







文章目录
前言
perf的简单使用如下所示:Linux perf的使用(一)
Linux perf event事件如下图所示:
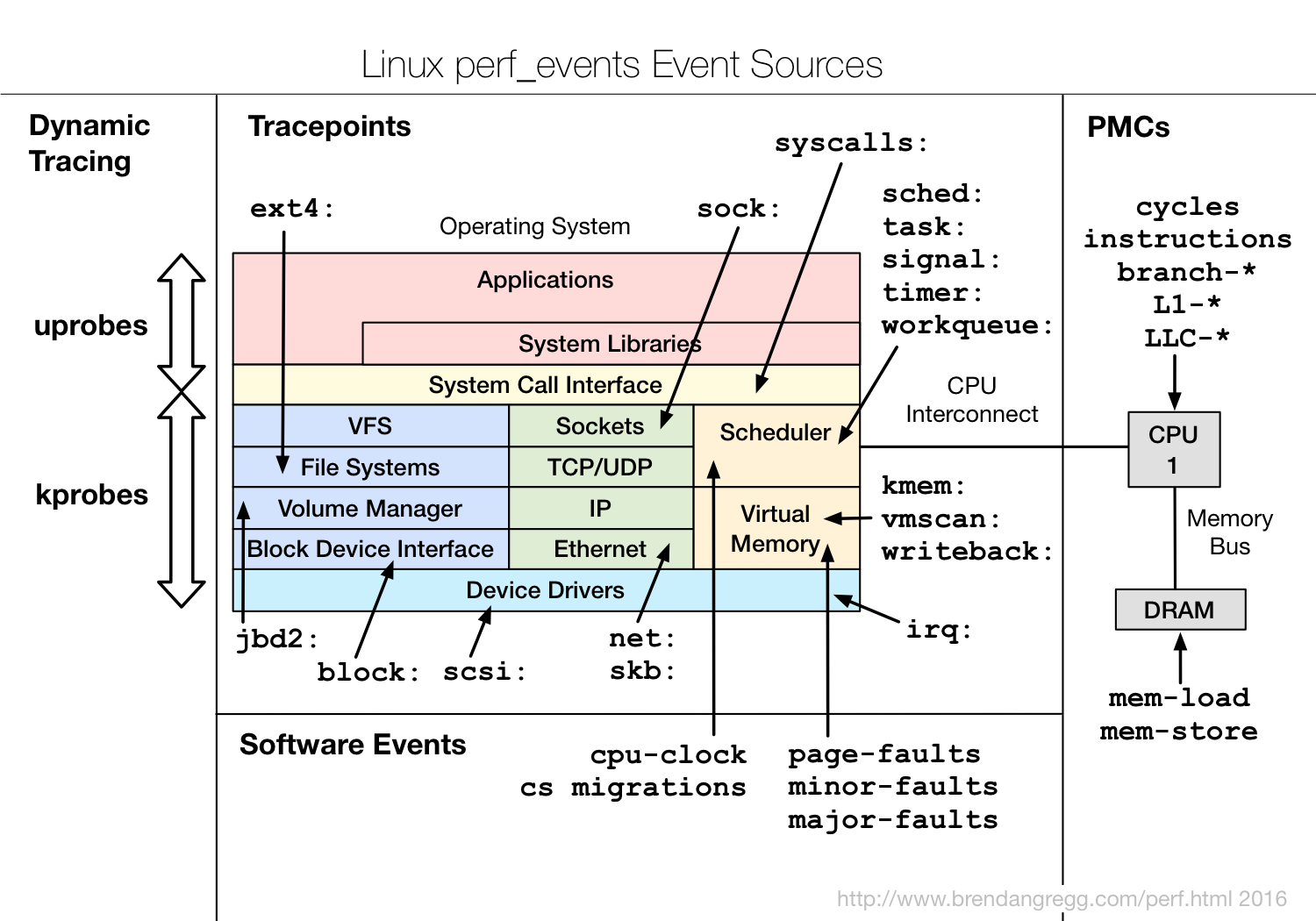
图片来自于:https://www.brendangregg.com/perf.html
事件类型包括:
Hardware Events:CPU性能监视计数器(CPU performance monitoring counters)。
Software Events:这些是基于内核计数器的低级事件。例如,CPU migrations, minor faults, major faults等。
Kernel Tracepoint Events:这是静态内核级的插入点,它们被硬编码在内核中比较重要的逻辑位置。
User Statically-Defined Tracing (USDT):这些是用户级程序和应用程序的静态跟踪点。
Dynamic Tracing:软件可以动态检测,在任何位置创建事件。对于内核软件,这使用kprobes框架。对于用户级软件,是uprobes框架。
Timed Profiling:可以使用perf-record-FHz以任意频率收集快照。这通常用于CPU使用情况分析,并通过创建自定义定时中断事件来工作。
通过perf可以收集有关上述事件的详细信息,包括时间戳、导致事件的代码路径以及其他特定的详细信息。perf_events的功能非常强大。
event是perf工作的基础,主要有两种:有使用硬件的PMU里的event,也有在内核代码中注册的event。
perf_event框架图如下所示:
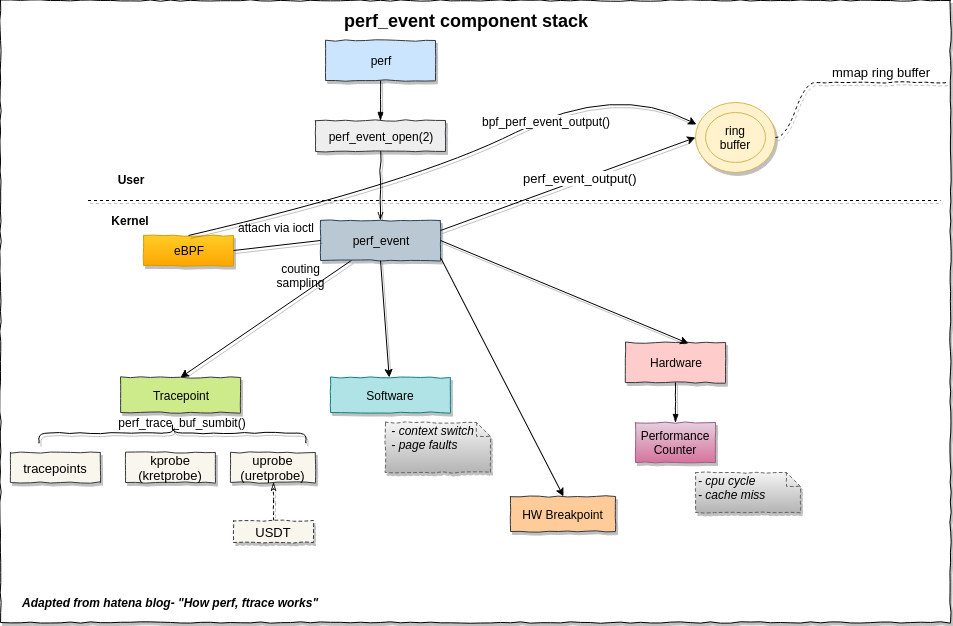
图片来自于:https://leezhenghui.github.io/linux/2019/03/05/exploring-usdt-on-linux.html
备注:Perf 通过系统调用perf_event_open()来完成对perf event的计数或者采样。
一、perf Events
可以使用list子命令列出当前可用的事件:
[root@localhost perf]# perf list
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
LLC-load-misses [Hardware cache event]
LLC-loads [Hardware cache event]
LLC-store-misses [Hardware cache event]
LLC-stores [Hardware cache event]
branch-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
iTLB-load-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
node-load-misses [Hardware cache event]
node-loads [Hardware cache event]
node-store-misses [Hardware cache event]
node-stores [Hardware cache event]
branch-instructions OR cpu/branch-instructions/ [Kernel PMU event]
branch-misses OR cpu/branch-misses/ [Kernel PMU event]
bus-cycles OR cpu/bus-cycles/ [Kernel PMU event]
cache-misses OR cpu/cache-misses/ [Kernel PMU event]
cache-references OR cpu/cache-references/ [Kernel PMU event]
cpu-cycles OR cpu/cpu-cycles/ [Kernel PMU event]
instructions OR cpu/instructions/ [Kernel PMU event]
intel_bts// [Kernel PMU event]
intel_pt// [Kernel PMU event]
mem-loads OR cpu/mem-loads/ [Kernel PMU event]
mem-stores OR cpu/mem-stores/ [Kernel PMU event]
......
rNNN [Raw hardware event descriptor]
cpu/t1=v1[,t2=v2,t3 ...]/modifier [Raw hardware event descriptor]
mem:<addr>[/len][:access] [Hardware breakpoint]
block:block_bio_backmerge [Tracepoint event]
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_frontmerge [Tracepoint event]
block:block_bio_queue [Tracepoint event]
block:block_bio_remap [Tracepoint event]
block:block_dirty_buffer [Tracepoint event]
block:block_getrq [Tracepoint event]
block:block_plug [Tracepoint event]
block:block_rq_abort [Tracepoint event]
block:block_rq_complete [Tracepoint event]
block:block_rq_insert [Tracepoint event]
block:block_rq_issue [Tracepoint event]
block:block_rq_remap [Tracepoint event]
block:block_rq_requeue [Tracepoint event]
block:block_sleeprq [Tracepoint event]
block:block_split [Tracepoint event]
block:block_touch_buffer [Tracepoint event]
block:block_unplug [Tracepoint event]
bridge:br_fdb_add [Tracepoint event]
bridge:br_fdb_external_learn_add [Tracepoint event]
bridge:br_fdb_update [Tracepoint event]
bridge:fdb_delete [Tracepoint event]
compaction:mm_compaction_isolate_freepages [Tracepoint event]
compaction:mm_compaction_isolate_migratepages [Tracepoint event]
compaction:mm_compaction_migratepages [Tracepoint event]
context_tracking:user_enter [Tracepoint event]
context_tracking:user_exit [Tracepoint event]
devlink:devlink_hwmsg [Tracepoint event]
......
事件类型包括:
■ Hardware event: Mostly processor events (implemented using PMCs)
■ Software event: A kernel counter event
■ Hardware cache event: Processor cache events (PMCs)
■ Kernel PMU event: Performance Monitoring Unit (PMU) events (PMCs)
■ cache, floating point...: Processor vendor events (PMCs) and brief descriptions
■ Raw hardware event descriptor: PMCs specified using raw codes
■ Hardware breakpoint: Processor breakpoint event
■ Tracepoint event: Kernel static instrumentation events
■ SDT event: User-level static instrumentation events (USDT)
■ pfm-events: libpfm events (added in Linux 5.8)
跟踪点和SDT事件主要列出静态检测点,但如果您创建了一些动态检测探测,那么也会列出这些检测点。比如示例:probe:do_nanosleep被描述为基于kprobe的“跟踪点事件”。
从这里我们可以了解到event都有哪些类型, perf list 列出的每个event后面都有一个"[]“,里面写了这个event属于什么类型,比如"Hardware event”、"Software event"等。完整的event类型,我们在内核代码枚举结构perf_type_id里可以看到:
// include/uapi/linux/perf_event.h
*
* attr.type
*/
enum perf_type_id {
PERF_TYPE_HARDWARE = 0,
PERF_TYPE_SOFTWARE = 1,
PERF_TYPE_TRACEPOINT = 2,
PERF_TYPE_HW_CACHE = 3,
PERF_TYPE_RAW = 4,
PERF_TYPE_BREAKPOINT = 5,
PERF_TYPE_MAX, /* non-ABI */
};
uapi 文件夹:内核版本从3.5开始,Linux Kernel 里多了一个 uapi 文件夹。uapi 只是把内核用到的头文件和用户态用到的头文件分开。
请参考:https://tinylab.org/linux-kernel-uapi/
perf-list命令接受搜索子字符串作为参数。例如,列出包含“mem_load_l3”的事件:
[root@localhost perf]# perf list mem_load_l3
List of pre-defined events (to be used in -e):
cache:
mem_load_l3_hit_retired.xsnp_hit
[Retired load instructions which data sources were L3 and cross-core snoop hits in on-pkg core cache Supports address when precise (Precise event)]
mem_load_l3_hit_retired.xsnp_hitm
[Retired load instructions which data sources were HitM responses from shared L3 Supports address when precise (Precise event)]
mem_load_l3_hit_retired.xsnp_miss
[Retired load instructions which data sources were L3 hit and cross-core snoop missed in on-pkg core cache Supports address when precise (Precise event)]
mem_load_l3_hit_retired.xsnp_none
[Retired load instructions which data sources were hits in L3 without snoops required Supports address when precise (Precise event)]
这些是硬件事件(基于PMC),输出包括简要描述。(精确事件)是指基于事件的精确采样(PEBS)功能事件。
二、Software Events
2.1 Software event简介
Software event是定义在Linux内核代码中的几个特定的事件,比较典型的有进程上下文切换(内核态到用户态的转换)事件context-switches、发生缺页中断的事件page-faults、cpu-migrations等。
软件事件通常映射到硬件事件,但在软件中进行检测。与硬件事件一样,它们可能具有默认的采样频率,通常为4000,因此在使用record子命令时只捕获一个子集。
perf提供了少量固定的软件事件:
[root@localhost perf]# perf list
List of pre-defined events (to be used in -e):
......
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
......
// include/uapi/linux/perf_event.h
/*
* Special "software" events provided by the kernel, even if the hardware
* does not support performance events. These events measure various
* physical and sw events of the kernel (and allow the profiling of them as
* well):
*/
enum perf_sw_ids {
PERF_COUNT_SW_CPU_CLOCK = 0,
PERF_COUNT_SW_TASK_CLOCK = 1,
PERF_COUNT_SW_PAGE_FAULTS = 2,
PERF_COUNT_SW_CONTEXT_SWITCHES = 3,
PERF_COUNT_SW_CPU_MIGRATIONS = 4,
PERF_COUNT_SW_PAGE_FAULTS_MIN = 5,
PERF_COUNT_SW_PAGE_FAULTS_MAJ = 6,
PERF_COUNT_SW_ALIGNMENT_FAULTS = 7,
PERF_COUNT_SW_EMULATION_FAULTS = 8,
PERF_COUNT_SW_MAX, /* non-ABI */
};
手册页 perf_event_open 中也记录了这些内容:
The perf_event_attr structure provides detailed configuration information for the event being created.
struct perf_event_attr {
__u32 type; /* Type of event */
......
}
type This field specifies the overall event type. It has one of the following values:
PERF_TYPE_SOFTWARE
This indicates one of the software-defined events provided by the kernel (even if no hardware support is available).
If type is PERF_TYPE_SOFTWARE, we are measuring software events provided by the kernel. Set config to one of the following:
PERF_COUNT_SW_CPU_CLOCK
This reports the CPU clock, a high-resolution per-CPU timer.
PERF_COUNT_SW_TASK_CLOCK
This reports a clock count specific to the task that is running.
PERF_COUNT_SW_PAGE_FAULTS
This reports the number of page faults.
PERF_COUNT_SW_CONTEXT_SWITCHES
This counts context switches. Until Linux 2.6.34, these were all reported as user-space events, after that they are reported as happening in the kernel.
PERF_COUNT_SW_CPU_MIGRATIONS
This reports the number of times the process has migrated to a new CPU.
PERF_COUNT_SW_PAGE_FAULTS_MIN
This counts the number of minor page faults. These did not require disk I/O to handle.
PERF_COUNT_SW_PAGE_FAULTS_MAJ
This counts the number of major page faults. These required disk I/O to handle.
PERF_COUNT_SW_ALIGNMENT_FAULTS (since Linux 2.6.33)
This counts the number of alignment faults. These happen when unaligned memory accesses happen; the kernel can handle these but it reduces performance. This hap‐
pens only on some architectures (never on x86).
PERF_COUNT_SW_EMULATION_FAULTS (since Linux 2.6.33)
This counts the number of emulation faults. The kernel sometimes traps on unimplemented instructions and emulates them for user space. This can negatively impact
performance.
PERF_COUNT_SW_DUMMY (since Linux 3.12)
This is a placeholder event that counts nothing. Informational sample record types such as mmap or comm must be associated with an active event. This dummy event
allows gathering such records without requiring a counting event.
2.2 内核源码示例
内核源码中进程上下文切换事件context-switches:
/*
* context_switch - switch to the new MM and the new
* thread's register state.
*/
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
......
prepare_task_switch(rq, prev, next);
......
finish_task_switch(this_rq(), prev);
......
}
prepare_task_switch()
-->perf_event_task_sched_out()
{
perf_sw_event(PERF_COUNT_SW_CONTEXT_SWITCHES, 1, NULL, 0);
if (static_key_false(&perf_sched_events.key))
__perf_event_task_sched_out(prev, next);
}
}
finish_task_switch()
-->perf_event_task_sched_in()
{
if (static_key_false(&perf_sched_events.key))
__perf_event_task_sched_in(prev, task);
}
缺页中断的事件page-faults:
do_page_fault()
-->__do_page_fault()
{
/* Get the faulting address: */
address = read_cr2();
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, address);
}
2.3 Software event的使用
软件事件可能有默认周期。这意味着当您使用它们进行采样时,您是在采样事件的子集,而不是跟踪每个事件。您可以使用perf record-vv进行检查:
[root@localhost perf]# perf record -vv -e context-switches /bin/true
Using CPUID GenuineIntel-6-9E
intel_pt default config: tsc,mtc,mtc_period=3,psb_period=3,pt,branch
------------------------------------------------------------
perf_event_attr:
type 1
size 112
config 0x3
{ sample_period, sample_freq } 4000
sample_type IP|TID|TIME|PERIOD
disabled 1
inherit 1
mmap 1
comm 1
freq 1
enable_on_exec 1
task 1
sample_id_all 1
exclude_guest 1
mmap2 1
comm_exec 1
------------------------------------------------------------
sys_perf_event_open: pid 11021 cpu 0 group_fd -1 flags 0x8 = 4
sys_perf_event_open: pid 11021 cpu 1 group_fd -1 flags 0x8 = 5
sys_perf_event_open: pid 11021 cpu 2 group_fd -1 flags 0x8 = 6
sys_perf_event_open: pid 11021 cpu 3 group_fd -1 flags 0x8 = 8
mmap size 528384B
perf event ring buffer mmapped per cpu
Synthesizing TSC conversion information
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.017 MB perf.data ]
有关这些字段的说明,请参阅perf_event_open手册页。默认情况下,内核调整采样率,以便每秒捕获大约4000个上下文切换事件。如果您真的想全部记录,请使用-c 1:
-c, --count=
Event period to sample.
[root@localhost perf]# perf record -vv -e context-switches -c 1 /bin/true
Using CPUID GenuineIntel-6-9E
intel_pt default config: tsc,mtc,mtc_period=3,psb_period=3,pt,branch
------------------------------------------------------------
perf_event_attr:
type 1
size 112
config 0x3
{ sample_period, sample_freq } 1
sample_type IP|TID|TIME
disabled 1
inherit 1
mmap 1
comm 1
enable_on_exec 1
task 1
sample_id_all 1
exclude_guest 1
mmap2 1
comm_exec 1
------------------------------------------------------------
sys_perf_event_open: pid 14388 cpu 0 group_fd -1 flags 0x8 = 4
sys_perf_event_open: pid 14388 cpu 1 group_fd -1 flags 0x8 = 5
sys_perf_event_open: pid 14388 cpu 2 group_fd -1 flags 0x8 = 6
sys_perf_event_open: pid 14388 cpu 3 group_fd -1 flags 0x8 = 8
mmap size 528384B
perf event ring buffer mmapped per cpu
Synthesizing TSC conversion information
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.017 MB perf.data ]
注意记录每一个事件的数量和所涉及的开销,尤其是频繁的上下文切换。您可以使用perf-stat检查事件的速率,以便您可以估计将要捕获的数据量。
三、Hardware Events (PMCs)
[root@localhost perf]# perf list
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
......
[root@localhost perf]# perf stat
^C
Performance counter stats for 'system wide':
10641.642600 cpu-clock (msec) # 3.998 CPUs utilized
475 context-switches # 0.045 K/sec
34 cpu-migrations # 0.003 K/sec
3,505 page-faults # 0.329 K/sec
94,260,640 cycles # 0.009 GHz
54,033,265 instructions # 0.57 insn per cycle
10,901,207 branches # 1.024 M/sec
364,597 branch-misses # 3.34% of all branches
2.661520522 seconds time elapsed
处理器和其他设备通常支持用于观察活动的硬件计数器。主要来源是处理器,它们通常称为性能监视计数器(PMC)。它们也有其他名称:CPU性能计数器(CP)、性能检测计数器(PIC)和性能监视单元事件(PMU事件)。这些都指的是同一件事:处理器上的可编程硬件寄存器,它们在CPU周期级别提供低级别的性能信息。
PMC是性能分析的重要资源。只有通过PMC,您才能测量CPU指令的效率、CPU缓存的命中率、内存和设备总线的利用率、互连利用率、暂停周期等。使用这些来分析性能可能会导致各种性能优化。
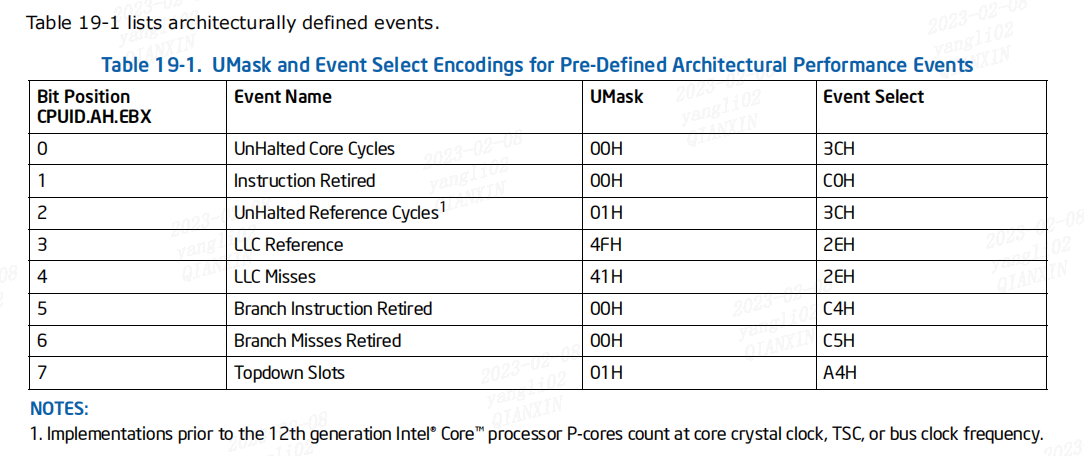
虽然有很多PMC,但Intel选择了上表中的事件作为“架构集”,提供了一些核心功能的高级概述。可以使用cpuid指令检查这些体系结构集PMC的存在。
支持架构性能监视的处理器可能不支持所有预定义的架构性能事件(表中所列举的事件),架构事件的数量通过CPUID.0AH:EAX[31:24].
在Linux上,PMC通过perf_event_open系统调用进行访问,并由包括perf在内的工具使用。
虽然有数百个PMC可用,但在CPU中只有固定数量的寄存器可用于同时测量它们,可能只有6个。您需要选择要在这六个寄存器上测量哪些PMC,或者循环使用不同的PMC集作为对它们进行采样的一种方式(Linux perf自动支持此功能)。其他软件计数器不会受到这些限制的影响。
PMC可以在不同的模式下使用:计数,在这种模式下,它们以几乎为零的开销来计数事件;以及溢出采样,在每一个可配置的事件数中就有一个事件发生中断,这样就可以捕获状态。计数可用于量化问题;溢出采样可用于显示负责的代码路径。
为了易于使用,perf提供了可替代使用的可读映射。例如,事件“branch-instructions”希望映射到系统上的分支指令PMC。其中一些人可读的名称在前面的列表中可见(硬件和PMU事件)。
将perf记录与PMC一起使用时,将使用默认采样频率,这样就不会记录所有事件。例如,记录周期事件:
root@localhost perf]# perf record -vve cycles -a sleep 1
Using CPUID GenuineIntel-6-9E
intel_pt default config: tsc,mtc,mtc_period=3,psb_period=3,pt,branch
------------------------------------------------------------
perf_event_attr:
size 112
{ sample_period, sample_freq } 4000
sample_type IP|TID|TIME|CPU|PERIOD
disabled 1
inherit 1
mmap 1
comm 1
freq 1
task 1
sample_id_all 1
exclude_guest 1
mmap2 1
comm_exec 1
------------------------------------------------------------
sys_perf_event_open: pid -1 cpu 0 group_fd -1 flags 0x8 = 4
sys_perf_event_open: pid -1 cpu 1 group_fd -1 flags 0x8 = 5
sys_perf_event_open: pid -1 cpu 2 group_fd -1 flags 0x8 = 6
sys_perf_event_open: pid -1 cpu 3 group_fd -1 flags 0x8 = 8
mmap size 528384B
perf event ring buffer mmapped per cpu
Synthesizing TSC conversion information
[ perf record: Woken up 1 times to write data ]
输出显示频率采样已启用(频率1),采样频率为4000。这告诉内核调整采样率,以便每台CPU每秒捕获大约4000个事件。这是可取的,因为某些PMC检测每秒可能发生数十亿次的事件(例如,CPU周期),并且记录每个事件的开销将令人望而却步。但这也是一个错误:perf的默认输出(没有非常详细的选项:-vv)并不表示正在使用频率采样,您可能希望记录所有事件。此事件频率仅影响记录子命令;stat统计所有事件。
可以使用-F选项修改事件频率,或者使用-c将事件频率更改为一个周期,该周期在每个周期中捕获一个事件(也称为溢出采样)。作为使用-F的示例:
perf record -F 99 -e cycles -a sleep 1
这将以99HZ(每秒事件数)的目标速率进行采样。
请注意,频率有限制,perf的CPU利用率也有限制,可以使用sysctl查看和设置:
[root@localhost perf]# sysctl kernel.perf_event_max_sample_rate
kernel.perf_event_max_sample_rate = 50000
[root@localhost perf]# cat /proc/sys/kernel/perf_event_max_sample_rate
50000
这表明该系统的最大采样率为50000Hertz。
[root@localhost perf]# sysctl kernel.perf_cpu_time_max_percent
kernel.perf_cpu_time_max_percent = 25
[root@localhost perf]# cat /proc/sys/kernel/perf_cpu_time_max_percent
25
perf(特别是PMU中断)允许的最大CPU利用率为25%。
四、Tracepoint Events
4.1 Tracepoint Events简介
这些跟踪点被硬编码在内核源码中较为重要,基于观测意义的位置,以便可以容易地跟踪更高级别的行为。例如,系统调用、TCP事件、文件系统I/O、磁盘I/O等。这些被分为跟踪点库;例如,“sock:”表示套接字事件,“sched:”表示CPU调度程序事件。跟踪点的一个关键价值是它们应该有一个稳定的API,所以如果您编写的工具在一个内核版本上使用它们,那么它们也应该在以后的版本上运行。
跟踪点通常通过放置include/trace/events/*中的宏添加到内核代码中。
关于Tracepoint简介请参考:Linux tracepoint 简介
4.2 Tracepoint Events的使用
[root@localhost perf]# perf list tracepoint
List of pre-defined events (to be used in -e):
block:block_bio_backmerge [Tracepoint event]
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_frontmerge [Tracepoint event]
block:block_bio_queue [Tracepoint event]
block:block_bio_remap [Tracepoint event]
block:block_dirty_buffer [Tracepoint event]
block:block_getrq [Tracepoint event]
block:block_plug [Tracepoint event]
block:block_rq_abort [Tracepoint event]
block:block_rq_complete [Tracepoint event]
block:block_rq_insert [Tracepoint event]
block:block_rq_issue [Tracepoint event]
block:block_rq_remap [Tracepoint event]
block:block_rq_requeue [Tracepoint event]
block:block_sleeprq [Tracepoint event]
block:block_split [Tracepoint event]
block:block_touch_buffer [Tracepoint event]
block:block_unplug [Tracepoint event]
bridge:br_fdb_add [Tracepoint event]
bridge:br_fdb_external_learn_add [Tracepoint event]
bridge:br_fdb_update [Tracepoint event]
bridge:fdb_delete [Tracepoint event]
compaction:mm_compaction_isolate_freepages [Tracepoint event]
compaction:mm_compaction_isolate_migratepages [Tracepoint event]
compaction:mm_compaction_migratepages [Tracepoint event]
......
在centos 7.6 发行版中,总结跟踪点库名称和跟踪点数量:
[root@localhost perf]# perf list | awk -F: '/Tracepoint event/ { lib[$1]++ } END {
> for (l in lib) { printf " %-16.16s %d\n", l, lib[l] } }' | sort | column
block 19 iommu 7 rcu 1
bridge 4 irq 5 regmap 15
compaction 3 irq_vectors 22 rpm 4
context_tracki 2 kmem 12 sched 23
devlink 1 kvm 55 scsi 5
dma_fence 8 kvmmmu 14 signal 2
drm 3 libata 6 skb 3
exceptions 2 mce 1 sock 2
filelock 6 migrate 2 sunrpc 31
filemap 2 module 5 syscalls 612
fs_dax 14 mpx 5 task 2
ftrace 1 napi 1 timer 13
gpio 2 net 9 ucsi 7
gvt 14 oom 1 udp 1
hda 5 pagemap 2 vmscan 15
hda_controller 6 power 20 vsyscall 1
hda_intel 4 printk 1 workqueue 4
hyperv 1 qdisc 1 writeback 25
i2c 8 random 15 xen 35
i915 39 ras 3 xfs 376
intel_ish 1 raw_syscalls 2 xhci-hcd 48
以下简单的一行计数系统调用执行的命令,并打印摘要(非零计数):
[root@localhost perf]# perf stat -e 'syscalls:sys_enter_*' gzip file 2>&1 | awk '$1 != 0'
Performance counter stats for 'gzip file':
1 syscalls:sys_enter_utimensat
1 syscalls:sys_enter_unlink
3 syscalls:sys_enter_newfstat
1 syscalls:sys_enter_lseek
2 syscalls:sys_enter_read
1 syscalls:sys_enter_write
1 syscalls:sys_enter_access
1 syscalls:sys_enter_fchmod
1 syscalls:sys_enter_fchown
4 syscalls:sys_enter_open
7 syscalls:sys_enter_close
4 syscalls:sys_enter_mprotect
1 syscalls:sys_enter_brk
1 syscalls:sys_enter_munmap
4 syscalls:sys_enter_rt_sigprocmask
12 syscalls:sys_enter_rt_sigaction
1 syscalls:sys_enter_exit_group
7 syscalls:sys_enter_mmap
0.000933241 seconds time elapsed
在系统范围内跟踪10秒并打印事件:
oot@ubuntu:/home/yl/study/perf# perf record -e block:block_rq_issue -a sleep 10; perf script
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.931 MB perf.data (153 samples) ]
kworker/u256:0- 5045 [002] 1264.855601: block:block_rq_issue: 0,0 N 8 () 0 + 0 [kworker/u256:0]
kworker/2:1H-ev 106 [002] 1266.331217: block:block_rq_issue: 8,0 WM 8192 () 1052672 + 16 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331300: block:block_rq_issue: 8,0 WM 4096 () 1052696 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331353: block:block_rq_issue: 8,0 WM 4096 () 1052720 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331409: block:block_rq_issue: 8,0 WM 4096 () 5246992 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331470: block:block_rq_issue: 8,0 WM 4096 () 22024200 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331521: block:block_rq_issue: 8,0 WM 4096 () 22024672 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331564: block:block_rq_issue: 8,0 WM 4096 () 22024712 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331600: block:block_rq_issue: 8,0 WM 4096 () 22026384 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331639: block:block_rq_issue: 8,0 WM 4096 () 22026568 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331672: block:block_rq_issue: 8,0 WM 4096 () 22295408 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331720: block:block_rq_issue: 8,0 WM 4096 () 42995712 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331768: block:block_rq_issue: 8,0 WM 12288 () 42995840 + 24 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331834: block:block_rq_issue: 8,0 WM 4096 () 42995968 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.331913: block:block_rq_issue: 8,0 WM 4096 () 42996096 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332091: block:block_rq_issue: 8,0 WM 4096 () 42996584 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332136: block:block_rq_issue: 8,0 WM 4096 () 42996744 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332180: block:block_rq_issue: 8,0 WM 4096 () 42996784 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332226: block:block_rq_issue: 8,0 WM 4096 () 42996904 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332260: block:block_rq_issue: 8,0 WM 4096 () 42997088 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332312: block:block_rq_issue: 8,0 WM 4096 () 42999216 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332353: block:block_rq_issue: 8,0 WM 4096 () 43000792 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332389: block:block_rq_issue: 8,0 WM 8192 () 43000872 + 16 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332423: block:block_rq_issue: 8,0 WM 4096 () 43000976 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332464: block:block_rq_issue: 8,0 WM 4096 () 43001328 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332493: block:block_rq_issue: 8,0 WM 12288 () 43001632 + 24 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332530: block:block_rq_issue: 8,0 WM 4096 () 43003072 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332580: block:block_rq_issue: 8,0 WM 32768 () 43003088 + 64 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332683: block:block_rq_issue: 8,0 WM 77824 () 43004512 + 152 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332819: block:block_rq_issue: 8,0 WM 4096 () 43061504 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.332926: block:block_rq_issue: 8,0 WM 4096 () 43062520 + 8 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.333026: block:block_rq_issue: 8,0 WM 8192 () 43130624 + 16 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.333089: block:block_rq_issue: 8,0 WM 16384 () 43130648 + 32 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.333136: block:block_rq_issue: 8,0 WM 24576 () 43130688 + 48 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.333239: block:block_rq_issue: 8,0 WM 12288 () 43130744 + 24 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.333310: block:block_rq_issue: 8,0 WM 12288 () 43130776 + 24 [kworker/2:1H]
kworker/2:1H-ev 106 [002] 1266.333352: block:block_rq_issue: 8,0 WM 16384 () 43130808 + 32 [kworker/2:1H]
......
打印此跟踪点的参数及其格式字符串(元数据摘要):
oot@ubuntu:/home/yl/study/perf# cat /sys/kernel/debug/tracing/events/block/block_rq_issue/format
name: block_rq_issue
ID: 1193
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:dev_t dev; offset:8; size:4; signed:0;
field:sector_t sector; offset:16; size:8; signed:0;
field:unsigned int nr_sector; offset:24; size:4; signed:0;
field:unsigned int bytes; offset:28; size:4; signed:0;
field:char rwbs[8]; offset:32; size:8; signed:1;
field:char comm[16]; offset:40; size:16; signed:1;
field:__data_loc char[] cmd; offset:56; size:4; signed:1;
print fmt: "%d,%d %s %u (%s) %llu + %u [%s]", ((unsigned int) ((REC->dev) >> 20)), ((unsigned int) ((REC->dev) & ((1U << 20) - 1))), REC->rwbs, REC->bytes, __get_str(cmd), (unsigned long long)REC->sector, REC->nr_sector, REC->comm
仅过滤大于65536字节的块I/O:
perf record -e block:block_rq_issue --filter 'bytes > 65536' -a sleep 10
跟踪由 “man ls” 命令触发的新进程:
[root@localhost perf]# perf list sched:sched_process_exec
List of pre-defined events (to be used in -e):
sched:sched_process_exec [Tracepoint event]
[root@localhost perf]# perf record -e sched:sched_process_exec -a
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.661 MB perf.data (59 samples) ]
[root@localhost perf]# perf report -n --sort comm --stdio
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 59 of event 'sched:sched_process_exec'
# Event count (approx.): 59
#
# Overhead Samples Command
# ........ ............ ...........
#
16.95% 10 grep
16.95% 10 head
8.47% 5 sleep
8.47% 5 tail
5.08% 3 df
5.08% 3 who
3.39% 2 bash
3.39% 2 consoletype
3.39% 2 grepconf.sh
3.39% 2 id
3.39% 2 lspci
3.39% 2 tty
3.39% 2 uname
1.69% 1 groff
1.69% 1 grotty
1.69% 1 less
1.69% 1 locale
1.69% 1 man
1.69% 1 nroff
1.69% 1 preconv
1.69% 1 tbl
1.69% 1 troff
#
# (Tip: Use parent filter to see specific call path: perf report -p <regex>)
#
4.3 Tracepoints Interface
跟踪工具可以通过tracefs中的跟踪事件文件(通常安装在/sys/kernel/debug/tracing)或perf_event_open系统调用来使用跟踪点。例如,基于Ftrace的iosnoop工具使用tracefs文件:
git clone --depth 1 https://github.com/brendangregg/perf-tools
root@localhost ~]# strace -e open,chdir perf-tools/bin/iosnoop
......
chdir("/sys/kernel/debug/tracing") = 0
open("/var/tmp/.ftrace-lock", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3
open("current_tracer", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3
open("buffer_size_kb", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3
open("events/block/block_rq_issue/enable", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3
open("events/block/block_rq_complete/enable", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3
......
对于较高版本的内核open系统调用发生了变化:
strace -e openat,chdir perf-tools/bin/iosnoop
输出包括指向tracefs目录的chdir和打开块跟踪点的“enable”文件。它还包括一个/var/tmp/.ftrace锁:这是编写的阻止并发工具用户的预防措施,tracefs接口不容易支持。
perf_event_open接口支持并发用户,并且在可能的情况下首选。同一工具的更新BCC版本使用该工具:
root@yl-virtual-machine:# strace -e perf_event_open /usr/share/bcc/tools/biolatency
perf_event_open({type=0x6 /* PERF_TYPE_??? */, size=PERF_ATTR_SIZE_VER7, config=0, sample_period=1, sample_type=0, read_format=0, precise_ip=0 /* arbitrary skid */, ...}, -1, 0, -1, PERF_FLAG_FD_CLOEXEC) = 7
perf_event_open({type=0x6 /* PERF_TYPE_??? */, size=PERF_ATTR_SIZE_VER7, config=0, sample_period=1, sample_type=0, read_format=0, precise_ip=0 /* arbitrary skid */, ...}, -1, 0, -1, PERF_FLAG_FD_CLOEXEC) = 9
......
perf_event_open是内核perf_events子系统的接口,它提供各种评测和跟踪功能。
4.4 Tracepoints Overhead
当跟踪点被激活时,它们会为每个事件增加少量的CPU开销。跟踪工具还可以增加后处理事件的CPU开销,以及记录事件的文件系统开销。开销是否高到足以干扰生产应用程序取决于事件的速率和CPU的数量,这是使用跟踪点时需要考虑的问题。
在当今的典型系统(4到128个CPU)上,发现低于每秒10000个的事件速率的开销可以忽略不计,只有超过100000个的开销才开始变得可测量。作为事件示例,您可能会发现磁盘事件通常小于每秒10000个,但调度程序事件可能远远超过每秒100000个,因此跟踪成本可能很高。
2018年在Linux 4.7中添加了一种新的跟踪点,称为原始跟踪点(raw tracepoints),它避免了创建稳定跟踪点参数的成本,从而减少了开销。
除了在使用跟踪点时启用的开销外,还有使跟踪点可用的禁用开销。禁用的跟踪点变为少量指令:对于x86_64,它是一个5字节无操作(nop)指令。在函数的末尾还添加了一个跟踪点处理程序,这会稍微增加它的文本大小。虽然这些开销很小,但在向内核添加跟踪点时,应该分析和理解这些开销。
4.5 User-Level Statically Defined Tracing (USDT)
与内核跟踪点类似,用户级静态定义跟踪(USDT)是 tracepoints 的用户空间版本。
USDT 与 uprobes 的关系类似于 tracepoints 与 kprobes 之间的关系。
USDT 和 tracepoints 是硬编码在源码中,是稳定的API,开销较小,跟踪点数量较少。
而uprobes和kprobes是修改运行代码的指令,以便在需要时插入指令,使用时有一定的开销,可以跟踪的数量很多。
一些应用程序和库在其代码中添加了USDT探针,为跟踪应用程序级事件提供了一个稳定的(和文档化的)API。这些跟踪点在应用程序源代码中的重要逻辑位置进行硬编码(通常通过放置宏),并作为一个稳定的API呈现(事件名称和参数)。许多应用程序已经包含了跟踪点,这些跟踪点是为了支持DTrace而添加的。例如,Java JDK、PostgreSQL数据库和libc中都有USDT探针。
然而,许多这些应用程序在默认情况下不会在Linux上编译它们。通常需要使用–withdtrace标志自己编译应用程序。
例如,使用此版本的Node.js编译USDT事件:
ubuntun下:
$ sudo apt-get install systemtap-sdt-dev # adds "dtrace", used by node build
由于我已经在centos 7上安装了systemtap,编译node.js即可(–with-dtrace)。
$ wget https://nodejs.org/dist/v4.4.1/node-v4.4.1.tar.gz
$ tar xvf node-v4.4.1.tar.gz
$ cd node-v4.4.1
$ ./configure --with-dtrace
$ make -j 8
要检查生成的节点二进制文件是否包含探测,请执行以下操作:
[root@localhost node-v4.4.1]# readelf -n node
Displaying notes found at file offset 0x00000254 with length 0x00000020:
Owner Data size Description
GNU 0x00000010 NT_GNU_ABI_TAG (ABI version tag)
OS: Linux, ABI: 2.6.32
Displaying notes found at file offset 0x00000274 with length 0x00000024:
Owner Data size Description
GNU 0x00000014 NT_GNU_BUILD_ID (unique build ID bitstring)
Build ID: 7cb25e0287bec225698aa0e38de31fdad07b0abf
Displaying notes found at file offset 0x00e67bc8 with length 0x000003c4:
Owner Data size Description
stapsdt 0x0000003c NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: gc__start
Location: 0x0000000000d98f74, Base: 0x000000000111133c, Semaphore: 0x0000000001467b94
Arguments: 4@%esi 4@%edx 8@%rdi
stapsdt 0x0000003b NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: gc__done
Location: 0x0000000000d98f84, Base: 0x000000000111133c, Semaphore: 0x0000000001467b96
Arguments: 4@%esi 4@%edx 8@%rdi
stapsdt 0x00000068 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: net__server__connection
Location: 0x0000000000d99251, Base: 0x000000000111133c, Semaphore: 0x0000000001467b88
Arguments: 8@%rax 8@-1096(%rbp) -4@-1100(%rbp) -4@-1104(%rbp)
stapsdt 0x00000061 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: net__stream__end
Location: 0x0000000000d994d1, Base: 0x000000000111133c, Semaphore: 0x0000000001467b8a
Arguments: 8@%rax 8@-1096(%rbp) -4@-1100(%rbp) -4@-1104(%rbp)
stapsdt 0x00000089 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: http__server__request
Location: 0x0000000000d999c0, Base: 0x000000000111133c, Semaphore: 0x0000000001467b8c
Arguments: 8@%r14 8@%rax 8@-4328(%rbp) -4@-4332(%rbp) 8@-4288(%rbp) 8@-4296(%rbp) -4@-4336(%rbp)
stapsdt 0x00000067 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: http__server__response
Location: 0x0000000000d99c41, Base: 0x000000000111133c, Semaphore: 0x0000000001467b8e
Arguments: 8@%rax 8@-1096(%rbp) -4@-1100(%rbp) -4@-1104(%rbp)
stapsdt 0x00000089 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: http__client__request
Location: 0x0000000000d99f7b, Base: 0x000000000111133c, Semaphore: 0x0000000001467b90
Arguments: 8@%rax 8@%rdx 8@-2136(%rbp) -4@-2140(%rbp) 8@-2184(%rbp) 8@-2192(%rbp) -4@-2144(%rbp)
stapsdt 0x00000060 NT_STAPSDT (SystemTap probe descriptors)
Provider: node
Name: http__client__response
Location: 0x0000000000d9a20e, Base: 0x000000000111133c, Semaphore: 0x0000000001467b92
Arguments: 8@%rdx 8@-1096(%rbp) -4@%eax -4@-1104(%rbp)
五、perf vs strace
进一步解释一下区别:strace的当前实现使用ptrace()附加到目标进程,并在系统调用期间停止它,就像调试器一样,这可能会造成严重的开销。为了证明这一点,下面的系统调用重载程序使用perf和strace自行运行。我只列出了显示其性能的输出行:
[root@localhost perf]# dd if=/dev/zero of=/dev/null bs=512 count=10000k
10240000+0 records in
10240000+0 records out
5242880000 bytes (5.2 GB) copied, 9.13118 s, 574 MB/s
[root@localhost perf]# perf stat -e 'syscalls:sys_enter_*' dd if=/dev/zero of=/dev/null bs=512 count=10000k
10240000+0 records in
10240000+0 records out
5242880000 bytes (5.2 GB) copied, 12.1365 s, 432 MB/s
[root@localhost perf]# strace -c dd if=/dev/zero of=/dev/null bs=512 count=10000k
10240000+0 records in
10240000+0 records out
5242880000 bytes (5.2 GB) copied, 283.28 s, 18.5 MB/s
使用perf时,程序运行速度慢1.3倍。但有了strace,它跑得慢了32倍。这很可能是最坏的结果:如果系统调用不那么频繁,两种工具之间的差异就不会那么大。
最新版本的perf包含了trace子命令,以提供与strace类似的功能,但开销要低得多。
perf trace 于Linux 3.7内核版本主线引入:
perf trace是perf性能分析基础设施中新增的一个工具。该工具的设计灵感来自于广受欢迎的’strace’工具,但它不使用ptrace()系统调用,而是使用Linux的追踪基础设施。它的目的是使追踪对更广泛的Linux用户群体更加容易。
perf trace将显示与目标相关的事件,最初是系统调用,但也包括其他系统事件,如页面错误、任务生命周期事件、调度事件等。这个工具目前还处于早期版本,因此只支持实时模式,并且还有很多细节需要改进,但最终将与其他perf工具一样,能够处理perf.data文件,允许从分析阶段分离出来的“记录”进行后续分析。
参考资料
https://www.brendangregg.com/perf.html
perf trace, an alternative to strace
Systems.Performance.Enterprise.and.the.Cloud.2nd.Edition

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









