






一、雅可比矩阵的定义:

雅可比矩阵是对多元函数的导数进行梯度扩展的一种矩阵表示。对于一个具有m个输入和n个输出的函数,雅可比矩阵的大小为n×m。雅可比矩阵中的每个元素表示了输出分量相对于输入分量的偏导数。
二、什么是自动求导?
自动求导是PyTorch的一项重要功能。 在计算过程中,PyTorch会为每个参与计算的张量建立一个计算图,用于记录计算过程中涉及的操作和张量之间的依赖关系,基于这个计算图,PyTorch可以根据链式法则自动计算函数的导数。
三、使用PyTorch的自动求导计算雅可比矩阵:
PyTorch的自动求导功能非常简单,只需要在需要求导的张量上调用.requires_grad_()方法。接下来,定义一个函数,该函数将需要计算雅可比矩阵的张量作为参数,并通过函数调用的方式计算该张量关于其他张量的偏导数。以下是一个示例:
import torch
def calculate_jacobian(x, y):
J = torch.zeros(y.size()[0], x.size()[0]) # 创建全零矩阵J,用于储存Jacobi矩阵,形状为(y的大小, x的大小),y在前,x在后,是因为Jacobi矩阵的定义,行数等于f的元素个数
grad_y = torch.zeros(y.size()) # 创建一个与 y 相同大小的全零向量,用于存储y的梯度
for i in range(y.size()[0]): # 遍历 y 的每个元素
grad_y.zero_() # 将 grad_y 清零
grad_y[i] = 1 # 再将grad_y的第i个元素设置为1,表示计算y中第i个元素的偏导数
x_grads = torch.autograd.grad(y, x, grad_outputs=grad_y, retain_graph=True, create_graph=True)[0]
# 使用torch.autograd.grad函数计算y关于x的偏导数
# grad_outputs参数用于指定计算过程中输出张量的梯度,默认为None,即所有输出的梯度都为1;
# retain_graph参数用于指定是否保留计算图,默认为False,即计算完一次偏导数后计算图将被释放;True表示保留计算图以便后续计算;
# create_graph参数用于指定是否创建一个计算图,用于计算二阶偏导数;True表示允许构建新的计算图以便梯度的梯度计算
J[i] = x_grads # 将计算得到的梯度x_grads存储到雅可比矩阵的第i行
return J
x = torch.tensor([2.0, 3.0], requires_grad=True)
y = x**2
J = calculate_jacobian(x, y)
print(J)
运行结果:
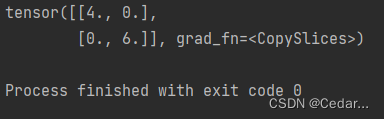
该输出实际上表示的是:
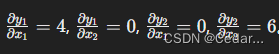
注:
1.如何理解代码中 y.size()[0] ?
在 PyTorch 中,y.size() 返回的是张量 y 的尺寸(shape),即一个包含张量每个维度大小的元组;y.size()[0] 则取这个元组的第一个元素,表示张量 y 的第一个维度的大小。具体来说,假设 y 是一个张量,它的形状为 (m, n),则:
y.size()返回(m, n);y.size()[0]返回m,即张量y的第一个维度的大小;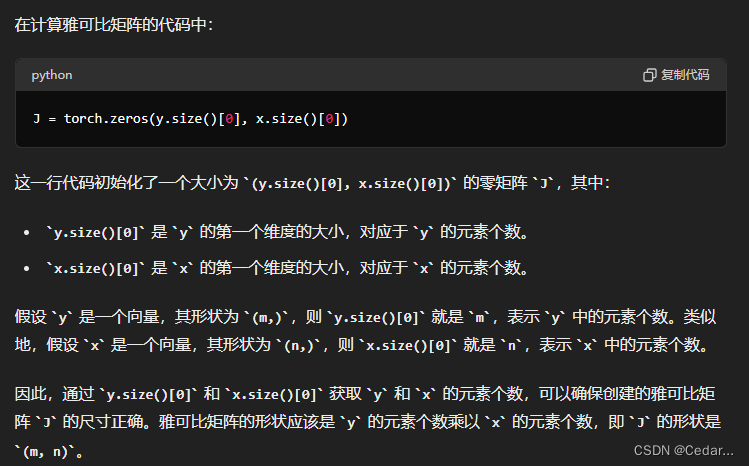

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









