4096000。
(13).输出层(Softmax):输出识别结果,看它究竟是1000个可能类别中的哪一个。
讨论
1.文章观点现在来看哪些不对。去掉某一层卷积后性能下降,意味着深度很重要,但是假如去掉之后,接下来的层数有个较好的参数,那么其实这话有一定妥协的
2. 初始化偏移量为1,偶尔可以设置为2,比较玄学
3. 完整的数据级上训练,而不是比赛数据集,效果更好
4. 论文有提到:两块gpu上得到的通道参数不一样,所以意味着学到了不同的模式,至于为什么?算是一个可跟着做的点
5. 视频处理现在依然是一个很难的领域
小tips
组合模型不能发好文章
过于复杂的模型也不太会有一篇好文章
比较平滑的参数曲线

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









