







 本文详细介绍了多种基于对比学习的神经网络模型,如InstDisc、InvaSpread、CPC、CMC等,探讨了它们的结构、工作原理和效果。这些模型在无监督特征学习中扮演重要角色,利用数据增强和不同的编码策略来提升模型的表现。同时,文章还提到了LeetCode在算法学习中的重要性。
本文详细介绍了多种基于对比学习的神经网络模型,如InstDisc、InvaSpread、CPC、CMC等,探讨了它们的结构、工作原理和效果。这些模型在无监督特征学习中扮演重要角色,利用数据增强和不同的编码策略来提升模型的表现。同时,文章还提到了LeetCode在算法学习中的重要性。
🤵 Author :Horizon John
✨ 编程技巧篇:各种操作小结
🏆 神经网络篇:经典网络模型
💻 算法篇:再忙也别忘了 LeetCode
[ 对比学习篇 ] 经典网络模型 —— Contrastive Learning

🚀 01. InstDisc

📜 Paper: Unsupervised Feature Learning via Non-Parametric Instance Discrimination [CVPR 2018]
🖥️ GitHub: lemniscate.pytorch
🎨 结构框图

🚩 详解
- 每个图片看成一个类别;
- 利用
memory bank来存储图像经神经网络编码后的特征(128维); 正样本:该图像本身 + 经过数据增强后的图像;负样本:数据集中其他的图像(从 memory bank 中随机抽取4096个样本);
超参数设定:
- temperatureτ = 0.07;
- NCE with m = 4, 096 to balance performance and computing cost;
- trained for 200 epochs using SGD with momentum;
- batch size = 256;
- learning rate is initialized to 0.03, scaled down with coefficient 0.1 every 40 epochs after the first 120 epochs;
🚩 效果

🚀 02. InvaSpread

📜 Paper: Unsupervised Embedding Learning via Invariant and Spreading Instance Feature [CVPR 2019]
🖥️ GitHub: Unsupervised_Embedding_Learning
🎨 结构框图

🚩 详解
- 没有使用额外的数据结构去存储大量的样本信息;
- 正负样本都来自于同一个
minibatch; - 使用同一个编码器进行端到端的学习;
正样本:该图像本身 + 经过数据增强后的图像(2);负样本:其他图像 + 经过数据增强后的图像((batch size-1) × 2);- 未能取得很好结果原因:batch size 太小导致负样本数量较小;
🚩 效果

🚀 03. CPC

📜 Paper: Representation Learning with Contrastive Predictive Coding [None 2018]
🖥️ GitHub: None
🎨 结构框图

🚩 详解
- 可以应用于音频、图片、强化学习;
- 将输入当成序列,利用前面的输入通过 RNN 或 LSTM 等网络输出来进行预测;
正样本:预测结果;负样本:随机样本通过 genc 得到的结果;
🚩 效果

🚀 04. CMC

📜 Paper: Contrastive Multiview Coding [ECCV 2020]
🖥️ GitHub: CMC
🎨 结构框图

🚩 详解
- 增大不同视角之间的互信息(视觉、听觉、触觉);
- 数据集:NYU RGBD,包含原始图像、深度信息、SwAV ace normal、分割图像;
正样本:同一图像的不同视角;负样本:其他图像;- 缺点:不同视角下使用的编码器不一样,计算成本过高;
- 作者后来又提出了
不同网络得到的特征也应该尽可能相似; - 利用蒸馏网络(teacher net & student net);
🚀 05. MoCov1

📜 Paper: Momentum Contrast for Unsupervised Visual Representation Learning [CVPR 2020]
🖥️ GitHub: moco
🎨 结构框图


🚩 详解
- InstDisc 的改进;
- 提出了
队列(queue)来解决 memory bank 中的大字典的问题; - 提出了
动量编码器来解决 字典中特征不一致的问题; - 利用
动态字典对 队列中的特征进行存储,每一次更新得到的 k 都会取代最开始的 k 值; - 动量编码器:yt = m·yt-1 + (1-m)·xt 使输出不完全依赖于当前的输入,还会收到上一个输出的影响,0 ≤ m ≤ 1 ,实现缓慢的更新每一次新的到的 k 值,使字典中的特征尽可能的保持一致;
- 正负样本都位于 队列当中,确保正负样本都是由同一个编码器提取得到的;
🚩 效果

🚀 06. SimCLRv1

📜 Paper: A Simple Framework for Contrastive Learning of Visual Representations [ICML 2020]
🖥️ GitHub: simclr
🎨 结构框图

🚩 详解
- 增大数据增强的数量;
- 编码后的特征再经过一个
g(·) 函数(MLP层) 再求 loss 值,实现更好的训练 特征编码器; - 设置了更大的 batchsize;
- 训练时间更久;
🚩 效果



🚀 07. Mocov2

📜 Paper: Improved Baselines with Momentum Contrastive Learning [None 2020]
🖥️ GitHub: None
🎨 结构框图

🚩 详解
- 借鉴 SimCLRv1 的策略,添加了MLP层,使用了数据增强,训练时使用 cos learning rate schedule,训练更多epochs;
🚩 效果

🚀 08. SimCLRv2

📜 Paper: Big Self-Supervised Models are Strong Semi-Supervised Learners [NeurIPS 2020]
🖥️ GitHub: simclr
🎨 结构框图

🚩 详解
- 使用更大的骨干网络模型;
- 增加 MLP层,实验测试两层最佳;
- 使用动量编码器,参考 MoCo;
🚩 效果

🚀 09. SWaV

📜 Paper: Unsupervised Learning of Visual Features by Contrasting Cluster Assignments [NeurIPS 2020]
🖥️ GitHub: swav
🎨 结构框图

🚩 详解
- 生成多个视角,利用一个视角得到的特征去预测另一个视角的特征;
- 与聚类工作相结合,利用
聚类中心(3000个)进行预测; - cz1 预测 Q2, cz2 预测 Q1,c 为聚类中心,z1 和 z2 为提取的特征编码;
- 采用聚类中心:可以降低采样的负样本数量从而减少计算成本,解决正样本也纳入到负样本中导致的样本不均衡的问题;
- 提出
Muti-crop的数据增强策略,多尺度的剪裁原始图像作为数据增强;
🚩 效果

🚀 10. BYOL

📜 Paper: Bootstrap Your Own Latent A New Approach to Self-Supervised Learning [NeurIPS 2020]
📜 Blog: Understanding Self-Supervised and Contrastive Learning with “Bootstrap Your Own Latent” (BYOL)
🖥️ GitHub: byol
🎨 结构框图

🚩 详解
- fθ 和 fξ 的网络结构一样,模型参数更新不同,fξ 采用动量编码器更新;
- gθ 和 gξ 是类似 SimCLR 的
MLP层,与 fθ 和 fξ 的更新策略一样; - 在模型最后输出部分 zθ 再经过一个 MLP层 得到 qθ(zθ),利用 qθ(zθ) 预测 z’ξ 计算 loss ;
- 模型测试阶段使用 yθ 作为输出;
🚩 效果

🚀 11. SimSiam

📜 Paper: Exploring Simple Siamese Representation Learning [CVPR 2021]
🖥️ GitHub: simsiam
🎨 结构框图


🚩 详解
- 较 BYOL 没有使用动量编码器进行参数更新;
- 总结性工作;
🚩 效果


🚀 12. Mocov3

📜 Paper: An Empirical Study of Training Self-Supervised Vision Transformers [ICCV 2021, Oral]
🖥️ GitHub: moco-v3
🎨 结构框图

🚩 详解
- 结合 MoCov2 和 SimSiam ;
- 骨干网络替换成了 ViT ;
🚩 效果

🚀 13. DINO

📜 Paper: Emerging Properties in Self-Supervised Vision Transformers [ICCV 2021]
🖥️ GitHub: dino
🎨 结构框图


🚩 详解
- 融合 ViT 模型;
- 使用 student gθs 得到的结果 P1 去预测 teacher gθt 得到的结果 P2 ;
🚩 效果


参考:

🚀 14. CLIP

📜 Paper: Learning Transferable Visual Models From Natural Language Supervision [None 2021]
🖥️ GitHub: CLIP
🎨 结构框图
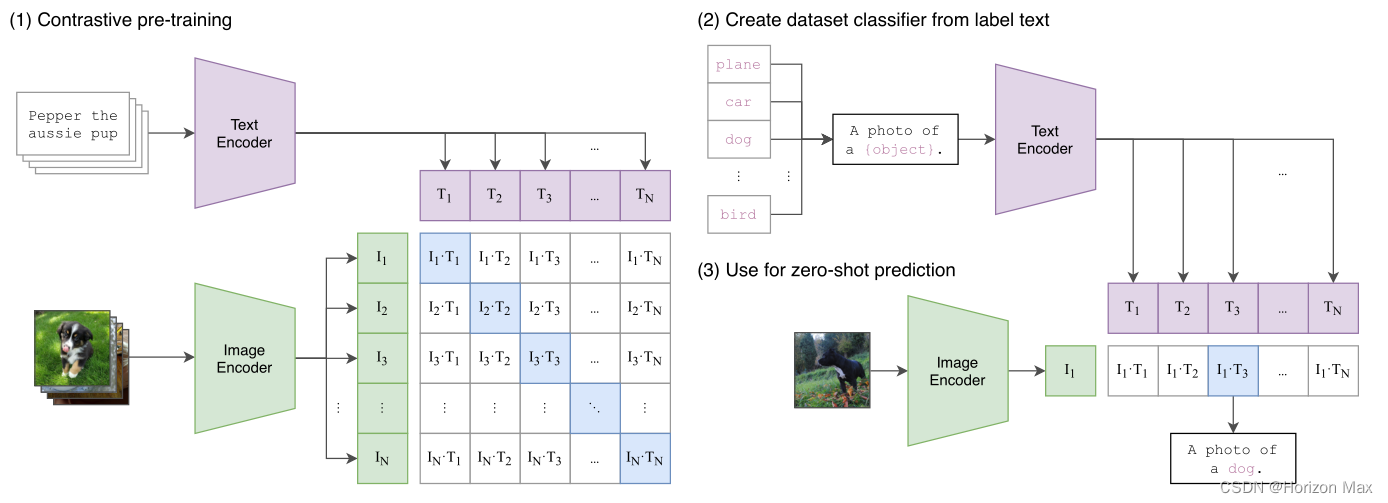

🚩 详解
- 模型训练采用了一个非常大的数据集:400 million 图片文字对(image,text);
- CLIP 预训练模型可以在不需要任何数据集训练的情况下和一个有监督学习的模型达成平手,甚至还会更高(ImageNet,ResNet);
正样本:对角线元素(IiTi (1 ≤ i ≤ N));负样本:除对角线元素外的其他元素;
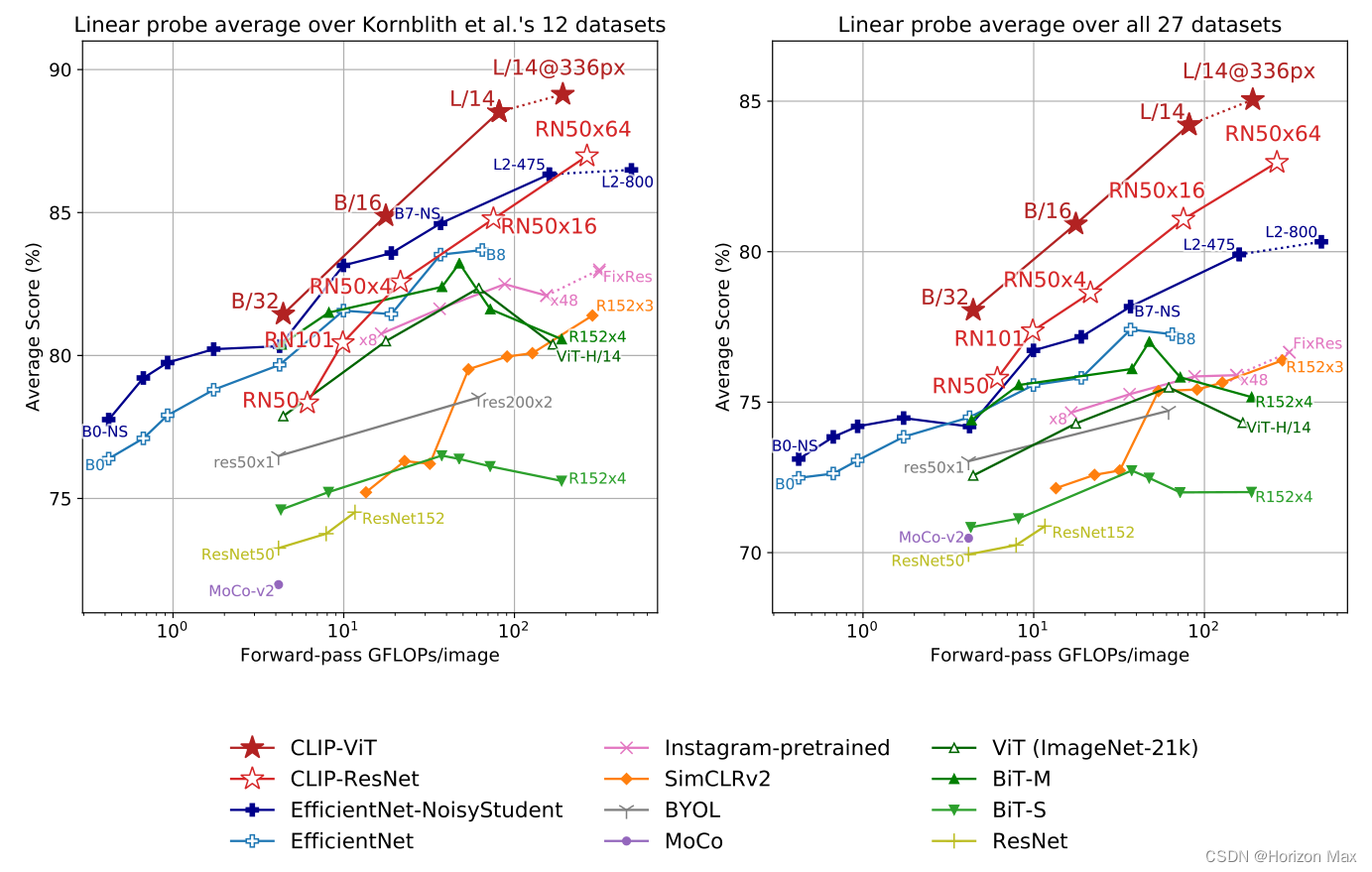
🚩 效果



















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











