






4.逻辑回归(Logistic Regression)
- 逻辑回归(Logistic Regression)是一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等。 注意,这里用的是“可能性”,而非数学上的“概率”,logisitc回归的结果并非数学定义中的概率值,不可以直接当做概率值来用。该结果往往用于和其他特征值加权求和,而非直接相乘。
2.那么逻辑回归与线性回归是什么关系呢?
逻辑回归(Logistic Regression)与线性回归(Linear Regression)都是一种广义线性模型(generalized linear model)。逻辑回归假设因变量 y 服从伯努利分布,而线性回归假设因变量 y 服从高斯分布。 因此与线性回归有很多相同之处,去除Sigmoid映射函数的话,逻辑回归算法就是一个线性回归。可以说,逻辑回归是以线性回归为理论支持的,但是逻辑回归通过Sigmoid函数引入了非线性因素,因此可以轻松处理0/1分类问题。
3.应用场景:
用于分类:适合做很多分类算法的基础组件。
用于预测:预测事件发生的概率(输出)。
用于分析:**单一因素对某一个事件发生的影响因素分析(特征参数值)。
信用评分
计算营销活动的成功率
预测某个产品的收入
特定的某一天是否会发生地震
4.逻辑回归表达式,由Sigmoid函数(又称逻辑函数)
5.决策边界(Decision Boundary)
决策边界,也称为决策面,是用于在N维空间**,将不同类别样本分开的平面或曲面。
注意:决策边界是假设函数的属性,由参数决定,而不是由数据集的特征决定。
6.优缺点
优点(7):
(模型)模型清晰,背后的概率推导经得住推敲。
(输出)输出值自然地落在0到1之间,并且有概率意义(逻辑回归的输出是概率么?https://www.jianshu.com/p/a8d6b40da0cf)。
(参数)参数代表每个特征对输出的影响,可解释性强。
(简单高效)实施简单,非常高效(计算量小、存储占用低),可以在大数据场景中使用。
(可扩展)可以使用online learning的方式更新轻松更新参数,不需要重新训练整个模型。
(过拟合)解决过拟合的方法很多,如L1、L2正则化。
(多重共线性)L2正则化就可以解决多重共线性问题。
缺点:
(特征相关情况)因为它本质上是一个线性的分类器,所以处理不好特征之间相关的情况。
(特征空间)特征空间很大时,性能不好。
(精度)容易欠拟合,精度不高。
与其他算法比较
逻辑回归
**回归:**一条直线对现有的一些数据点进行你个(该线称为最佳拟合直线),这个拟合的过程叫做回归。
**回归进行分类的主要思想:**根据现有数据对分类边界线建立回归公式,以此进行分类。
**回归:**表示找到最佳拟合的数据集。
**训练分类器的做法:**使用最优化算法,寻找最佳拟合参数。

5.1 基于Logistic 回归和Sigmoid分类
1.Logistic 回归
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
使用数据类型:数值型和标称型数据。
2.Sigmoid函数
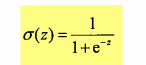
确定Logistic 回归分类器:在没个特征上乘一个回归系数,然后把所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0-1之间的数值。
5.2 基于最优化方法的最佳回归系数确定
Sigmoid函数输入z,是由以下公式得出:
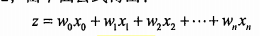
其中向量x是分类器的输入数据,向量w是最佳系数。
5.2.1 梯度上升法–求数据集的最佳参数
**基本思想:**找到某个函数的最大值,最好的方法是沿着函数的梯度方向探寻。
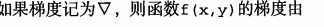
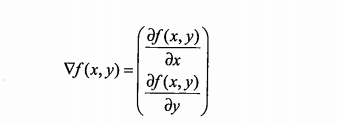
要求f(x,y)必须要在待计算的点上有定义且可微。
梯度的方向就是导数最大值的方向,即函数变化率最快的方向。因此,梯度方向可以通过对函数求导得到。
向梯度相反方向移动保证每一次迭代都在减少会下降到局部全局最小值。
梯度上升法求函数的最大值,梯度下降法求函数的最小值
5.2.2 训练算法:使用梯度上升找到最佳参数

5.2.3 分析数据:画出决策边界
5.2.4 训练算法:随机梯度上升
**梯度上升算法缺点:**每次更新回归系数都需要遍历整个数据集,导致计算复杂度高。
**改进:**一次仅用一个样本点来更新回归系数,称为随机梯度上升算法。

两者区别:
1.随机梯度上升的变量h和误差error都是向量,而前者全是数值;
2.前者没有矩阵转换过程,所有的数据类型都是numpy数组。
判断算法优劣的方法:
是否收敛,是否达到稳定值。
**对随机梯度上升改进:**加快收敛速度、避免来回波动。–改进的随机梯度上升算法。
5.4 本章小结
Logistic 回归目的:寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优算法完成。最常用的是梯度上升算法,又可简化为随机梯度上升算法。
随机梯度上升算法优点:占用更少资源,是一个在线算法,可以在数据到来时完成参数更新,而不需要读取整个数据集进行批量处理。
















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









