






前两次关于感知机学习规则方面的知识做了充足的铺垫,介绍了何为学习规则,对感知机进行了进一步的介绍。本次博客将真正的学习感知机学习规则。
1.感知机学习规则
由于其学习规则是有监督训练的实例,所以这里学习规则将提供一组能正确反应网络行为的实例:{P1,T1},{P2,T2},…{Pq,Tq}。
其中Pq是网络的输入,Tq是网络的目标输出。当每个输入作用到网络上时,网络的实际输出与目标比较。然后学习规则调整该网络的权值和偏置值,使得网络的实际输出进一步靠近目标输出。
(1).测试问题
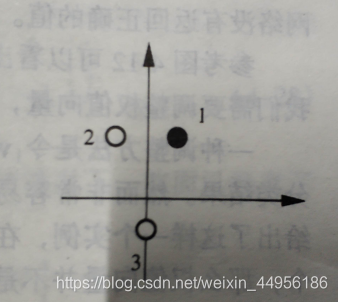
首先我们讨论一个简单的测试问题。在该测试问题中输入与目标输出如下:
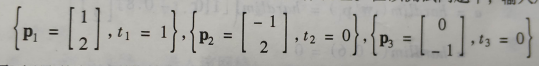
此问题可以用如图说明,更加直观。图中用空心圆表示目标输出为0,用黑色圆圈表示目标输出为1.。
 此问题相应的网络应该有两个输入和一个输出。为了简化其学习规则的开发,这里首先采用一种没有偏置值的网络。
此问题相应的网络应该有两个输入和一个输出。为了简化其学习规则的开发,这里首先采用一种没有偏置值的网络。
神经网络设计学习笔记(7)——感知机学习规则(3)
最新推荐文章于 2022-05-04 22:12:21 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









