







01 SENet(2017年)
💚论文:《Squeeze-and-Excitation Networks》
💚论文连接:https://arxiv.org/abs/1709.01507
💚代码地址:https://github.com/hujie-frank/SENet
💚PyTorch代码地址:https://github.com/miraclewkf/SENet-PyTorch
SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。SE block嵌在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的 。作者的动机是希望显式地建模特征通道之间的相互依赖关系。
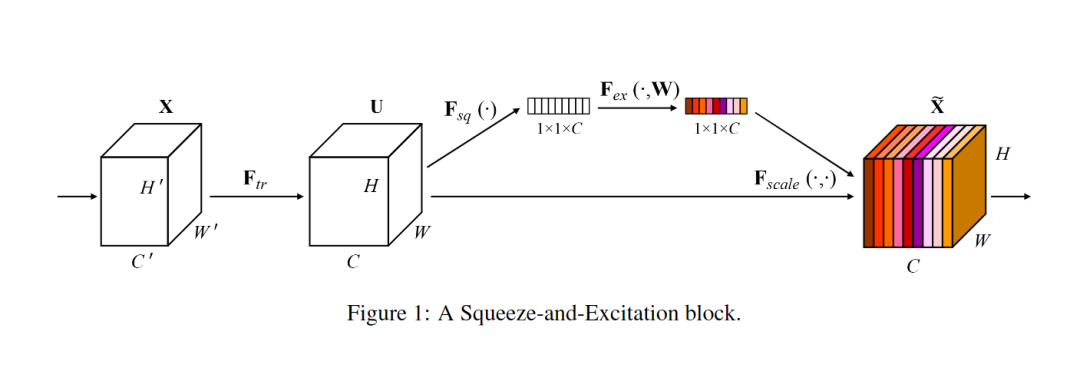
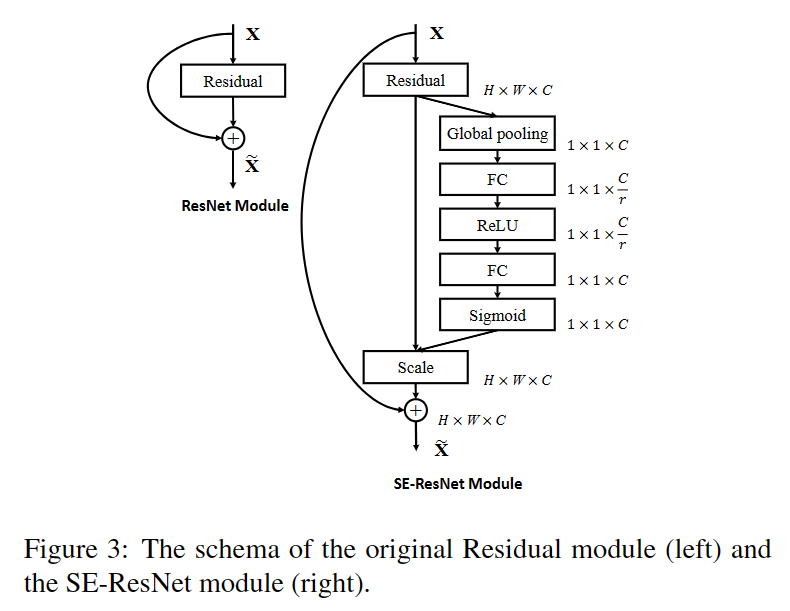
注:Fsq代表Squeeze操作,Fex代表Excitation操作,Fscale代表Scale操作。
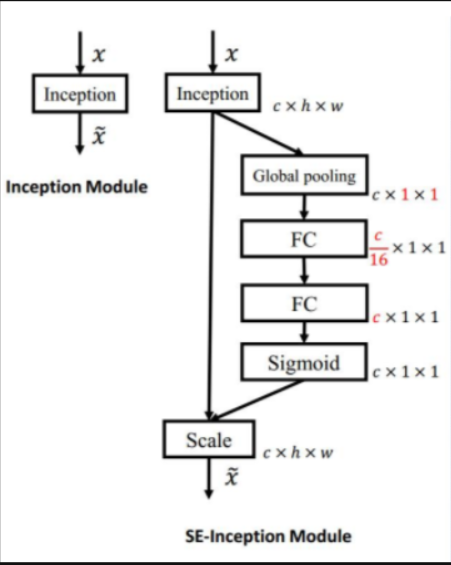
SE Block结构如下图所示:输入X经过任意变换之后变为输出U,假设输出的U不是最优的,每个通道的重要程度不同,有的通道更有用,有的通道不太有用。因此对于每一个输出通道,先进行global average pooling,每个通道得到一个标量,C个通道得到C个数,然后经过FC-ReLU-FC-Sigmoid得到C个0到1之间的标量,作为通道的权重。最后对原来输出通道的每个通道用对应的权重加权(对应通道的每个元素与权重分别相乘),得到新的加权后的特征图,作者称之为feature recalibration。
✅ Squeeze
由于卷积只是在一个局部空间内进行操作,U很难获得足够的信息来提取channel之间的关系,对于网络中前面的层这更严重,因为感受野比较小。Squeeze操作将一个channel上整个空间特征编码为一个全局特征,采用global average pooling来实现(原则上也可以采用更复杂的聚合策略),公式如下:
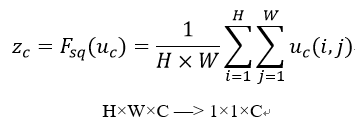
✅ Excitation
Squeeze操作得到了全局描述特征,接下来需要另一种运算来抓取channel之间的关系,这个操作需要满足两个原则:首先要灵活,它要可以学习到各个channel之间的非线性关系;第二点是学习的关系不是互斥的,因为这里允许多channel的特征,而不是one-hot形式。基于此,这里采用sigmoid形式的gating机制:

为了降低模型的复杂度以及泛化能力,这里采用包含两个全连接层的bottleneck结构,其中第一个FC层起到降维的作用,降维系数为r是一个超参数(实验证明当r为16的时候效果最好)。然后采用ReLU激活,最后的FC层恢复原始的维度。
✅Scale
Scale操作是将学习到的各个channel的激活值(sigmoid激活,值为0到1)乘以U上的原始特征:
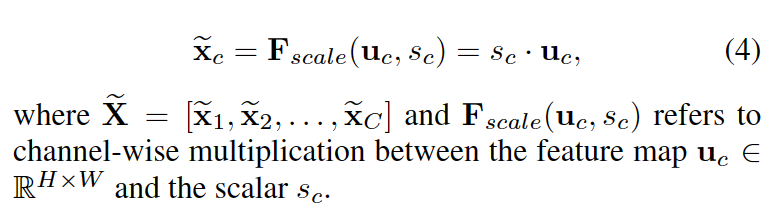

总的来说,SE Block首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,得到不同channel的权重。最后进行Scale操作,即将得到的不同channel的权重乘以原来的特征图得到最终特征。本质上,SE Block是在channel维度上做attention或者gating操作。这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE Block是通用的,这意味着其可以嵌入到现有的网络框架中。
02 CBAM(2018年)
💚论文题目:《CBAM: Convolutional Block Attention Module》
💚论文地址:https://arxiv.org/pdf/1807.06521.pdf
卷积注意力模块(CBAM)是一种用于前馈卷积神经网络的简单而有效的注意力模块。给定一个中间特征图,CBAM模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将注意力图与输入特征图相乘以进行自适应特征优化。由于CBAM是轻量级的通用模块,因此可以忽略的。该模块的开销而将其无缝集成到任何CNN架构中,并且可以与基础CNN一起进行端到端训练。
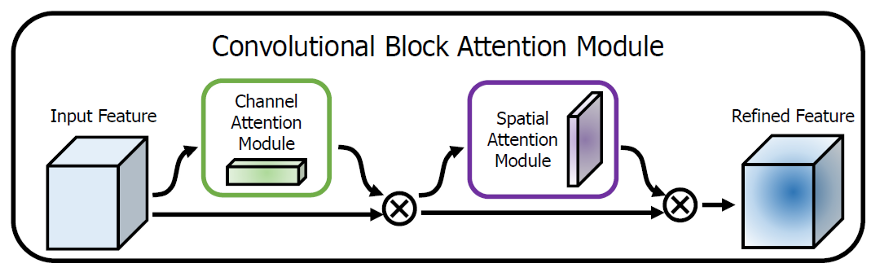
这两个模块可以以并行或顺序的方式放置。结果表明,顺序排列的结果比并行排列的结果好。对于排列的顺序,实验结果表明,通道在前面略优于空间在前面。
✅通道注意力模块(CAM)
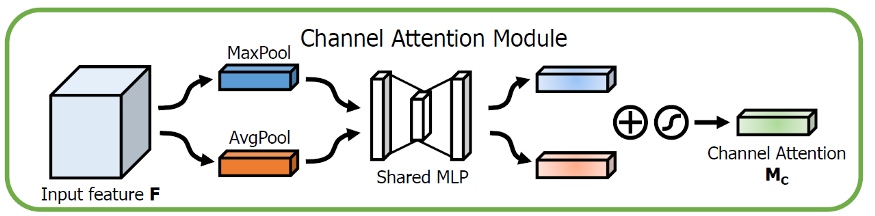
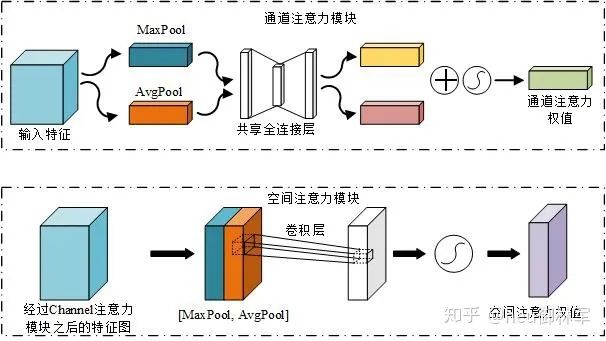
事实上,CAM 与 SENet 相比,只是多了一个并行的 Max Pooling 层。通道注意力聚焦在“什么”是有意义的输入图像,为了有效计算通道注意力,需要对输入特征图的空间维度进行压缩,对于空间信息的聚合,常用的方法是平均池化。但有人认为,最大池化收集了另一个重要线索,关于独特的物体特征,可以推断更细的通道上的注意力。因此,平均池化和最大池化的特征是同时使用的。
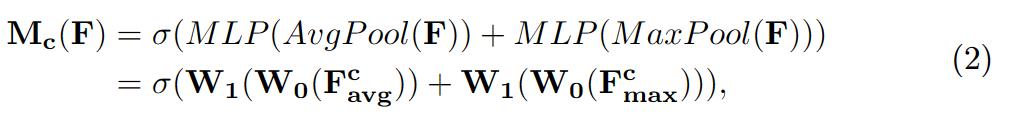
Fcavg和Fcmax,分别表示平均池化特征和最大池化特征。然后,这两个描述符被转发到一个共享网络,以产生通道注意力图Mc。共享网络由一个多层感知器(MLP)组成,其中有一个隐含层。为减少参数开销,隐藏层的激活大小设为R/C=r×1×1,其中R为下降率。将共享网络应用到每个描述符后,输出的特征向量使用element-wise求和进行合并。σ表示sigmoid函数。这个Mc(F)与F进行元素相乘得到F’。
将输入的特征图F(H×W×C)分别经过基于width和height的global max pooling(全局最大池化)和global average pooling(全局平均池化),得到两个1×1×C的特征图,接着,再将它们分别送入一个两层的神经网络(MLP),第一层神经元个数为 C/r(r为减少率),激活函数为 Relu,第二层神经元个数为 C,这个两层的神经网络是共享的。而后,将MLP输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的channel attention feature,即M_c。最后,将M_c和输入特征图F做element-wise乘法操作,生成Spatial attention模块需要的输入特征。
✅空间注意力模块(SAM)
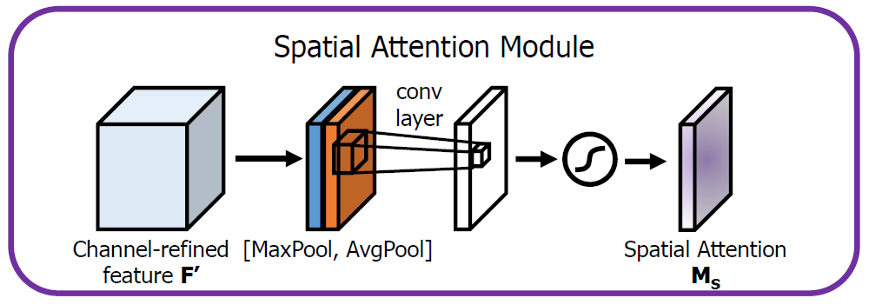
空间注意力聚焦在“哪里”是最具信息量的部分,这是对通道注意力的补充。为了计算空间注意力,沿着通道轴应用平均池化和最大池操作,然后将它们连接起来生成一个有效的特征描述符。然后应用卷积层生成大小为R×H×W 的空间注意力图Ms(F),该空间注意图编码了需要关注或压制的位置。
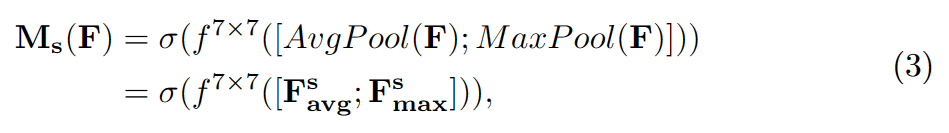
具体来说,使用两个pooling操作聚合成一个feature map的通道信息,生成两个2D图: Fsavg大小为1×H×W,Fsmax大小为1×H×W。σ表示sigmoid函数,f7×7表示一个滤波器大小为7×7的卷积运算。
将Channel attention模块输出的特征图F‘作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,得到两个H×W×1 的特征图,然后将这2个特征图基于channel 做concat操作(通道拼接)。然后经过一个7×7卷积(7×7比3×3效果要好)操作,降维为1个channel,即H×W×1。再经过sigmoid生成spatial attention feature,即M_s。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
参考文章:https://zhuanlan.zhihu.com/p/101590167
注:本文仅用于学术分享,如有侵权,请联系后台作删文处理。
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!



















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











