









强化学习原理
- 1、基本概念
- 2、数学架构
- 3、核心目标与机制
- 4、分类
- 4、纯评论家、纯演员和演员-评论家
- 5、与其他学习范式的对比
- 6、论文汇总
- 7、附录
- 附录一:算法分类
- 附录二:算法分类
- 附录三:策略算法
1、基本概念
强化学习:目前比较主流的优化方式有 3 种:BON,DPO 和 PPO。
框架
概念定义
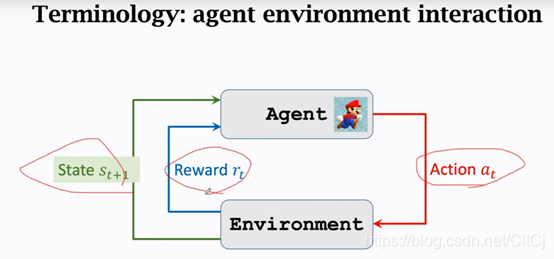
强化学习(Reinforcement learning,RL)讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的 环境(environment) 里面去极大化它能获得的奖励。通过感知所处环境的 状态(state) 对 动作(action) 的 反应(reward), 来指导更好的动作,从而获得最大的 收益(return),这被称为在交互中学习,这样的学习方法就被称作强化学习。
在强化学习过程中,智能体跟环境一直在交互。智能体在环境里面获取到状态,智能体会利用这个状态输出一个动作,一个决策。然后这个决策会放到环境之中去,环境会根据智能体采取的决策,输出下一个状态以及当前的这个决策得到的奖励。智能体的目的就是为了尽可能多地从环境中获取奖励。
- 目标:智能体(Agent)通过与环境(Environment)的交互,学习最优策略(Policy)以最大化长期累积奖励(Reward)。
- 交互循环:观察状态(State, S S S)→ 选择动作(Action, A A A)→ 获得奖励(Reward, R R R)→ 转移至新状态( S ′ S' S′),循环往复。
智能体(agent):操作对象
状态(state):环境状态,当前位置(当前时间t下的状态)
行为(action):下一步的活动
奖励(reward):当前状态,执行某下一个活动获得的奖励
策略(policy):根据所有活动的奖励,选择某个奖励值最高的活动(到达目标的步骤)
或者:
智能体 (Agent):在环境中执行动作的实体,例如游戏中的玩家。
环境 (Environment):智能体交互的外部世界,例如迷宫或棋盘游戏。
状态 (State):环境在某一时刻的描述,例如迷宫中的位置坐标。
动作 (Action):智能体在某一状态下可执行的操作,例如“向上移动”或“发射导弹”。
奖励 (Reward):环境对智能体动作的即时反馈,例如得分增加或扣减。
策略 (Policy):智能体选择动作的规则,可以是确定性(如“向右走”)或随机性(如“以80%概率向右”)。
示例:迷宫导航
状态:智能体所在的格子坐标(如(2,3))。
动作:上下左右移动。
奖励:到达终点+10,掉入陷阱-5,每移动一步-1。
目标:找到最短路径到达终点。
策略( Policy)和智能体(Agent) 看作一个整体
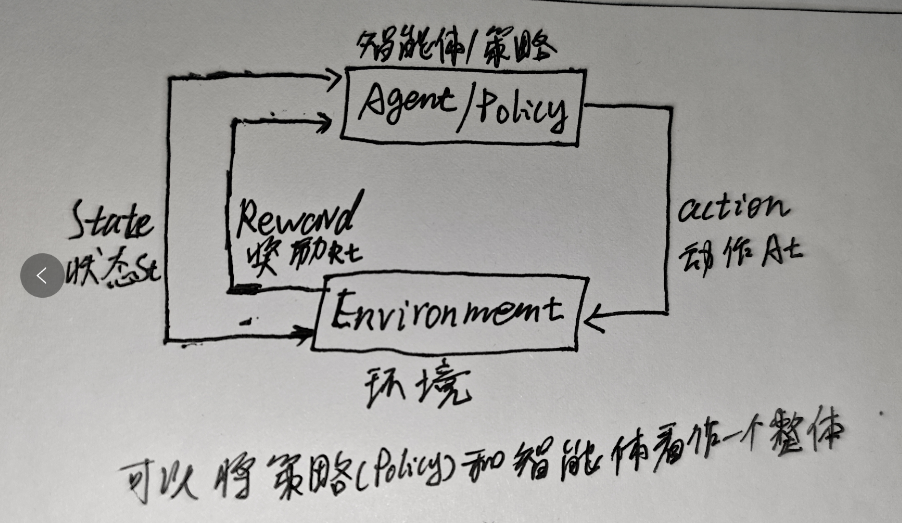
策略(policy)
下面一个概念policy记为 π函数,policy是什么意思呢就是我们观测到屏幕上这个画面的时候,你该让马里奥做什么样的action呢,是往上还是左还是右,policy的意思就是根据观测到的状态来进行决策,来控制agent运动。
在数学上policy函数π是这样定义的,这个policy函数π是个概率密度函数:
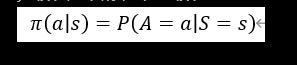 这个公式的意思就是给定状态s做出动作a的概率密度。
这个公式的意思就是给定状态s做出动作a的概率密度。


智能体的决策规则,定义从状态到动作的映射,分为:
- 确定性策略: a = π ( s ) a = \pi(s) a=π(s)(直接输出动作)。
- 随机性策略: π ( a ∣ s ) = P ( A = a ∣ S = s ) \pi(a|s) = P(A=a|S=s) π(a∣s)=P(A=a∣S=s)(输出动作概率分布)。
术语
-
定义
- 强化学习(Reinforcement Learning,RL)是智能体(agent)在环境(environment)中采取一系列行动(action),以最大化累积奖励(reward)的过程。与监督学习不同,强化学习没有给定的标记数据,智能体通过与环境的交互来学习最优策略(policy)。
-
智能体(Agent)
- 智能体是强化学习中的决策者。例如,在机器人导航任务中,机器人就是智能体。它根据环境反馈的信息来决定下一步的行动,如向前进、向左转等操作。
-
环境(Environment)
- 环境是智能体所处的外部世界。以游戏为例,在围棋游戏中,棋盘的布局、对手的棋子位置等构成了环境。环境会根据智能体的行动做出响应,改变自身的状态并给智能体相应的奖励信号。
-
状态(State)
- 状态是环境的当前情况的描述。在自动驾驶场景下,车辆周围其他车辆的位置、速度、交通信号灯的状态等都是状态的组成部分。例如,当车辆接近交叉路口,交通灯为红色,周围有其他车辆在等待时,这就是一种特定的状态。
-
动作(Action)
- 动作是智能体可以在环境中执行的操作。在机械臂操作任务中,机械臂的关节可以进行弯曲、伸直、旋转等动作。每个动作都会导致环境状态的改变。
-
奖励(Reward)
- 奖励是环境对智能体行动的反馈,用于引导智能体学习好的行为。奖励可以是正的(鼓励智能体重复类似行为)或负的(惩罚智能体的不良行为)。在推荐系统中,当用户点击推荐的内容时,系统可以给予一个正的奖励;如果用户对推荐内容完全没有反应,就可能给予负的奖励。
-
策略(Policy)
- 策略是智能体根据当前状态决定采取何种动作的规则。它可以是确定性的,例如,在某个状态下总是采取特定的动作;也可以是随机性的,以一定的概率分布选择不同的动作。比如在股票交易的强化学习场景中,策略可以是根据股票价格走势的状态,以一定的概率决定买入、卖出或者观望。
- 智能体的决策规则,定义从状态到动作的映射,分为:
- 确定性策略: a = π ( s ) a = \pi(s) a=π(s)(直接输出动作)。
- 随机性策略: π ( a ∣ s ) = P ( A = a ∣ S = s ) \pi(a|s) = P(A=a|S=s) π(a∣s)=P(A=a∣S=s)(输出动作概率分布)。
-
价值函数(Value Function)
- 价值函数用于评估某个状态的好坏程度。它是从该状态开始,按照当前策略继续执行下去所能获得的预期累积奖励。在游戏场景中,一个高价值的状态可能意味着智能体更有可能获胜。例如,在一款冒险游戏中,当智能体收集到很多道具,且距离宝藏很近时,这个状态的价值很高。
- 价值函数(Value Function)
- 评估状态或动作的长期价值,衡量未来累积奖励的期望:
- 状态价值函数 V π ( s ) V^\pi(s) Vπ(s):从状态 s s s 出发,遵循策略 π \pi π 时的累积奖励期望。
- 动作价值函数 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a):从状态 s s s 执行动作 a a a 后,遵循策略 π \pi π 时的累积奖励期望。
- 评估状态或动作的长期价值,衡量未来累积奖励的期望:
-
模型(Model)
- 在强化学习中,模型是对环境动态特性的描述。它能够预测在给定当前状态和动作的情况下,下一个状态和奖励是什么。例如,在模拟飞行器飞行的强化学习环境中,有一个模型可以计算飞行器在特定控制动作下(如改变飞行姿态、调整油门等)的位置、速度等状态变量的变化以及是否会受到奖励(如成功完成飞行任务)。
参考:
https://zhuanlan.zhihu.com/p/466455380
https://blog.csdn.net/CltCj/article/details/119445005
https://zhuanlan.zhihu.com/p/1897751434465899901
https://zhuanlan.zhihu.com/p/690597667
2、数学架构
1. 马尔可夫决策过程(MDP)


马尔可夫决策过程(MDP)
- 五元组
⟨
S
,
A
,
P
,
R
,
γ
⟩
\langle S, A, P, R, \gamma \rangle
⟨S,A,P,R,γ⟩,其中:
- P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a):状态转移概率(环境模型);
- R ( s , a , s ′ ) R(s,a,s') R(s,a,s′):即时奖励函数。
强化学习的数学框架,满足马尔可夫性:当前状态包含所有必要信息,未来与过去无关,即:
P
(
s
t
+
1
∣
s
t
,
a
t
,
s
t
−
1
,
a
t
−
1
,
…
)
=
P
(
s
t
+
1
∣
s
t
,
a
t
)
P(s_{t+1}|s_t, a_t, s_{t-1}, a_{t-1}, \dots) = P(s_{t+1}|s_t, a_t)
P(st+1∣st,at,st−1,at−1,…)=P(st+1∣st,at)
MDP由五元组
(
S
,
A
,
P
,
R
,
γ
)
(S, A, P, R, \gamma)
(S,A,P,R,γ)定义,其中:
- P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a):状态转移概率(如“在位置 ( 2 , 3 ) (2,3) (2,3)向左移动,有90%概率到 ( 1 , 3 ) (1,3) (1,3),10%概率撞墙停留在原地”);
- R ( s , a , s ′ ) R(s,a,s') R(s,a,s′):即时奖励(如从 s s s执行 a a a到 s ′ s' s′的奖励)。
- 举例:简化的MDP迷宫(无随机转移):每个位置执行动作后确定转移到下一个位置,奖励固定。
强化学习的数学基础,由五元组 ( S , A , P , R , γ ) (S, A, P, R, \gamma) (S,A,P,R,γ) 构成:
- 状态转移模型 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a):在状态 s s s 执行动作 a a a 后转移到状态 s ′ s' s′ 的概率。
- 折扣因子 γ \gamma γ:平衡即时奖励与未来奖励的重要性( γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1])。
- 应用实例:迷宫问题中,状态是位置,动作是移动方向,奖励根据是否到达目标或陷阱设定。
强化学习问题通常建模为马尔可夫决策过程(Markov Decision Process, MDP),包含以下要素:
- 状态空间(State Space):所有可能的状态集合。
- 动作空间(Action Space):所有可能的动作集合。
- 状态转移概率(Transition Probability):执行动作后状态转移的概率 P ( s ′ ∣ s , a ) P(s' | s, a) P(s′∣s,a)。
- 奖励函数(Reward Function): R ( s , a , s ′ ) R(s, a, s') R(s,a,s′) 表示在状态 s s s 执行动作 a a a 转移到 s ′ s' s′ 的即时奖励。
- 折扣因子(Discount Factor): γ ∈ [ 0 , 1 ] \gamma \in [0, 1] γ∈[0,1],用于平衡当前奖励与未来奖励的重要性。
2. 价值函数(Value Function)
- 状态价值函数
V
π
(
s
)
V^\pi(s)
Vπ(s):遵循策略
π
\pi
π 时,从状态
s
s
s 出发的期望回报,
V π ( s ) = E π [ G t ∣ s t = s ] = E π [ r t + 1 + γ V π ( s t + 1 ) ∣ s t = s ] V^\pi(s) = \mathbb{E}_\pi \left[ G_t \mid s_t = s \right] = \mathbb{E}_\pi \left[ r_{t+1} + \gamma V^\pi(s_{t+1}) \mid s_t = s \right] Vπ(s)=Eπ[Gt∣st=s]=Eπ[rt+1+γVπ(st+1)∣st=s] - 动作价值函数
Q
π
(
s
,
a
)
Q^\pi(s,a)
Qπ(s,a):遵循策略
π
\pi
π 时,从状态
s
s
s 执行动作
a
a
a 后的期望回报,
Q π ( s , a ) = E π [ r t + 1 + γ Q π ( s t + 1 , a t + 1 ) ∣ s t = s , a t = a ] Q^\pi(s,a) = \mathbb{E}_\pi \left[ r_{t+1} + \gamma Q^\pi(s_{t+1}, a_{t+1}) \mid s_t = s, a_t = a \right] Qπ(s,a)=Eπ[rt+1+γQπ(st+1,at+1)∣st=s,at=a]
3. 贝尔曼方程(Bellman Equation)
描述值函数的递推关系,是动态规划的基础
- 状态价值的贝尔曼方程:
V π ( s ) = ∑ a π ( a ∣ s ) [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V π ( s ′ ) ] V^\pi(s) = \sum_a \pi(a|s) \left[ R(s,a) + \gamma \sum_{s'} P(s'|s,a) V^\pi(s') \right] Vπ(s)=a∑π(a∣s)[R(s,a)+γs′∑P(s′∣s,a)Vπ(s′)] - 动作价值的贝尔曼方程:
Q π ( s , a ) = R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) ∑ a ′ π ( a ′ ∣ s ′ ) Q π ( s ′ , a ′ ) Q^\pi(s,a) = R(s,a) + \gamma \sum_{s'} P(s'|s,a) \sum_{a'} \pi(a'|s') Q^\pi(s', a') Qπ(s,a)=R(s,a)+γs′∑P(s′∣s,a)a′∑π(a′∣s′)Qπ(s′,a′)
4. 最优价值函数与最优策略
- 最优状态价值 V ∗ ( s ) V^*(s) V∗(s):所有策略中的最大状态价值, V ∗ ( s ) = max π V π ( s ) V^*(s) = \max_\pi V^\pi(s) V∗(s)=maxπVπ(s)。
- 最优动作价值 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a): Q ∗ ( s , a ) = max π Q π ( s , a ) Q^*(s,a) = \max_\pi Q^\pi(s,a) Q∗(s,a)=maxπQπ(s,a)。
- 最优策略 π ∗ \pi^* π∗:满足 π ∗ ( a ∣ s ) = 1 \pi^*(a|s) = 1 π∗(a∣s)=1 当且仅当 a = arg max a Q ∗ ( s , a ) a = \arg\max_a Q^*(s,a) a=argmaxaQ∗(s,a)(确定性)或选择最优动作概率为1(随机性)。
3、核心目标与机制
1. 优化目标:最大化累积奖励
- 智能体通过与环境交互(试错学习),调整策略以最大化长期奖励总和。累积奖励通常通过**折扣因子(Discount Factor,
γ
∈
[
0
,
1
]
\gamma \in [0,1]
γ∈[0,1])**计算:
G t = r t + 1 + γ r t + 2 + γ 2 r t + 3 + ⋯ = ∑ k = 0 ∞ γ k r t + k + 1 G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \dots = \sum_{k=0}^\infty \gamma^k r_{t+k+1} Gt=rt+1+γrt+2+γ2rt+3+⋯=k=0∑∞γkrt+k+1
γ = 0 \gamma=0 γ=0 关注即时奖励, γ = 1 \gamma=1 γ=1 关注所有未来奖励。
2. 策略(Policy)
策略是从状态到动作的映射规则,可以是确定性(如直接选择最优动作)或随机性(如按概率分布选择)。
注意:策略(Policy)和策略梯度方法(policy gradient)不是同个东西,价值函数和策略梯度都是为了寻找最优策略

3. 价值函数方法(Value Function)
• 状态价值函数
V
(
s
)
V(s)
V(s):评估从状态
s
s
s 开始的长期预期回报。
• 动作价值函数
Q
(
s
,
a
)
Q(s,a)
Q(s,a):评估在状态
s
s
s 执行动作
a
a
a 的长期价值,Q-learning等算法通过迭代更新Q表学习最优策略。
• 实例:在跳棋程序中,通过比较当前与下一步棋局的评分差异更新策略(隐含时序差分思想)。
4. 策略梯度方法(policy gradient)
与基于价值的方法不同,策略梯度方法直接参数化策略
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s),通过调整参数
θ
\theta
θ 最大化期望回报。目标函数定义:
策略
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s) 是一个由参数
θ
\theta
θ 决定的概率分布,表示在状态
s
s
s 下选择动作
a
a
a 的概率。目标函数
J
(
θ
)
J(\theta)
J(θ) 定义为:
J
(
θ
)
=
E
τ
∼
π
θ
[
R
(
τ
)
]
J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(\tau) \right]
J(θ)=Eτ∼πθ[R(τ)]
其中
τ
=
(
s
0
,
a
0
,
s
1
,
a
1
,
…
)
\tau = (s_0, a_0, s_1, a_1, \dots)
τ=(s0,a0,s1,a1,…) 是轨迹,
R
(
τ
)
=
∑
t
=
0
T
γ
t
r
t
R(\tau) = \sum_{t=0}^T \gamma^t r_t
R(τ)=∑t=0Tγtrt 是折扣累积回报,
γ
∈
[
0
,
1
]
\gamma \in [0,1]
γ∈[0,1] 是折扣因子 。
强化学习: 优化目标、价值函数、策略梯度方法,它们之间的联系与区别
1.优化目标:最大化累积奖励为最终优化目标,价值函数和策略梯度是实现这一目标的手段。
2. 价值函数和策略梯度(优化目标)
- 价值函数(优化目标):价值函数衡量
“状态”或“状态-动作对”的长期价值,分为状态价值函数 V π ( s ) V^\pi(s) Vπ(s) 和 动作价值函数 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a)。- 状态价值函数
V
π
(
s
)
V^\pi(s)
Vπ(s):表示在状态
s
s
s 下,遵循策略
π
\pi
π 的期望回报。
V π ( s ) = E π [ G t ∣ S t = s ] V^\pi(s) = \mathbb{E}_\pi \left[ G_t \mid S_t = s \right] Vπ(s)=Eπ[Gt∣St=s] - 动作价值函数
Q
π
(
s
,
a
)
Q^\pi(s, a)
Qπ(s,a):表示在状态
s
s
s 下执行动作
a
a
a,之后遵循策略
π
\pi
π 的期望回报。
Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] Q^\pi(s, a) = \mathbb{E}_\pi \left[ G_t \mid S_t = s, A_t = a \right] Qπ(s,a)=Eπ[Gt∣St=s,At=a] - 最优价值函数(Optimal Value Function)
当智能体找到最优策略 π ∗ \pi^* π∗ 时,对应最优价值函数:
V ∗ ( s ) = max π V π ( s ) , Q ∗ ( s , a ) = max π Q π ( s , a ) V^*(s) = \max_\pi V^\pi(s), \quad Q^*(s,a) = \max_\pi Q^\pi(s,a) V∗(s)=πmaxVπ(s),Q∗(s,a)=πmaxQπ(s,a)
通过最优价值函数寻找最优策略,先学习值函数然后从中导出策略,间接优化策略(如选择价值最高的动作),属于“间接法
- 状态价值函数
V
π
(
s
)
V^\pi(s)
Vπ(s):表示在状态
s
s
s 下,遵循策略
π
\pi
π 的期望回报。
- 策略梯度(优化目标):
目标函数定义:策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 是一个由参数 θ \theta θ 决定的概率分布,表示在状态 s s s 下选择动作 a a a 的概率。目标函数 J ( θ ) J(\theta) J(θ) 定义为:
J ( θ ) = E τ ∼ π θ [ R ( τ ) ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(\tau) \right] J(θ)=Eτ∼πθ[R(τ)]
其中 τ = ( s 0 , a 0 , s 1 , a 1 , … ) \tau = (s_0, a_0, s_1, a_1, \dots) τ=(s0,a0,s1,a1,…) 是轨迹, R ( τ ) = ∑ t = 0 T γ t r t R(\tau) = \sum_{t=0}^T \gamma^t r_t R(τ)=∑t=0Tγtrt 是折扣累积回报, γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1] 是折扣因子 。
策略梯度方法是一类强化学习算法,其核心思想是直接在策略空间中搜索最优策略,而不是先学习值函数然后从中导出策略。这些算法通过优化参数化的策略函数(通常是一个神经网络),使得期望的累积奖励最大化。
具体来讲在深度强化中(我们现在使用的强化学习算法都是深度强化学习)策略π \pi π就是一个神经网络,神经网络的参数是θ \theta θ。参考:链接
- 价值函数和策略梯度区别:显式 vs. 隐式策略
4、分类
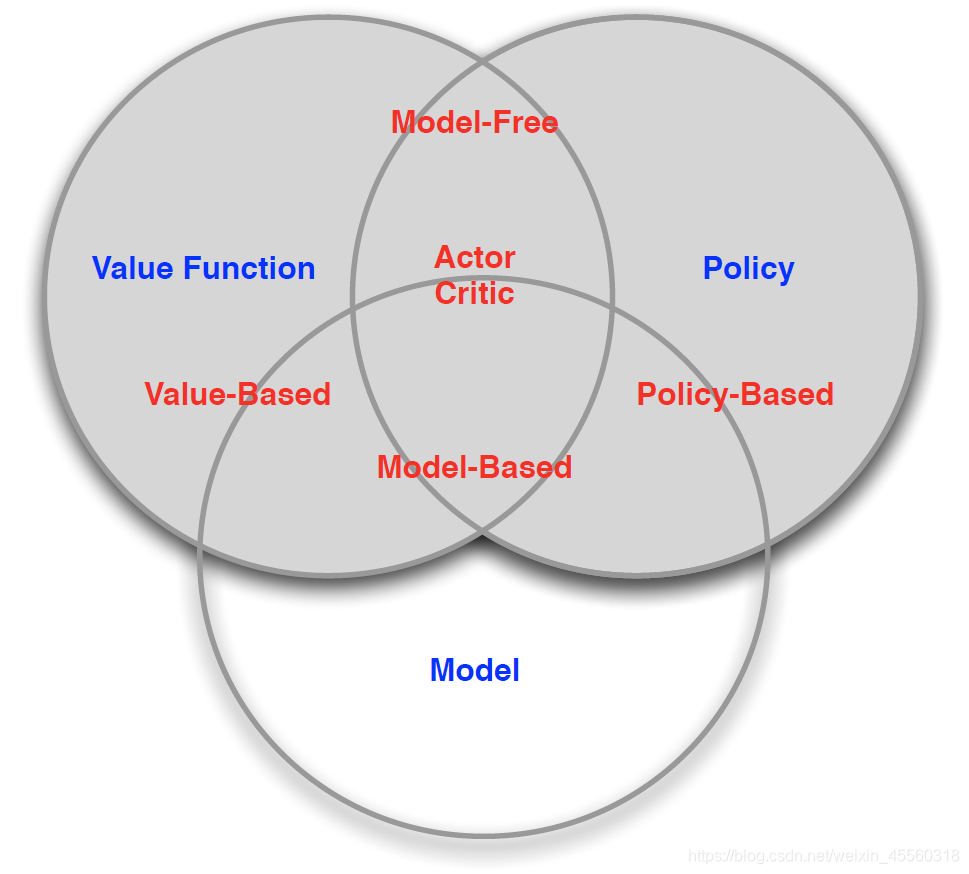
1.基本分类
https://blog.csdn.net/weixin_45560318/article/details/112981006
强化学习的基本问题按照两种原则进行分类。
- 基于策略和价值的分类,分为三类:
- 基于价值的方法(Value Based):没有策略但是有价值函数
- 基于策略的方法(Policy Based):有策略但是没有价值函数
- 参与评价方法(Actor Critic):既有策略也有价值函数
- 基于环境的分类,分为两类:
- 无模型的方法(Model Free):有策略和价值函数,没有模型
- 基于模型的方法(Model Based):有策略和价值函数,也有模型
(1)按学习方式分类
- 基于价值(Value-Based):学习价值函数(如Q-learning、Sarsa),间接优化策略。
- 基于策略(Policy-Based):直接优化策略函数(如策略梯度算法)。
- Actor-Critic:结合两者,同时学习策略(Actor)和价值函数(Critic)(如A3C、PPO)。
(2)按环境模型分类
- 模型无关(Model-Free):不学习环境动态模型,直接通过交互学习(如Q-learning、强化学习经典算法)。
- 模型相关(Model-Based):先学习环境模型(状态转移和奖励函数),再规划策略(如基于模型的规划算法)。
2.核心算法分类
价值和策略
(1)Q-learning,Sarsa,DQN:这些输出是状态动作的值,根据值的大小选择适当的动作。
(2)policy gradient :输出直接是动作或者每个动作的概率,根据概率选择适当的动作。
1. 价值-based方法(学习价值函数,间接求策略)
- 核心思想:通过估计 V ( s ) V(s) V(s) 或 Q ( s , a ) Q(s,a) Q(s,a),推导最优策略(如贪心策略)。
- 状态价值函数 V π ( s ) V^\pi(s) Vπ(s):从状态 s s s 出发,遵循策略 π \pi π 的期望回报, V π ( s ) = E π [ G t ∣ s t = s ] V^\pi(s) = \mathbb{E}_\pi[G_t | s_t = s] Vπ(s)=Eπ[Gt∣st=s]。
- 动作价值函数 Q π ( s , a ) Q^\pi(s, a) Qπ(s,a):在状态 s s s 执行动作 a a a 后,遵循策略 π \pi π 的期望回报, Q π ( s , a ) = E π [ G t ∣ s t = s , a t = a ] Q^\pi(s, a) = \mathbb{E}_\pi[G_t | s_t = s, a_t = a] Qπ(s,a)=Eπ[Gt∣st=s,at=a]。
经典算法
-
动态规划(DP):基于模型,直接求解贝尔曼方程(如策略迭代、价值迭代)。
-
蒙特卡洛方法(MC):无模型,通过采样轨迹计算平均回报(如首次访问MC、每次访问MC)。
-
时间差分学习(TD):结合DP和MC,利用引导(Bootstrapping)更新价值(如TD(0)、TD( λ \lambda λ))。
-
Q-learning:离线策略(Off-Policy),学习最优动作价值函数 Q ∗ ( s , a ) = E [ R + γ max a ′ Q ( s ′ , a ′ ) ∣ s , a ] Q^*(s, a) = \mathbb{E}[R + \gamma \max_{a'} Q(s', a') | s, a] Q∗(s,a)=E[R+γmaxa′Q(s′,a′)∣s,a]。
-
Sarsa:在线策略(On-Policy),更新当前策略的 Q ( s , a ) = E [ R + γ Q ( s ′ , a ′ ) ∣ s , a , a ′ ] Q(s, a) = \mathbb{E}[R + \gamma Q(s', a') | s, a, a'] Q(s,a)=E[R+γQ(s′,a′)∣s,a,a′]。
-
Q-Learning:通过更新Q表学习最优动作价值函数 (Q^*(s,a)),适用于离散动作空间。
-
DQN(Deep Q-Network):用深度神经网络近似Q值,处理高维状态(如图像输入),改进版包括Double DQN(缓解高估)和Dueling DQN(分解状态价值与优势)。
(1)动态规划(DP,已知环境模型)
- 策略评估(Policy Evaluation):迭代求解贝尔曼方程 V k + 1 ( s ) = ∑ a π ( a ∣ s ) [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V k ( s ′ ) ] V_{k+1}(s) = \sum_a \pi(a|s) \left[ R(s,a) + \gamma \sum_{s'} P(s'|s,a) V_k(s') \right] Vk+1(s)=∑aπ(a∣s)[R(s,a)+γ∑s′P(s′∣s,a)Vk(s′)]。
- 策略提升(Policy Improvement):基于当前 V ( s ) V(s) V(s) 生成新策略 π ′ ( a ∣ s ) = arg max a [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V ( s ′ ) ] \pi'(a|s) = \arg\max_a \left[ R(s,a) + \gamma \sum_{s'} P(s'|s,a) V(s') \right] π′(a∣s)=argmaxa[R(s,a)+γ∑s′P(s′∣s,a)V(s′)]。
- 策略迭代(Policy Iteration):策略评估 + 策略提升交替进行,直至收敛。
- 值迭代(Value Iteration):直接迭代最优贝尔曼方程 V k + 1 ( s ) = max a [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V k ( s ′ ) ] V_{k+1}(s) = \max_a \left[ R(s,a) + \gamma \sum_{s'} P(s'|s,a) V_k(s') \right] Vk+1(s)=maxa[R(s,a)+γ∑s′P(s′∣s,a)Vk(s′)]。
(2)时间差分学习(TD,模型未知,在线学习)
- TD(0):用下一状态的估计值
V
(
s
′
)
V(s')
V(s′) 更新当前状态价值,
V ( s t ) ← V ( s t ) + α [ r t + 1 + γ V ( s t + 1 ) − V ( s t ) ] V(s_t) \leftarrow V(s_t) + \alpha \left[ r_{t+1} + \gamma V(s_{t+1}) - V(s_t) \right] V(st)←V(st)+α[rt+1+γV(st+1)−V(st)]
其中 α \alpha α 为学习率。 - SARSA:基于当前策略采样
(
s
t
,
a
t
,
r
t
+
1
,
s
t
+
1
,
a
t
+
1
)
(s_t, a_t, r_{t+1}, s_{t+1}, a_{t+1})
(st,at,rt+1,st+1,at+1),更新
Q
(
s
t
,
a
t
)
Q(s_t, a_t)
Q(st,at),
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + 1 + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_{t+1} + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t) \right] Q(st,at)←Q(st,at)+α[rt+1+γQ(st+1,at+1)−Q(st,at)]
属于**在线策略(On-Policy)**算法。 - Q-learning:用最优动作
max
a
Q
(
s
t
+
1
,
a
)
\max_a Q(s_{t+1}, a)
maxaQ(st+1,a) 替代下一动作,更新
Q
(
s
t
,
a
t
)
Q(s_t, a_t)
Q(st,at),
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + 1 + γ max a Q ( s t + 1 , a ) − Q ( s t , a t ) ] Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_{t+1} + \gamma \max_a Q(s_{t+1}, a) - Q(s_t, a_t) \right] Q(st,at)←Q(st,at)+α[rt+1+γamaxQ(st+1,a)−Q(st,at)]
属于**离线策略(Off-Policy)**算法。
(3)深度强化学习(DRL,处理高维状态)
- DQN(Deep Q-Network):用神经网络近似
Q
(
s
,
a
)
Q(s,a)
Q(s,a),引入**经验回放(Experience Replay)和目标网络(Target Network)**稳定训练,
损失函数 = E [ ( y − Q ( s , a ; θ ) ) 2 ] , y = r + γ max a ′ Q ( s ′ ; θ − ) \text{损失函数} = \mathbb{E} \left[ \left( y - Q(s,a; \theta) \right)^2 \right], \quad y = r + \gamma \max_{a'} Q(s'; \theta^-) 损失函数=E[(y−Q(s,a;θ))2],y=r+γa′maxQ(s′;θ−)
其中 θ − \theta^- θ− 为目标网络参数(定期更新)。 - 变种:
- Double DQN:用当前网络选动作,目标网络评估价值,缓解过估计问题;
- Dueling DQN:分离状态价值和动作优势函数,提升样本效率;
- Rainbow DQN:融合多种改进技术(优先级回放、噪声网络等)。
2. 策略-based方法(直接学习策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s)
- 核心思想:参数化策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s),通过梯度上升最大化期望回报。
代表性算法:
- REINFORCE:蒙特卡洛策略梯度,利用回报 R t R_t Rt 作为梯度估计,公式为 ∇ θ log π ( a t ∣ s t ; θ ) ⋅ R t \nabla_\theta \log \pi(a_t|s_t;\theta) \cdot R_t ∇θlogπ(at∣st;θ)⋅Rt。
- 信任区域策略优化(TRPO, Trust Region Policy Optimization):通过约束策略更新步长(KL散度)保证单调改进,稳定性强但计算复杂。
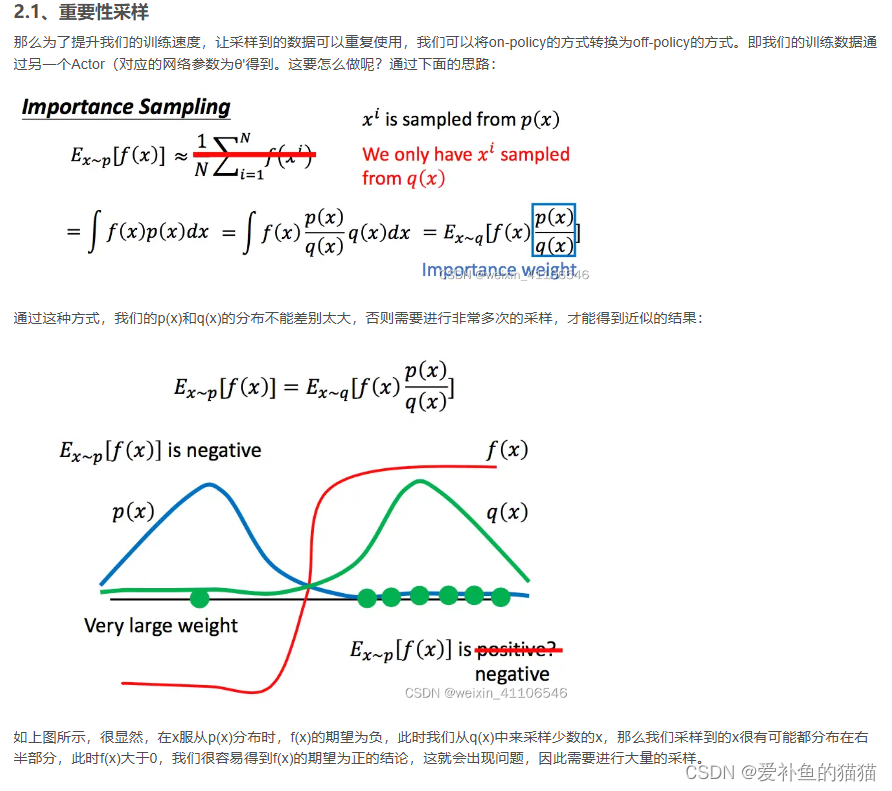
- 近端策略优化(PPO, Proximal Policy Optimization):TRPO 的简化版,用截断重要性采样(Clipped Importance Sampling)替代约束,易实现且广泛应用。
- 随机策略梯度(SPG, Stochastic Policy Gradient):通用框架,梯度基于期望回报的微分 ∇ θ E π θ [ R ] \nabla_\theta \mathbb{E}_{\pi_\theta}[R] ∇θEπθ[R]
(1)策略梯度(Policy Gradient, PG)
- 目标函数:
- 起始状态分布: J ( θ ) = V π θ ( s 0 ) J(\theta) = V^{\pi_\theta}(s_0) J(θ)=Vπθ(s0);
- 平均奖励(连续任务): J ( θ ) = E s ∼ ρ π , a ∼ π θ [ R ( s , a ) ] J(\theta) = \mathbb{E}_{s \sim \rho^\pi, a \sim \pi_\theta} [R(s,a)] J(θ)=Es∼ρπ,a∼πθ[R(s,a)]。
- 策略梯度定理:
∇ θ J ( θ ) = E π θ [ ∇ θ log π θ ( a ∣ s ) ⋅ Q π θ ( s , a ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\pi_\theta} \left[ \nabla_\theta \log \pi_\theta(a|s) \cdot Q^{\pi_\theta}(s,a) \right] ∇θJ(θ)=Eπθ[∇θlogπθ(a∣s)⋅Qπθ(s,a)]
即梯度为策略对数的导数乘以动作价值。
(2)REINFORCE算法(蒙特卡洛策略梯度)
- REINFORCE算法(蒙特卡洛策略梯度):用实际回报
G
t
G_t
Gt 替代
Q
π
θ
(
s
t
,
a
t
)
Q^{\pi_\theta}(s_t, a_t)
Qπθ(st,at),
∇ θ J ( θ ) ≈ ∑ t ∇ θ log π θ ( a t ∣ s t ) ⋅ G t \nabla_\theta J(\theta) \approx \sum_t \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t ∇θJ(θ)≈t∑∇θlogπθ(at∣st)⋅Gt
方差高,需引入基线(Baseline, 如 V ( s t ) V(s_t) V(st))减少方差。
3、Actor-Critic方法(结合价值与策略)
- Actor:策略网络 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s),输出动作;
- Critic:价值网络 V ( s ) V(s) V(s) 或 Q ( s , a ) Q(s,a) Q(s,a),评估动作好坏(优势函数 A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s,a) = Q^\pi(s,a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)−Vπ(s))。
- 梯度公式:
∇ θ J ( θ ) = E π θ [ ∇ θ log π θ ( a ∣ s ) ⋅ A π ( s , a ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\pi_\theta} \left[ \nabla_\theta \log \pi_\theta(a|s) \cdot A^\pi(s,a) \right] ∇θJ(θ)=Eπθ[∇θlogπθ(a∣s)⋅Aπ(s,a)] - 经典算法:
-
Actor-Critic(AC):结合策略网络(Actor)和价值网络(Critic),用Critic估计优势函数 A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)。
-
A2C(Advantage Actor-Critic):同步更新Actor和Critic,降低方差;
-
A3C(Asynchronous A3C):异步分布式训练,提升效率;
-
DDPG(Deep Deterministic Policy Gradient):处理连续动作,Critic估计 Q ( s , a ) Q(s,a) Q(s,a),Actor用确定性策略 a = μ ( s ; θ ) a = \mu(s; \theta) a=μ(s;θ),结合DQN的经验回放和目标网络;
-
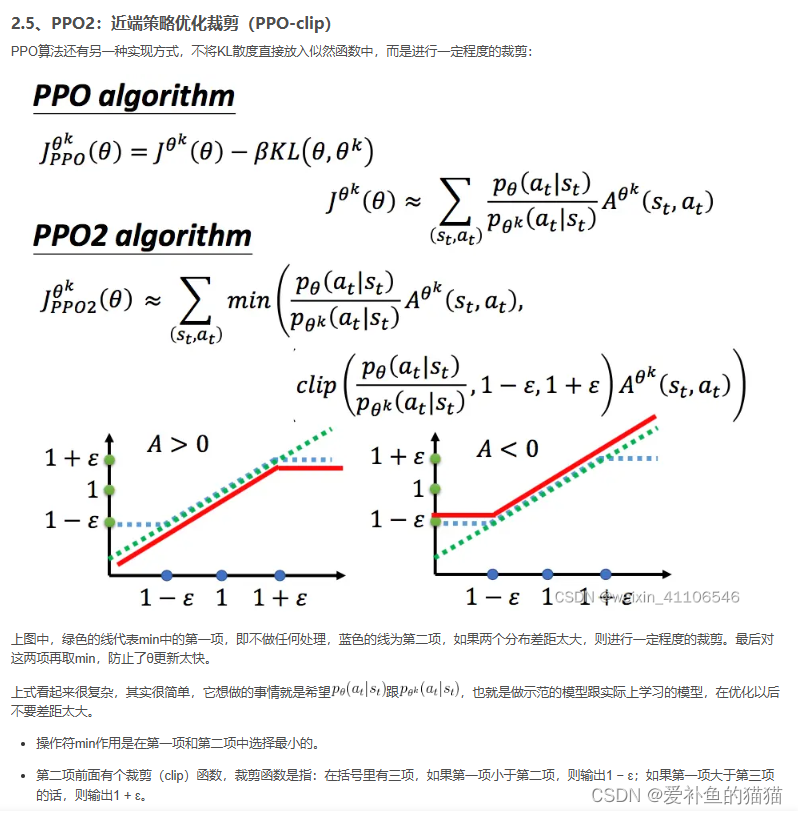
PPO(Proximal Policy Optimization):通过信任区域(Trust Region)限制策略更新幅度,用重要性采样处理离线数据,
目标函数 = E [ min ( r t ( θ ) ⋅ A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) ⋅ A ^ t ) ] \text{目标函数} = \mathbb{E} \left[ \min \left( r_t(\theta) \cdot \hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \cdot \hat{A}_t \right) \right] 目标函数=E[min(rt(θ)⋅A^t,clip(rt(θ),1−ϵ,1+ϵ)⋅A^t)]
其中 r t ( θ ) = π θ ( a t ∣ s t ) / π θ old ( a t ∣ s t ) r_t(\theta) = \pi_\theta(a_t|s_t) / \pi_{\theta_{\text{old}}}(a_t|s_t) rt(θ)=πθ(at∣st)/πθold(at∣st), A ^ t \hat{A}_t A^t 为优势估计。 -
SAC 软演员-评论家(SAC, Soft Actor-Critic):最大化熵正则化的期望回报,学习随机策略,具有良好的探索性和收敛性,适合连续动作场景。
-
4. 模型-based方法(学习环境模型,辅助规划)
- 核心思想:先学习环境动态 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a) 和奖励模型 R ( s , a ) R(s,a) R(s,a),再用规划(如DP)优化策略。
- 算法:
- Dyna:结合模型学习和无模型学习(如Q-learning);
- Model-Predictive RL:基于模型预测未来状态,优化短期策略。
(1)基于模型(Model-Based)
- 特点:依赖对环境的动态模型(状态转移概率和奖励函数)的显式建模。
- 典型算法:
- 动态规划(DP):如值迭代(Value Iteration)、策略迭代(Policy Iteration)。
- Dyna-Q:结合模型学习与无模型学习。
- 蒙特卡洛树搜索(MCTS):如AlphaGo中的树搜索策略。
- 核心思想:显式学习环境模型(状态转移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a) 和奖励函数 r ( s , a ) r(s,a) r(s,a)),通过模型规划未来动作。
- 典型算法:
- 动态规划(Dynamic Programming, DP):策略迭代、价值迭代
- 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)
- 基于模型的策略优化(Model-Based Policy Optimization, MBPO)
- 特点:利用模型预测减少真实环境交互,但模型误差可能导致性能下降。
(2)无模型(Model-Free)
-
特点:不显式建模环境,直接通过交互经验学习策略或价值函数。
-
典型算法:
- Q-Learning、SARSA(基于价值)。
- REINFORCE、PPO(基于策略)。
- Actor-Critic(混合策略与价值)。
-
核心思想:不直接学习环境模型,通过与环境交互数据估计价值函数或策略。
-
典型算法:
- 价值迭代类:Q-learning、SARSA
- 深度强化学习:DQN及其变种(Double DQN、Dueling DQN、Rainbow等)
- 策略梯度类:REINFORCE、TRPO、PPO
- Actor-Critic类:A3C、DDPG、SAC
-
特点:依赖大量数据,适用于复杂环境(如游戏、机器人控制),但样本效率较低。
1. 基于模型的强化学习(Model-Based RL)
核心思想:显式学习环境模型(状态转移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a) 和奖励函数 r ( s , a ) r(s,a) r(s,a)),通过模型预测未来状态和奖励,结合规划(Planning)优化策略。
- 优势:可利用模型进行虚拟经验采样,数据效率高;适合长序列决策、环境动态已知或可建模的场景。
- 劣势:模型误差可能导致策略偏差;复杂环境中建模难度大。
- 代表性算法:
- Dyna系列:结合在线学习(Learning)与模型规划(Planning),如 Dyna-Q。
- 模型预测控制(MPC, Model-Predictive Control):基于短期模型预测的滚动优化。
- 基于模型的策略优化(MBPO, Model-Based Policy Optimization):通过模型生成虚拟数据训练策略,结合无模型算法(如PPO)。
- 世界模型(World Model):如 DeepMind 的 MuZero(结合神经网络建模与蒙特卡洛树搜索)。
2. 无模型强化学习(Model-Free RL)
核心思想:不显式建模环境,直接通过与环境交互的样本(状态、动作、奖励、下一状态)学习策略或值函数。
- 优势:适用于环境动态未知或复杂的场景(如游戏、机器人);避免模型偏差。
- 劣势:数据效率低,需大量交互样本。
- 细分方向:
- 值函数为中心(Value-Based):学习值函数(状态值 V ( s ) V(s) V(s) 或动作值 Q ( s , a ) Q(s,a) Q(s,a)),通过贪心策略推导动作。
- 策略为中心(Policy-Based):直接参数化策略 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 或 μ ( s ; θ ) \mu(s;\theta) μ(s;θ)(确定性策略)。
- Actor-Critic(结合值与策略):同时学习值函数(Critic)和策略(Actor),通过 Critic 指导 Actor 优化。
3、总结
算法分类图谱
强化学习算法
├─ 模型依赖性:
│ ├─ 基于模型(Model-Based):Dyna, MPC, MBPO, MuZero
│ └─ 无模型(Model-Free):Value-Based, Policy-Based, Actor-Critic
├─ 策略表示:
│ ├─ 值函数(Value-Based):Q-learning, DQN, DDPG(Critic部分)
│ ├─ 策略函数(Policy-Based):REINFORCE, PPO(随机策略)
│ └─ 演员-评论家(Actor-Critic):A3C, SAC, PPO(带Critic)
├─ 策略性质:
│ ├─ 确定性(Deterministic):DDPG, TD3
│ └─ 随机性(Stochastic):SAC, REINFORCE
├─ 学习范式:
│ ├─ 在线(On-Policy):SARSA, A3C, PPO
│ ├─ 离线(Off-Policy):Q-learning, DQN, SAC
│ └─ 模仿学习:BC, IRL (GAIL, AIRL)
├─ 动作空间:
│ ├─ 离散:DQN, Q-learning
│ └─ 连续:DDPG, SAC, PPO(连续版)
├─ 层级架构:
│ ├─ 分层(HRL):HAC, FeUdal Networks
│ └─ 多智能体(MARL):QMIX, AlphaStar
└─ 扩展目标:
├─ 约束RL:拉格朗日乘数法
└─ 多目标RL:帕累托优化
以下是强化学习算法的分类汇总表格,涵盖主要分类标准及代表算法:
| 分类标准 | 类别 | 代表算法 | 描述 |
|---|---|---|---|
| 算法类型 | 基于值的方法 | Q-Learning, DQN, SARSA | 通过价值函数(如Q值)选择最优动作,间接优化策略。 |
| 策略梯度方法 | REINFORCE, PPO, TRPO | 直接优化策略参数,通过梯度上升最大化累积奖励。 | |
| Actor-Critic | A2C, A3C, DDPG, SAC, TD3 | 结合值函数(Critic评估动作价值)和策略网络(Actor生成动作)。 | |
| 模型使用 | 无模型方法 | DQN, PPO, SAC, DDPG | 不依赖环境模型,直接通过与环境交互学习策略。 |
| 基于模型方法 | Dyna-Q, MBMF, AlphaZero | 学习或利用环境模型进行模拟和规划。 | |
| 是否使用深度 | 传统强化学习 | Q-Learning, SARSA | 基于表格或线性函数逼近,未使用深度神经网络。 |
| 深度强化学习 | DQN, DDPG, PPO, SAC | 结合深度神经网络进行非线性函数逼近。 | |
| 策略更新方式 | On-Policy | SARSA, A2C, PPO | 使用当前策略生成的数据进行更新,策略与行为一致。 |
| Off-Policy | Q-Learning, DQN, DDPG, SAC | 可使用历史或其他策略生成的数据进行更新。 | |
| 动作空间 | 离散动作空间 | DQN, Q-Learning | 适用于有限离散动作选择场景(如游戏控制)。 |
| 连续动作空间 | DDPG, SAC, PPO (连续变体) | 支持连续动作输出(如机器人控制)。 | |
| 学习目标 | 确定性策略 | DDPG, TD3 | 输出确定性动作(适用于连续控制)。 |
| 随机性策略 | SAC, PPO | 输出动作概率分布,支持探索与不确定性场景。 |
补充说明:
- 混合方法:如SAC(Soft Actor-Critic)结合了最大熵优化与Actor-Critic框架,TD3(Twin Delayed DDPG)通过双Q网络解决过估计问题。
- 扩展分类:
- 多智能体强化学习:MADDPG, QMIX。
- 分层强化学习:H-DQN, Option-Critic。
- 元强化学习:MAML-RL, RL²。
以下是强化学习算法的分类汇总,按不同维度整理成表格形式:
一、按是否基于环境模型分类
| 分类维度 | 子类别 | 核心思想 | 代表性算法 | 特点及应用场景 |
|---|---|---|---|---|
| 基于模型 | Model-Based RL | 先学习环境模型(状态转移/奖励函数),再利用模型规划决策 | Dyna、Model-Predictive RL、MB-MPO | 适合样本效率要求高的场景,但模型误差可能导致性能下降,常见于机器人控制等领域。 |
| 无模型 | Model-Free RL | 直接通过与环境交互学习策略或值函数,不显式建模环境 | Q-learning、Sarsa、Policy Gradient、PPO、DQN | 依赖大量交互数据,鲁棒性强,适用于复杂环境(如游戏、自动驾驶)。 |
二、按策略与值函数的处理方式分类
| 分类维度 | 子类别 | 核心思想 | 代表性算法 | 特点及应用场景 |
|---|---|---|---|---|
| 值函数方法 | Value-Based | 学习值函数(状态价值 V ( s ) V(s) V(s) 或动作价值 Q ( s , a ) Q(s,a) Q(s,a)),通过贪心策略选择动作 | Q-learning、Sarsa、DQN、DRQN | 策略隐含在值函数的贪心选择中,适用于离散动作空间,如Atari游戏。 |
| 策略梯度方法 | Policy-Based | 直接参数化策略 $\pi(a | s;\theta)$,通过梯度上升优化期望奖励 | REINFORCE、PPO、TRPO、SAC |
| 演员-评论家 | Actor-Critic | 结合值函数(评论家)与策略(演员),用值函数指导策略更新 | A3C、A2C、DDPG、ACER、TD3 | 平衡值函数的稳定性和策略梯度的直接性,适合复杂连续控制任务(如机器人、强化学习推荐)。 |
三、按学习模式(在线/离线)分类
| 分类维度 | 子类别 | 核心思想 | 代表性算法 | 特点及应用场景 |
|---|---|---|---|---|
| 在线学习 | On-Policy | 策略更新基于当前策略与环境交互的数据 | Sarsa、A2C、PPO(部分变种) | 数据实时生成,策略与数据分布一致,但效率较低,需持续与环境交互。 |
| 离线学习 | Off-Policy | 策略更新基于历史数据(旧策略生成的数据) | Q-learning、DQN、DDPG、SAC(离线版本) | 可复用历史数据,适合数据稀缺或环境不可交互场景(如医疗、金融),需处理分布偏移问题。 |
四、按动作空间类型分类
| 分类维度 | 子类别 | 核心思想 | 代表性算法 | 特点及应用场景 |
|---|---|---|---|---|
| 离散动作 | Discrete Actions | 动作空间有限,可直接枚举所有可能动作 | Q-learning、DQN、SARSA、Policy Gradient(离散版) | 适用于动作空间较小的场景,如棋盘游戏、简单机械臂控制。 |
| 连续动作 | Continuous Actions | 动作空间无限,需参数化策略或值函数输出连续数值 | DDPG、PPO(连续版)、SAC、TD3 | 适合需要精细控制的场景,如机器人运动、自动驾驶轨迹规划。 |
五、按是否结合深度神经网络分类(深度强化学习)
| 分类维度 | 子类别 | 核心思想 | 代表性算法 | 特点及应用场景 |
|---|---|---|---|---|
| 深度强化学习 | Deep RL | 使用神经网络近似值函数或策略,处理高维状态空间(如图像、自然语言) | DQN、DRQN、AC、A3C、PPO、SAC | 解决传统RL在高维状态下的维度灾难问题,是当前主流研究方向(如AlphaGo、OpenAI Five)。 |
| 传统强化学习 | Classic RL | 使用表格或线性函数表示值函数/策略,适用于低维状态/动作空间 | Q-learning(表格版)、Sarsa、REINFORCE(线性版) | 计算简单,适合小规模问题(如网格世界、小状态空间控制)。 |
说明:
- 交叉分类:许多算法属于多个类别(如PPO既是策略梯度算法,也是演员-评论家算法,可处理连续动作)。
- 应用趋势:深度强化学习(结合神经网络)在复杂场景中占主导,而传统算法适用于小规模或可解释性要求高的任务。
- 核心区别:值函数方法通过“选择最优动作”间接优化策略,策略梯度直接参数化策略,演员-评论家则结合两者优势。
如需某类算法的详细原理或对比,可进一步补充说明!
4、各算法适用场景建议
- 离散动作、简单环境:Q-learning、DQN(如Atari游戏)。
- 连续动作、高维状态:SAC(稳定且探索性好)、PPO(通用强鲁棒性)。
- 样本效率优先:Model-Based(如MBPO)、Offline RL(如CQL)。
- 多智能体协作/竞争:CTDE方法(如QMIX)、独立学习(小规模场景)。
- 复杂决策与规划:MuZero(围棋、星际争霸)、分层RL(机器人复杂任务)。
强化学习算法的分类维度多样,实际应用中常需根据具体任务(如离散/连续动作、环境模型是否已知、是否需要高效采样等)选择合适的算法。例如:
- 简单离散环境:Q-Learning、DQN。
- 连续控制任务:DDPG、PPO、SAC。
- 多智能体场景:MADDPG、QMIX。
- 离线数据学习:BCQ、CQL。
4、纯评论家、纯演员和演员-评论家
1.对比
| 方法 | 核心机制 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|
| 纯评论家 | 价值函数优化 | 离散动作、全局最优 | 稳定性高、易收敛 | 维度灾难、难以处理连续动作 |
| 纯演员 | 直接策略优化 | 连续动作、局部优化 | 灵活性强、无需价值函数 | 高方差、样本效率低 |
| 演员-评论家 | 策略与价值函数联合优化 | 复杂任务、高维状态 | 低方差、样本效率高 | 实现复杂、需协调双网络更新 |
CLSTM-PPO论文中汇总:
本节简要总结了强化学习、LSTM 和一些最先进的模型在量化交易中的应用,回顾了强化学习中经常应用于金融市场的三种学习方法和用于预测股票价格的 LSTM 神经网络。这三种学习方法是:纯评论家学习、演员纯学习和演员-评论家学习。https://arxiv.org/pdf/2212.02721

一、纯评论家学习(Pure Critic Learning,基于价值的方法)
核心思想
- 不直接学习策略,而是通过估计价值函数(状态价值 V ( s ) V(s) V(s) 或动作价值 Q ( s , a ) Q(s,a) Q(s,a))间接导出策略(如贪心策略)。
- 策略隐式存在,由价值函数决定(例如:在离散动作空间中,选择使 Q ( s , a ) Q(s,a) Q(s,a) 最大的动作)。
代表算法
- Q-learning、SARSA、DQN(深度Q网络)等。
关键特点
- 优点:
- 理论清晰,适用于离散动作空间(连续动作需特殊处理,如函数近似)。
- 无需显式参数化策略,计算复杂度较低(尤其在状态/动作空间较小的场景)。
- 缺点:
- 策略隐式依赖价值函数,在连续动作空间中难以直接优化(需离散化或复杂近似)。
- 价值函数的估计误差可能导致策略偏差(如DQN的过估计问题)。
适用场景
- 离散动作环境(如Atari游戏)、状态空间中等规模的任务。
二、演员纯学习(Pure Actor Learning,基于策略的方法)
核心思想
- 直接参数化策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s)(随机策略)或 a = μ θ ( s ) a = \mu_\theta(s) a=μθ(s)(确定性策略),通过策略梯度直接优化策略。
- 不依赖显式价值函数,仅通过环境反馈的奖励信号(或累计回报)更新策略参数。
代表算法
- REINFORCE(蒙特卡洛策略梯度)、DDPG(确定性策略梯度,严格来说结合了评论家,但核心是策略优化)、PPO(近端策略优化,实际属于演员-评论家,但策略更新占主导)。
关键特点
- 优点:
- 天然适合连续动作空间(可直接输出连续动作的概率分布或确定性值)。
- 能学习随机策略(如探索-利用平衡),适用于需要随机行为的场景(如博弈论中的混合策略)。
- 缺点:
- 策略梯度的方差较大(依赖采样回报,尤其在蒙特卡洛方法中),需大量样本。
- 缺乏价值函数作为“基线”,优化效率可能较低。
适用场景
- 连续控制任务(如机器人运动)、需要随机策略的复杂环境。
三、演员-评论家学习(Actor-Critic Learning,策略-价值结合方法)
核心思想
- 同时学习策略(演员)和价值函数(评论家):
- 演员:参数化策略 π θ \pi_\theta πθ,负责决策动作。
- 评论家:估计价值函数(如 V ( s ) V(s) V(s) 或 Q ( s , a ) Q(s,a) Q(s,a)),评估演员策略的好坏,为策略更新提供梯度方向。
- 评论家的价值估计可作为“基线”,减少策略梯度的方差(如用优势函数 A ( s , a ) = Q ( s , a ) − V ( s ) A(s,a) = Q(s,a) - V(s) A(s,a)=Q(s,a)−V(s))。
代表算法
- Actor-Critic(AC)、A3C(异步优势演员-评论家)、PPO(结合重要性采样和评论家)、SAC(软演员-评论家,引入熵正则化)。
关键特点
- 优点:
- 结合了基于价值和基于策略的优势:评论家减少方差,演员直接优化策略,样本效率较高。
- 适用于连续/离散动作空间,灵活性强。
- 缺点:
- 需协调演员和评论家的更新,可能出现“策略-价值不一致”(如评论家过拟合导致演员学习偏差)。
- 稳定性问题(如深度网络中,梯度噪声可能放大误差)。
适用场景
- 复杂高维环境(如强化学习与机器人、游戏AI),尤其需要高效样本利用和连续动作控制的任务。
四、三者对比与联系
| 维度 | 纯评论家(基于价值) | 纯演员(基于策略) | 演员-评论家(结合) |
|---|---|---|---|
| 学习对象 | 价值函数(隐式策略) | 显式策略函数 | 策略函数 + 价值函数 |
| 动作空间 | 离散(连续需特殊处理) | 连续/离散 | 连续/离散 |
| 样本效率 | 较高(无需采样轨迹) | 较低(依赖采样回报) | 中等(评论家减少方差) |
| 方差 | 低(价值函数平滑) | 高(直接依赖奖励) | 中等(基线降低方差) |
| 代表算法 | Q-learning、DQN | REINFORCE、DDPG | AC、PPO、SAC |
| 典型场景 | 离散动作小游戏 | 机器人连续控制 | 复杂环境(如星际争霸、自动驾驶) |
对比总结
| 方法 | 核心机制 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|
| 纯评论家 | 价值函数优化 | 离散动作、全局最优 | 稳定性高、易收敛 | 维度灾难、难以处理连续动作 |
| 纯演员 | 直接策略优化 | 连续动作、局部优化 | 灵活性强、无需价值函数 | 高方差、样本效率低 |
| 演员-评论家 | 策略与价值函数联合优化 | 复杂任务、高维状态 | 低方差、样本效率高 | 实现复杂、需协调双网络更新 |
总结
- 纯评论家:适合离散动作、策略隐式导出的简单场景。
- 纯演员:适合连续动作、需显式策略优化的任务,但样本效率低。
- 演员-评论家:平衡了价值估计和策略优化,是处理复杂环境的主流框架,但需解决稳定性问题。
实际应用中,演员-评论家方法(如PPO、SAC)因兼顾效率和灵活性,在深度强化学习中更为常用,尤其在连续控制和高维状态空间任务中表现突出。
选择建议
• 离散动作与简单任务:优先考虑Q-Learning或DQN。
• 连续动作与精细控制:选择策略梯度(如PPO)或演员-评论家(如A3C)。
• 高维状态与实时决策:采用深度演员-评论家(如DDPG)。
通过结合不同方法的优势,演员-评论家框架在多数复杂任务中表现出色,成为现代强化学习的核心范式。
5、与其他学习范式的对比
-
监督学习
• 依赖标注数据:需大量带标签样本(如图像分类),而强化学习仅需奖励信号。
• 反馈形式:监督学习直接提供正确答案,强化学习通过试错调整策略。 -
无监督学习
• 目标差异:无标签,无监督学习聚焦数据内在结构(如聚类),而强化学习以最大化累积奖励为目标。 -
强化学习
强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法:- 监督学习 是从外部监督者提供的带标注训练集中进行学习。 (任务驱动型)
- 非监督学习 是一个典型的寻找未标注数据中隐含结构的过程。 (数据驱动型)
- 强化学习 更偏重于智能体与环境的交互, 这带来了一个独有的挑战 ——“试错(exploration)”与“开发(exploitation)”之间的折中权衡,智能体必须开发已有的经验来获取收益,同时也要进行试探,使得未来可以获得更好的动作选择空间。 (从错误中学习)
强化学习主要有以下几个特点:- 试错学习:强化学习一般没有直接的指导信息,Agent 要以不断与 Environment 进行交互,通过试错的方式来获得最佳策略(Policy)。
- 延迟回报:强化学习的指导信息很少,而且往往是在事后(最后一个状态(State))才给出的。比如 围棋中只有到了最后才能知道胜负。
6、论文汇总
6.1 强化学习发展历程论文汇总表
以下是强化学习发展历程的关键论文汇总表格,涵盖理论奠基、算法演进、应用突破及最新进展(截至2024年),并附推荐阅读顺序:
Q-learning的诞生
1989:Chris Watkins的博士论文《Learning from Delayed Rewards》首次提出Q-learning算法,后于1992年与Dayan合作发表《Q-learning》,正式确立无模型RL框架。
Watkins在《Learning from Delayed Rewards》中提出Q-learning
Watkins & Dayan《Q-learning》
| 年份 | 模型/方法 | 论文标题 | 核心贡献 | 链接 |
|---|---|---|---|---|
| 1957 | 动态规划 | 《Dynamic Programming》 | 提出贝尔曼方程,奠定强化学习数学框架。 | 链接 |
| 1960 | 马尔可夫决策过程(MDP) | 《Dynamic Programming and Markov Processes》 | 建立MDP模型,将序列决策问题转化为状态-动作-奖励的数学模型。 | 链接 |
| 1988 | TD学习 | 《Learning to Predict by the Methods of Temporal Differences》 | 提出TD(λ)算法,解决无模型学习问题,成为强化学习核心理论。 | 链接 |
| 1989 | Q-learning | 《Learning from Delayed Rewards》 | 首次实现无模型最优动作价值函数学习,成为经典算法。 | 链接 |
| 1995 | TD-Gammon | 《TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play》 | 结合TD学习与神经网络,在西洋双陆棋中超越人类水平,验证强化学习潜力。 | 链接 |
| 1998 | 强化学习教材 | 《Reinforcement Learning: An Introduction》 | 系统阐述强化学习理论,成为领域“圣经”。 | 链接 |
| 2013 | DQN | 《Playing Atari with Deep Reinforcement Learning》 | 首次将深度学习与Q-learning结合,实现Atari游戏端到端控制,开启深度强化学习时代。 | 链接 |
| 2015 | DQN(改进版) | 《Human-Level Control Through Deep Reinforcement Learning》 | 引入经验回放和目标网络,在49款Atari游戏中超越人类专家水平。 | 链接 |
| 2016 | A3C | 《Asynchronous Methods for Deep Reinforcement Learning》 | 提出异步并行训练框架,提升连续动作空间任务效率。 | 链接 |
| 2016 | AlphaGo | 《Mastering the Game of Go with Deep Neural Networks and Tree Search》 | 结合强化学习与蒙特卡洛树搜索,击败人类围棋冠军。 | 链接 |
| 2017 | AlphaZero | 《Mastering the Game of Go without Human Knowledge》 | 仅用强化学习实现超越人类棋力,证明无监督学习潜力。 | 链接 |
| 2017 | PPO | 《Proximal Policy Optimization Algorithms》 | 通过信任区域优化解决策略更新不稳定问题,成为工业界常用算法。 | 链接 |
| 2018 | SAC | 《Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor》 | 引入最大熵原理,提升策略鲁棒性,适用于连续动作空间。 | 链接 |
| 2023 | Sora | 《Sora: Zero-Shot Transfer with State-Space Models for Robotic Manipulation》 | 结合模型学习与强化学习,实现机器人零样本操作。 | 链接 |
| 2024 | 去中心化策略优化 | 《Efficient and scalable reinforcement learning for large-scale network control》 | 提出基于模型的去中心化方法,适用于电网、交通等大规模系统。 | 链接 |
强化学习发展历程关键论文表格(截至2024年)
| 年份 | 模型/算法 | 论文标题 | 核心贡献 | 链接 |
|---|---|---|---|---|
| 1951 | 操作性条件反射理论 | Science and Human Behavior | 提出奖励机制的心理学基础,为强化学习的反馈机制提供理论支持。 | 亚马逊图书链接 |
| 1957 | 贝尔曼方程 | Dynamic Programming | 提出最优决策的核心数学工具,奠定动态规划理论基础。 | 普林斯顿大学出版社 |
| 1983 | 反向传播算法 | Approximating Dynamic Programming for Optimal Control | 将反向传播引入动态规划,推动函数逼近在强化学习中的应用。 | IEEE Xplore |
| 1988 | TD学习 | Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems | 提出时序差分(TD)学习,成为现代强化学习理论的基石。 | IEEE Xplore |
| 1992 | Q-learning | Q-learning | 提出无模型强化学习框架,首次实现无需环境模型的最优策略学习。 | ResearchGate |
| 1999 | 策略梯度 | Policy Gradient Methods for Reinforcement Learning with Function Approximation | 提出策略梯度定理,为直接优化策略提供理论支持。 | MIT Press |
| 2013 | DQN | Playing Atari with Deep Reinforcement Learning | 首次将深度神经网络与Q-learning结合,实现Atari游戏的超人表现,开启深度强化学习时代。 | arXiv |
| 2015 | 改进版DQN | Human-Level Control through Deep Reinforcement Learning | 引入经验回放和目标网络,提升深度强化学习的稳定性,在49款Atari游戏中达到人类水平。 | Nature |
| 2016 | A3C | Asynchronous Methods for Deep Reinforcement Learning | 提出异步优势演员-评论家算法,通过并行更新策略和价值函数,大幅提升训练效率。 | arXiv |
| 2016 | AlphaGo | Mastering the Game of Go with Deep Neural Networks and Tree Search | 结合深度神经网络与蒙特卡洛树搜索(MCTS),击败围棋世界冠军,展示深度强化学习的潜力。 | Nature |
| 2017 | AlphaZero | Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm | 仅通过自我对弈学习,在围棋、国际象棋和将棋中超越人类水平,提出通用强化学习框架。 | arXiv |
| 2017 | PPO | Proximal Policy Optimization Algorithms | 简化信任区域策略优化(TRPO),成为当前最常用的策略优化算法,兼顾效率与稳定性。 | arXiv |
| 2018 | SAC | Soft Actor-Critic Algorithms and Applications | 结合最大熵框架与策略优化,在连续控制任务中表现优异,提升样本效率。 | arXiv |
| 2021 | 离线RL(Transformer) | Offline Reinforcement Learning as One Big Sequence Modeling Problem | 将离线RL视为序列建模问题,利用Transformer架构提升泛化能力,推动离线学习实用化。 | arXiv |
| 2024 | RL+进化算法 | Reinforcement Learning-Assisted Evolutionary Algorithm | 探索RL与进化算法的结合,提升样本效率,在复杂优化问题中实现突破。 | [需通过学术数据库获取] |
| 2024 | 综述与趋势 | A Comprehensive Survey of Reinforcement Learning | 全面总结RL算法,涵盖理论、实践与未来挑战,提供技术全景分析。 | GitHub |
| 2024 | 生物启发式学习 | Synaptic Balancing | 提出生物启发式学习规则,提升神经网络鲁棒性,为神经形态计算提供新方向。 | PLOS Computational Biology |
强化学习发展历程论文汇总表(1956-2024)
| 年份 | 模型/算法名称 | 论文/贡献名称 | 核心贡献 | 链接(参考来源) |
|---|---|---|---|---|
| 1956 | 动态规划(DP) | Bellman《Dynamic Programming》 | 奠定强化学习的数学基础,提出最优控制理论框架 | |
| 1988 | TD算法 | Sutton《Learning to Predict by Temporal Differences》 | 提出时序差分学习理论,融合动态规划与蒙特卡洛方法 | |
| 1992 | Q-learning | Watkins & Dayan《Q-learning》 | 首个无模型强化学习算法,证明收敛性并推动实际应用 | |
| 1994 | SARSA | Rummery & Niranjan《On-Line Q-Learning》 | 完善同策略时序差分学习框架 | |
| 2013 | DQN | Mnih et al.《Playing Atari with Deep RL》 | 首次结合CNN与经验回放,实现高维状态端到端学习 | |
| 2015 | DDPG | Lillicrap et al.《Continuous Control with DRL》 | 解决连续动作空间问题,应用于机器人控制 | |
| 2016 | AlphaGo | Silver et al.《Mastering Go with DNN》 | 结合MCTS与DRL击败人类围棋冠军,开启博弈AI新纪元 | |
| 2017 | PPO | Schulman et al.《Proximal Policy Optimization》 | 改进策略梯度稳定性,成为连续控制任务标准算法 | |
| 2020 | CQL | Kumar et al.《Conservative Q-Learning》 | 提出保守Q函数估计方法,解决离线强化学习分布偏移问题 | |
| 2023 | Safe RLHF | OpenAI《Training Language Models via Human Feedback》 | 通过人类反馈对齐大模型伦理,推动AI安全研究 | |
| 2024 | APE框架 | Zhang et al.《Adaptive Pretrained Encoder for RL Generalization》 | 动态预训练视觉编码器,提升复杂环境泛化能力 |
注:部分论文链接因来源限制暂缺,可参考Google Scholar或顶会论文集(NeurIPS/ICML/AAAI)。
6.2 总结与推荐阅读顺序
总结
- 理论奠基:动态规划(1957)和MDP(1960)为强化学习提供数学基础,TD学习(1988)和Q-learning(1989)解决无模型学习问题。
- 算法演进:深度强化学习(DQN,2013)结合深度学习实现突破,A3C(2016)和PPO(2017)提升训练效率,SAC(2018)增强策略鲁棒性。
- 应用突破:AlphaGo(2016)和AlphaZero(2017)在棋类领域超越人类,Sora(2023)推动机器人零样本操作。
- 最新趋势:去中心化策略优化(2024)和生成模型结合成为新方向,强化学习在大规模系统和跨学科融合中持续扩展。
推荐阅读顺序
-
基础理论:
- Sutton和Barto的《Reinforcement Learning: An Introduction》(1998)——全面掌握核心理论。
- Q-learning(1989)——理解无模型学习的经典算法。
-
深度强化学习:
- DQN(2013)——了解深度强化学习的开端。
- AlphaGo(2016)——体验强化学习在复杂博弈中的应用。
-
算法进阶:
- PPO(2017)——学习工业界主流算法。
- SAC(2018)——掌握最大熵原理在策略优化中的应用。
-
最新进展:
- 去中心化策略优化(2024)——探索大规模系统的强化学习方法。
- Sora(2023)——关注机器人领域的零样本学习突破。
资源补充
- 会议论文:NeurIPS、ICML、ICRL等顶级会议收录大量强化学习研究(如NeurIPS 2019收录38篇强化学习论文)。
- 预印本平台:ArXiv每日更新强化学习研究,如2024年AAAI收录52篇深度强化学习论文。
- 开源项目:OpenAI的Spinning Up、DeepMind的AlphaFold等代码库提供实践参考。
通过以上阅读路径,可逐步掌握强化学习从理论到应用的完整发展脉络,并跟踪最新技术趋势。
6.3 发展历程论文汇总
以下是强化学习发展历程中的关键论文和技术突破的详细汇总,按时间顺序和技术方向分类,涵盖理论奠基、算法演进、应用突破及最新进展:
一、理论奠基与早期探索(1950s–1980s)
1. 心理学与神经科学基础
- 操作性条件反射(1938):B.F. Skinner在《The Behavior of Organisms》中提出行为通过奖励和惩罚塑造的理论,为强化学习的奖惩机制提供了心理学依据。
- 动态规划(1957):Richard Bellman在《Dynamic Programming》中提出最优子结构和贝尔曼方程,为后续强化学习的数学框架奠定基础。
- 马尔可夫决策过程(MDP)(1960):Ronald Howard在《Dynamic Programming and Markov Processes》中建立MDP模型,将强化学习问题转化为状态-动作-奖励的序列决策问题。
2. 计算方法的早期尝试
- 自适应控制算法(1954):Farley和Clark首次提出模拟神经网络的自适应控制算法,探索机器通过环境反馈学习的能力。
- 跳棋程序(1959):Arthur Samuel在《Some Studies in Machine Learning Using the Game of Checkers》中开发首个具备学习能力的跳棋程序,引入“机器学习”术语,并提出启发式搜索和动态规划结合的方法。
二、强化学习理论形成(1980s–1990s)
1. 核心理论框架
- 时序差分学习(TD Learning)(1988):Sutton在《Learning to Predict by the Methods of Temporal Differences》中提出TD(λ)算法,解决了动态规划需要环境模型的问题,成为无模型强化学习的核心。
- Actor-Critic架构(1983):Barto、Sutton和Anderson在《Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems》中提出基于神经元的自适应元件,结合策略评估(Critic)和策略改进(Actor),为后续算法提供框架。
2. 关键算法突破
- Q-learning(1989):Watkins在《Learning from Delayed Rewards》中提出Q-learning,首次实现无模型的最优动作价值函数学习,成为强化学习的经典算法。
- TD-Gammon(1995):Tesauro在《TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play》中结合TD学习和神经网络,在西洋双陆棋中超越人类水平,验证了强化学习的潜力。
3. 教材与综述
- 《Reinforcement Learning: An Introduction》(1998):Sutton和Barto合著的教材成为强化学习领域的“圣经”,系统阐述核心理论和算法,累计引用超75,000次。
三、算法演进与深度强化学习崛起(2000s–2010s)
1. 深度强化学习的突破
- 深度Q网络(DQN)(2013):Mnih等人在《Playing Atari with Deep Reinforcement Learning》中首次将深度学习与Q-learning结合,实现Atari游戏的端到端控制,标志着深度强化学习时代的开启。
- 人类水平控制(2015):Mnih等人在《Human-Level Control Through Deep Reinforcement Learning》中改进DQN,引入经验回放和目标网络,在49款Atari游戏中超越人类专家水平。
2. 策略梯度与Actor-Critic方法
- A3C(异步优势Actor-Critic)(2016):Mnih等人在《Asynchronous Methods for Deep Reinforcement Learning》中提出异步并行训练框架,显著提升训练效率,适用于连续动作空间任务。
- PPO(近端策略优化)(2017):Schulman等人在《Proximal Policy Optimization Algorithms》中提出PPO,通过信任区域优化解决策略更新不稳定问题,成为工业界常用算法。
3. 模型与探索
- 基于模型的强化学习(2015):Oh等人在《Control of Memory, Active Perception, and Action in Minecraft》中结合模型学习与规划,提升样本效率。
- 优先经验回放(2016):Schaul等人在《Prioritized Experience Replay》中提出PER,通过优先采样高误差样本加速学习。
四、应用突破与多智能体扩展(2010s–2020s)
1. 游戏与棋类
- AlphaGo(2016):Silver等人在《Mastering the Game of Go with Deep Neural Networks and Tree Search》中结合强化学习与蒙特卡洛树搜索,击败人类围棋冠军。
- AlphaZero(2017):Silver等人在《Mastering the Game of Go without Human Knowledge》中仅用强化学习实现超越人类的棋力,证明无监督学习的潜力。
2. 机器人与控制
- DDPG(深度确定性策略梯度)(2015):Lillicrap等人在《Continuous Control with Deep Reinforcement Learning》中提出DDPG,解决连续动作空间问题,应用于机器人控制。
- Sora(2023):OpenAI在《Sora: Zero-Shot Transfer with State-Space Models for Robotic Manipulation》中结合模型学习与强化学习,实现机器人零样本操作。
3. 多智能体强化学习
- MADDPG(2017):Lowe等人在《Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments》中提出多智能体Actor-Critic框架,解决协作与竞争任务。
- ACORN(2025):谢翊等人在《ACORN: Acyclic Coordination with Reachability Network to Reduce Communication Redundancy in Multi-Agent Systems》中提出无环协调网络,降低多智能体通信开销。
五、最新进展与趋势(2020s–至今)
1. 大规模系统与去中心化
- 去中心化策略优化(2024):北京大学杨耀东课题组在《Efficient and scalable reinforcement learning for large-scale network control》中提出基于模型的去中心化方法,适用于电网、交通等大规模系统。
2. 理论与算法创新
- SAC(软 Actor-Critic)(2018):Haarnoja等人在《Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor》中引入最大熵原理,提升策略的鲁棒性。
- 离线强化学习(2020s):Fujimoto等人在《Off-Policy Deep Reinforcement Learning without Exploration》中研究利用历史数据学习,减少在线探索需求。
3. 跨学科融合
- 神经科学启发(2024):Sutton和Barto因在强化学习领域的奠基性贡献获得图灵奖,其工作融合心理学、控制论与机器学习。
- 生成模型结合(2023):Karras等人在《Generative Adversarial Networks for Reinforcement Learning》中探索GAN与强化学习的结合,提升样本效率。
六、经典论文与资源推荐
-
必读论文:
- Sutton和Barto的《Reinforcement Learning: An Introduction》(1998)。
- Mnih等人的《Playing Atari with Deep Reinforcement Learning》(2013)。
- Silver等人的《Mastering the Game of Go with Deep Neural Networks and Tree Search》(2016)。
-
综述与教材:
- Kaelbling等人的《Reinforcement Learning: A Survey》(2002)。
- OpenAI的《Spinning Up in Deep RL》在线教程。
-
会议与资源:
- NeurIPS、ICML、ICRL:顶级会议中强化学习论文占比逐年上升,如NeurIPS 2019收录38篇强化学习论文。
- ArXiv:预印本平台每日更新强化学习研究,如2024年AAAI收录52篇深度强化学习论文。
总结
强化学习从早期心理学理论发展到现代深度强化学习,经历了从理论奠基、算法创新到大规模应用的历程。关键突破包括Q-learning、DQN、AlphaGo等,近年来多智能体、模型学习和跨学科融合成为新趋势。未来,强化学习将在自主系统、科学发现等领域持续突破,同时面临样本效率、泛化能力等挑战。
7、附录
附录一:算法分类
强化学习(Reinforcement Learning, RL)算法的分类可以从多个角度进行划分。以下是常见的分类方式及其典型算法:
1. 基于是否依赖环境模型
(1)基于模型(Model-Based)
- 特点:依赖对环境的动态模型(状态转移概率和奖励函数)的显式建模。
- 典型算法:
- 动态规划(DP):如值迭代(Value Iteration)、策略迭代(Policy Iteration)。
- Dyna-Q:结合模型学习与无模型学习。
- 蒙特卡洛树搜索(MCTS):如AlphaGo中的树搜索策略。
(2)无模型(Model-Free)
- 特点:不显式建模环境,直接通过交互经验学习策略或价值函数。
- 典型算法:
- Q-Learning、SARSA(基于价值)。
- REINFORCE、PPO(基于策略)。
- Actor-Critic(混合策略与价值)。
2. 基于策略与价值函数的关系
(1)基于价值(Value-Based)
- 特点:通过优化价值函数(如Q值函数)间接推导策略。
- 典型算法:
- Q-Learning、DQN(Deep Q-Network)。
- SARSA、Double DQN。
(2)基于策略(Policy-Based)
- 特点:直接优化策略函数,适用于连续动作空间或随机策略。
- 典型算法:
- REINFORCE(蒙特卡洛策略梯度)。
- PPO(Proximal Policy Optimization)。
- TRPO(Trust Region Policy Optimization)。
(3)Actor-Critic(混合方法)
- 特点:结合策略(Actor)和价值函数(Critic),兼具两者的优势。
- 典型算法:
- A3C(Asynchronous Advantage Actor-Critic)。
- DDPG(Deep Deterministic Policy Gradient)。
- SAC(Soft Actor-Critic)。
3. 基于是否结合深度学习
(1)传统强化学习
- 特点:使用表格或线性函数表示价值或策略。
- 典型算法:Q-Learning、SARSA、REINFORCE。
(2)深度强化学习(Deep RL)
- 特点:利用深度神经网络拟合复杂价值函数或策略。
- 典型算法:
- DQN(结合经验回放和固定目标网络)。
- DDPG(连续动作空间下的深度策略梯度)。
- PPO(高效稳定的策略优化)。
4. 基于策略更新方式
(1)同策略(On-Policy)
- 特点:使用当前策略生成数据并更新策略。
- 典型算法:SARSA、REINFORCE、PPO。
(2)异策略(Off-Policy)
- 特点:使用历史策略生成的数据更新当前策略。
- 典型算法:Q-Learning、DQN、DDPG。
5. 基于学习目标
(1)在线学习(Online Learning)
- 特点:智能体与环境实时交互并更新策略。
- 典型算法:SARSA、PPO。
(2)离线学习(Offline Learning)
- 特点:从固定数据集中学习,不与环境交互。
- 典型算法:BCQ(Batch-Constrained Q-Learning)、CQL(Conservative Q-Learning)。
6. 基于采样方式
(1)蒙特卡洛方法(Monte Carlo, MC)
- 特点:基于完整回合的奖励进行更新。
- 典型算法:REINFORCE。
(2)时序差分(Temporal Difference, TD)
- 特点:基于单步或有限步的奖励进行更新。
- 典型算法:Q-Learning、SARSA、TD3(Twin Delayed DDPG)。
7. 其他特殊分类
(1)多智能体强化学习(MARL)
- 特点:多个智能体协作或竞争。
- 典型算法:MADDPG、QMIX。
(2)元强化学习(Meta-RL)
- 特点:学习快速适应新任务的通用策略。
- 典型算法:MAML(Model-Agnostic Meta-Learning)。
(3)分层强化学习(HRL)
- 特点:分解任务为子目标或子策略。
- 典型算法:HIRO、Option-Critic。
总结
强化学习算法的分类维度多样,实际应用中常需根据具体任务(如离散/连续动作、环境模型是否已知、是否需要高效采样等)选择合适的算法。例如:
- 简单离散环境:Q-Learning、DQN。
- 连续控制任务:DDPG、PPO、SAC。
- 多智能体场景:MADDPG、QMIX。
- 离线数据学习:BCQ、CQL。
附录二:算法分类
强化学习(Reinforcement Learning, RL)算法的分类可以从多个维度进行,包括 模型依赖性、策略表示、学习范式、动作空间特性、学习目标 等。以下是一个系统且详细的分类框架,结合经典与前沿算法,覆盖核心分类维度:
一、按 模型依赖性(Model-Based vs Model-Free)
1. 基于模型的强化学习(Model-Based RL)
核心思想:显式学习环境模型(状态转移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a) 和奖励函数 r ( s , a ) r(s,a) r(s,a)),通过模型预测未来状态和奖励,结合规划(Planning)优化策略。
- 优势:可利用模型进行虚拟经验采样,数据效率高;适合长序列决策、环境动态已知或可建模的场景。
- 劣势:模型误差可能导致策略偏差;复杂环境中建模难度大。
- 代表性算法:
- Dyna系列:结合在线学习(Learning)与模型规划(Planning),如 Dyna-Q。
- 模型预测控制(MPC, Model-Predictive Control):基于短期模型预测的滚动优化。
- 基于模型的策略优化(MBPO, Model-Based Policy Optimization):通过模型生成虚拟数据训练策略,结合无模型算法(如PPO)。
- 世界模型(World Model):如 DeepMind 的 MuZero(结合神经网络建模与蒙特卡洛树搜索)。
2. 无模型强化学习(Model-Free RL)
核心思想:不显式建模环境,直接通过与环境交互的样本(状态、动作、奖励、下一状态)学习策略或值函数。
- 优势:适用于环境动态未知或复杂的场景(如游戏、机器人);避免模型偏差。
- 劣势:数据效率低,需大量交互样本。
- 细分方向:
- 值函数为中心(Value-Based):学习值函数(状态值 V ( s ) V(s) V(s) 或动作值 Q ( s , a ) Q(s,a) Q(s,a)),通过贪心策略推导动作。
- 策略为中心(Policy-Based):直接参数化策略 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 或 μ ( s ; θ ) \mu(s;\theta) μ(s;θ)(确定性策略)。
- Actor-Critic(结合值与策略):同时学习值函数(Critic)和策略(Actor),通过 Critic 指导 Actor 优化。
二、按 策略表示与学习方式(Value-Based vs Policy-Based vs Actor-Critic)
1. 值函数为中心(Value-Based RL)
核心目标:学习最优值函数 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a) 或 V ∗ ( s ) V^*(s) V∗(s),策略由值函数导出(如 ϵ \epsilon ϵ-贪心、Softmax)。
- 离散动作空间:
- Q-learning:离线策略(Off-Policy),利用最大未来奖励更新 Q Q Q 值,目标为 Q ( s , a ) ← r + γ max a ′ Q ( s ′ , a ′ ) Q(s,a) \leftarrow r + \gamma \max_{a'} Q(s',a') Q(s,a)←r+γmaxa′Q(s′,a′)。
- SARSA:在线策略(On-Policy),根据当前策略的下一动作更新,目标为 Q ( s , a ) ← r + γ Q ( s ′ , a ′ ) Q(s,a) \leftarrow r + \gamma Q(s',a') Q(s,a)←r+γQ(s′,a′)。
- 深度Q网络(DQN):用神经网络近似 Q ( s , a ) Q(s,a) Q(s,a),引入经验回放(Experience Replay)和目标网络(Target Network)稳定训练,如 Double DQN、Dueling DQN。
- 连续动作空间:
- 深度确定性策略梯度(DDPG, Deep Deterministic Policy Gradient):结合值函数(Critic)与确定性策略(Actor),本质为 Actor-Critic,但常被归类为 Value-Based 扩展(因 Critic 主导)。
2. 策略为中心(Policy-Based RL)
核心目标:直接优化策略函数 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ)(随机策略)或 μ ( s ; θ ) \mu(s;\theta) μ(s;θ)(确定性策略),通过梯度上升最大化期望回报。
- 优势:可处理连续动作空间;能学习随机策略(如探索需求高的场景)。
- 劣势:收敛性依赖梯度估计质量;值函数通常需辅助估计(如用基线函数减少方差)。
- 代表性算法:
- REINFORCE:蒙特卡洛策略梯度,利用回报 R t R_t Rt 作为梯度估计,公式为 ∇ θ log π ( a t ∣ s t ; θ ) ⋅ R t \nabla_\theta \log \pi(a_t|s_t;\theta) \cdot R_t ∇θlogπ(at∣st;θ)⋅Rt。
- 信任区域策略优化(TRPO, Trust Region Policy Optimization):通过约束策略更新步长(KL散度)保证单调改进,稳定性强但计算复杂。
- 近端策略优化(PPO, Proximal Policy Optimization):TRPO 的简化版,用截断重要性采样(Clipped Importance Sampling)替代约束,易实现且广泛应用。
- 随机策略梯度(SPG, Stochastic Policy Gradient):通用框架,梯度基于期望回报的微分 ∇ θ E π θ [ R ] \nabla_\theta \mathbb{E}_{\pi_\theta}[R] ∇θEπθ[R]。
3. Actor-Critic 算法(结合值与策略)
核心架构:
- Actor:参数化策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 或 μ θ ( s ) \mu_\theta(s) μθ(s),负责生成动作。
- Critic:估计值函数 V ( s ) V(s) V(s) 或 Q ( s , a ) Q(s,a) Q(s,a),评价动作质量,指导 Actor 优化。
- 优势:结合值函数的稳定梯度估计与策略函数的直接优化,数据效率高于纯 Policy-Based。
- 代表性算法:
- A3C(Asynchronous Advantage Actor-Critic):异步多智能体训练,利用优势函数 A ( s , a ) = Q ( s , a ) − V ( s ) A(s,a) = Q(s,a) - V(s) A(s,a)=Q(s,a)−V(s) 减少方差。
- DDPG(如上所述,也可归为此类):确定性策略 + Q-Critic,适用于连续动作空间。
- 软演员-评论家(SAC, Soft Actor-Critic):最大化熵正则化的期望回报,学习随机策略,具有良好的探索性和收敛性,适合连续动作场景。
- PPO with Critic:PPO 常结合 Critic 估计优势函数(如广义优势估计 GAE),实际属于 Actor-Critic 变体。
三、按 策略性质(确定性 vs 随机性)
-
确定性策略(Deterministic Policy)
- 输出明确动作 a = μ ( s ; θ ) a = \mu(s;\theta) a=μ(s;θ),适用于动作空间连续且需稳定决策的场景(如机器人控制)。
- 算法:DDPG、TD3(Twin Delayed DDPG,通过双 Critic 减少过估计)、部分基于规则的策略。
-
随机性策略(Stochastic Policy)
- 输出动作概率分布 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ),天然具备探索性,适合需要概率决策或环境随机的场景。
- 算法:REINFORCE、PPO(随机策略版本)、SAC(显式最大化熵,鼓励探索)。
四、按 学习范式(在线 vs 离线 vs 模仿学习)
-
在线学习(On-Policy)
- 直接使用当前策略与环境交互的样本训练,策略更新时需保持数据同分布。
- 算法:SARSA、A3C、PPO(本质为在线,但通过截断重要性采样允许一定离线数据重用)。
-
离线学习(Off-Policy)
- 使用历史数据(来自其他策略)训练,无需实时交互,适合利用专家数据或旧策略数据。
- 优势:可重用数据,安全(避免在危险环境中试错);劣势:分布偏移问题(数据与当前策略不匹配)。
- 算法:Q-learning、DQN、DDPG(离线策略版本)、离线强化学习(如 BCQ、CQL)。
-
模仿学习(Imitation Learning)
- 从专家演示中学习策略,而非通过奖励信号,属于强化学习的扩展范式。
- 细分:
- 行为克隆(Behavior Cloning):直接拟合专家动作的条件分布 π ( a ∣ s ) \pi(a|s) π(a∣s)。
- 逆强化学习(IRL, Inverse Reinforcement Learning):先推断专家的奖励函数,再用 RL 求解最优策略(如 GAIL、AIRL)。
五、按 动作空间特性(离散 vs 连续 vs 结构化)
-
离散动作空间
- 动作集合有限(如游戏中的上下左右),值函数和策略可直接处理离散选择。
- 典型算法:Q-learning、DQN、Policy Gradient(离散输出层)。
-
连续动作空间
- 动作需输出实数向量(如机器人关节角度),需特殊处理(如参数化均值和方差的高斯策略,或确定性函数)。
- 典型算法:DDPG、PPO(连续版本)、SAC。
-
结构化动作空间
- 动作具有层次或组合结构(如推荐系统中的项目集合、路径规划中的节点序列)。
- 常用方法:结合注意力机制(如强化学习与 Transformer 结合,用于组合优化问题,如车辆调度、TSP)。
六、按 层级与架构(分层 vs 分布式 vs 多智能体)
-
分层强化学习(HRL, Hierarchical RL)
- 将任务分解为高层策略(目标生成)和低层策略(具体动作),提升复杂任务的学习效率。
- 核心概念:子目标(Subgoal)、选项(Option,包含启动状态、策略、终止条件)。
- 算法:HAC(Hierarchical Actor-Critic)、FeUdal Networks。
-
分布式强化学习
- 通过并行化环境交互或模型训练加速学习,如 A3C(异步多线程)、IMPALA(重要性加权 Actor-Learner 架构)。
-
多智能体强化学习(MARL, Multi-Agent RL)
- 智能体之间存在交互(合作、竞争、混合场景),需处理非平稳环境(因其他智能体策略变化)。
- 分类:
- 完全合作:共享奖励,如星际争霸协作任务。
- 竞争:零和博弈,如 AlphaStar、OpenAI Five。
- 混合动机:部分合作部分竞争,如交通灯控制。
- 算法:
- 集中式训练-分布式执行(CTDE):如 QMIX、VDN(值函数分解)。
- 独立学习(Independent RL):每个智能体视为独立环境,忽略其他智能体策略变化。
- 博弈论视角:纳什均衡求解,如极大极小策略。
七、按 优化目标扩展(标准 RL vs 带约束 vs 多目标)
- 标准 RL:最大化累计奖励(如折扣回报 E [ ∑ t γ t r t ] \mathbb{E}[\sum_t \gamma^t r_t] E[∑tγtrt])。
- 约束强化学习(CRL, Constrained RL):在满足状态/动作约束(如安全、能耗)的前提下最大化奖励,如拉格朗日乘数法、惩罚函数。
- 多目标 RL:优化多个冲突目标(如奖励与样本效率),常用帕累托最优、权重聚合方法。
八、按 数据利用方式(样本效率)
- 样本低效算法:如早期的 Q-learning、REINFORCE,需大量交互数据。
- 样本高效算法:
- 基于模型(Model-Based):通过虚拟数据增强。
- 离线强化学习(Offline RL):重用历史数据,避免在线试错。
- 元学习(Meta-RL):快速适应新任务,如 MAML(Model-Agnostic Meta-Learning)。
总结:算法分类图谱
强化学习算法
├─ 模型依赖性:
│ ├─ 基于模型(Model-Based):Dyna, MPC, MBPO, MuZero
│ └─ 无模型(Model-Free):Value-Based, Policy-Based, Actor-Critic
├─ 策略表示:
│ ├─ 值函数(Value-Based):Q-learning, DQN, DDPG(Critic部分)
│ ├─ 策略函数(Policy-Based):REINFORCE, PPO(随机策略)
│ └─ 演员-评论家(Actor-Critic):A3C, SAC, PPO(带Critic)
├─ 策略性质:
│ ├─ 确定性(Deterministic):DDPG, TD3
│ └─ 随机性(Stochastic):SAC, REINFORCE
├─ 学习范式:
│ ├─ 在线(On-Policy):SARSA, A3C, PPO
│ ├─ 离线(Off-Policy):Q-learning, DQN, SAC
│ └─ 模仿学习:BC, IRL (GAIL, AIRL)
├─ 动作空间:
│ ├─ 离散:DQN, Q-learning
│ └─ 连续:DDPG, SAC, PPO(连续版)
├─ 层级架构:
│ ├─ 分层(HRL):HAC, FeUdal Networks
│ └─ 多智能体(MARL):QMIX, AlphaStar
└─ 扩展目标:
├─ 约束RL:拉格朗日乘数法
└─ 多目标RL:帕累托优化
各算法适用场景建议
- 离散动作、简单环境:Q-learning、DQN(如Atari游戏)。
- 连续动作、高维状态:SAC(稳定且探索性好)、PPO(通用强鲁棒性)。
- 样本效率优先:Model-Based(如MBPO)、Offline RL(如CQL)。
- 多智能体协作/竞争:CTDE方法(如QMIX)、独立学习(小规模场景)。
- 复杂决策与规划:MuZero(围棋、星际争霸)、分层RL(机器人复杂任务)。
通过以上分类,可根据具体问题的环境特性(模型已知否、动作空间类型)、数据条件(在线交互 vs 离线数据)、任务目标(单智能体 vs 多智能体,是否有约束)选择合适的算法框架。
附录三:策略算法
策略算法
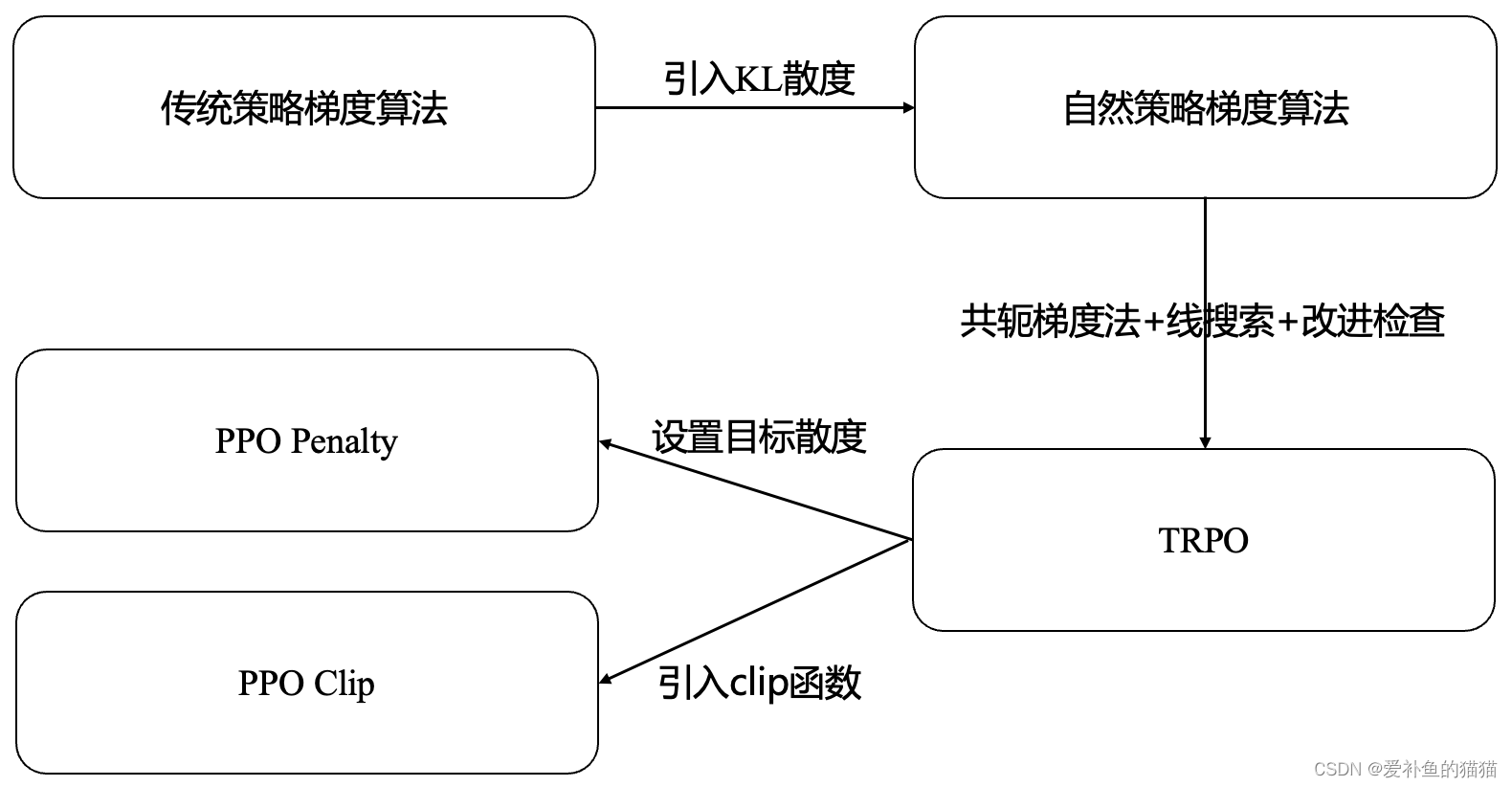
数据期望E
https://zhuanlan.zhihu.com/p/481760712
离散型随机变量的一切可能的取值与对应的概率乘积之和称为该离散型随机变量的数学期望 [2](若该求和绝对收敛),记为E(x)




贝尔曼方程
https://blog.csdn.net/qq_39160779/article/details/107289652
https://bbs.pinggu.org/thread-7248238-1-1.html
https://blog.csdn.net/Mocode/article/details/130383093
https://blog.csdn.net/Catherine_he_ye/article/details/129108969
整个过程往Gt里面添加条件,条件数学期望。
贝尔曼方程,又叫动态规划方程,是以Richard Bellman命名的,表示动态规划问题中相邻状态关系的方程。某些决策问题可以按照时间或空间分成多个阶段,每个阶段做出决策从而使整个过程取得效果最优的多阶段决策问题,可以用动态规划方法求解。某一阶段最优决策的问题,通过贝尔曼方程转化为下一阶段最优决策的子问题,从而初始状态的最优决策可以由终状态的最优决策(一般易解)问题逐步迭代求解。存在某种形式的贝尔曼方程,是动态规划方法能得到最优解的必要条件。绝大多数可以用最优控制理论解决的问题,都可以通过构造合适的贝尔曼方程来求解。https://blog.csdn.net/qq_39160779/article/details/107289652
整个过程往Gt里面添加条件

动作值函数(Action-Value Function)和状态值函数(State-Value Function)是强化学习中两个关键的价值函数,用于评估智能体的行为和状态。以下是它们的定义以及区别:
-
动作值函数 :
定义: 表示在给定状态 下,采取动作 后获得的期望累积回报。
数学表示:
作用: 衡量在特定状态下采取某个动作的长期价值,帮助智能体做出最优的动作选择。 -
状态值函数 :
定义: 表示在给定状态下,从该状态开始按照某个策略采取动作所获得的期望累积回报。
数学表示:
作用: 衡量在特定状态下按照某个策略的长期价值,帮助智能体评估当前状态的好坏程度。
区别与联系:
区别: 动作值函数关注在给定状态下采取某个具体动作的价值,而状态值函数关注在给定状态下按照某个策略行动的总体价值。
联系: 动作值函数和状态值函数之间有关系,特别是在策略确定的情况下。对于某个状态 和动作,有 当且仅当智能体在状态 时选择采取动作 的概率为1。
链接:https://blog.csdn.net/qq_40718185/article/details/135035928
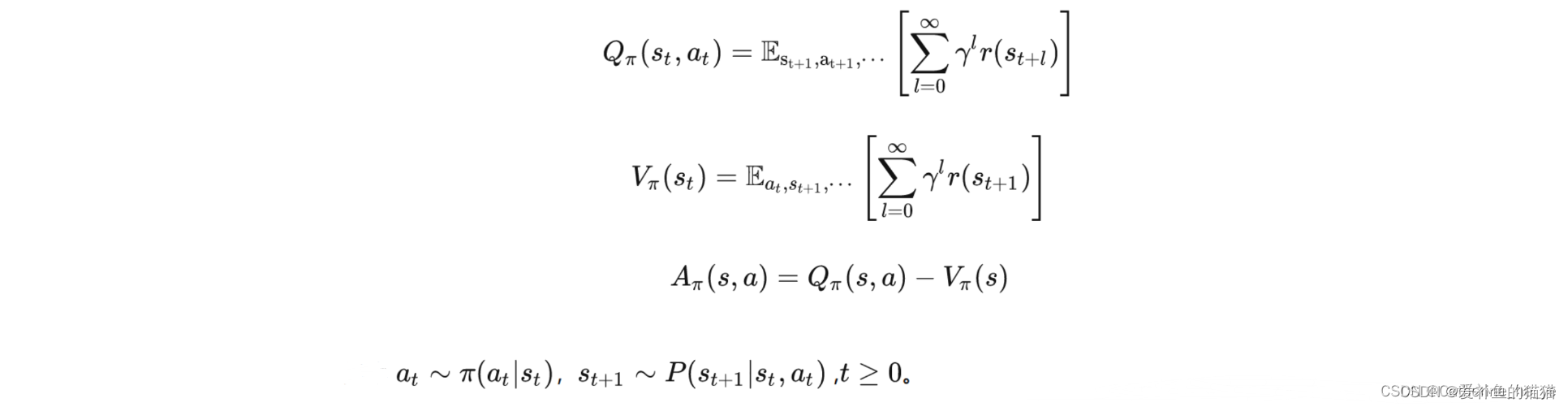


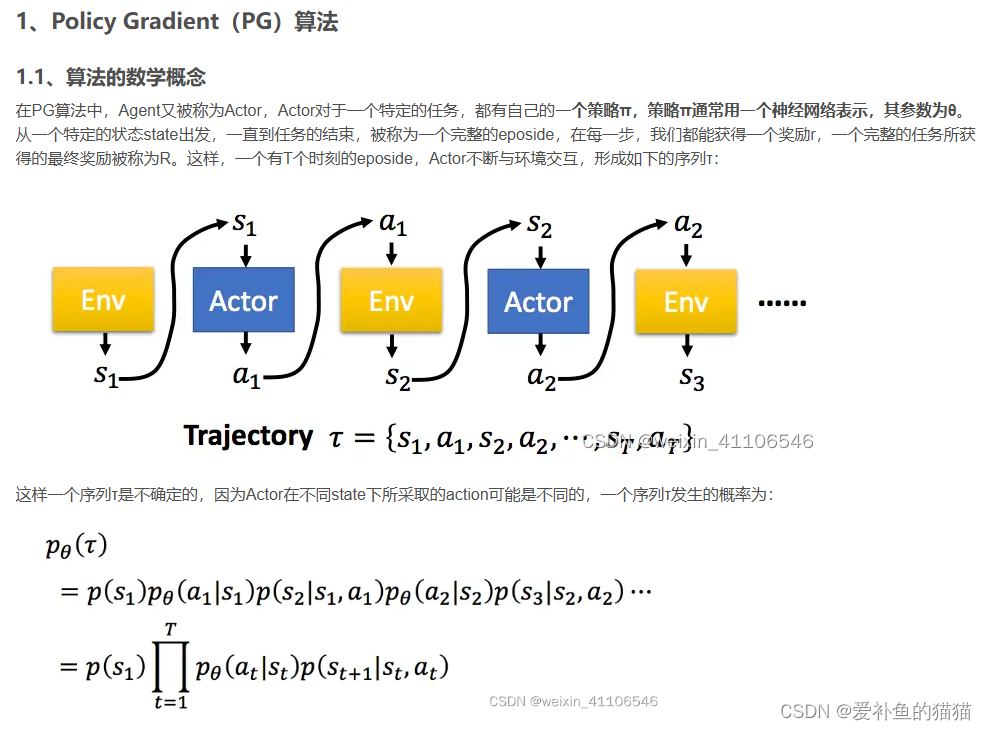
PG 策略梯度算法
目标值:对所有的奖励求期望,概率p通过上一个状态求得,类似马尔可夫求概率。
损失:通过求期望奖励最大化,求解策略的概率p的o参数。
在PG算法中,Agent又被称为Actor,Actor对于一个特定的任务,都有自己的一个策略π,策略π通常用一个神经网络表示,其参数为θ。从一个特定的状态state出发,一直到任务的结束,被称为一个完整的eposide,在每一步,我们都能获得一个奖励r,一个完整的任务所获得的最终奖励被称为R。这样,一个有T个时刻的eposide,Actor不断与环境交互。序列τ所获得的奖励为每个阶段所得到的奖励的和,称为R(τ)。因此,在Actor的策略为π的情况下,所能获得的期望奖励,而我们的期望是调整Actor的策略π,使得期望奖励最大化,于是有了策略梯度的方法,既然期望函数已经有了,只要使用梯度提升的方法更新我们的网络参数θ(即更新策略π)就好了,所以问题的重点变为了求参数的梯度。

自然策略梯度算法
解决梯度更新步长的问题,将∇ θ 前后的散度KL来计算更新的步长。
在传统的策略梯度算法中,我们根据目标函数梯度∇ θ J ( θ )和步长α更新策略权重θ ,这样的更新过程可能会出现两个常见的问题:
过冲(Overshooting):更新错过了奖励峰值并落入了次优策略区域
下冲(Undershooting):在梯度方向上采取过小的更新步长会导致收敛缓慢
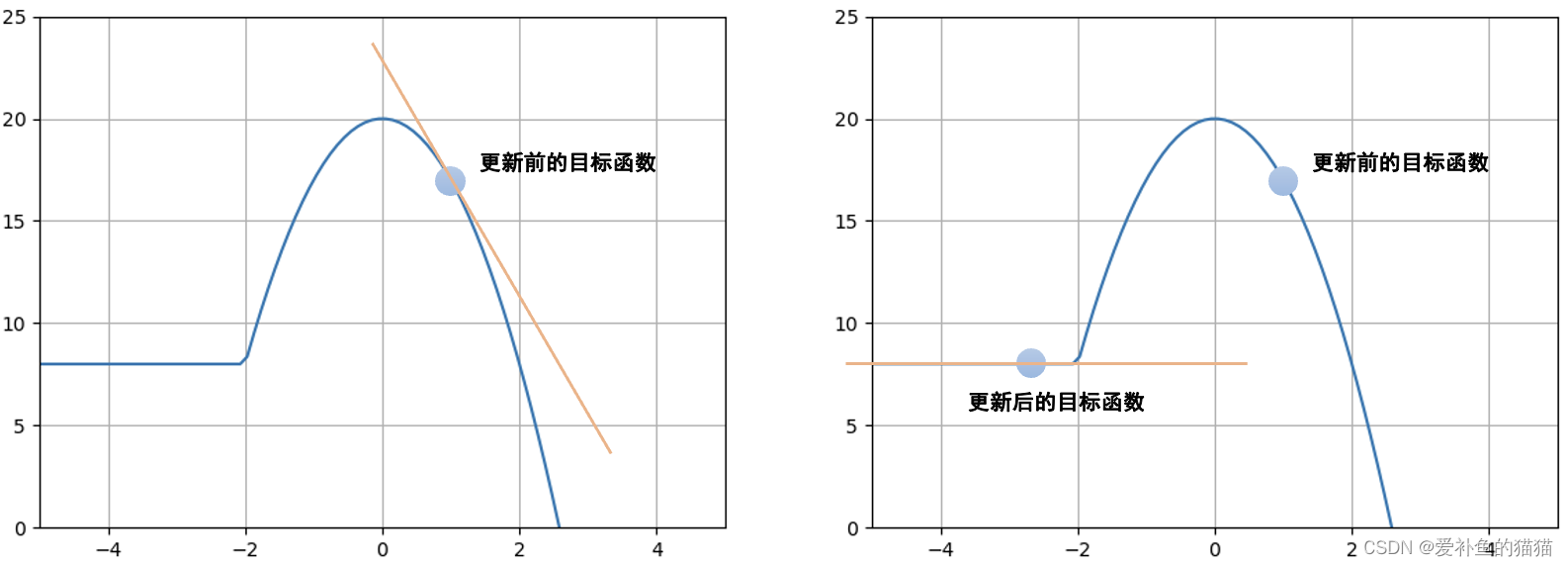
原因是不同的分布对参数变化的敏感度是不同的。比如在下图中,我们都让策略权重变化了1个单位的欧式距离,但是对左图的影响是远大于右图的。所以,只限制参数是不合理的,更应该考虑分布对参数变化的敏感度,传统的策略梯度算法无法考虑到这种曲率变化,我们需要引入二阶导数,这正是自然策略梯度相较于传统策略梯度算法的区别。
TRPO信任区域策略优化
RPO 与 PPO 不一样的地方是约束项的位置不一样,PPO 是直接把约束放到要优化的式子里,可以直接用梯度上升的方法最大化这个式子。但TRPO是把 KL 散度当作约束,它希望跟的 KL 散度小于一个。如果我们使用的是基于梯度的优化时,有约束是很难处理的,因为它把 KL 散度约束当做一个额外的约束,没有放目标里面。PPO 跟 TRPO 的性能差不多,但 PPO 在实现上比 TRPO 容易的多,所以我们一般就用 PPO,而不用TRPO。
TRPO是on-policy的,为什么这里采用IS?对于TRPO及PPO而言,虽然是基于on-policy的思想构建算法,但是对于on-policy而言,采样得到的数据仅训练一次就丢掉有些浪费,因此通常是将一次采样得到的经验数据分为多个minibatch进行训练,一般的还会sample reuse一下。如此一来,策略更新时所依赖的经验数据并非是实时采样得到的数据,这样就会造成一种off-policy的情况,因此就会引入importance sampling进行纠正。

PPO近端策略优化
通过散度KL用以另一个确定的分布q来拟合原来的分布p。
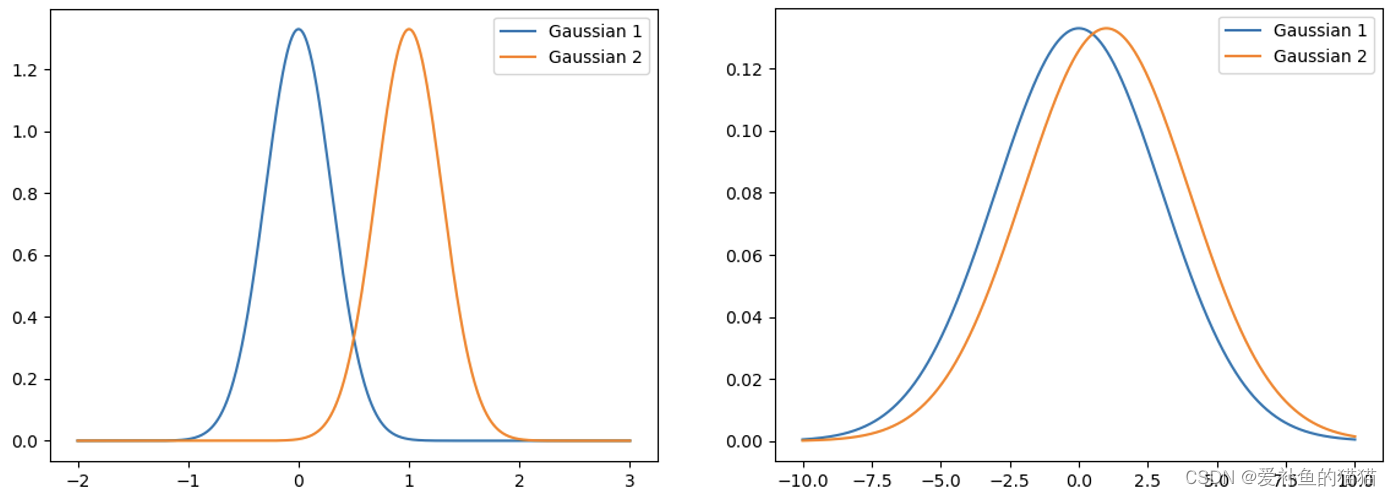
q(x)可以是任何分布。重要性采样有一些问题。虽然我们可以把p换成任何的q。但是在实现上,p和q不能差太多。差太多的话,会有一些问题。两个随机变量的平均值一样,并不代表它的方差一样,可以带入方差公式。
PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个agent;与之对应的就是off-policy的策略,即想要训练的agent和与环境进行交互的agent不是同一个agent,简单来说,就是拿别人的经验来训练自己。
举个下棋的例子,如果你是通过自己下棋来不断提升自己的棋艺,那么就是on-policy的,如果是通过看别人下棋来提升自己,那么就是off-policy的。

TRPO和PPO对比
https://blog.csdn.net/zuzhiang/article/details/103650805

DPO
https://blog.csdn.net/qq_55736201/article/details/138923673
DPO(直接偏好优化)简化了RLHF流程。它的工作原理是创建人类偏好对的数据集,每个偏好对都包含一个提示和两种可能的完成方式——一种是首选,一种是不受欢迎。然后对LLM进行微调,以最大限度地提高生成首选完成的可能性,并最大限度地减少生成不受欢迎的完成的可能性。与传统的微调方法相比,DPO 绕过了建模奖励函数这一步,设计一种包含正负样本对比的损失函数,通过直接在偏好数据上优化模型来提高性能。(即不训练奖励模型,语言模型直接做偏好优化)。
DPO(Direct Preference Optimization)的核心思想是直接优化语言模型(LM)以符合人类偏好,而不是首先拟合一个奖励模型然后使用强化学习(RL)进行优化。这是通过对偏好学习问题进行重新参数化来实现的,其中使用了一个简单的二元交叉熵目标函数来直接从人类偏好中训练LM。
DPPO(Distributed Proximal Policy Optimization)简单来说就是多线程并行版的 PPO。相应的代码是按照莫烦的教程来写的,使用了和 A3C 算法类似的网络结构。但是与 A3C 算法不同的是,A3C 算法是副网络与主网络有着相同的网络结构,并用副网络计算出来的梯度更新主网络的参数,更新完后再将主网络的参数同步给副网络。链接:https://blog.csdn.net/zuzhiang/article/details/103650805
传统 RLHF 与 DPO 比较
https://www.cnblogs.com/mengrennwpu/p/17999027
人类反馈强化学习 (RLHF) 是一种机器学习技术,它利用人类的直接反馈来训练“奖励模型”,然后利用该模型通过强化学习来优化人工智能代理的性能。

上图左边是RLHF算法,右边为DPO算法,两图的差异对比即可体现出DPO的改进之处。
-
RLHF算法包含奖励模型(reward model)和策略模型(policy model,也称为演员模型,actor model),基于偏好数据以及强化学习不断迭代优化策略模型的过程。
-
DPO算法不包含奖励模型和强化学习过程,直接通过偏好数据进行微调,将强化学习过程直接转换为SFT过程,因此整个训练过程简单、高效,主要的改进之处体现在于损失函数。
PS:
3. 偏好数据,可以表示为三元组(提示语prompt, 良好回答chosen, 一般回答rejected)。论文中的chosen表示为下标w(即win),rejected表示为下标l(即lose)
4. RLHF常使用PPO作为基础算法,整体流程包含了4个模型,且通常训练过程中需要针对训练的actor model进行采样,因此训练起来,稳定性、效率、效果不易控制。
-
- actor model/policy model: 待训练的模型,通常是SFT训练后的模型作为初始化
-
- reference model: 参考模型,也是经SFT训练后的模型进行初始化,且通常与actor model是同一个模型,且模型冻结,不参与训练,其作用是在强化学习过程中,保障actor model与reference model的分布差异不宜过大。
-
- reward model: 奖励模型,用于提供每个状态或状态动作对的即时奖励信号。
-
- Critic model: 作用是估计状态或状态动作对的长期价值,也称为状态值函数或动作值函数。
- DPO算法仅包含RLHF中的两个模型,即演员模型(actor model)以及参考(reference model),且训练过程中不需要进行数据采样。
现有方法:传统上,语言模型通过使用标注的人类偏好数据来进行训练,以展现所期望的行为。这些偏好代表了被认为是安全和有帮助的行为类型。这个训练过程分为两个阶段:首先是在大型文本数据集上的无监督预训练,然后是偏好学习阶段。基本的方法是使用高质量的人类演示进行监督微调。但是,最成功的方法使用来自人类(或AI)反馈的强化学习(RLHF/RLAIF)。RLHF通过将奖励模型拟合到人类偏好的数据集上来工作。然后使用强化学习优化这个模型,产生高奖励的响应,而不会过于偏离原始模型。尽管RLHF是有效的,但它在涉及多个语言模型训练的复杂性上是计算成本高昂的。
直接偏好优化 (DPO):本文引入了DPO,一种基于人类偏好优化语言模型的新方法。与RLHF不同,DPO不依赖于明确的奖励建模或强化学习。它针对与RLHF相同的目标,但提供了一种更简单、更直接的培训方法。DPO的工作原理是增加偏好样本的对数概率与减小非偏好样本响应的对数概率。它结合了动态加权机制,以避免仅使用概率比目标时遇到的模型退化问题。
交叉熵
https://www.cnblogs.com/wangguchangqing/p/12068084.html
信息量是衡量某个事件的不确定性,而熵是衡量一个系统(所有事件)的不确定性。
熵是信息量的期望值,是一个随机变量(一个系统,事件所有可能性)不确定性的度量。熵值越大,随机变量的取值就越难确定,系统也就越不稳定;熵值越小,随机变量的取值也就越容易确定,系统越稳定。




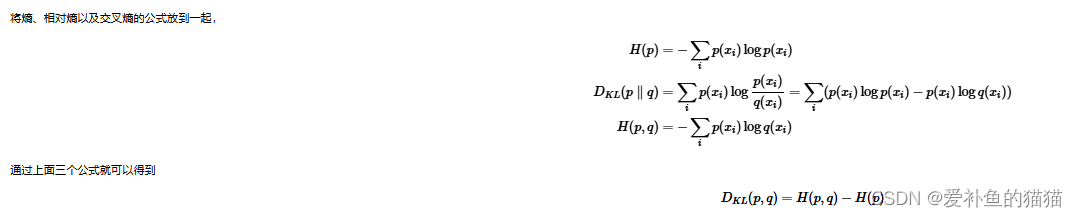
交叉熵损失函数(CrossEntropy Loss)
https://blog.csdn.net/weixin_43786241/article/details/109154274


原理
https://zhuanlan.zhihu.com/p/653975451
理论基础:DPO依赖于理论上的偏好模型,如Bradley-Terry模型,来测量奖励函数与经验偏好数据的对齐程度。与传统方法不同,传统方法使用偏好模型来训练奖励模型,然后基于该奖励模型训练策略,DPO直接根据策略定义偏好损失。给定一个关于模型响应的人类偏好数据集,DPO可以使用简单的二元交叉熵目标来优化策略,无需在培训过程中明确学习奖励函数或从策略中采样。
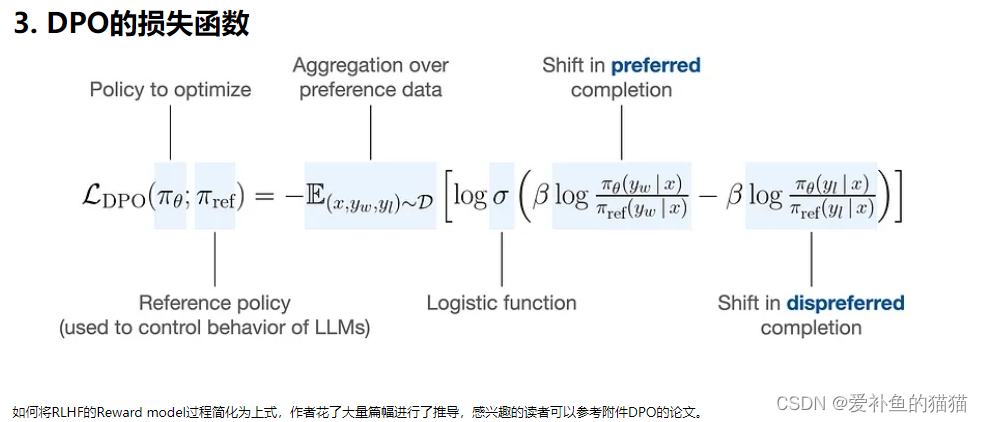
从PPO目标推导出目标优化策略DPO




DPO/IPO/KTO/SimPO
https://blog.csdn.net/beingstrong/article/details/138973997
https://blog.csdn.net/Brilliant_liu/article/details/136871766
直接偏好优化(DPO)、身份偏好优化(IPO)和 Taversky Optimisation 优化(KTO)
在推荐系统中,DPO算法可以通过收集用户的直接反馈来优化推荐结果;IPO算法则可以利用用户的身份特征进行个性化推荐;而KTO算法则可以模拟人类的决策过程,提高推荐的准确性。当然,这三种算法也可以结合使用,以实现更好的优化效果。
-
对比:
至少从目前看来,DPO 是最稳健和性能最好的大语言模型对齐算法。KTO 也同样具有发展前景,因为 DPO 和 IPO 都需要成对偏好数据,而 KTO 可以应用于任何含有正负面标签的数据集。在这篇博客中,作者强调了在执行偏好对齐时选择正确的超参数的重要性。通过实验证明了 DPO 在成对偏好设置中优于 KTO,尽管有更强的理论保证,但 IPO 的性能似乎很差。 https://www.jiqizhixin.com/articles/2024-02-19 -
IPO

-
KTO
KTO直接最大化模型生成的效用而不是人类偏好的对数似然。它只需要关于输出是否可取的二进制信号,这使得它更容易用于实际场景,特别是在偏好数据稀缺且昂贵的情况下。实验证明,KTO的表现优于基于偏好的方法如DPO,并且即便在极端数据不平衡的情况下也能保持良好表现。作者还讨论了KTO的理论意义,并提出了未来在不同设置中发现最佳人类意识损失函数的研究方向。。通过研究经济学家Kahneman和Tversky关于人类决策的工作,设计了一种不需要像“输入X的输出A胜过输出B”这样的偏好的对齐方法。相反,对于输入X,我们只需要知道输出Y是可取的还是不可取的。这种单一反馈是丰富的:每个公司都有可以标记为可取(例如,销售成功)或不可取(例如,没有销售)的客户互动数据。
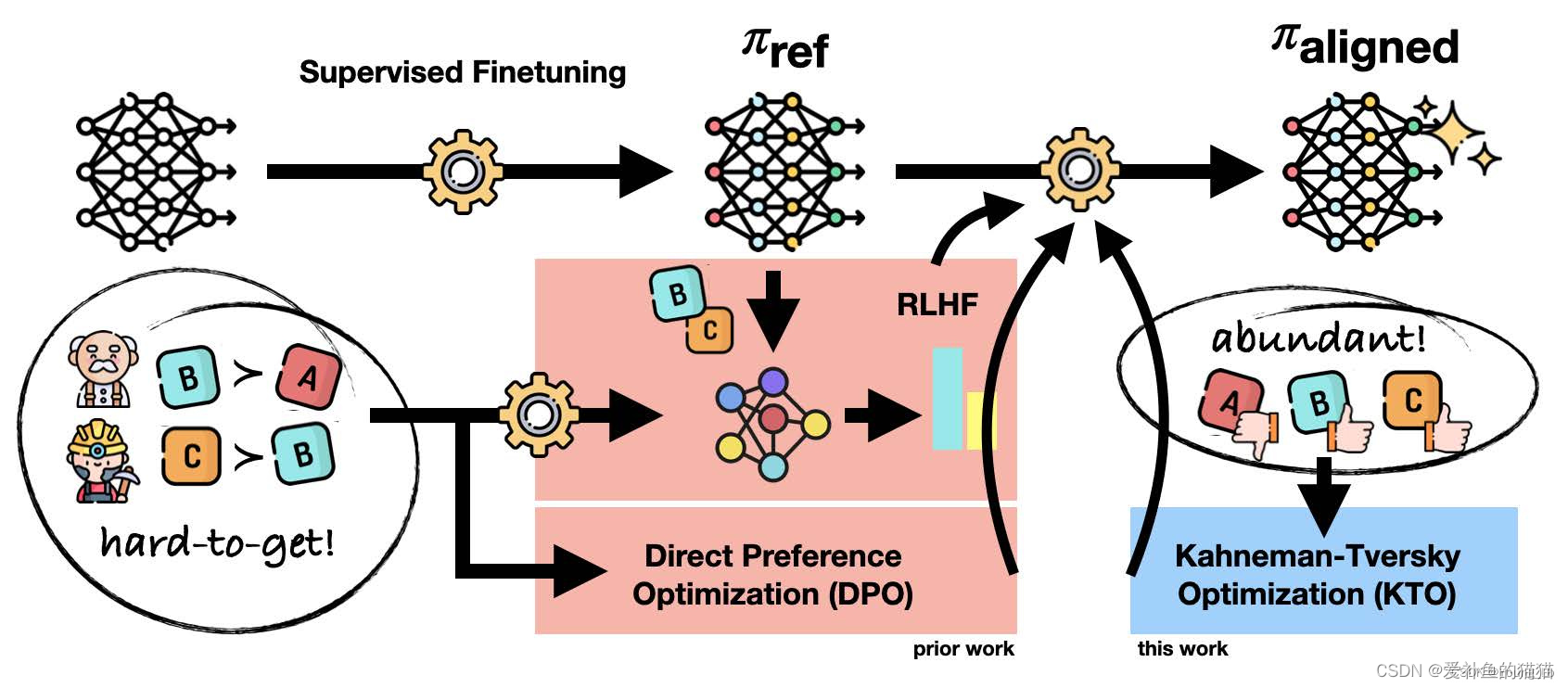
一、问题引入
本文通过“厌恶损失”引出了传统的偏好对其策略PPO、DPO、RLHF等都在一定程度上拟合了人的一部分偏好,导致大模型在某些场景下不会选择期望最大的决策。
Kahneman 和 Tversky 的前景理论解释了为什么人类在面对不确定事件时会做出无法最大化期望值的决策(1992)。 例如,由于人类是厌恶损失的,假设一场赌博以 80% 的概率返回 100 美元,以 20% 的概率返回 0 美元,不参加赌博直接返回60美元。在数学上,避免赌博的收益期望为60美元;而接受赌博的收益期望为0.8 * 100+0.2 * 0=80美元。大模型理论上应该选择期望最大的决策,即参加赌博;而大多数的人面对同样的场景则往往会选择不参加赌博直接获取60美元(即使这样的选择在数学上是期望更低的)。
因为人有很多类似的无法做出期望最大决策的场景,所以直接以人的偏好指导大模型的训练往往也会使大模型学到这种偏好,而无法做出期望收益更大的决策。
二、KTO与传统对齐策略的差异
1.传统对齐策略
传统的对齐策略如PPO、DPO、RLHF、SLiC等,训练数据往往是(x,y1,y2)三元组形式;其中的x为输入,y1、y2为两个输出(y1为更期望的输出)。
但是这种数据中包含了大量的人类偏好,数据本身可能就不是很合理。
场景一:如果某个场景下给出的两个答案,并没有绝对的y1好,y2不好,只是相对的y1由于y2。比如,当输入为:“一个人下班之后很累,他期望用什么交通工具回家?”,标注者可能将y1标为 “打车” 将y2标注为 “坐公交” ,但是这并不能说明 “坐公交” 是不可以接受的。
场景二:如果query只能给出一个好的结果,无法给出相对更差的结果。这种结果就无法被包括在偏好训练的数据集中。
链接:https://blog.csdn.net/Brilliant_liu/article/details/136871766 -
SimPO
https://www.jiqizhixin.com/articles/2024-05-27-8
使用 DPO 时,得到隐式奖励的方式是使用当前策略模型和监督式微调(SFT)模型之间的响应似然比的对数 的对数比。但是,这种构建奖励的方式并未与引导生成的指标直接对齐,该指标大约是策略模型所生成响应的平均对数似然。训练和推理之间的这种差异可能导致性能不佳。
SimPO 包含两个主要组件:(1)在长度上归一化的奖励,其计算方式是使用策略模型的奖励中所有 token 的平均对数概率;(2)目标奖励差额,用以确保获胜和失败响应之间的奖励差超过这个差额。总结起来,SimPO 具有以下特点:
简单:SimPO 不需要参考模型,因此比 DPO 等其它依赖参考模型的方法更轻量更容易实现;
性能优势明显:尽管 SimPO 很简单,但其性能却明显优于 DPO 及其最新变体(比如近期的无参考式目标 ORPO)。如图 1 所示。并且在不同的训练设置和多种指令遵从基准(包括 AlpacaEval 2 和高难度的 Arena-Hard 基准)上,SimPO 都有稳定的优势;



ORPO
ORPO是一种单步微调和对准指令llm的新方法。它不需要任何奖励或SFT模型,并且ORPO比DPO和RLHF更简单。根据论文ORPO的性能与DPO相当或略好。但是ORPO需要几千个训练步骤来学习好的和坏的反应之间的区别。
应该从现在开始使用ORPO吗?
如果想要一个简单有效的方法,ORPO是可以得。但是想要得到最好的结果,ORPO还不能完全的得到验证。因为目前还没有一个偏好优化方法的全面比较。但是我们可以从ORPO开始,因为他毕竟比较简单。
ORPO(直接相当于合并了监督微调SFT+RLHF)是另一种新的LLM对齐方法,这种方法甚至不需要SFT模型。通过ORPO,LLM可以同时学习回答指令和满足人类偏好。ORPO是一种新颖的微调技术,它将传统的监督微调和偏好对齐阶段整合到一个过程中。这减少了训练所需的计算资源和时间。SFT过程中,如果不加以控制,可能会增加生成不受欢迎风格文本的可能性。ORPO通过在SFT中引入赔率比损失来解决这个问题,从而在提高领域适应性的同时,避免学习到不良的生成风格。这点你如果做过SFT就会发现,因为SFT不同尺度的模型对数据集的质量和数量都存在比较高的要求,表现为你会发现有时候你的指令答案并不是按你所训练的预想去回答。

1.赔率比(Log Odds Ratio Term)以及LOSS函数
ORPO引进了赔率比,用来比较两个事件发生的概率比。在ORPO中,它用来比较生成更符合人类偏好响应和被拒绝响应的概率。
赔率比具有数学上的稳定性和敏感性(在常用的负对数似然损失(negative log-likelihood loss)中加入了一个简单的赔率比项。这个赔率比项是基于对数赔率的),使其成为在SFT(Supervised Fine-tuning)中结合偏好对齐的理想选择。

各种策略对比
https://blog.csdn.net/weixin_44119362/article/details/137239427
-
RLHF算法包含奖励模型(reward model)和策略模型(policy model,也称为演员模型,actor model),基于偏好数据以及强化学习不断迭代优化策略模型的过程。RLHF常使用PPO作为基础算法。
-
DPO算法不包含奖励模型和强化学习过程,直接通过偏好数据进行微调,将强化学习过程直接转换为SFT过程,因此整个训练过程简单、高效,主要的改进之处体现在于损失函数。直接偏好优化(DPO)、身份偏好优化(IPO)和 Taversky Optimisation 优化(KTO)。
DPO要通过SFT的模型和偏好数据集进行直接偏好回归优化的训练,不需要像RLHF一样通过训练RM模型再进行PPO优化训练,所以DPO从2023年下半年到目前为止都是模型提升性能的一个关键重要训练方式(事实上还有IPO\KTO,但DPO的方式综合起来更稳定)。 -
ORPO(直接相当于合并了监督微调SFT+RLHF)是另一种新的LLM对齐方法,这种方法甚至不需要SFT模型。通过ORPO,LLM可以同时学习回答指令和满足人类偏好。ORPO是一种新颖的微调技术,它将传统的监督微调和偏好对齐阶段整合到一个过程中。这减少了训练所需的计算资源和时间。SFT过程中,如果不加以控制,可能会增加生成不受欢迎风格文本的可能性。ORPO通过在SFT中引入赔率比损失来解决这个问题,从而在提高领域适应性的同时,避免学习到不良的生成风格。这点你如果做过SFT就会发现,因为SFT不同尺度的模型对数据集的质量和数量都存在比较高的要求,表现为你会发现有时候你的指令答案并不是按你所训练的预想去回答。
- 稳定更新:
在强化学习中,SFT常用于确保活动策略(active policy)相对于旧策略(old policy)的稳定更新。在RLHF中,在PPO迭代中,SFT模型作为旧策略,有助于在训练过程中保持稳定性。而DPO则是通过数据去直接优化的,ORPO也是如此。 - 避免不良生成风格:
SFT过程中,如果不加以控制,可能会增加生成不受欢迎风格文本的可能性。ORPO通过在SFT中引入赔率比损失来解决这个问题,从而在提高领域适应性的同时,避免学习到不良的生成风格。这点你如果做过SFT就会发现,因为SFT不同尺度的模型对数据集的质量和数量都存在比较高的要求,表现为你会发现有时候你的指令答案并不是按你所训练的预想去回答。 - 效率和性能:
论文强调了SFT在提高算法效率和性能方面的重要性。通过直接在SFT中整合偏好对齐,ORPO能够以更少的计算资源和训练步骤达到有效的偏好对齐。 - 单步对齐,无需额外参考模型:
ORPO方法的一个创新之处是它不需要额外的参考模型来进行偏好对齐。这与传统的偏好对齐方法不同,后者通常需要一个参考模型来生成被拒绝的响应。SFT在ORPO中起到了核心作用,使得模型可以直接在训练数据上进行偏好学习。
总之,SFT在ORPO算法中的作用是多方面的,它不仅提高了模型对特定任务的适应性,还通过结合赔率比损失来引导模型学习人类的偏好,同时避免了不良生成风格的学习,并提高了训练过程的效率和性能。链接:https://blog.csdn.net/weixin_44119362/article/details/137239427
模型对齐
微调对齐的实质是调整token生成概率分布,即给定任意用户指令,改变其生成回复内容的token序列分布,让符合人类偏好(如3H标准:harmless 无害 + helpful 有用性 + 忠实性 honest)的回复得到较高的概率,反之较低概率。
对齐(Alignment),是指大语言模型(LLM)与人类意图的一致性。换言之,就是让LLM生成的结果更加符合人类的预期,包括遵循人类的指令,理解人类的意图,进而能产生有帮助的回答等。对齐是决定LLM能否在实际场景中得到真正应用的关键因素。因此,评估模型的对齐水平显得至关重要 —— 如果没有评估,我们就无法判断模型的优劣。
如何让大模型的能力和行为跟人类的价值、真实意图和伦理原则相一致,确保人类与人工智能协作过程中的安全与信任。这个问题被称为“价值对齐”(value alignment,或AI alignment)。价值对齐是AI安全的一个核心议题。
在一定程度上,模型的大小和模型的风险、危害成正相关,模型越大,风险越高,对价值对齐的需求也就越强烈。就当前而言,大模型的核心能力来源于预训练阶段,而且大模型在很大程度上基于整个互联网的公开信息进行训练,这既决定了它的能力,也决定了其局限性,互联网内容存在的问题都可能映射在模型当中。
一个没有价值对齐的大语言模型(LLM),可能输出含有种族或性别歧视的内容,帮助网络黑客生成用于进行网络攻击、电信诈骗的代码或其他内容,尝试说服或帮助有自杀念头的用户结束自己的生命,以及生产诸如此类的有害内容。因此,为了让大模型更加安全、可靠、实用,就需要尽可能地防止模型的有害输出或滥用行为。这是当前AI价值对齐的一项核心任务。

















 6916
6916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









