







 超级会员免费看
超级会员免费看
 本文介绍了NÜWA,一个统一的多模态预训练模型,支持图像和视频的视觉合成任务。该模型采用3D transformer编码器-解码器框架,并引入3D Nearby Attention机制,降低计算复杂度,提高生成质量。NÜWA在多个下游任务上表现出优越性能,展示出零样本学习能力。
本文介绍了NÜWA,一个统一的多模态预训练模型,支持图像和视频的视觉合成任务。该模型采用3D transformer编码器-解码器框架,并引入3D Nearby Attention机制,降低计算复杂度,提高生成质量。NÜWA在多个下游任务上表现出优越性能,展示出零样本学习能力。
21年11月,微软、北大联合发布了NUWA模型,一个统一通用的多模态预训练模型,在 8 个下游任务上效果惊艳。目前该项目已经发展成为一系列工作,而且都公开了源代码。

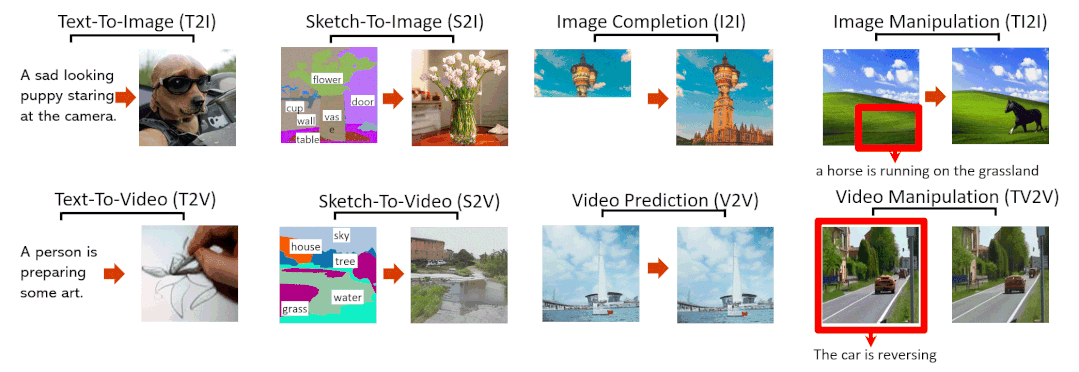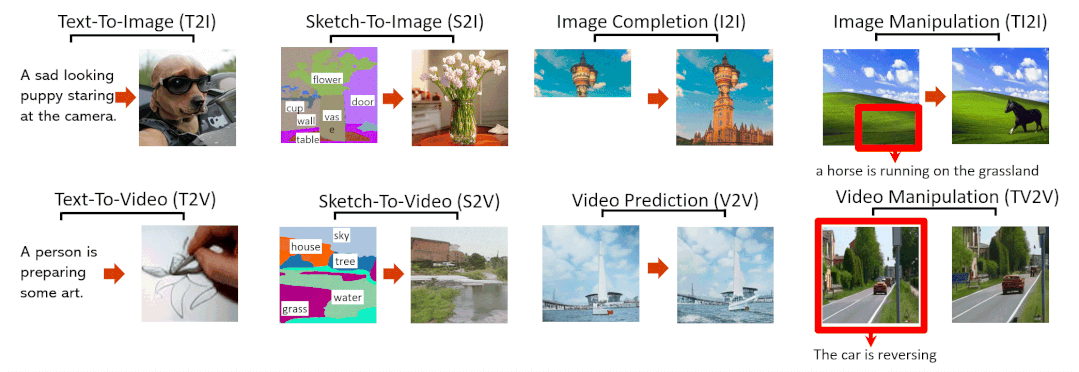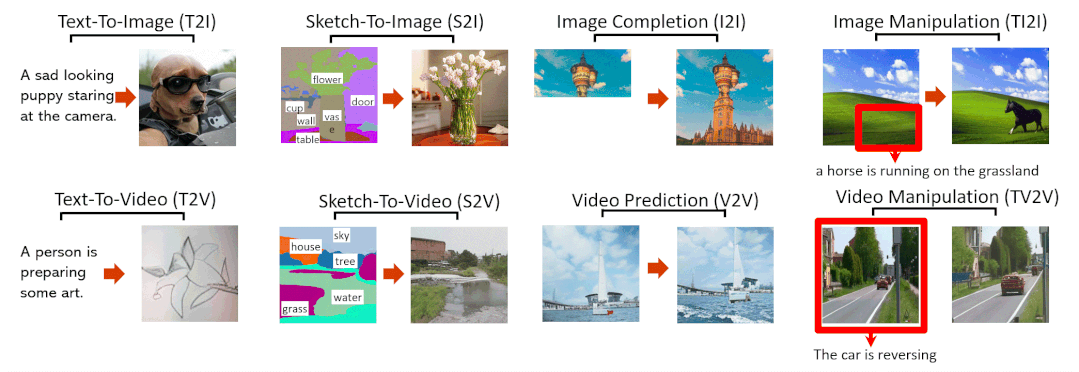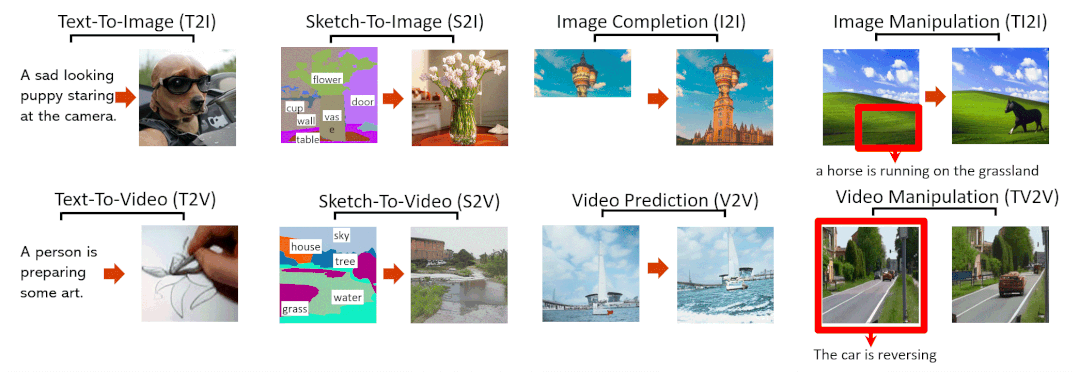
Abstract
本文提出了一种统一的多模态预训练模型N̈UWA,该模型可以实现各种视觉合成任务,包括生成新的或操作现有的视觉数据(即图像和视频)。为了同时处理不同场景的语言、图像和视频,本文设计了一个 3D transformer 编码器-解码器框架,它不仅可以将视频作为 3D 数据处理,还可以适配文本和图像作为 1D 和 2D 数据。考虑视觉数据的性质并降低计算复杂度,本文还提出了一种 3D Nearby Attention(3DNA)邻域自注意机制。我们在 8 个下游任务上评估了 N̈UWA,与几个强基线相比,N̈UWA在文生图像、文生视频、视频预测等方面取得

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1353
1353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











