






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
我的环境:
-
语言环境:python 3.8
-
编译器:jupyter notebook
-
深度学习环境:Pytorch
torch == 2.1.0+cpu
torchvision == 0.16.0+cpu
LSTM介绍
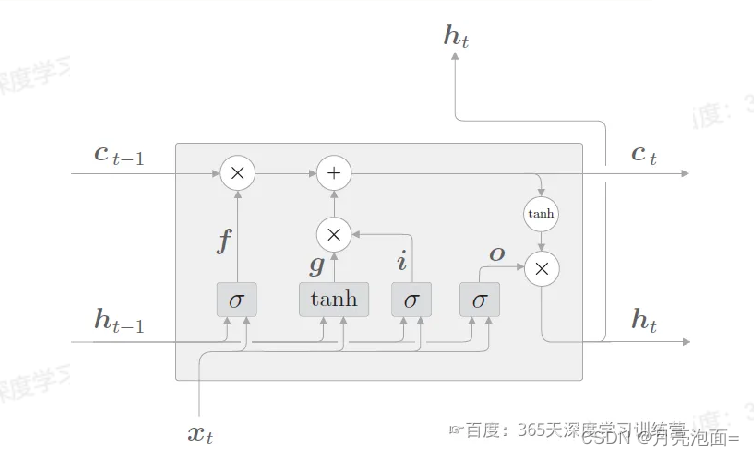
1. 输入输出
- 输入:当前时刻网络输出x_t,上一时刻LSTM输出h_t-1,上一时刻记忆单元c_t-1
- 输出:当前时刻LSTM输出h_t,隐藏状态向量h_t, 记忆单元c_t
2. 三个门
- 遗忘门ft,表示h_t-1的那些特征被用于计算c_t,sigmoid函数
- 输入门it,决定哪些新信息被添加到记忆单元,sigmoid函数筛选信息*tanh生成候选信息
- 输出门ot,决定记忆单元哪些信息输出到h_t中,sigmoid筛选细腻*tanh处理后的记忆单元 = h_t
任务说明:
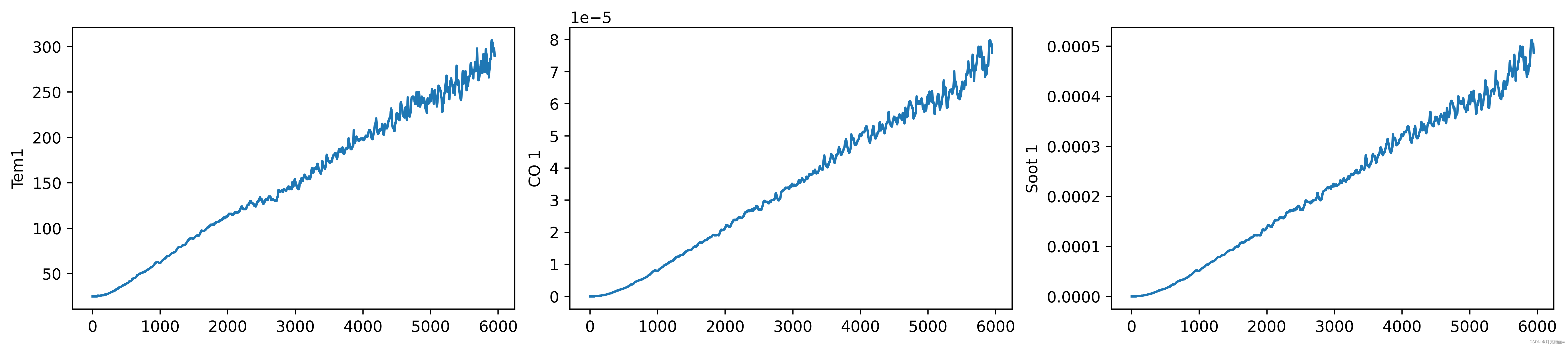
- 数据集提供了火灾温度(tem1),一氧化碳浓度(co1),烟雾浓度(soot1)随时间变化的数据,对未来某一时刻火灾温度进行预测。
- R2达到0.83.
- 使用1-8时刻预测9-10时刻。
一、准备工作
import tensorflow as tf
import pandas as pd
import numpy as np
df = pd.read_csv("woodpine2.csv")
df
| Time | Tem1 | CO 1 | Soot 1 | |
|---|---|---|---|---|
| 0 | 0.000 | 25.0 | 0.000000 | 0.000000 |
| 1 | 0.228 | 25.0 | 0.000000 | 0.000000 |
| 2 | 0.456 | 25.0 | 0.000000 | 0.000000 |
| 3 | 0.685 | 25.0 | 0.000000 | 0.000000 |
| 4 | 0.913 | 25.0 | 0.000000 | 0.000000 |
| ... | ... | ... | ... | ... |
| 5943 | 366.000 | 295.0 | 0.000077 | 0.000496 |
| 5944 | 366.000 | 294.0 | 0.000077 | 0.000494 |
| 5945 | 367.000 | 292.0 | 0.000077 | 0.000491 |
| 5946 | 367.000 | 291.0 | 0.000076 | 0.000489 |
| 5947 | 367.000 | 290.0 | 0.000076 | 0.000487 |
5948 rows × 4 columns
plt.rcParams['savefig.dpi'] = 500 #像素
plt.rcParams['figure.dpi'] = 500 #分辨率
fig, ax = plt.subplots(1,3,constrained_layout = True, figsize = (14,3))
sns.lineplot(data = df["Tem1"], ax = ax[0])
sns.lineplot(data = df["CO 1"], ax = ax[1])
sns.lineplot(data = df["Soot 1"], ax = ax[2])
<Axes: ylabel='Soot 1'>
二、数据预处理
dataFrame = df.iloc[:,1:]
dataFrame
| Tem1 | CO 1 | Soot 1 | |
|---|---|---|---|
| 0 | 25.0 | 0.000000 | 0.000000 |
| 1 | 25.0 | 0.000000 | 0.000000 |
| 2 | 25.0 | 0.000000 | 0.000000 |
| 3 | 25.0 | 0.000000 | 0.000000 |
| 4 | 25.0 | 0.000000 | 0.000000 |
| ... | ... | ... | ... |
| 5943 | 295.0 | 0.000077 | 0.000496 |
| 5944 | 294.0 | 0.000077 | 0.000494 |
| 5945 | 292.0 | 0.000077 | 0.000491 |
| 5946 | 291.0 | 0.000076 | 0.000489 |
| 5947 | 290.0 | 0.000076 | 0.000487 |
5948 rows × 3 columns
1. 设置X,y
width_X = 8 #前8个时段为X
width_y = 2 #第9个时段为y
X = []
y = []
in_start = 0
for _,_ in df.iterrows():
in_end = in_start + width_X
out_end = in_end + width_y
if out_end < len(dataFrame):
X_ = np.array(dataFrame.iloc[in_start:in_end , ])
X_ = X_.reshape((len(X_)*3))
y_ = np.array(dataFrame.iloc[in_end: out_end , 0])
X.append(X_)
y.append(y_)
in_start += 1
X = np.array(X)
y = np.array(y)
X,y
(array([[2.50e+01, 0.00e+00, 0.00e+00, ..., 2.50e+01, 2.07e-38, 1.33e-37],
[2.50e+01, 0.00e+00, 0.00e+00, ..., 2.50e+01, 5.37e-37, 3.45e-36],
[2.50e+01, 0.00e+00, 0.00e+00, ..., 2.50e+01, 5.51e-36, 3.54e-35],
...,
[2.96e+02, 7.84e-05, 5.03e-04, ..., 2.96e+02, 7.77e-05, 4.99e-04],
[2.97e+02, 7.86e-05, 5.04e-04, ..., 2.95e+02, 7.73e-05, 4.96e-04],
[2.97e+02, 7.87e-05, 5.05e-04, ..., 2.94e+02, 7.69e-05, 4.94e-04]]),
array([[ 25., 25.],
[ 25., 25.],
[ 25., 25.],
...,
[295., 294.],
[294., 292.],
[292., 291.]]))
X.shape, y.shape
((5938, 24), (5938, 2))
2. 归一化
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range = (0,1))
X_scales = sc.fit_transform(X)
X_scales.shape
(5938, 24)
X_scaled = X_scales.reshape(len(X_scales),width_X,3)
X_scaled.shape
(5938, 8, 3)
3. 划分数据集
X_train = np.array(X_scaled[:5000]).astype('float64')
y_train = np.array(y[:5000]).astype('float64')
X_test = np.array(X_scaled[5000:]).astype('float64')
y_test = np.array(y[5000:]).astype('float64')
X_train.shape, X_test.shape
((5000, 8, 3), (938, 8, 3))
三、模型构建,编译,训练
1. 模型构建
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Bidirectional
from tensorflow.keras import Input
model = Sequential()
model.add(LSTM(units=64, activation = 'relu',return_sequences = True, input_shape = (X_train.shape[1],3)))
model.add(LSTM(units=64, activation = 'relu'))
model.add(Dense(width_y))
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_4 (LSTM) (None, 8, 64) 17408
lstm_5 (LSTM) (None, 64) 33024
dense_2 (Dense) (None, 2) 130
=================================================================
Total params: 50562 (197.51 KB)
Trainable params: 50562 (197.51 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
2. 模型编译
model.compile(optimizer = tf.keras.optimizers.Adam(1e-3),
loss = 'mean_squared_error')
3. 模型训练
epochs = 50
history = model.fit(X_train,y_train,
epochs = epochs,
batch_size = 64,
validation_data = (X_test,y_test),
validation_freq = 1)
Epoch 1/50
79/79 [==============================] - 3s 15ms/step - loss: 13002.8154 - val_loss: 5616.8252
Epoch 2/50
79/79 [==============================] - 1s 12ms/step - loss: 247.7659 - val_loss: 1137.9130
Epoch 3/50
79/79 [==============================] - 1s 12ms/step - loss: 38.8453 - val_loss: 379.3899
Epoch 4/50
79/79 [==============================] - 1s 12ms/step - loss: 11.2683 - val_loss: 248.6566
Epoch 5/50
79/79 [==============================] - 1s 13ms/step - loss: 8.5500 - val_loss: 252.0033
Epoch 6/50
79/79 [==============================] - 1s 13ms/step - loss: 8.6463 - val_loss: 186.1750
Epoch 7/50
79/79 [==============================] - 1s 12ms/step - loss: 8.5890 - val_loss: 203.9141
Epoch 8/50
79/79 [==============================] - 1s 13ms/step - loss: 8.2541 - val_loss: 226.8261
Epoch 9/50
79/79 [==============================] - 1s 13ms/step - loss: 8.2206 - val_loss: 214.3781
Epoch 10/50
79/79 [==============================] - 1s 13ms/step - loss: 8.3749 - val_loss: 164.7413
Epoch 11/50
79/79 [==============================] - 1s 12ms/step - loss: 8.4348 - val_loss: 167.7527
Epoch 12/50
79/79 [==============================] - 1s 12ms/step - loss: 8.6248 - val_loss: 165.3832
Epoch 13/50
79/79 [==============================] - 1s 13ms/step - loss: 8.5666 - val_loss: 224.6095
Epoch 14/50
79/79 [==============================] - 1s 13ms/step - loss: 8.3841 - val_loss: 213.7288
Epoch 15/50
79/79 [==============================] - 1s 15ms/step - loss: 8.2504 - val_loss: 271.5983
Epoch 16/50
79/79 [==============================] - 1s 14ms/step - loss: 8.7495 - val_loss: 180.2835
Epoch 17/50
79/79 [==============================] - 1s 12ms/step - loss: 8.2108 - val_loss: 239.1326
Epoch 18/50
79/79 [==============================] - 1s 14ms/step - loss: 8.6858 - val_loss: 152.2928
Epoch 19/50
79/79 [==============================] - 1s 14ms/step - loss: 8.4797 - val_loss: 255.9244
Epoch 20/50
79/79 [==============================] - 1s 13ms/step - loss: 8.3837 - val_loss: 190.1214
Epoch 21/50
79/79 [==============================] - 1s 13ms/step - loss: 8.2621 - val_loss: 131.4390
Epoch 22/50
79/79 [==============================] - 1s 12ms/step - loss: 8.1924 - val_loss: 194.1792
Epoch 23/50
79/79 [==============================] - 1s 12ms/step - loss: 8.0023 - val_loss: 214.8212
Epoch 24/50
79/79 [==============================] - 1s 13ms/step - loss: 8.0245 - val_loss: 150.9851
Epoch 25/50
79/79 [==============================] - 1s 12ms/step - loss: 8.4004 - val_loss: 123.8255
Epoch 26/50
79/79 [==============================] - 1s 12ms/step - loss: 8.6597 - val_loss: 191.1270
Epoch 27/50
79/79 [==============================] - 1s 13ms/step - loss: 8.4472 - val_loss: 151.8523
Epoch 28/50
79/79 [==============================] - 1s 13ms/step - loss: 8.1072 - val_loss: 126.9261
Epoch 29/50
79/79 [==============================] - 1s 13ms/step - loss: 9.8221 - val_loss: 249.2247
Epoch 30/50
79/79 [==============================] - 1s 13ms/step - loss: 8.1813 - val_loss: 158.8967
Epoch 31/50
79/79 [==============================] - 1s 13ms/step - loss: 8.8521 - val_loss: 121.6337
Epoch 32/50
79/79 [==============================] - 1s 14ms/step - loss: 8.6561 - val_loss: 108.4152
Epoch 33/50
79/79 [==============================] - 1s 12ms/step - loss: 9.1036 - val_loss: 121.5477
Epoch 34/50
79/79 [==============================] - 1s 13ms/step - loss: 8.8073 - val_loss: 97.2747
Epoch 35/50
79/79 [==============================] - 1s 13ms/step - loss: 9.1284 - val_loss: 195.3769
Epoch 36/50
79/79 [==============================] - 1s 13ms/step - loss: 7.7126 - val_loss: 141.8356
Epoch 37/50
79/79 [==============================] - 1s 13ms/step - loss: 7.7963 - val_loss: 211.4055
Epoch 38/50
79/79 [==============================] - 1s 13ms/step - loss: 8.8638 - val_loss: 204.0073
Epoch 39/50
79/79 [==============================] - 1s 12ms/step - loss: 7.9304 - val_loss: 116.1591
Epoch 40/50
79/79 [==============================] - 1s 14ms/step - loss: 7.6471 - val_loss: 235.9073
Epoch 41/50
79/79 [==============================] - 1s 12ms/step - loss: 7.7511 - val_loss: 120.2813
Epoch 42/50
79/79 [==============================] - 1s 12ms/step - loss: 9.3354 - val_loss: 280.3375
Epoch 43/50
79/79 [==============================] - 1s 13ms/step - loss: 8.0944 - val_loss: 96.3422
Epoch 44/50
79/79 [==============================] - 1s 12ms/step - loss: 8.4290 - val_loss: 373.7235
Epoch 45/50
79/79 [==============================] - 1s 13ms/step - loss: 9.6937 - val_loss: 190.6326
Epoch 46/50
79/79 [==============================] - 1s 12ms/step - loss: 7.9022 - val_loss: 177.4366
Epoch 47/50
79/79 [==============================] - 1s 12ms/step - loss: 8.1687 - val_loss: 161.2531
Epoch 48/50
79/79 [==============================] - 1s 13ms/step - loss: 9.5011 - val_loss: 140.0809
Epoch 49/50
79/79 [==============================] - 1s 12ms/step - loss: 8.8527 - val_loss: 176.4043
Epoch 50/50
79/79 [==============================] - 1s 12ms/step - loss: 7.7198 - val_loss: 164.9144
四、模型评估
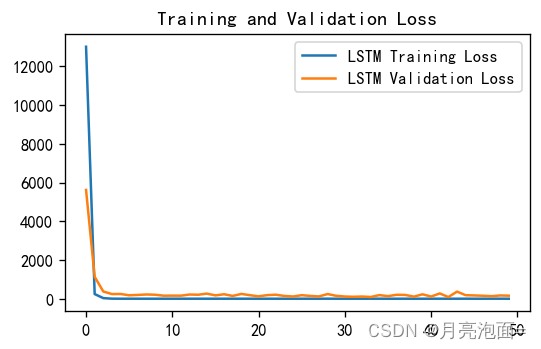
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(5, 3),dpi = 120)
plt.plot(history.history['loss'], label='LSTM Training Loss')
plt.plot(history.history['val_loss'], label='LSTM Validation Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()
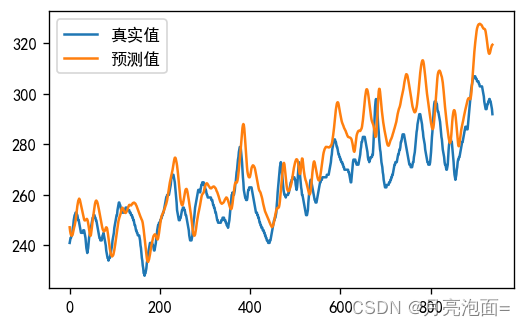
调用模型进行预测
predicted_lstm = model.predict(X_test)
y_test_one = [i[0] for i in y_test]
predicted_y_one = [i[0] for i in predicted_lstm]
plt.figure(figsize=(5, 3),dpi = 120)
plt.plot(y_test_one[:1000], label='真实值')
plt.plot(predicted_y_one[:1000], label='预测值')
plt.legend()
plt.show()
30/30 [==============================] - 0s 3ms/step
from sklearn import metrics
RMSE_lstm = metrics.mean_squared_error(predicted_lstm,y_test)**0.5
R2_lstm = metrics.r2_score(predicted_lstm,y_test)
RMSE_lstm, R2_lstm
(12.841900251368994, 0.6532699613567474)
完成预测单个时间步达到0.86的R2以后,更改为预测两个时间步,结果如上。















 4952
4952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









