






前情提要:关于影像组学特征,网上大多数文献采用公开的pyradiomics包进行,想要了解有哪些特征,请移步官方文档,地址:https://pyradiomics.readthedocs.io/en/latest/
图像保存方式如下:

1、导入相关包:
import pandas as pd
import numpy as np
import radiomics
import skimage
import os
from radiomics import featureextractor
2、单个病例图像的组学特征提取(代码):
#提取单个特征
extractor = featureextractor.RadiomicsFeatureExtractor()#定义一个特征提取器
extractor.enableAllImageTypes()#设置图像类型:选择pyradiomics包里可以实现的所有图像类型,包括原始图像、指数变换、梯度变换、对数变换、小波特征、平方根、平方、lbp-2D、lbp-3D。
src_path = r'E:\pycharm\project\tiqu_features\multi\1.2-0\yanchi_src_tumor.nrrd'#存放原始图像的路径
label_path = r'E:\pycharm\project\tiqu_features\multi\1.2-0\yanchi_label_tumor.nrrd'#存放label标签的路径
###注意:原始图像和标签在同一个文件夹下
feature = extractor.execute(src_path,label_path)#提取特征
featureA = pd.DataFrame([feature])#转为表格形式
featureA.to_excel("1.2-0—yanchi-result.xlsx")#保存为excel表格
为了方便展示结果,在featureA = pd.DataFrame([feature])后面添加一行转置代码:featureA = np.transpose(featureA)
结果显示如下(仅展示了提取原始图像original的结果):

3、多个病例图像的特征提取(代码):
#批量提取特征:
path = r'E:\pycharm\project\tiqu_features\multi'#multi文件夹下存放多个病例的文件夹,每个病例文件夹下包含一个原始图像和一个label图像
folders = os.listdir(path)#创建一个multi文件夹下的list,便于后续的遍历
df = pd.DataFrame()#创建一个空表
extractor = featureextractor.RadiomicsFeatureExtractor()#定义提取器
extractor.enableAllImageTypes()#设置图像类型
for folder in folders:
#循环遍历每一个病例
print(folder)
imagefile = os.path.join(path,folder,'yanchi_src_tumor.nrrd')#获取原始图像路径
labelfile = os.path.join(path,folder,'yanchi_label_tumor.nrrd')#获取label图像路径
feature = extractor.execute(imagefile,labelfile)#提取特征
df_new = pd.DataFrame.from_dict(feature.values()).T#获取特征值,转为表格形式,并转置
df_new.columns = feature.keys()#获得特征名
df_new.insert(0,'ID',folder)#在表格第一列插入病例文件夹名称
df = pd.concat([df,df_new])#将所有病例放入一个表格中
df.to_excel(os.path.join(path,'yanchi_result.xlsx'))
结果如下: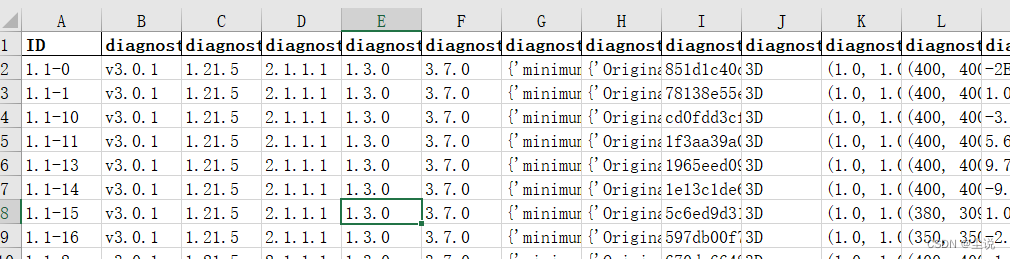
关于特征提取之后,数据分析之前的事:特征数据标准化。
1、导入相关包:
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
2、标准化:
path = r'E:\pycharm\project\features_select\before_standard.xlsx'#before_standard表示提取出来的特征,包含所有分类的特征
data = pd.read_excel(path)
x = data[data.columns[3:]]#x表示需要标准化的特征值。[3:]表示从第四列开始往后的所有列都需要标准化
y = data[data.columns[0:3]]#y表示不需要进行标准化的数据。[0:3]表示从第一列到第三列,(左闭右开,即0,1,2)不需要进行标准化
x_colNames = x.columns#获得x的名称
y_colNames = y.columns#获得y的
x = x.astype(np.float64)
x = StandardScaler().fit_transform(x)#标准化
x = pd.DataFrame(x)#转为表格形式
x.columns = x_colNames#获取特征名称
data_new = pd.concat([y,x],axis=1)#以左右的方式拼接y和x。
data_new.to_excel("Radiomics_standard.xlsx")
结果如下:
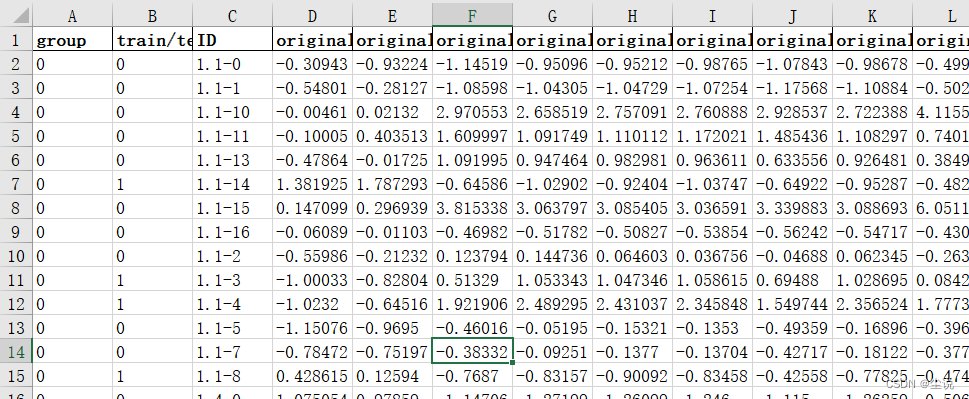














 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









