







原文链接:https://blog.csdn.net/xu380393916/article/details/109304082
一、SENET
SENET是2017年的世界冠军,SE全称Squeeze-and-Excitation是一个模块,将现有的网络嵌入SE模块的话,那么该网络就是SENet,它几乎可以嵌入当前流行的任何网络,那么为什么会引出这个东西呢,来看下图:
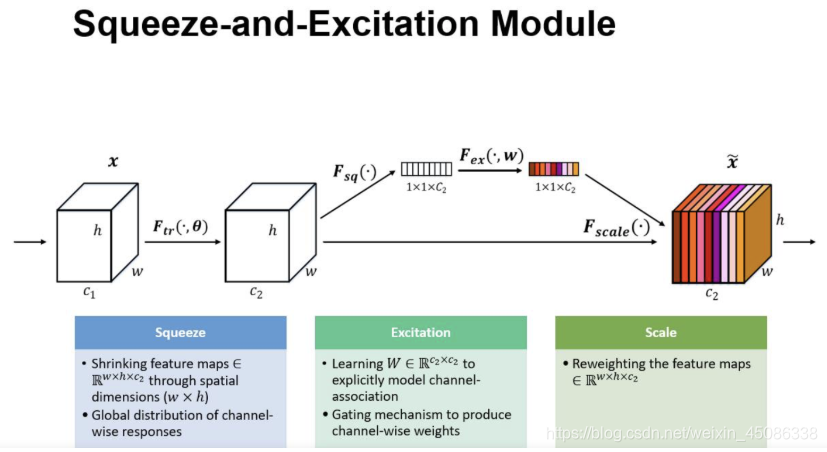
SE结构
一个SEblock的过程分为 Squeeze(压缩) 和 Excitation(激发) 两个步骤:
Squeeze(压缩) 通过在Feature Map层上执行Global Average Pooling,得到当前Feature Map的全局压缩特征量;
Excitation(激发) 通过两层全连接的bottleneck结构得到Feature Map中每个通道的权值,并将加权后的Feature Map作为下一层网络的输入
一个feature map经过一系列卷积池化得到的feature map,通常我们认为这个得到的feature map的每个通道都是同样重要的,我们并没有分那个通道重要,那个通道不怎么重要,那么实际上会不会有这种情况呢,就是得到的featurmap 的每个通道的重要性都不一样,比如确实有的图片三个通道,我只有一个通道有用,其它通道没什么用,比如一张包含动物的图片,那么背景肯定不怎么重要,它转化为灰度图后,只有一个通道比较重要,其它的不怎么重要,那么其实实际上我们得到的feature map每个通道的重要程度还是不一样的,也就是说每个通道其实还应该有一个重要性权值才行,然后每个通道的重要性权值乘以每个通道原来的值,就是我们求的真正feature map,这个feature map不同的通道重要性不一样(可能权值大的乘以原来的数要大些)如上面得到最终图,每个通道颜色不一样,也就代表着不同的重要性
那么每个通道的权值或者重要性怎么来呢,就是上面这块,做法如下:
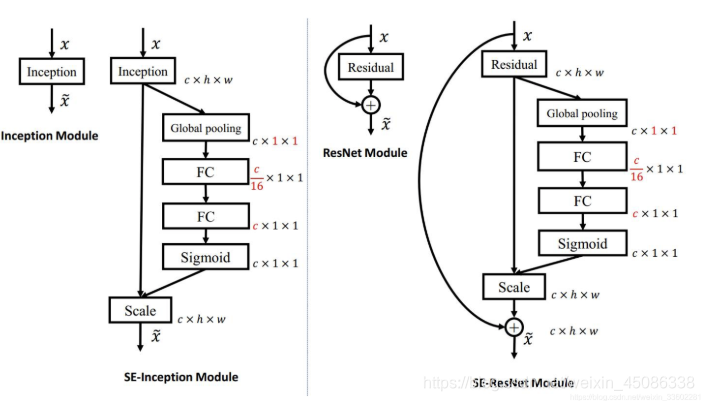
其实很简单,假入原来feature map 是 h * w * c的,给它做一个global池化(池化窗口就是h * w 得到的就是1 * 1窗口,通道数不变)得到 1 * 1 * c的feature map,然后它再接两个全连接层(第一个全连接层神经元个数是c/16,相当于对c进行了降维,输入是c个特征,第二个全连接层神经元个数为c,相当于又增维回到了c个特征,这样做比直接用一个 Fully Connected 层的好处在于具有更多的非线性,可以更好地拟合通道间复杂的相关性,极大地减少了参数量和计算量),然后再接一个sigmod层(这里采用sigmod应该是通道之间是具有相关性的,所以不能用softmax,softmax的话,最终加起来必须为1),输出1 * 1 * c,
原来的feature map维度h * w * c,得到的是通道的权值维度1 * 1 * c,然后它们进行相乘,这里是全乘,不是矩阵相乘,然后得到的feature map对应的每个通道重要性就不一样了(可能更重要的它的值要大些)
那么h * w * c 和1 * 1 * c 是怎么相乘的呢?看一个例子

像这样相乘
这个是一个通道的,看到没它乘的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









