










DataWhale Task04:手搓一个LLM Eval 241001
开源内容:https://github.com/datawhalechina/tiny-universe/blob/main/content/TinyEval/readme.md
视频link:https://meeting.tencent.com/user-center/shared-record-info?id=8b9cf6ca-add6-477b-affe-5b62e2d8f27e&from=3
微调遇到的问题:
- 如何判断各大模型在当前数据集上的表现
- 对于选择式、判别式、生成式等不同的生成任务,如何才能够客观地评价模型生成质量
评测任务的流程:
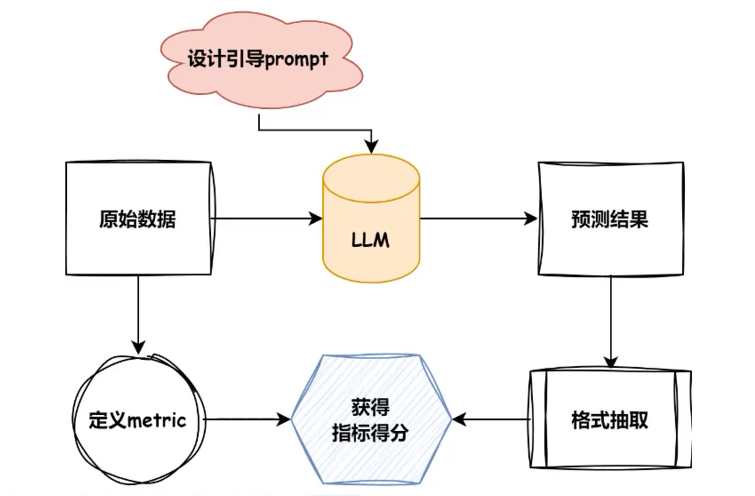
EVal流程
- 首先,根据目标数据集的任务类型指定合理的评测metric
- 根据目标数据的形式总结模型引导prompt.
- 根据模型初步预测结果采纳合理的抽取方式
- 对相应的pred与anwser进行得分计算
inference.py___预测
eval.py__evaltion
支持的测评数据集与测评Metric
| name | type | metric |
|---|---|---|
| multi_news | 长文本回答 | Rouge |
| multifieldqa_zh | 短文本回答 | F1 |
| trec | 生成式选择 | accuracy |
生成式F1
- 引导prompt为
阅读以下文字并用中文简短回答:\n\n{context}\n\n现在请基于上面的文章回答下面的问题,只告诉我答案,不要输出任何其他字词。\n\n问题:{input}\n回答:
- config内包含的为设置一些路径,设置一些问询引导的promote形式,设置最大的生存数量,前置设置的参数
 - model2path 模型输入
- model2path 模型输入
-load_model 指出path,devices等等

中间一段进行截断。截断策略,对于模型而言,尤其是制定了输入的长度,如果使用阶段命令则其会在输入的末尾进行阶段,但由于引导性prompt的存在,在inputs的两端均有关键信息,故需要对两端的信息进行保留,对中间部位进行截断操作,才能最大限度地抱持输出效果!
get_pred函数:
def get_pred(self, data, max_length, max_gen, prompt_format, device, out_path):
model, tokenizer = self.load_model_and_tokenizer(self.path, device)
for json_obj in tqdm(data):
prompt = prompt_format.format(**json_obj)
# 在中间截断,因为两头有关键信息.
tokenized_prompt = tokenizer(prompt, truncation=False, return_tensors="pt").input_ids[0]
if len(tokenized_prompt) > max_length:
half = int(max_length/2)
prompt = tokenizer.decode(tokenized_prompt[:half], skip_special_tokens=True)+tokenizer.decode(tokenized_prompt[-half:], skip_special_tokens=True)
prompt = self.build_chat(prompt)
input = tokenizer(prompt, truncation=False, return_tensors="pt").to(device)
# 表示喂进去的tokens的长度
context_length = input.input_ids.shape[-1]
eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids(["<|im_end|>"])[0]]
output = model.generate(
**input,
max_new_tokens=max_gen,
do_sample=False,
temperature=1.0,
eos_token_id=eos_token_id,
)[0]
pred = tokenizer.decode(output[context_length:], skip_special_tokens=True)
pred = self.post_process(pred)
with open(out_path, "a", encoding="utf-8") as f:
json.dump({"pred": pred, "answers": json_obj["answers"], "all_classes": json_obj["all_classes"], "length": json_obj["length"]}, f, ensure_ascii=False)
f.write('\n')
data: 输入的数据,通常是一个包含多个 JSON 对象的列表。
max_length: 最大输入长度,控制输入提示的长度。
max_gen: 最大生成的标记数,控制模型生成的输出长度。
prompt_format: 用于格式化输入提示的字符串模板。
device: 指定模型运行的设备(如 CPU 或 GPU)。
out_path: 输出文件的路径,预测结果将写入该文件。
model, tokenizer = self.load_model_and_tokenizer(self.path, device)
代码调用 load_model_and_tokenizer 方法加载指定路径下的模型和分词器,并将其转移到指定的设备上。
for json_obj in tqdm(data):
使用 tqdm 包来显示进度条,遍历输入数据中的每个 JSON 对象。
prompt = prompt_format.format(**json_obj)
使用 JSON 对象中的数据填充提示格式字符串。
tokenized_prompt = tokenizer(prompt, truncation=False, return_tensors="pt").input_ids[0]
if len(tokenized_prompt) > max_length:
half = int(max_length/2)
prompt = tokenizer.decode(tokenized_prompt[:half], skip_special_tokens=True) + tokenizer.decode(tokenized_prompt[-half:], skip_special_tokens=True)
将提示文本进行分词并检查其长度。如果长度超过 max_length,则截断提示,只保留前后各一半的信息。
prompt = self.build_chat(prompt)
对提示进行进一步处理,以适应聊天模型的输入格式。
input = tokenizer(prompt, truncation=False, return_tensors="pt").to(device)
context_length = input.input_ids.shape[-1]
对处理后的提示进行分词并转移到设备上。获取上下文的长度。
eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids(["<|im_end|>"])[0]]
定义结束标记的 ID,用于模型生成的输出。
output = model.generate(
**input,
max_new_tokens=max_gen,
do_sample=False,
temperature=1.0,
eos_token_id=eos_token_id,
)[0]
调用模型的 generate 方法生成文本。设置生成的最大新标记数、是否进行采样等参数。
pred = tokenizer.decode(output[context_length:], skip_special_tokens=True)
pred = self.post_process(pred)
将生成的输出解码为文本,跳过特殊标记,并进行后处理。
with open(out_path, "a", encoding="utf-8") as f:
json.dump({"pred": pred, "answers": json_obj["answers"], "all_classes": json_obj["all_classes"], "length": json_obj["length"]}, f, ensure_ascii=False)
f.write('\n')
将预测结果、原始答案、所有类别和长度以 JSON 格式写入输出文件,确保字符编码为 UTF-8。
f1评分函数
def f1_score(prediction, ground_truth, **kwargs):
# Counter以dict的形式存储各个句子对应的词与其对应个数,&操作符返回两个Counter中共同的元素的键值对
common = Counter(prediction) & Counter(ground_truth)
# 显示prediction与gt的共同元素的个数
num_same = sum(common.values())
if num_same == 0:
return 0
# 即模型预测正确的样本数量与总预测样本数量的比值
precision = 1.0 * num_same / len(prediction)
# 模型正确预测的样本数量与总实际样本数量的比值
recall = 1.0 * num_same / len(ground_truth)
f1 = (2 * precision * recall) / (precision + recall)
return f1
prediction: 模型生成的预测结果,通常是一个词的列表。
ground_truth: 真实标签或标准答案,也是一个词的列表。
**kwargs: 可选的额外参数,未在函数中使用。
计算共同元素:
common = Counter(prediction) & Counter(ground_truth)
使用 Counter 类计算 prediction 和 ground_truth 中的共同元素(即同时存在于两个列表中的词)。& 操作符返回两个 Counter 对象中共同的键及其最小计数。
计算共同元素的数量:
num_same = sum(common.values())
统计共同元素的总数,即模型预测正确的词的数量。
处理特殊情况:
if num_same == 0:
return 0
如果没有共同元素(即 num_same 为 0),则返回 F1 分数为 0,避免除以零的情况。
计算精确率:
precision = 1.0 * num_same / len(prediction)
精确率(Precision)是正确预测的数量与模型总预测数量的比值,反映模型的预测准确性。
计算召回率:
recall = 1.0 * num_same / len(ground_truth)
召回率(Recall)是正确预测的数量与真实样本数量的比值,反映模型的覆盖率。
计算 F1 分数:
f1 = (2 * precision * recall) / (precision + recall)
F1 分数是精确率和召回率的调和平均数,综合考虑了模型的准确性和覆盖率,值越高表示模型性能越好。
返回结果:
return f1
最后返回计算得到的 F1 分数。
















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











