







用国产大模型+LangChain+Neo4j建立知识图谱 之一 实体关系提取与导入
本篇以网络小说《悟空传》的前7章来演示用国产LLM+LangChain+Neo4j(中文版)从非结构化的文本文档中构建知识图谱,开发支持微软GraphRAG论文中所述的全局查询与局部查询的具体过程。分为两个语料文件以演示从多文档数据集中构建知识图谱,第1个文本文件包含第14章,第2个文本文件包含第57章。从结构化的存量知识库中构建知识图谱会更简单一些,直接写Cypher查询语句灌入Neo4j就可以了。
这个解决方案集成了Neo4j GraphRAG方案图数据库与工具链的优势,以及微软GrapRAG方案实体社区全局视野的优势,无缝连接各个主流的国产大模型,集各家之所长,是国内开发部署GraphRAG落地应用可行的高性价比解决方案。对于生产环境高负载高并发的落地应用来说,高性能图数据库与强大LLM模型的支撑是必不可少的,而LangChain这样的开发框架则有效的提高了构建、集成、开发、测试与部署落地应用等整个软件研发周期的效率,可以快速开发出应用原型,快速的迭代进化,快速的部署测试和应用。
在从非结构化文本建立知识图谱的阶段,对一个文档要作如下的处理:
1、分词(token)。中文分词比字母文字要复杂很多,不能简单的用OpenAI的cl100k_base等字母分词模型,本篇用开源的HanLP,本地运行,厂商独立,深度学习预训练大模型中文分词效果比较好。LLM中的token是分词结果的词,包括标点符号。
2、分块(chunk)。前后分块之间要有适当的重叠,以保证检索中文档内语义上的连贯。分块的断句要比较合适,尽量在一个分块中包含完整的句子,即块首重叠部分与块末截断部分都是完整的句子,块大小可以在指定分块大小的上下根据当前句子的状况适当浮动,重叠部分的大小也可以根据指定的大小及当前的内容浮动。 已完成研究。
3、对每个分块提取实体关系。 已完成研究。
4、实体解析(指代消解),在全局所有文档中合并相同的实体。已完成研究。
5、社区摘要。已完成研究。
一、读入文本文档
用同一个主题的文档测试,因为LLM提取的实体类型形同,比较好处理。
import os
import codecs
from openai.resources import api_key
os.environ['http_proxy']="http://127.0.0.1:7890"
os.environ['https_proxy']="http://127.0.0.1:7890"
# 读入测试数据------------------------------------------------------------------
# 指定测试数据的目录路径
# 有2个测试文件,第1个存放《悟空传》的第1~4章,第2个存放第5~7章。
directory_path = '/home/ubuntu/dataset/test_neo4j'
# 读入测试文件。
def read_txt_files(directory):
# 存放结果的列表
results = []
# 遍历指定目录下的所有文件和文件夹
for filename in os.listdir(directory):
# 检查文件扩展名是否为.txt
if filename.endswith(".txt"):
# 构建完整的文件路径
file_path = os.path.join(directory, filename)
# 打开并读取文件内容
with codecs.open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 将文件名和内容以列表形式添加到结果列表
results.append([filename, content])
return results
# 调用函数并打印结果
file_contents = read_txt_files(directory_path)
for file_name, content in file_contents:
print("文件名:", file_name)
在本篇的知识图谱中,每个文本文档会建立一个__Document__结点,文件名是其唯一标识,全图不能重复。为了方便文档归集,结点中设置了domain属性来标记同一个主题数据集的文档。
文件名: wukongzhuan-1-4.txt
文件名: wukongzhuan-5-7.txt
二、文本分块
LLM的工作都是基于token,token就是单词,包括标点符号,先分词,再分块。对于大的文本文件,要从中提取实体关系,LLM的处理能力有限,必须分块处理。另外GraphRAG向量搜索只需要返回相关的片段,也需要文本分块。为保证提取的知识图谱之间有更好的语义交叉连接质量,文本块之间要有适当的重叠,文本块开头的重叠部分与末尾的截断部分最好是完整的句子。所以文本块的大小和重叠部分的大小要根据当前的文本内容动态调整,注意这里的大小指的是token的计数,不是字节数。
# 文本分块----------------------------------------------------------------------
import hanlp
# 单任务模型,分词,token的计数是计算词,包括标点符号。
tokenizer = hanlp.load(hanlp.pretrained.tok.COARSE_ELECTRA_SMALL_ZH)
# 划分段落。
def split_into_paragraphs(text):
return text.split('\n')
# 判断token是否为句子结束符,视情况再增加。
def is_sentence_end(token):
return token in ['。', '!', '?']
# 向后查找到句子结束符,用于动态调整chunk划分以保证chunk以完整的句子结束
def find_sentence_boundary_forward(tokens, chunk_size):
end = len(tokens) # 默认的end值设置为tokens的长度
for i in range(chunk_size, len(tokens)): # 从chunk_size开始向后查找
if is_sentence_end(tokens[i]):
end = i + 1 # 包含句尾符号
break
return end
# 从位置start开始向前寻找上一句的句子结束符,以保证分块重叠的部分从一个完整的句子开始。
def find_sentence_boundary_backward(tokens, start):
for i in range(start - 1, -1, -1):
if is_sentence_end(tokens[i]):
return i + 1 # 包含句尾符号
return 0 # 找不到
# 文本分块,文本块的参考大小为chunk_size,文本块之间重叠部分的参考大小为overlap。
# 为了保证文本块之间重叠的部分及文本块末尾截断的部分都是完整的句子,
# 文本块的大小和重叠部分的大小都是根据当前文本块的内容动态调整的,是浮动的值。
def chunk_text(text, chunk_size=300, overlap=50):
if chunk_size <= overlap: # 参数检查
raise ValueError("chunk_size must be greater than overlap.")
# 先划分为段落,段落保存了语义上的信息,整个段落去处理。
paragraphs = split_into_paragraphs(text)
chunks = []
buffer = []
# 逐个段落处理
i = 0
while i < len(paragraphs):
# 注满buffer,直到大于chunk_szie,整个段落读入,段落保存了语义上的信息。
while len(buffer) < chunk_size and i < len(paragraphs):
tokens = tokenizer(paragraphs[i])
buffer.extend(tokens)
i += 1
# 当前buffer分块
while len(buffer) >= chunk_size:
# 保证从完整的句子处截断。
end = find_sentence_boundary_forward(buffer, chunk_size)
chunk = buffer[:end]
chunks.append(chunk) # 保留token的状态以便后面计数
# 保证重叠的部分从完整的句子开始。
start_next = find_sentence_boundary_backward(buffer, end - overlap)
if start_next==0: # 找不到了上一句的句子结束符,调整重叠范围再找一次。
start_next = find_sentence_boundary_backward(buffer, end-1)
if start_next==0: # 真的找不到,放弃块首的完整句子重叠。
start_next = end - overlap
buffer=buffer[start_next:]
if buffer: # 如果缓冲区还有剩余的token
# 检查一下剩余部分是否已经包含在最后一个分块之中,它只是留作块间重叠。
last_chunk = chunks[len(chunks)-1]
rest = ''.join(buffer)
temp = ''.join(last_chunk[len(last_chunk)-len(rest):])
if temp!=rest: # 如果不是留作重叠,则是最后的一个分块。
chunks.append(buffer)
return chunks
# 使用自定义函数进行分块
for file_content in file_contents:
print("文件名:", file_content[0])
chunks = chunk_text(file_content[1], chunk_size=500, overlap=50)
file_content.append(chunks)
# 打印分块结果
for file_content in file_contents:
print(f"File: {file_content[0]} Chunks: {len(file_content[2])}")
for i, chunk in enumerate(file_content[2]):
print(f"Chunk {i+1}: {len(chunk)} tokens.")
分块情况,每块的token数是动态调整的。
File: wukongzhuan-1-4.txt Chunks: 7
Chunk 1: 537 tokens.
Chunk 2: 510 tokens.
Chunk 3: 502 tokens.
Chunk 4: 501 tokens.
Chunk 5: 535 tokens.
Chunk 6: 540 tokens.
Chunk 7: 301 tokens.
File: wukongzhuan-5-7.txt Chunks: 5
Chunk 1: 501 tokens.
Chunk 2: 504 tokens.
Chunk 3: 525 tokens.
Chunk 4: 502 tokens.
Chunk 5: 421 tokens.
看看第1个文件的第1、2及最后一个分块,可以看到每块开头重叠的部分及末尾截断的部分都是完整的句子,最后一块自然结束,分块也尽量保留了原文中的段落信息,整段读入去处理,因为段落也包含了语义的信息。
>>> print(''.join(file_contents[0][2][0]))
《悟空传》今何在2017-07-11一个声音狂笑着,他大笑着殴打神仙,大笑着毁灭一切,他知道神永远杀不完,他知道天宫无边无际。这战斗将无法终止,直到他倒下,他仍然狂笑,笑出了眼泪。这个天地,我来过,我奋战过,我深爱过,我不在乎结局。[01.]四个人走到这里,前边一片密林,又没有路了。“悟空,我饿了,给我找些吃的来。”唐僧往石头上大模大样一坐,命令道。“我正忙着,你不会自己去找?又不是没有腿。”孙悟空拄着棒子说。“你忙?忙什么?”“你不觉得这晚霞很美吗?”孙悟空说,眼睛还望着天边,“我只有看看这个,才能每天坚持向西走下去啊。”“你可以一边看一边找啊,只要不撞到大树上就行。”“我看晚霞的时候不做任何事!”“孙悟空你不能这样,不能这样欺负秃头,你把他饿死了,我们就找不到西天,找不到西天,我们身上的诅咒永远也解除不了。”猪八戒说。“呸!什么时候轮到你这个猪头说话了?”“你说什么?你说谁是猪?!”“不是,是猪头!啊哈哈哈……”“你敢再说一遍!”猪八戒举着钉耙就要往上冲。“吵什么吵什么!老子要困觉了!要打滚远些打!”沙和尚大吼。三个恶棍怒目而视。“打吧打吧,打死一个少一个。”唐僧站起身来,“你们是大爷,我去给你们找吃的,还不行吗?最好让妖怪吃了我,那时你们就哭吧。”“快去吧,那儿有女妖精正等着你呢。”孙悟空叫道。“哼哼哼哼……”三个怪物都在冷笑。“别以为我离了你们就不行!”唐僧回头冲他们挥挥拳头,拍拍身上的尘土,又整整长袍,开始向林中走去。刚迈一步,“刺啦”——僧袍就被扯破了。“哈哈哈哈……”三个家伙笑成一团,也忘了打架。[02.]这是一片紫色的丛林,到处长着奇怪的植物,飘着终年不散的青色雾气,越往里走,脚下就越潮湿,头上就越昏暗,最后枝叶完全遮蔽了天空,唐僧也完全迷路了。
>>> print(''.join(file_contents[0][2][1]))
[02.]这是一片紫色的丛林,到处长着奇怪的植物,飘着终年不散的青色雾气,越往里走,脚下就越潮湿,头上就越昏暗,最后枝叶完全遮蔽了天空,唐僧也完全迷路了。“多么有生机的一片地方,这么多不同的生命。”唐僧却笑了。“谢谢!”有个声音回答他。唐僧一回头,看见一棵会说话的树,紫黑色树干上有两只一眨一眨的眼睛。“真是惊奇,生命是多么奇妙,让我摸摸你,土里的精灵。”唐僧伸出手去。那树干上泌满紫色的汁液,摸上去湿滑无比。树很惬意地享受着抚摩,它那无数下垂的分枝都不禁舒畅地摇动起来。“呵,有上万年没有人来到我面前了,从前……几千年前吧,有一群猴子在我身上戏耍,后来他们都不知哪儿去了。那时我还没有眼,只能感觉到有很多会动的生灵在我身边说话、唱歌,我看不见,也不能动,但我很幸福。现在我终于长出了眼睛。可是他们却不知哪里去了……不知哪里去了……”“他们死了。”唐僧说。“死?死是什么?”“死就是什么也看不见,什么也听不见,什么也感觉不到,什么也不会想,就像你未出生时一样。”“不,不要死!也不要孤独地生活。”“你还可能活很久,你还没有手,没有腿,以后都会长出来的。”“我花了十万年才长出眼睛,我再也忍受不了那么漫长的等待了,我现在就想去摸一摸身边的同类,摸一摸你。你身上的气味真令我心醉。”“我已经很久没洗澡了。对了,你没嘴,你用什么说话?”“我用这个。”怪树抖了抖它前面的一根枝条。那上面有一张人的嘴。“这不是你自己的。”“没错,是我捡的,三百年前有一个人在这里被吃了。剩下了这个,我用我能滋润万物的树汁浸泡它使它不腐烂,又费了几十年的时间才长出枝条捡起它。
>>> print(''.join(file_contents[0][2][6]))
”那女子摔在地上,鲜血从口中流出来,却还强撑着看孙悟空:“你,你不认得我了……是的,我变成这个样子,你自然认不出来,可我受了玉帝的咒,再也不能变回从前的样子……我是……”女子突然惨叫一声,一口血直喷出来,在地上痛苦地挣扎着。唐僧叹了一声:“唉,莫不是你也受了咒法,再不能说出自己是谁?”那女子双手紧紧攥住地上的泥土,显然痛苦至极。“秃头,你别信她,妖怪我见得多了,什么招都使得出来。让开,让我结果了她。”孙悟空道。“我并没有挡着你呀,你打呀,怎么不打?”“我……你叫我打我就打吗?偏要过会儿再打。”“恨不死的阿弥陀,负尽千重罪,炼就不死心。”唐僧又整了整他那已烂得不成样子的衣裳,踱着步向林外走去,“你们慢聊,我不打扰了。我要去那幽深的雨巷散步,期盼再相逢一个丁香花样的妖精……”他又停步看了看万年老树的残躯,缓缓叹道:“不要死,也不要孤独地生活。几十万年就是为了这一天吗?”
三、在Neo4j中创建文档与分块的图结构
这里文档结点用__Document__标签,是为了与后面langchain_community.graphs.neo4j_graph.Neo4jGraph.add_graph_documents()创建的Document结点区分开来,块结点用__Chunk__标签,后面add_graph_documents()创建的实体结点有__Entity__标签,这样命名风格上也保持一致,也与微软GraphRAG等保持一致。
先执行这一步是为了给每个__Chunk__结点生成一个chunk_id,后面用add_graph_documents()将块中提取的实体关系写入Neo4j时,要把chunk_id写入生成的Document结点,然后根据chunk_id匹配合并两个结点,以建立起__Chunk__结点与__Entity__结点之间的关系。
这段代码引用了Neo4j Knowledge Graph Builder的实现,稍作修改。
# 在Neo4j中创建文档与Chunk的图结构----------------------------------------------
# https://python.langchain.com/v0.2/api_reference/community/graphs/langchain_community.graphs.neo4j_graph.Neo4jGraph.html#langchain_community.graphs.neo4j_graph.Neo4jGraph.add_graph_documents
from langchain_community.graphs import Neo4jGraph
from langchain_core.documents import Document
import hashlib
import logging
from typing import List
os.environ["NEO4J_URI"] = "bolt://winhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
graph = Neo4jGraph(refresh_schema=False)
# 创建Document结点,与Chunk之间按属性名fileName匹配。
def create_Document(graph,type,uri,file_name, domain):
query = """
MERGE(d:`__Document__` {fileName :$file_name}) SET d.type=$type,
d.uri=$uri, d.domain=$domain
RETURN d;
"""
doc = graph.query(query,{"file_name":file_name,"type":type,"uri":uri,"domain":domain})
return doc
# 创建Document结点
for file_content in file_contents:
doc = create_Document(graph,"local",directory_path,file_content[0],"《悟空传》")
#创建Chunk结点并建立Chunk之间及与Document之间的关系
#这个程序直接从Neo4j KG Builder拷贝引用,为了增加tokens属性稍作修改。
#https://github.com/neo4j-labs/llm-graph-builder/blob/main/backend/src/make_relationships.py
def create_relation_between_chunks(graph, file_name, chunks: List)->list:
logging.info("creating FIRST_CHUNK and NEXT_CHUNK relationships between chunks")
current_chunk_id = ""
lst_chunks_including_hash = []
batch_data = []
relationships = []
offset=0
for i, chunk in enumerate(chunks):
page_content = ''.join(chunk)
page_content_sha1 = hashlib.sha1(page_content.encode()) # chunk.page_content.encode()
previous_chunk_id = current_chunk_id
current_chunk_id = page_content_sha1.hexdigest()
position = i + 1
if i>0:
last_page_content = ''.join(chunks[i-1])
offset += len(last_page_content) # chunks[i-1].page_content
if i == 0:
firstChunk = True
else:
firstChunk = False
metadata = {"position": position,"length": len(page_content), "content_offset":offset, "tokens":len(chunk)}
chunk_document = Document(
page_content=page_content, metadata=metadata
)
chunk_data = {
"id": current_chunk_id,
"pg_content": chunk_document.page_content,
"position": position,
"length": chunk_document.metadata["length"],
"f_name": file_name,
"previous_id" : previous_chunk_id,
"content_offset" : offset,
"tokens" : len(chunk)
}
batch_data.append(chunk_data)
lst_chunks_including_hash.append({'chunk_id': current_chunk_id, 'chunk_doc': chunk_document})
# create relationships between chunks
if firstChunk:
relationships.append({"type": "FIRST_CHUNK", "chunk_id": current_chunk_id})
else:
relationships.append({
"type": "NEXT_CHUNK",
"previous_chunk_id": previous_chunk_id, # ID of previous chunk
"current_chunk_id": current_chunk_id
})
query_to_create_chunk_and_PART_OF_relation = """
UNWIND $batch_data AS data
MERGE (c:`__Chunk__` {id: data.id})
SET c.text = data.pg_content, c.position = data.position, c.length = data.length, c.fileName=data.f_name,
c.content_offset=data.content_offset, c.tokens=data.tokens
WITH data, c
MATCH (d:`__Document__` {fileName: data.f_name})
MERGE (c)-[:PART_OF]->(d)
"""
graph.query(query_to_create_chunk_and_PART_OF_relation, params={"batch_data": batch_data})
query_to_create_FIRST_relation = """
UNWIND $relationships AS relationship
MATCH (d:`__Document__` {fileName: $f_name})
MATCH (c:`__Chunk__` {id: relationship.chunk_id})
FOREACH(r IN CASE WHEN relationship.type = 'FIRST_CHUNK' THEN [1] ELSE [] END |
MERGE (d)-[:FIRST_CHUNK]->(c))
"""
graph.query(query_to_create_FIRST_relation, params={"f_name": file_name, "relationships": relationships})
query_to_create_NEXT_CHUNK_relation = """
UNWIND $relationships AS relationship
MATCH (c:`__Chunk__` {id: relationship.current_chunk_id})
WITH c, relationship
MATCH (pc:`__Chunk__` {id: relationship.previous_chunk_id})
FOREACH(r IN CASE WHEN relationship.type = 'NEXT_CHUNK' THEN [1] ELSE [] END |
MERGE (c)<-[:NEXT_CHUNK]-(pc))
"""
graph.query(query_to_create_NEXT_CHUNK_relation, params={"relationships": relationships})
return lst_chunks_including_hash
#创建Chunk结点并建立Chunk之间及与Document之间的关系
for file_content in file_contents:
file_name = file_content[0]
chunks = file_content[2]
result = create_relation_between_chunks(graph, file_name , chunks)
file_content.append(result)
```
建立的图如下,文档与块之间有清晰的顺序关系,每个块也保留了tokens等有用的统计数据。
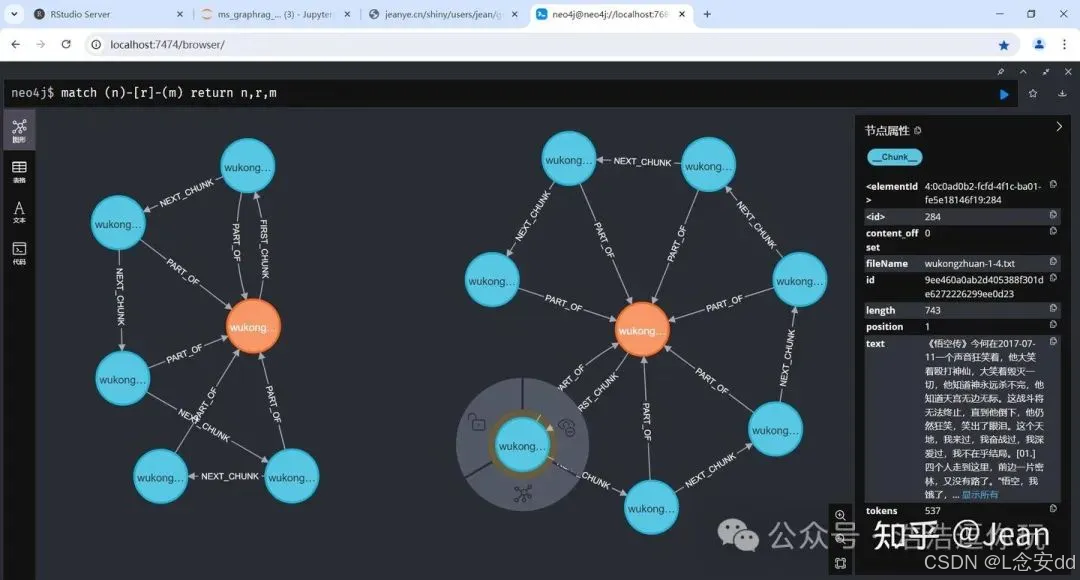
## 四、用LLM在每个文本块中提取实体关系
在《用Neo4j与LangChain实现从局部到全局的RAG:建立知识图谱》一文中,可以通过LLMGraphTransformer调用OpenAI的gpt-4等LLM直接抽取知识图谱并存储进Neo4j,Neo4j Knowledge Graph Builder也是调用它来完成。
```python
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0, model_name="gpt-4o")
llm_transformer = LLMGraphTransformer(
llm=llm,
node_properties=["description"],
relationship_properties=["description"]
)
from typing import List
from langchain_community.graphs.graph_document import GraphDocument
from langchain_core.documents import Document
def process_text(text: str) -> List[GraphDocument]:
doc = Document(page_content=text)
return llm_transformer.convert_to_graph_documents([doc])
经过测试,LLMGraphTransformer并不支持国产的大模型,需要自己去实现。所以修改了前文引用的微软GraphRAG提示词,抽取实体关系时增加输出关系类型,以便生成GraphDocument对象,并调用它写入Neo4j,它要求relationship中有关系类型的数据。
import os
import sys
sys.path.append("/home/ubuntu/Python")
from LangChainHelper import loadLLM, loadEmbedding
from langchain_core.messages import HumanMessage, SystemMessage
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate
)
# llm = loadLLM("OpenAI")
llm = loadLLM("Baidu")
# llm = loadLLM("Xunfei")
# llm = loadLLM("Tengxun")
# llm = loadLLM("Ali")
system_template="""
-目标-
给定相关的文本文档和实体类型列表,从文本中识别出这些类型的所有实体以及所识别实体之间的所有关系。
-步骤-
1.识别所有实体。对于每个已识别的实体,提取以下信息:
-entity_name:实体名称,大写
-entity_type:以下类型之一:[{entity_types}]
-entity_description:对实体属性和活动的综合描述
将每个实体格式化为("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>
2.从步骤1中识别的实体中,识别彼此*明显相关*的所有实体配对(source_entity, target_entity)。
对于每对相关实体,提取以下信息:
-source_entity:源实体的名称,如步骤1中所标识的
-target_entity:目标实体的名称,如步骤1中所标识的
-relationship_type:关系类型,确保关系类型的一致性和通用性,使用更通用和无时态的关系类型
-relationship_description:解释为什么你认为源实体和目标实体是相互关联的
-relationship_strength:一个数字评分,表示源实体和目标实体之间关系的强度
将每个关系格式化为("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_type>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_strength>)
3.实体和关系的所有属性用中文输出,步骤1和2中识别的所有实体和关系输出为一个列表。使用**{record_delimiter}**作为列表分隔符。
4.完成后,输出{completion_delimiter}
######################
-示例-
######################
Example 1:
Entity_types: [person, technology, mission, organization, location]
Text:
while Alex clenched his jaw, the buzz of frustration dull against the backdrop of Taylor's authoritarian certainty. It was this competitive undercurrent that kept him alert, the sense that his and Jordan's shared commitment to discovery was an unspoken rebellion against Cruz's narrowing vision of control and order.
Then Taylor did something unexpected. They paused beside Jordan and, for a moment, observed the device with something akin to reverence. “If this tech can be understood..." Taylor said, their voice quieter, "It could change the game for us. For all of us.”
The underlying dismissal earlier seemed to falter, replaced by a glimpse of reluctant respect for the gravity of what lay in their hands. Jordan looked up, and for a fleeting heartbeat, their eyes locked with Taylor's, a wordless clash of wills softening into an uneasy truce.
It was a small transformation, barely perceptible, but one that Alex noted with an inward nod. They had all been brought here by different paths
################
Output:
("entity"{tuple_delimiter}"Alex"{tuple_delimiter}"person"{tuple_delimiter}"Alex is a character who experiences frustration and is observant of the dynamics among other characters."){record_delimiter}
("entity"{tuple_delimiter}"Taylor"{tuple_delimiter}"person"{tuple_delimiter}"Taylor is portrayed with authoritarian certainty and shows a moment of reverence towards a device, indicating a change in perspective."){record_delimiter}
("entity"{tuple_delimiter}"Jordan"{tuple_delimiter}"person"{tuple_delimiter}"Jordan shares a commitment to discovery and has a significant interaction with Taylor regarding a device."){record_delimiter}
("entity"{tuple_delimiter}"Cruz"{tuple_delimiter}"person"{tuple_delimiter}"Cruz is associated with a vision of control and order, influencing the dynamics among other characters."){record_delimiter}
("entity"{tuple_delimiter}"The Device"{tuple_delimiter}"technology"{tuple_delimiter}"The Device is central to the story, with potential game-changing implications, and is revered by Taylor."){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Taylor"{tuple_delimiter}"workmate"{tuple_delimiter}"Alex is affected by Taylor's authoritarian certainty and observes changes in Taylor's attitude towards the device."{tuple_delimiter}7){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Jordan"{tuple_delimiter}"workmate"{tuple_delimiter}"Alex and Jordan share a commitment to discovery, which contrasts with Cruz's vision."{tuple_delimiter}6){record_delimiter}
("relationship"{tuple_delimiter}"Taylor"{tuple_delimiter}"Jordan"{tuple_delimiter}"workmate"{tuple_delimiter}"Taylor and Jordan interact directly regarding the device, leading to a moment of mutual respect and an uneasy truce."{tuple_delimiter}8){record_delimiter}
("relationship"{tuple_delimiter}"Jordan"{tuple_delimiter}"Cruz"{tuple_delimiter}"workmate"{tuple_delimiter}"Jordan's commitment to discovery is in rebellion against Cruz's vision of control and order."{tuple_delimiter}5){record_delimiter}
("relationship"{tuple_delimiter}"Taylor"{tuple_delimiter}"The Device"{tuple_delimiter}"study"{tuple_delimiter}"Taylor shows reverence towards the device, indicating its importance and potential impact."{tuple_delimiter}9){completion_delimiter}
#############################
Example 2:
Entity_types: [person, technology, mission, organization, location]
Text:
They were no longer mere operatives; they had become guardians of a threshold, keepers of a message from a realm beyond stars and stripes. This elevation in their mission could not be shackled by regulations and established protocols—it demanded a new perspective, a new resolve.
Tension threaded through the dialogue of beeps and static as communications with Washington buzzed in the background. The team stood, a portentous air enveloping them. It was clear that the decisions they made in the ensuing hours could redefine humanity's place in the cosmos or condemn them to ignorance and potential peril.
Their connection to the stars solidified, the group moved to address the crystallizing warning, shifting from passive recipients to active participants. Mercer's latter instincts gained precedence— the team's mandate had evolved, no longer solely to observe and report but to interact and prepare. A metamorphosis had begun, and Operation: Dulce hummed with the newfound frequency of their daring, a tone set not by the earthly
#############
Output:
("entity"{tuple_delimiter}"Washington"{tuple_delimiter}"location"{tuple_delimiter}"Washington is a location where communications are being received, indicating its importance in the decision-making process."){record_delimiter}
("entity"{tuple_delimiter}"Operation: Dulce"{tuple_delimiter}"mission"{tuple_delimiter}"Operation: Dulce is described as a mission that has evolved to interact and prepare, indicating a significant shift in objectives and activities."){record_delimiter}
("entity"{tuple_delimiter}"The team"{tuple_delimiter}"organization"{tuple_delimiter}"The team is portrayed as a group of individuals who have transitioned from passive observers to active participants in a mission, showing a dynamic change in their role."){record_delimiter}
("relationship"{tuple_delimiter}"The team"{tuple_delimiter}"Washington"{tuple_delimiter}"leaded by"{tuple_delimiter}"The team receives communications from Washington, which influences their decision-making process."{tuple_delimiter}7){record_delimiter}
("relationship"{tuple_delimiter}"The team"{tuple_delimiter}"Operation: Dulce"{tuple_delimiter}"operate"{tuple_delimiter}"The team is directly involved in Operation: Dulce, executing its evolved objectives and activities."{tuple_delimiter}9){completion_delimiter}
#############################
Example 3:
Entity_types: [person, role, technology, organization, event, location, concept]
Text:
their voice slicing through the buzz of activity. "Control may be an illusion when facing an intelligence that literally writes its own rules," they stated stoically, casting a watchful eye over the flurry of data.
"It's like it's learning to communicate," offered Sam Rivera from a nearby interface, their youthful energy boding a mix of awe and anxiety. "This gives talking to strangers' a whole new meaning."
Alex surveyed his team—each face a study in concentration, determination, and not a small measure of trepidation. "This might well be our first contact," he acknowledged, "And we need to be ready for whatever answers back."
Together, they stood on the edge of the unknown, forging humanity's response to a message from the heavens. The ensuing silence was palpable—a collective introspection about their role in this grand cosmic play, one that could rewrite human history.
The encrypted dialogue continued to unfold, its intricate patterns showing an almost uncanny anticipation
#############
Output:
("entity"{tuple_delimiter}"Sam Rivera"{tuple_delimiter}"person"{tuple_delimiter}"Sam Rivera is a member of a team working on communicating with an unknown intelligence, showing a mix of awe and anxiety."){record_delimiter}
("entity"{tuple_delimiter}"Alex"{tuple_delimiter}"person"{tuple_delimiter}"Alex is the leader of a team attempting first contact with an unknown intelligence, acknowledging the significance of their task."){record_delimiter}
("entity"{tuple_delimiter}"Control"{tuple_delimiter}"concept"{tuple_delimiter}"Control refers to the ability to manage or govern, which is challenged by an intelligence that writes its own rules."){record_delimiter}
("entity"{tuple_delimiter}"Intelligence"{tuple_delimiter}"concept"{tuple_delimiter}"Intelligence here refers to an unknown entity capable of writing its own rules and learning to communicate."){record_delimiter}
("entity"{tuple_delimiter}"First Contact"{tuple_delimiter}"event"{tuple_delimiter}"First Contact is the potential initial communication between humanity and an unknown intelligence."){record_delimiter}
("entity"{tuple_delimiter}"Humanity's Response"{tuple_delimiter}"event"{tuple_delimiter}"Humanity's Response is the collective action taken by Alex's team in response to a message from an unknown intelligence."){record_delimiter}
("relationship"{tuple_delimiter}"Sam Rivera"{tuple_delimiter}"Intelligence"{tuple_delimiter}"contact"{tuple_delimiter}"Sam Rivera is directly involved in the process of learning to communicate with the unknown intelligence."{tuple_delimiter}9){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"First Contact"{tuple_delimiter}"leads"{tuple_delimiter}"Alex leads the team that might be making the First Contact with the unknown intelligence."{tuple_delimiter}10){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Humanity's Response"{tuple_delimiter}"leads"{tuple_delimiter}"Alex and his team are the key figures in Humanity's Response to the unknown intelligence."{tuple_delimiter}8){record_delimiter}
("relationship"{tuple_delimiter}"Control"{tuple_delimiter}"Intelligence"{tuple_delimiter}"controled by"{tuple_delimiter}"The concept of Control is challenged by the Intelligence that writes its own rules."{tuple_delimiter}7){completion_delimiter}
#############################
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template="""
-真实数据-
######################
实体类型:{entity_types}
文本:{input_text}
######################
输出:
"""
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt, MessagesPlaceholder("chat_history"), human_message_prompt]
)
chain = chat_prompt | llm
tuple_delimiter = " : "
record_delimiter = "\n"
completion_delimiter = "\n\n"
entity_types = ["人物","妖怪","位置"]
chat_history = []
import time
t0 = time.time()
for file_content in file_contents:
results = []
for chunk in file_content[2]:
t1 = time.time()
input_text = ''.join(chunk)
answer = chain.invoke({
"chat_history": chat_history,
"entity_types": entity_types,
"tuple_delimiter": tuple_delimiter,
"record_delimiter": record_delimiter,
"completion_delimiter": completion_delimiter,
"input_text": input_text
})
t2 = time.time()
results.append(answer.content)
print(input_text)
print("\n")
print(answer.content)
print("块耗时:",t2-t1,"秒")
print("\n")
print("文件耗时:",t2-t0,"秒")
print("\n\n")
file_content.append(results)
作为比较,可以看看LLMGraphTransformer的源码,它的系统提示词翻译后是这样的:
system_prompt ="""
“#知识图谱生成指令说明\n”
“##1.概述\n”
“您是一个顶级算法,旨在提取结构化的信息格式,用于构建知识谱。\n”
“尽量从文本中获取尽可能多的信息,而无需牺牲准确性。不要添加任何文本中未明确说明的信息。\n”
“-**节点**表示实体和概念。\n”
“-目的是使知识图谱简单明了,使其可供广大受众访问。\n”
“##2.标记节点\n”
“-**一致性**:确保节点标签使用已有的类型。\n”
“确保节点标签使用基础或基本类型。\n”
“-例如,当您识别代表一个人的实体时,始终将其标记为**‘人’**。避免使用更具体的术语,比如‘数学家’或‘科学家’。”
“-**节点ID***:切勿使用整数作为节点ID。节点ID应为在文本中找到的名称或人类可读的标识符。\n”
“-**关系**表示实体或概念之间的连接。\n”
“构建知识图谱时确保关系类型的一致性和通用性,而不是使用特定和瞬时类型”
“例如'BECAME_PROFESSOR',使用更通用和无时态的关系类型,比如‘PROFESSOR’。请确保使用通用和无时态的关系类型!\n”
“##3.实体解析(指代消解)\n”
“-**保持实体一致性**:提取实体时,至关重要的是确保一致性。\n”
'如果一个实体,如“John Doe”,在文本中被多次提及但用不同的名字或代词称呼(例如,“Joe”、“他”),
在整个知识图谱中始终使用该实体的最完整标识符。在此示例中,使用“John Doe”作为实体ID。\n'
“记住,知识图谱应该连贯且易于理解。”
“因此,保持实体引用的一致性至关重要。\n”
“##4.严格遵守\n”
“严格遵守规则。不遵守规则将导致终止生成输出。”
"""
然后它为LLM准备的例子,是在与用户(数据)的提示词合并为最终的提示词时再加进去的。相比来说,微软GraphRAG的提示词与例子更精细更准确,所以还是用微软GraphRAG的提示词作为模板。
提取的实体类型是:
entity_types = ["人物","妖怪","位置"]
百度的ERNIE-4.0-8K输出的例子如下:
>>> print(answer.content)
("entity" : "猪八戒" : "人物" : "猪八戒是唐僧的徒弟之一,性格憨厚,食欲旺盛,有时显得有点懒惰和胆小,但在关键时刻也会表现出勇敢和忠诚。")
("entity" : "孙悟空" : "人物" : "孙悟空是唐僧的大徒弟,拥有神通广大的能力,性格桀骜不驯,但同时也是一个非常有责任心和正义感的人。")
("entity" : "沙和尚" : "人物" : "沙和尚是唐僧的徒弟之一,性格沉稳,虽然言语不多,但是非常忠诚和可靠。")
("entity" : "唐僧" : "人物" : "唐僧是西天取经的主要角色之一,性格善良,慈悲为怀,但有时也显得有些懦弱和容易受惊。")
("entity" : "怪树" : "妖怪" : "怪树是一个拥有神秘力量的妖怪,能够与唐僧进行交流,并对他进行考验。")
("entity" : "丛林" : "位置" : "丛林是故事发生的一个地点,充满了神秘和未知,也是唐僧和他的徒弟们遇到妖怪的地方。")
("relationship" : "猪八戒" : "孙悟空" : "师兄弟" : "猪八戒和孙悟空都是唐僧的徒弟,他们之间是师兄弟关系,虽然有时争吵,但在关键时刻会互相支持。" : 8)
("relationship" : "沙和尚" : "孙悟空" : "师兄弟" : "沙和尚和孙悟空同为唐僧的徒弟,他们之间也是师兄弟关系,共同承担保护唐僧的责任。" : 7)
("relationship" : "唐僧" : "孙悟空" : "师徒" : "唐僧是孙悟空的师父,他们之间是师徒关系,孙悟空承担着保护唐僧的责任。" : 9)
("relationship" : "唐僧" : "猪八戒" : "师徒" : "唐僧是猪八戒的师父,猪八戒作为徒弟,也有保护唐僧的职责。" : 9)
("relationship" : "唐僧" : "沙和尚" : "师徒" : "沙和尚是唐僧的徒弟,他们之间存在师徒关系,沙和尚同样需要保护唐僧。" : 8)
("relationship" : "唐僧" : "怪树" : "遭遇" : "唐僧在丛林中遇到了怪树,并与其进行了对话和互动。" : 6)
耗时统计如下,两个文件共耗时339秒才处理完,可见这类任务对算力资源的要求很高,Ollama本地部署的小参数LLM很难胜任,效果也不够好,一般要依赖云端部署的大参数大模型。
块耗时: 35.538485050201416 秒
块耗时: 20.14278554916382 秒
块耗时: 21.234768867492676 秒
块耗时: 31.248700857162476 秒
块耗时: 34.52422118186951 秒
块耗时: 19.276843547821045 秒
块耗时: 42.7333881855011 秒
文件耗时: 204.72153162956238 秒
块耗时: 20.799682140350342 秒
块耗时: 41.76913261413574 秒
块耗时: 22.383585929870605 秒
块耗时: 28.66208267211914 秒
块耗时: 20.513476848602295 秒
文件耗时: 338.849595785141 秒
OpenAI gpt-4o-mini,讯飞星火 Spark4.0 Ultra,腾讯混元 hunyuan-pro,阿里通义千问 qwen-max等各大厂的当家大模型都输出了大致符合要求的结果,篇幅关系就不逐一列举了。但各大厂的当家大模型在提取关系类型时的表现有差异,如果要应用于非结构化文本GraphRAG领域,基础模型可能需要做一些微调优化。
附:加载模型用的工具类LangChainHelper.py,上面用到的那些工具函数以后有时间再合并进去。
import os
from openai.resources import api_key
from keys import keys
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain_community.chat_models import ChatSparkLLM
from langchain_community.embeddings import SparkLLMTextEmbeddings
from langchain_community.chat_models import ChatHunyuan
from langchain_community.embeddings import HunyuanEmbeddings
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
os.environ['http_proxy']="http://127.0.0.1:7890"
os.environ['https_proxy']="http://127.0.0.1:7890"
os.environ["OPENAI_API_KEY"] = api_key.key
os.environ["QIANFAN_AK"] = keys.API_KEY
os.environ["QIANFAN_SK"] = keys.SECRET_KEY
os.environ["HUNYUAN_SECRET_ID"] = keys.tx_id
os.environ["HUNYUAN_SECRET_KEY"] = keys.tx_key
os.environ["DASHSCOPE_API_KEY"] = keys.qianwen_key
def loadLLM(vendor):
if vendor=="Baidu":
model = QianfanChatEndpoint(
streaming=True,
model="ERNIE-4.0-8K",
**{"top_p": 0.4, "temperature": 0.1, "penalty_score": 1}
)
elif vendor=="Xunfei":
model = ChatSparkLLM(
spark_app_id = keys.appid,
spark_api_key = keys.api_key,
spark_api_secret = keys.api_secret,
model='Spark4.0 Ultra',
#spark_api_url="wss://spark-api.xf-yun.com/v2.1/chat",
#spark_llm_domain="generalv2",
timeout=120 # 科大讯飞星火默认的超时是30秒,不够,有些块的处理超过30秒,设置为120秒。
)
elif vendor=="Tengxun":
model = ChatHunyuan(
hunyuan_app_id=1303211952,
hunyuan_secret_id = keys.tx_id,
hunyuan_secret_key = keys.tx_key,
model = "hunyuan-pro",
# streaming=True
)
elif vendor=="Ali":
model = ChatTongyi(model="qwen-turbo") # qwen-plus, qwen-turbo, qwen-max
else:
model = ChatOpenAI(model="gpt-4o-mini") # gpt-4o-mini, gpt-4o
return model
def loadEmbedding(vendor):
if vendor=="Baidu":
embeddings = QianfanEmbeddingsEndpoint()
elif vendor=="Xunfei":
embeddings = SparkLLMTextEmbeddings(
spark_app_id = keys.appid,
spark_api_key = keys.api_key,
spark_api_secret = keys.api_secret,
)
elif vendor=="Tengxun":
embeddings = HunyuanEmbeddings()
elif vendor=="Ali":
embeddings = DashScopeEmbeddings(
model="text-embedding-v1", dashscope_api_key = keys.qianwen_key
)
elif vendor=="BAAI":
embeddings = SentenceTransformerEmbeddings(
# Will create a cache folder for the model: models--sentence-transformers--all-MiniLM-L6-v2
# model_name="all-MiniLM-L6-v2", cache_folder="/home/ubuntu/.cache/huggingface/hub/" # /home/ubuntu/dataset
model_name="BAAI/bge-m3", cache_folder="/home/ubuntu/.cache/huggingface/hub/" # /home/ubuntu/dataset
)
else:
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
return embeddings
if __name__ == "__main__":
query = "你好,请介绍一下你自己。"
vendors = ["OpenAI","Baidu","Xunfei","Tengxun","Ali"]
for vendor in vendors:
chat = loadLLM(vendor)
res = chat.invoke(query)
print(res)
embeddings = loadEmbedding(vendor)
single_vector = embeddings.embed_query(query)
print(len(single_vector))
print(single_vector[:8])
五、提取的实体关系写入Neo4j
# 提取的实体关系写入Neo4j-------------------------------------------------------
# 自己写代码由 answer.content生成一个GraphDocument对象
# 每个GraphDocument对象里增加一个metadata属性chunk_id,以便与前面建立的Chunk结点关联
import re
from langchain_community.graphs.graph_document import GraphDocument, Node, Relationship
from langchain_core.documents import Document
# 将每个块提取的实体关系文本转换为LangChain的GraphDocument对象
def convert_to_graph_document(chunk_id, input_text, result):
# 提取节点和关系
node_pattern = re.compile(r'\("entity" : "(.+?)" : "(.+?)" : "(.+?)"\)')
relationship_pattern = re.compile(r'\("relationship" : "(.+?)" : "(.+?)" : "(.+?)" : "(.+?)" : (.+?)\)')
nodes = {}
relationships = []
# 解析节点
for match in node_pattern.findall(result):
node_id, node_type, description = match
if node_id not in nodes:
nodes[node_id] = Node(id=node_id, type=node_type, properties={'description': description})
# 解析并处理关系
for match in relationship_pattern.findall(result):
source_id, target_id, type, description, weight = match
# 确保source节点存在
if source_id not in nodes:
nodes[source_id] = Node(id=source_id, type="未知", properties={'description': 'No additional data'})
# 确保target节点存在
if target_id not in nodes:
nodes[target_id] = Node(id=target_id, type="未知", properties={'description': 'No additional data'})
relationships.append(Relationship(source=nodes[source_id], target=nodes[target_id], type=type,
properties={"description":description, "weight":float(weight)}))
# 创建图对象
graph_document = GraphDocument(
nodes=list(nodes.values()),
relationships=relationships,
# page_content不能为空。
source=Document(page_content=input_text, metadata={"chunk_id": chunk_id})
)
return graph_document
# 构造所有文档所有Chunk的GraphDocument对象
for file_content in file_contents:
chunks = file_content[3]
results = file_content[4]
graph_documents = []
for chunk, result in zip(chunks, results):
graph_document = convert_to_graph_document(chunk["chunk_id"] ,chunk["chunk_doc"].page_content, result)
graph_documents.append(graph_document)
# print(chunk)
# print(result)
# print(graph_document)
# print("\n\n")
file_content.append(graph_documents)
# 实体关系图写入Neo4j,此时每个Chunk是作为Documet结点创建的
# 后面再根据chunk_id把这个Document结点与相应的Chunk结点合并
for file_content in file_contents:
# 删除没有识别出实体关系的空的图对象
graph_documents = []
for graph_document in file_content[5]:
if len(graph_document.nodes)>0 or len(graph_document.relationships)>0:
graph_documents.append(graph_document)
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)
这时看到的知识图谱是这样的:langchain_community.graphs.neo4j_graph.Neo4jGraph.add_graph_documents()会为每个块创建一个Document结点,然后为每个从块中提取的实体创建一个块与实体之间的MENTIONS关系,然后实体之间的关系就按LLM提取的结果建立,每个实体都会有一个__Entity__标签,然而这些文本块的Document结点与前面建立的相应__Chunk__结点之间并没有连接。
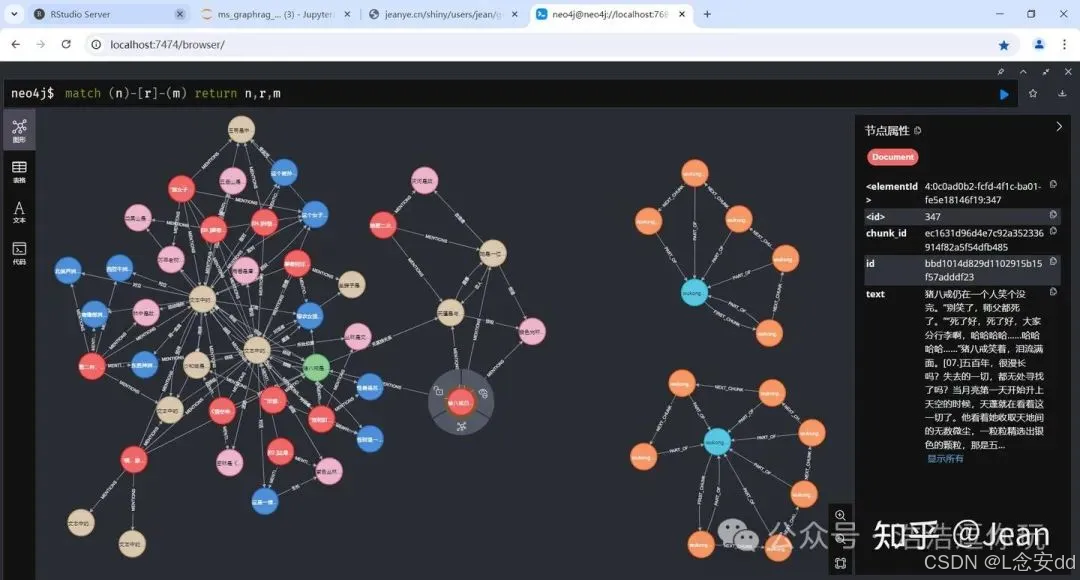
最后一步是把Document结点下的所有连接都转移到对应的__Chunk__结点下,然后删除那个Document结点,这样__Document__->Chunk->__Entity__的结构就初步建好了。它们之间通过chunk_id可以建立起一一对应的关系,这段代码也参考了Neo4j Knowledge Graph Builder合并结点的实现。
# 合并Chunk结点与add_graph_documents()创建的相应Document结点,
# 迁移所有的实体关系到Chunk结点,并删除相应的Document结点。
# 完成Document->Chunk->Entity的结构。
def merge_relationship_between_chunk_and_entites(graph: Neo4jGraph, graph_documents_chunk_chunk_Id : list):
batch_data = []
logging.info("Create MENTIONS relationship between chunks and entities")
for graph_doc_chunk_id in graph_documents_chunk_chunk_Id:
query_data={
'chunk_id': graph_doc_chunk_id,
}
batch_data.append(query_data)
if batch_data:
unwind_query = """
UNWIND $batch_data AS data
MATCH (c:`__Chunk__` {id: data.chunk_id}), (d:Document{chunk_id:data.chunk_id})
WITH c, d
MATCH (d)-[r:MENTIONS]->(e)
MERGE (c)-[newR:MENTIONS]->(e)
ON CREATE SET newR += properties(r)
DETACH DELETE d
"""
graph.query(unwind_query, params={"batch_data": batch_data})
# 合并块结点与Document结点
for file_content in file_contents:
graph_documents_chunk_chunk_Id=[]
for chunk in file_content[3]:
graph_documents_chunk_chunk_Id.append(chunk["chunk_id"])
merge_relationship_between_chunk_and_entites(graph, graph_documents_chunk_chunk_Id)
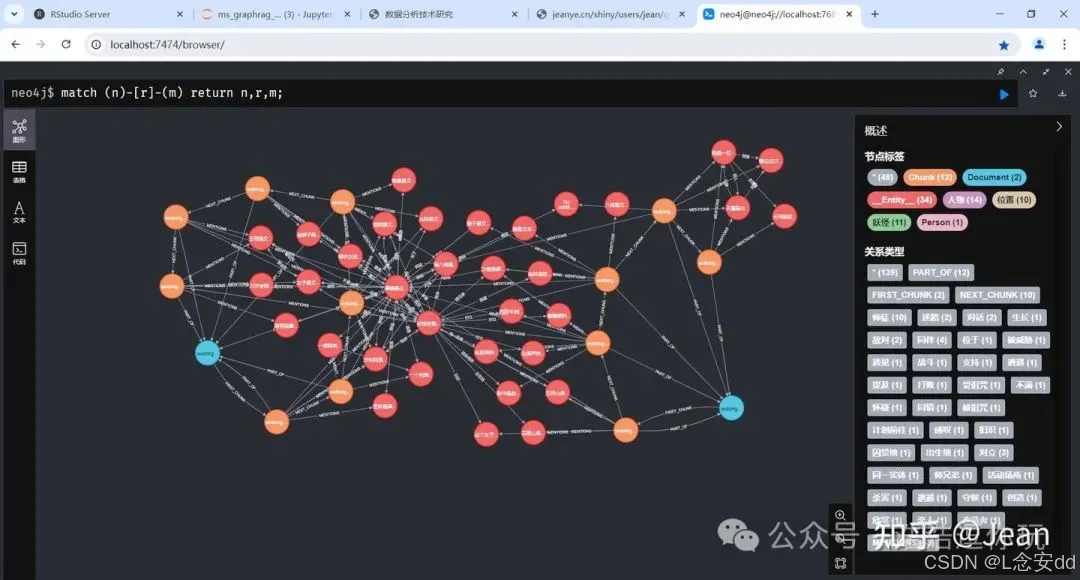
现在可以看看最后建好的知识图谱了,它包含了2个文档结点,每个文档结点下有若干个块结点,每个块结点下有若干个实体结点,实体之间是LLM提取的实体关系。
match (n)-[r]-(m) return n,r,m
六、评估LLM提取的知识图谱
1、看看识别的实体清单。
match (n:`__Entity__`) return n.id as name,labels(n)as type order by n.id limit 100;
可以看到有些实体虽然id不同,但实际上指的都是同一个实体,因为它们是在不同的文本块中分开单独识别的。
name type
"万年老树" ["__Entity__", "位置"]
"丛林" ["__Entity__", "位置"]
"东胜神洲齐天大圣美猴王" ["__Entity__", "妖怪"]
"五岳山" ["__Entity__", "位置"]
"会说话的树" ["__Entity__", "妖怪"]
"北俱芦洲混天大圣鹏魔王" ["__Entity__", "妖怪"]
"南赡部洲通天大圣猕猴王" ["__Entity__", "妖怪"]
"唐僧" ["__Entity__", "人物"]
"天河" ["__Entity__", "位置"]
"天蓬" ["__Entity__", "人物"]
"女子" ["__Entity__", "妖怪"]
"她" ["__Entity__", "人物"]
"孙悟空" ["__Entity__", "人物"]
"密林" ["__Entity__", "位置"]
"怪兽" ["__Entity__", "妖怪"]
"怪树" ["__Entity__", "妖怪"]
"林中" ["__Entity__", "位置"]
"沙僧" ["__Entity__", "人物"]
"沙和尚" ["__Entity__", "人物"]
"猪" ["__Entity__", "人物"]
"猪八戒" ["__Entity__", "人物", "Person"]
"猴子" ["__Entity__", "人物"]
"玉帝" ["__Entity__", "人物"]
"紫色丛林" ["__Entity__", "位置"]
"绿衣女孩" ["__Entity__", "人物", "妖怪"]
"花果山" ["__Entity__", "位置"]
"西贺牛洲平天大圣牛魔王" ["__Entity__", "妖怪"]
"那女子" ["__Entity__", "人物", "妖怪"]
"金蝉子" ["__Entity__", "人物"]
"银色光环" ["__Entity__", "位置"]
"雨巷" ["__Entity__", "位置"]
2、看看实体之间的关系。
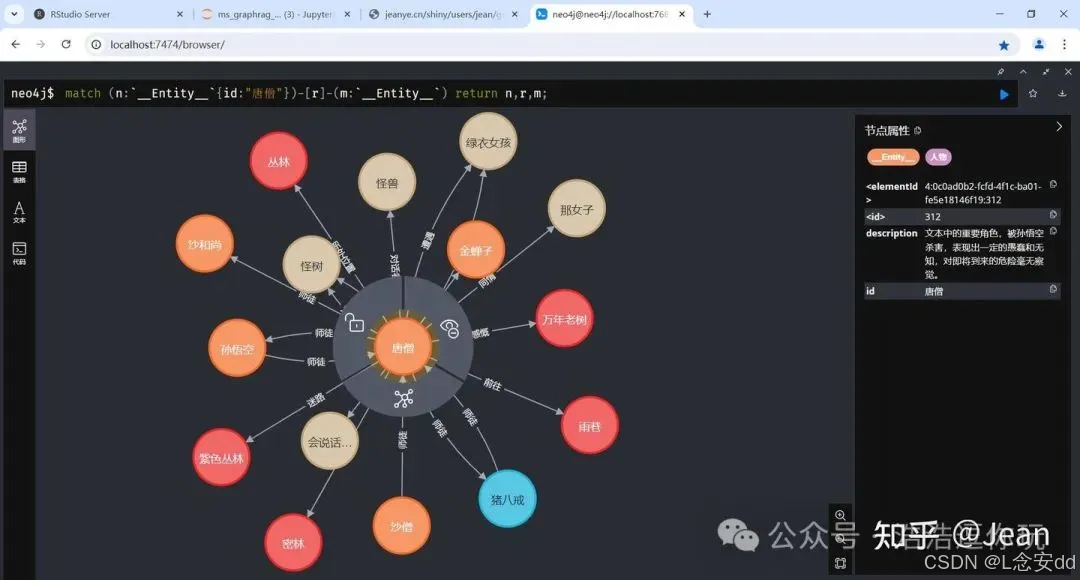
再看看妖妖想吃唐僧肉的关系网,当仁不让的C位。Neo4jGraph中是用MERGE插入实体结点的,在不同的文本块中识别出的结点“唐僧”,插入结点时id相同就会合并,所以上面看不到有id重复的结点,然后唐僧才会有这么C位的关系网。
match (n:`__Entity__`{id:"唐僧"})-[r]-(m:`__Entity__`) return n,r,m;
eo4jGraph源码中构造结点与关系导入Cypher语句的函数,用的是MERGE语句:
def _get_node_import_query(baseEntityLabel: bool, include_source: bool) -> str:
if baseEntityLabel:
return (
f"{include_docs_query if include_source else ''}"
"UNWIND $data AS row "
f"MERGE (source:`{BASE_ENTITY_LABEL}` {{id: row.id}}) "
"SET source += row.properties "
f"{'MERGE (d)-[:MENTIONS]->(source) ' if include_source else ''}"
"WITH source, row "
"CALL apoc.create.addLabels( source, [row.type] ) YIELD node "
"RETURN distinct 'done' AS result"
)
else:
return (
f"{include_docs_query if include_source else ''}"
"UNWIND $data AS row "
"CALL apoc.merge.node([row.type], {id: row.id}, "
"row.properties, {}) YIELD node "
f"{'MERGE (d)-[:MENTIONS]->(node) ' if include_source else ''}"
"RETURN distinct 'done' AS result"
)
def _get_rel_import_query(baseEntityLabel: bool) -> str:
if baseEntityLabel:
return (
"UNWIND $data AS row "
f"MERGE (source:`{BASE_ENTITY_LABEL}` {{id: row.source}}) "
f"MERGE (target:`{BASE_ENTITY_LABEL}` {{id: row.target}}) "
"WITH source, target, row "
"CALL apoc.merge.relationship(source, row.type, "
"{}, row.properties, target) YIELD rel "
"RETURN distinct 'done'"
)
else:
return (
"UNWIND $data AS row "
"CALL apoc.merge.node([row.source_label], {id: row.source},"
"{}, {}) YIELD node as source "
"CALL apoc.merge.node([row.target_label], {id: row.target},"
"{}, {}) YIELD node as target "
"CALL apoc.merge.relationship(source, row.type, "
"{}, row.properties, target) YIELD rel "
"RETURN distinct 'done'"
)
3、看看实体与文本块的关系。
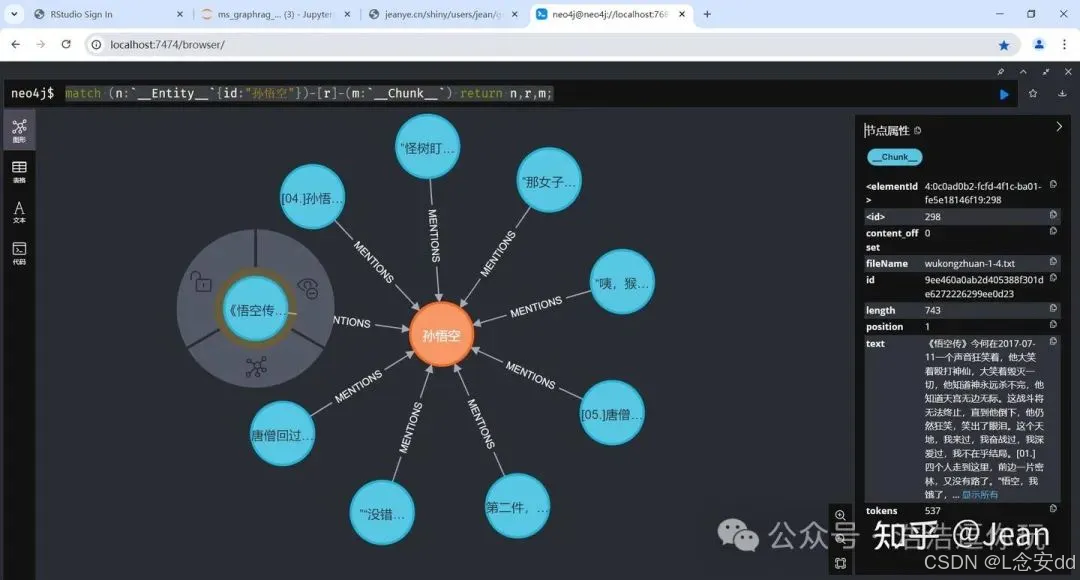
再看看齐天大圣都在哪些章节中出场了,可以看到初步的实体合并已经让知识图谱跨越了块与文档,它们通过“孙悟空”这样的实体连接到了一起,这正是知识图谱的优势所在。
match (n:`__Entity__`{id:"孙悟空"})-[r]-(m:`__Chunk__`) return n,r,m;
4、看看图的Schema。
这是从总体上快速检查LLM实体关系提取质量的有效方法。
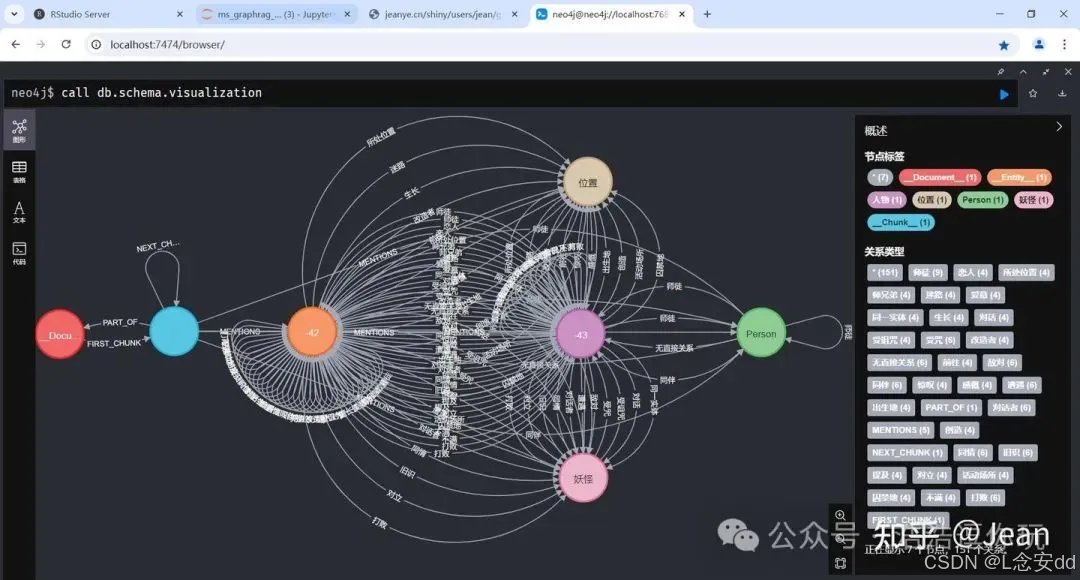
这个Schema需要解释一下。一个识别出来的实体,它会同时有两个标签,[“Entity”,“人物”]、[“Entity”,“妖怪”]、[“Entity”,“位置”],中文的标签是LLM提取时给的,Entity__标签是写入Neo4j时选项baseEntityLabel=True附加的。所以会看到__Entity、人物、妖怪、位置这几类标签之间会有各种关系类型的连接,然后蓝色的__Chunk__到它们之间会有一个MENTIONS关系的连接。因为所有实体都有个__Entity__的标签,所以看到了橙色的__Entity__标签上有很多各种关系的自连接。如果在调用add_graph_documents()写入Neo4j时设定baseEntityLabel=False,每个实体结点就不会有__Entity__标签,上面的Schema中就不会有橙色的__Entity__结点,也不会有那么多的连接,Schema就会简化很多,这正是Neo4j KGBuilder的选择。
上图中可以看到最右边有个绿色的Person标签结点,这说明LLM提取时某些实体返回了Person这个类型,原因是在上面将LLM提取结果转换为GraphDocument的过程中,关系描述内的结点并没有出现在所提取的结点列表中,convert_to_graph_document()将它标记为Person类型(后面修正为未知类型)。这是LLM的问题,也许可以改进提示词,明确要求关系输出中的结点必须出现再结点输出的列表中。
我们把它找出来。
match (n:Person) return labels(n),n.id, n.description
原来是二师兄。
│["__Entity__", "人物", "Person"]│"猪八戒"│"猪八戒是文本中的一个角色,他在师父死后表现出一种复杂的情绪,既笑又泪流满面。"│
猪八戒有3个标签,因为它是合并过的结点。在Neo4jGraph的add_graph_documents()函数写入Neo4j时,用的是MERGE方式,所以标签为人物的猪八戒和标签为Person的猪八戒合并后,它就同时有了这两个标签,另一个标签__Entity__是选项baseEntityLabel=True附加的。
**同时可以看到用MERGE合并实体和关系的另一个局限性,可以看到猪八戒的实体描述是最后出现的实体结点的描述,其它同名实体结点的描述直接被替换了。**这从上面Neo4jGraph源码的 _get_node_import_query()函数可以看出来,这是需要改进的地方。
if baseEntityLabel:
return (
...
"SET source += row.properties "
...
)
也许把所有同名结点的描述发给LLM综合一下,或者拼接起来都保留会更好,我们可以通过继承Neo4jGraph类并重载_get_node_import_query()和_get_rel_import_query()等方法来实现实体和关系合并的优化。
from langchain_community.graphs import Neo4jGraph
class MyNeo4jGraph(Neo4jGraph):
def _get_node_import_query(baseEntityLabel: bool, include_source: bool) -> str:
...
def _get_rel_import_query(baseEntityLabel: bool) -> str:
...
5、最后看看识别的关系。
match (n:`__Entity__`)-[r]-(m:`__Entity__`)
with r
return type(r) as type, count(r) as c
order by c desc
输出如下,识别的关系类型需要进一步的标准化规范化,比如“师兄弟”与“同伴”其实是同一种关系,“对立”与“敌对”应该也是。
type c
"师徒" 12
"同伴" 6
"对立" 6
"敌对" 6
"对话者" 6
"迷路" 4
"同一实体" 2
"活动场所" 2
"师兄弟" 2
"旧识" 2
"囚禁地" 2
"出生地" 2
"不满" 2
"打败" 2
"前往" 2
"感慨" 2
"同情" 2
"提及" 2
"遭遇" 2
"所处位置" 2
"对话" 2
"无直接关系" 2
"生长" 2
"受诅咒" 2
"受咒" 2
"恋人" 2
"惊叹" 2
"爱慕" 2
"改造者" 2
"创造" 2
假定在第一次提取之前,我们对该文档集并无多少了解,所以只指定了要提取的实体类型,因为我们都熟知《西游记》的故事,换个专业的术语来说就是领域专家了解一些领域知识。现在我们对领域知识有了更多的了解,我们可以尝试改进系统提示词和示例,让LLM在指定的关系类型列表中选择实体之间的关系,现在来重新提取一次。
relationship_types=["师徒", "师兄弟", "对抗", "对话", "态度", "故事地点", "其它"]
们只关注提取的3类实体之间最可能的关系,不在其中的就归入“其它”来兜底。系统提示词模板中-relationship_type的描述修改为:
-relationship_type:以下类型之一:[{relationship_types}],当不能归类为上述列表中前面的类型时,归类为最后的一类“其它”
用户提示词模板也增加关系类型的描述:
human_template="""
-真实数据-
######################
实体类型:{entity_types}
关系类型:{relationship_types}
文本:{input_text}
######################
输出:
"""
测试一下。
chat_history = []
answer = chain.invoke({
"chat_history": chat_history,
"entity_types": entity_types,
"relationship_types": relationship_types,
"tuple_delimiter": tuple_delimiter,
"record_delimiter": record_delimiter,
"completion_delimiter": completion_delimiter,
"input_text": input_text
})
print(answer.content)
LLM很好的规范了关系类型的输出:
>>> print(answer.content)
("entity" : "猪八戒" : "人物" : "猪八戒是唐僧的徒弟,性格憨厚,食欲旺盛,与孙悟空常有互动。")
("entity" : "孙悟空" : "人物" : "孙悟空是唐僧的大徒弟,神通广大,性格桀骜不驯,与猪八戒常有打闹。")
("entity" : "沙和尚" : "人物" : "沙和尚是唐僧的徒弟之一,性格沉稳,言语不多,睡梦中也会呼应师兄弟的行动。")
("entity" : "唐僧" : "人物" : "唐僧是西天取经的主要角色,性格懦弱,常被妖怪捉拿,但有着坚定的信仰。")
("entity" : "怪树" : "妖怪" : "怪树是一个拥有意识的妖怪,与唐僧进行了对话,对唐僧的生死有决定权。")
("entity" : "丛林" : "位置" : "丛林是故事发生的一个地点,唐僧和徒弟们在此遇到了怪树。")
("relationship" : "猪八戒" : "孙悟空" : "师兄弟" : "猪八戒和孙悟空是师兄弟关系,两人之间常有互动和打闹。" : 8)
("relationship" : "沙和尚" : "孙悟空" : "师兄弟" : "沙和尚和孙悟空是师兄弟关系,虽然沙和尚言语不多,但也会呼应师兄弟的行动。" : 7)
("relationship" : "沙和尚" : "猪八戒" : "师兄弟" : "沙和尚和猪八戒是师兄弟关系,三人共同保护唐僧取经。" : 7)
("relationship" : "唐僧" : "孙悟空" : "师徒" : "唐僧是孙悟空的师父,孙悟空保护唐僧取经。" : 9)
("relationship" : "唐僧" : "猪八戒" : "师徒" : "唐僧是猪八戒的师父,猪八戒协助唐僧取经。" : 8)
("relationship" : "唐僧" : "沙和尚" : "师徒" : "唐僧是沙和尚的师父,沙和尚负责背负行李,保护唐僧。" : 7)
("relationship" : "唐僧" : "怪树" : "对抗" : "唐僧被怪树捉拿,两者之间存在对抗关系。" : 6)
("relationship" : "孙悟空" : "怪树" : "对抗" : "孙悟空为了救出唐僧,与怪树发生了对抗。" : 7)
("relationship" : "猪八戒" : "唐僧" : "对话" : "猪八戒与唐僧之间进行了对话,讨论了关于怪树的事情。" : 5)
("relationship" : "唐僧" : "丛林" : "故事地点" : "唐僧和徒弟们在丛林中遇到了怪树,丛林是故事发生的重要地点。" : 8)
现在重新生成一次该文档集的知识图谱,可以看到经过规范化后,关系的种类减少了,Schema简化了,这一次把关系输出中不在结点输出中的结点标记为未知类型。
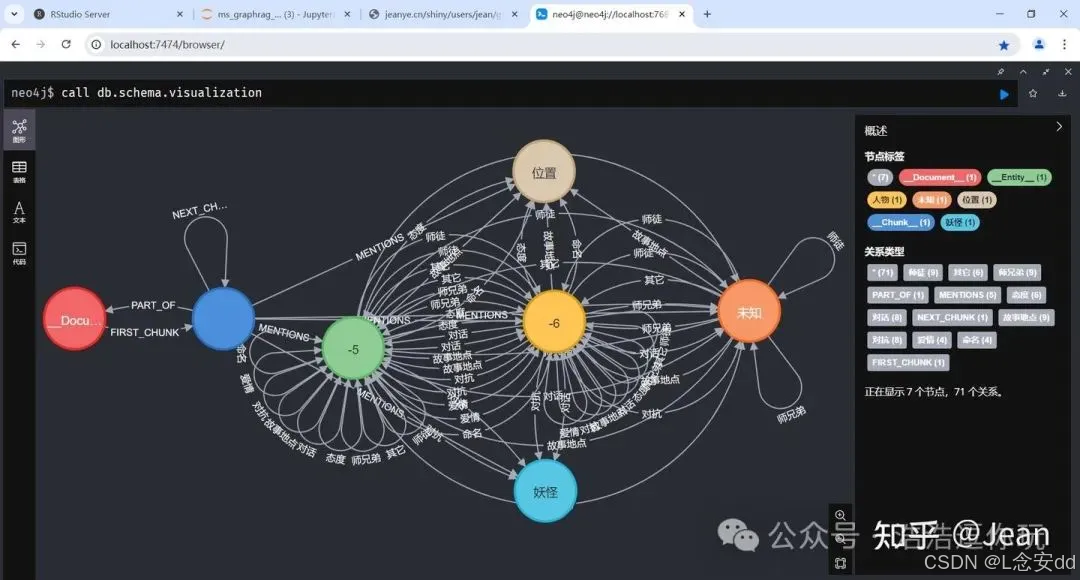
再看看识别的关系类型,少了很多。LLM遵循了归类到其它的指令,但是没有100%的遵循,因为还有关系识别为爱情和命名的类型,而不是归入其它的类型。这正是用LLM从非结构化文档中提取实体关系时的不确定性和局限性:虽然这个方法效率很高,效果也很好,但目前还没有办法让LLM 100%的执行提示词的要求,虽然它可能能够在99%的时候正确执行指令,但是偶尔还是会跑偏出错。了解存在这个不确定性和局限性是很重要的。
type c
"故事地点" 22
"对话" 16
"师兄弟" 16
"师徒" 14
"对抗" 12
"态度" 6
"其它" 2
"爱情" 2
"命名" 2
现在LLM提取的效果已经非常不错了。
七、OpenAI的输出
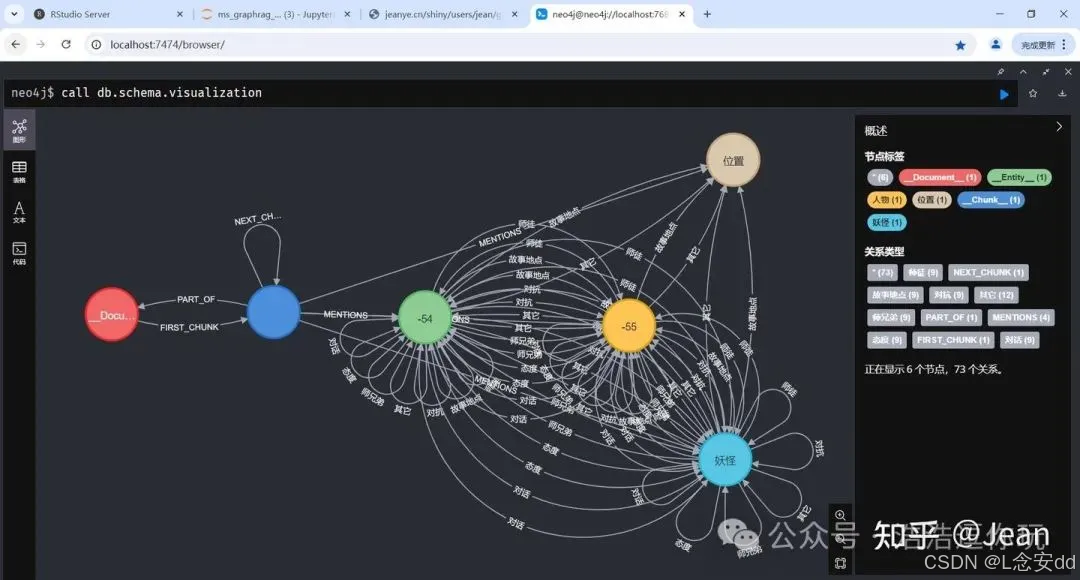
OpenAI gpt-4o-mini 第一次就100%执行了系统提示词的指令,输出完全正确,不得不佩服,国内各大厂要正视差距,努力赶上。中文500个token大约700~800字节,一页作文方格纸的篇幅,速度很快,体验很好。
1、Schema。
没有多余的标签,完全遵循系统提示词的指令。
2、提取的实体。
name type
"万年老树" ["__Entity__", "位置"]
"东胜神洲" ["__Entity__", "位置"]
"五岳山" ["__Entity__", "位置"]
"会说话的树" ["__Entity__", "妖怪"]
"北俱芦洲" ["__Entity__", "位置"]
"南赡部洲" ["__Entity__", "位置"]
"唐僧" ["__Entity__", "人物"]
"四魔王" ["__Entity__", "妖怪"]
"天蓬" ["__Entity__", "人物", "妖怪"]
"女妖" ["__Entity__", "妖怪"]
"女子" ["__Entity__", "妖怪"]
"女孩" ["__Entity__", "妖怪"]
"她" ["__Entity__", "人物", "妖怪"]
"妖怪" ["__Entity__", "妖怪"]
"孙悟空" ["__Entity__", "人物"]
"怪兽" ["__Entity__", "妖怪"]
"怪树" ["__Entity__", "妖怪"]
"悟空" ["__Entity__", "人物"]
"月" ["__Entity__", "妖怪"]
"沙僧" ["__Entity__", "人物"]
"沙和尚" ["__Entity__", "人物"]
"猪" ["__Entity__", "人物"]
"猪八戒" ["__Entity__", "人物"]
"紫色的丛林" ["__Entity__", "位置"]
"绿衣女孩" ["__Entity__", "人物"]
"花果山" ["__Entity__", "位置"]
"西贺牛洲" ["__Entity__", "位置"]
"那女子" ["__Entity__", "妖怪"]
"银河" ["__Entity__", "位置"]
3、提取的关系。
完全遵循系统提示词的指令。
type c
"故事地点" 22
"对话" 22
"对抗" 20
"态度" 18
"师兄弟" 14
"师徒" 10
"其它" 8
4、建立的知识图谱。
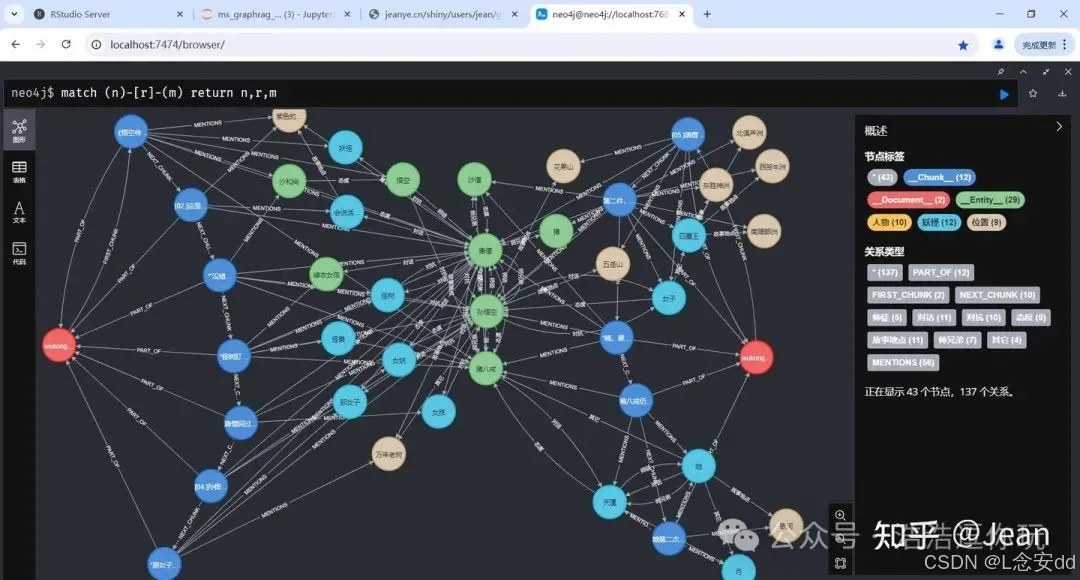
5、处理的速度很快。
共耗时不到1分钟,1分钟 VS 6分钟,这可能是云端算力的差别,可能也有模型实现上的差别。
块耗时: 6.724599838256836 秒
块耗时: 4.233803033828735 秒
块耗时: 5.919651508331299 秒
块耗时: 4.632024765014648 秒
块耗时: 3.9346086978912354 秒
块耗时: 3.276869297027588 秒
块耗时: 4.239957809448242 秒
文件耗时: 32.96166753768921 秒
块耗时: 3.9983274936676025 秒
块耗时: 6.548298120498657 秒
块耗时: 4.509512186050415 秒
块耗时: 3.746511220932007 秒
块耗时: 4.7137768268585205 秒
文件耗时: 56.47823882102966 秒
附:不比较提取知识图谱的质量,四个主流国产大模型的参考总体耗时如下,其中讯飞用的是websocket通讯,需要在ChatLLM模型初始化时指定timeout参数>30秒,以免超时出错。
百度 文件耗时: 404.7422833442688 秒
讯飞 文件耗时: 342.7268991470337 秒
腾讯 文件耗时: 239.05918431282043 秒
阿里 文件耗时: 435.01095271110535 秒
这只是一个初步的知识图谱,后面还要在全图的范围内通过实体解析(指代消解)合并相同的实体,以及建立社区结构,增加__Community__类结点,并作社区摘要。然后要为实体的描述或块的文本建立向量索引,这些工作完成后,完整的知识图谱就建好了,可以通过全局检索和局部检索来准确的回答问题,具体可以参阅前文《用Neo4j与LangChain实现从局部到全局的RAG:建立知识图谱》。
我注意到一个重要的区别是,Neo4j Knowledge Graph Builder的向量索引建立在Chunk结点的层级上,它不使用__Entity__标签,通过HAS_ENTITY关系来明确Chunk与实体的关系(参阅源码可知,在迁移Document结点的关系到Chunk结点时,将实体的MENTIONS关系替换为HAS_ENTITY关系);微软GraphRAG的向量索引建立在__Entity__层级的结点上,不同类型的实体会有附加的类型标签。我觉得实体有统一的附加__Entity__标签会方便一点,在实体层级上的局部搜索会更精准一些,所以决定还是使用微软GraphRAG的图结构。


















 174
174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











